







双指针算法
双指针算法分类

双指针算法模板

性质:

总结
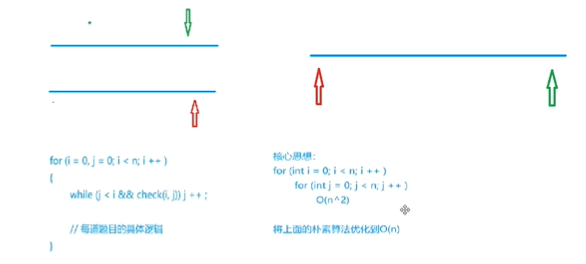
为什么双指针算法可以起到优化的作用:
i:0->n
j:0->n 在每次循环完毕,j不需要归零,因此j也是0->n
两个指针最多为2n
例1
输入字符串,把其中每一个单词输出来,单词之间用空格隔开
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char str[1000];
gets(str);
int n = strlen(str);
for(int i = 0;str[i];i++)
{
int j = i;
//分清楚
while(j < n && str[j] != ' ') j++;
//这道题的具体逻辑
for(int k = i;k < j;k++) printf("%c",str[k]);
printf("\n");
i = j;
}
return 0;
}
例2
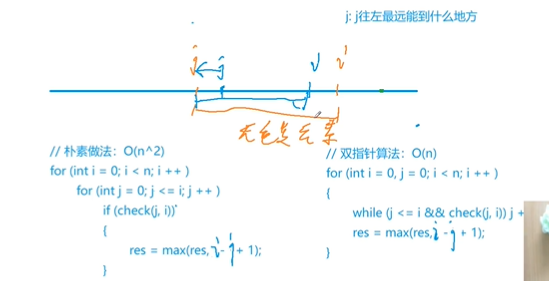
双指针怎么想:可以从暴力的方式想,然后利用单调性改进
给定一个长度为 n 的整数序列,请找出最长的不包含重复的数的连续区间,输出它的长度。
输入格式
第一行包含整数 n。
第二行包含 n 个整数(均在 0∼105 范围内),表示整数序列。
输出格式
共一行,包含一个整数,表示最长的不包含重复的数的连续区间的长度。
数据范围
1≤n≤105
输入样例:
5
1 2 2 3 5
输出样例:
3
s[N]
s[a[i]]]++
//799
#include <iostream>
using namespace std;
const int N = 100010;
int a[N];
int s[N]; //计数器,每个数出现的次数
int n;
int main()
{
cin>>n;
for(int i = 0;i < n;i++ ) cin >> a[i];
int res = 0;
for(int i = 0,j=0 ;i < n;i++)
{
s[a[i]]++;
while(s[a[i]] > 1)
{
s[a[j]]--; //j表示弹出数据,对应统计的数量降低
j++; //向前移动
}
res = max(res,i-j+1); //因为最后一次可能不是最大的,该值用于统计累加过程中整个串中最大的一次数值记录
}
cout<< res <<endl;
return 0;
}
位运算
二进制的第k位

//n的二进制表示中第k位
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
int n = 10;
for(int k = 3;k>=0;k--)
//向右移动k位
cout<< (n>>k&1);
return 0;
}
lowbit 返回x的最后一位1
给定一个长度为 n 的数列,请你求出数列中每个数的二进制表示中 1 的个数。
输入格式
第一行包含整数 n。
第二行包含 n 个整数,表示整个数列。
输出格式
共一行,包含 n 个整数,其中的第 i 个数表示数列中的第 i 个数的二进制表示中 1 的个数。
数据范围
1≤n≤100000,
0≤数列中元素的值≤109
输入样例:
5
1 2 3 4 5
输出样例:
1 1 2 1 2

实现
lowbit的实现:x & -x
~代表数值取反
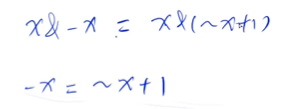

应用:统计x中1的个数。
要先学会走路,再学会飞。不能还不会走路,就去飞。一步步来,不然会摔得很惨
#include <iostream>
using namespace std;
int n;
int lowbit(int x)
{
return x & -x;
}
int main()
{
cin>>n;
//针对每一个数值进行处理,不需要存储相关信息
while(n--)
{
int x;
cin>>x;
int res = 0;
while(x) x -= lowbit(x),res++; //每次减去x的最后一位
cout<<res<<' ';
}
return 0;
}
计算机中编码知识

解释为什么反码是取反后加一,而不是直接取反?
计算机底层实现没有减法,减法由加法实现
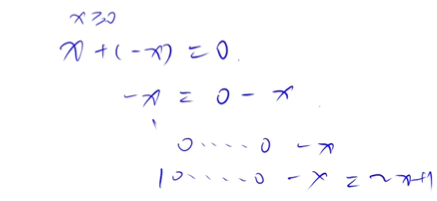
做题思路
人类做题的过程就是dfs的过程
有同学学习比较快,或者接触比较早,或者对各种算法已经熟悉了
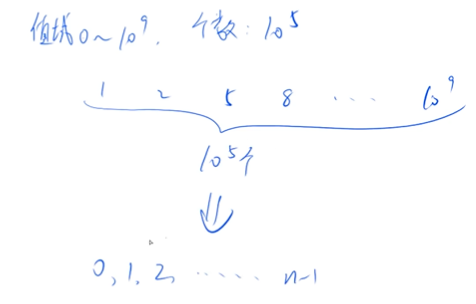
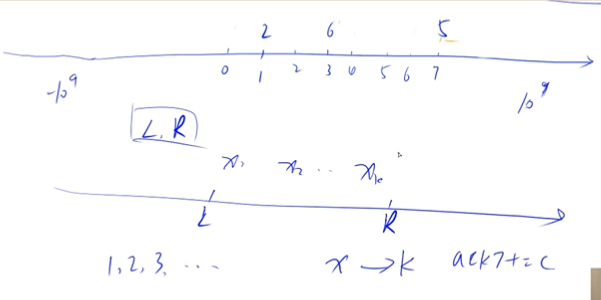
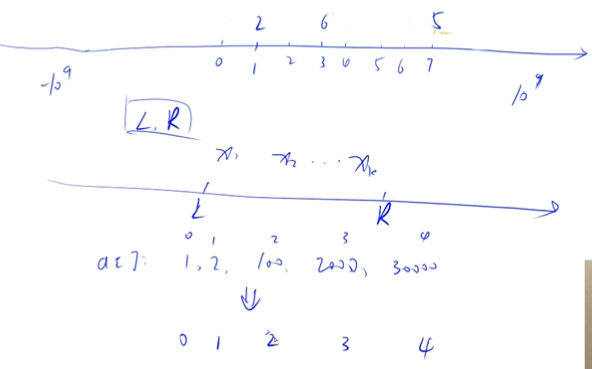
离散化
假定有一个无限长的数轴,数轴上每个坐标上的数都是 0。
现在,我们首先进行 n 次操作,每次操作将某一位置 x 上的数加 c。
接下来,进行 m 次询问,每个询问包含两个整数 l 和 r,你需要求出在区间 [l,r] 之间的所有数的和。
输入格式
第一行包含两个整数 n 和 m。
接下来 n 行,每行包含两个整数 x 和 c。
再接下来 m 行,每行包含两个整数 l 和 r。
输出格式
共 m 行,每行输出一个询问中所求的区间内数字和。
数据范围
−109≤x≤109,
1≤n,m≤105,
−109≤l≤r≤109,
−10000≤c≤10000
输入样例:
3 3
1 2
3 6
7 5
1 3
4 6
7 8
输出样例:
8
0
5
特指整数离散化,保序离散化


#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef pair<int,int> PII;
const int N = 300010;
int n,m;
int a[N],s[N];
vector<int> alls;
vector<PII> add,query;
int find(int x)
{
int l = 0,r = alls.size()-1;
while(l < r)
{
int mid = l + r >>1;
if(alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r+1;
}
//java/python中无unique函数,如何用代码实现
/*
vector<int >::iterator unique(vector<int > &a)
{
int j = 0;
for(int i = 0 ; i < a.size();i++)
if(!i || a[i] != a[i-1])
a[j++] = a[i];
//a[0]~a[j-1] 所有a中不重复的数
return a.begin() + j;
}
*/
int main()
{
cin>>n>>m;
for(int i = 0;i<n;i++)
{
int x,c;
cin>>x>>c;
add.push_back({x,c});
alls.push_back(x);
}
for(int i = 0;i<m;i++)
{
int l,r;
cin>>l>>r;
query.push_back({l,r});
alls.push_back(l);
alls.push_back(r);
}
//去重
sort(alls.begin(),alls.end());
// 使用C++库中unique函数
alls.erase(unique(alls.begin(),alls.end()),alls.end());
//手写后unique函数
//alls.erase(unique(alls),alls.end());
//处理插入
for(auto item : add)
{
int x = find(item.first);
a[x] += item.second;
}
//预处理前缀和
for(int i = 1;i <= alls.size();i++) s[i] = s[i-1] + a[i];
//处理询问
for(auto item : query)
{
int l = find(item.first), r =find(item.second);
cout<< s[r] -s[l-1]<<endl;
}
return 0;
}
区间合并
给定 n 个区间 [li,ri],要求合并所有有交集的区间。
注意如果在端点处相交,也算有交集。
输出合并完成后的区间个数。
例如:[1,3] 和 [2,6] 可以合并为一个区间 [1,6]。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含两个整数 l 和 r。
输出格式
共一行,包含一个整数,表示合并区间完成后的区间个数。
数据范围
1≤n≤100000,
−109≤li≤ri≤109
输入样例:
5
1 2
2 4
5 6
7 8
7 9
输出样例:
3
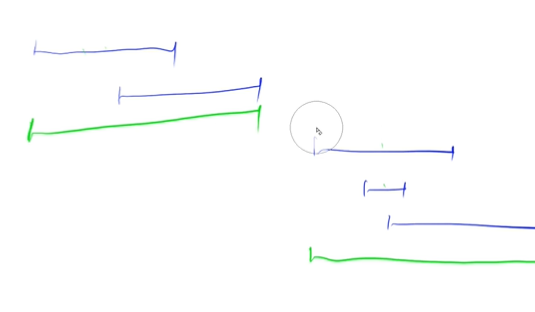
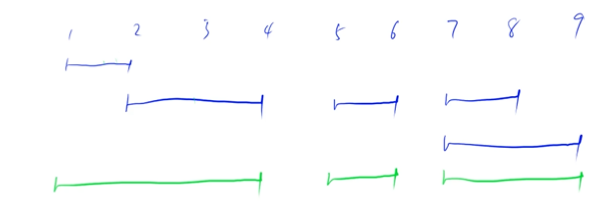
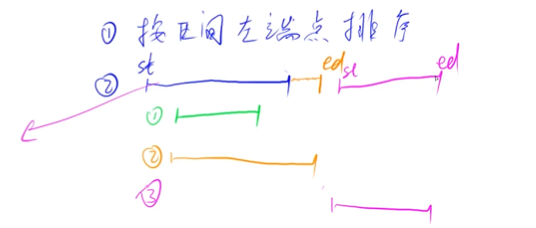
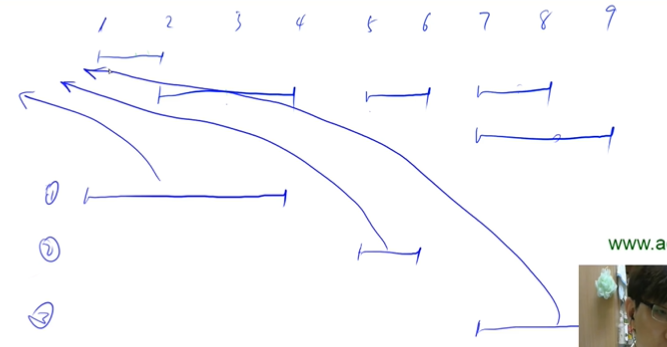
区间合并的思路如下:
- 确定一个标准区间
- 从候选区间中拿出一个比较,可以分为两种情况
- 起始区间在标准区间中
- 起始区间在标准区间外
- 将最后的区间加入至结果中
//Acw版本
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
const int N = 100010;
typedef pair<int,int > PII;
int n;
vector<PII> segs;
void merge(vector<PII> &segs)
{
vector<PII> res; //用于存储合并结果
sort(segs.begin(),segs.end()); //字典序排序,从first元素开始排序
int st = -2e9,ed = -2e9; //一开始虚构的标准区间,只初始化一次,不能添加至结果中
for(auto seg:segs)
{
if(seg.first > ed)
//if(ed < seg.first)
{
if(ed != -2e9) res.push_back({st,ed}); //将区间放置于结果区间中,不能将一开始虚构的区间至于结果中
st = seg.first,ed = seg.second; //区间进行赋值
}
else ed = max(ed,seg.second);
}
if(st != -2e9) res.push_back({st,ed}); //同上
segs = res;
}
int main()
{
cin>>n;
for(int i = 0;i < n;i++)
{
int l,r;
cin>>l>>r;
segs.push_back({l,r});
}
merge(segs);
cout<<segs.size()<<endl;
return 0;
}
自我理解版:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef pair<int,int > PII;
vector<PII> segs;
int n,l,r;
void merge(vector<PII> &segs)
{
vector<PII> res;
int st = -2e9;
int ed = st;
sort(segs.begin(),segs.end());
for(auto seg:segs)
{
if(seg.first > ed)
{
if(ed != -2e9 ) res.push_back({st,ed}); //不能将一开始虚构的区间至于结果中
st = seg.first, ed = seg.second;
}
else
ed = max(seg.second,ed);
}
if(ed != -2e9 ) res.push_back({st,ed}); //同上
segs = res;
}
int main()
{
scanf("%d",&n);
while(n--)
{
scanf("%d%d",&l,&r);
segs.push_back({l,r});
}
merge(segs);
printf("%ld",segs.size());
return 0;
}














 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









