







1.Redis有哪些数据结构
1.String类型,相当于Java中的String,Redis中通过C语言用一种叫做SDS(简单动态字符串)的数据类型实现的,常用
set key value;get key;mset key1 value1 key2 value2;mget key1 key2
2.list列表,相当于Java中的双向链表LinkedList,在数据量少的时候底层使用的是ziplist这种占空间较少的结构,在数据量变多后会用ziplist+指针形成链表,常用
lpush;lpop;rpush;rpop;lrange list start end
3.hash,类似于Java中的HashMap,存储Key-Value键值对,常用
hset key name1 property1 name2 property2;hgetall key;
4.set,类似于Java中HashSet,存储不能重复的value值,常用
sadd;spop
5.sortedset,可以为值保存权重,set可以按权重顺序排序,底层是skiplist跳表,跳表类似于b+树,会一层一层地将代表数据选举出来,便于查询。
常用zadd value score
2.Redis为什么快?
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路 I/O 复用模型,非阻塞 IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
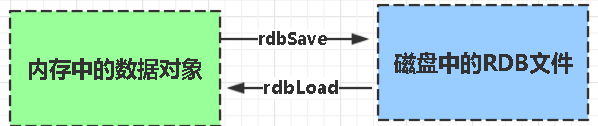
3.Redis持久化方式
1.RDB方式
RDB:是Redis DataBase缩写快照
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
优点:
- 1、只有一个文件 dump.rdb,方便持久化。
- 2、容灾性好,一个文件可以保存到安全的磁盘。
- 3、性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis 的高性能
- 4.相对于数据集大时,比 AOF 的启动效率更高。
缺点:
- 1、数据安全性低。RDB 是间隔
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2668
2668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









