






查找的概念:
查找:在数据集合中查找满足某种条件的数据元素的过程称为查找
查找表(查找结构):用于查找的数据集合成为查找表,它由同一类型的数据元素或记录组成
关键字:数据元素中唯一标识该元素的某个数据项的值,使用基于关键字的查找,查找结果应是唯一的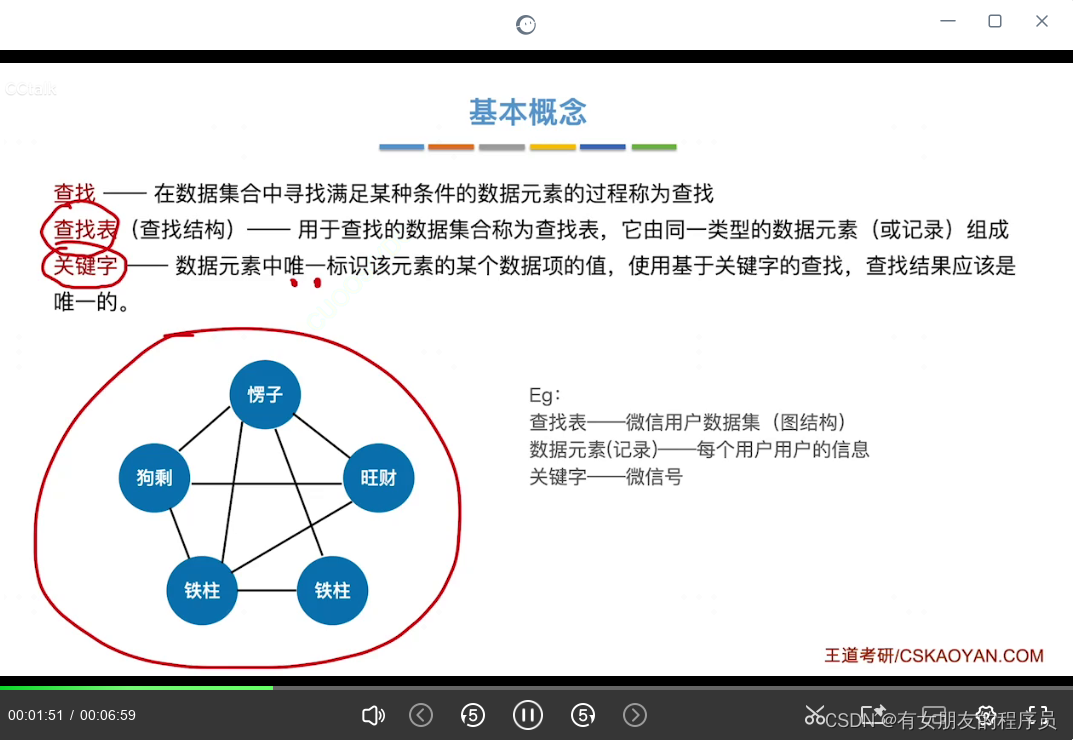
考虑实际使用中的操作效率:

平均查找长度 ASL:
 总结:
总结:
顺序查找的实现:

用查找判定树分析 ASL:
成功结点查找长度:自身所在层数
一个异常的结点查找长度:其父结点所在层数(共有 n+1种查找异常的情况)
默认情况下,各异常情况或成功情况都等概率发生

顺序查找的优化(被查找概率不相等):
将被查概率大的结点放在靠前位置,这样顺序就不保证了,根据实际应用来使用

总结:

折半查找算法思想(二分查找法,适用有序和顺序表):

二分查找法实现逻辑;更好 min的 left和 right的下标值:

二分查找法的效率:

二分查找判定树的构造:二分查找判断树一定是平衡二叉树
右子树结点树 - 左子树结点树 = 0,1(即总结点为 偶数时则最左子树少一个结点)
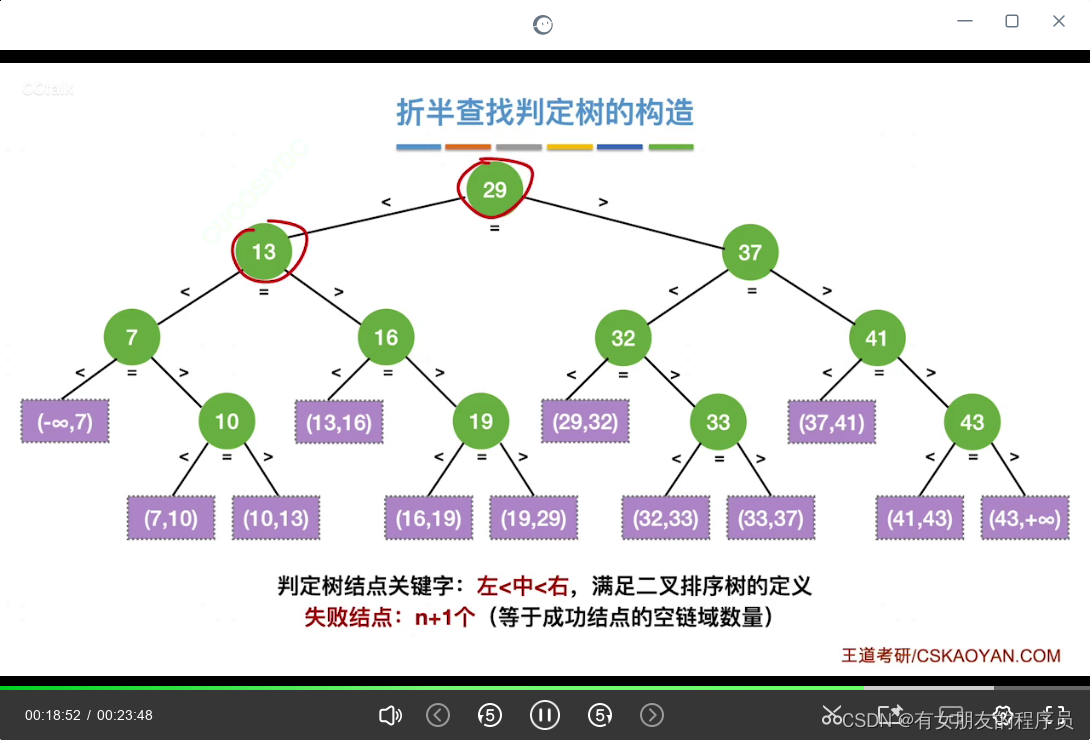
折半查找的查找效率:

总结:

分块查找:

分块查找的算法思想:

索引表中保存的是目标快中最大的索引值,所以目标关键字在索引表中不存在时则以 low>high 的 low所在块区间进行查找,若 low超出查找范围则查找异常
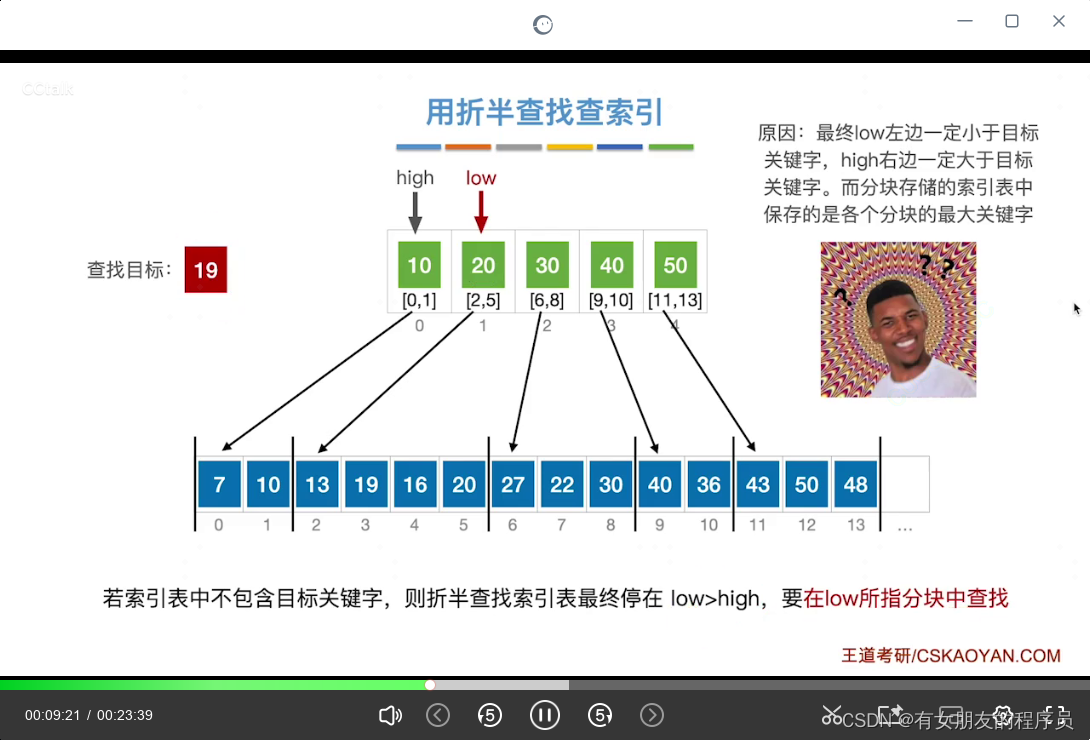
查找效率分析:(ASL)

最优 ASL的结果为:


总结:
二叉排序树的定义(BST):
左子树结点值 < 根结点值 < 右子树结点值:左右子树又是一颗二叉排序树:中序遍历时增序
代码实现部分:

递归代码实现:
二叉排序树的插入:(递归实现 空间复杂度 O(h))用循环方式来删除效果更好

二叉排序树的删除:
二叉排序树用删除结点的直接后继来替代:单前结点的右子树最小的结点(一定没有左子树)来替换删除结点

这样就转换为第一种或第二种情况,把替换删除结点位置结点空出的位置左子树接替上去
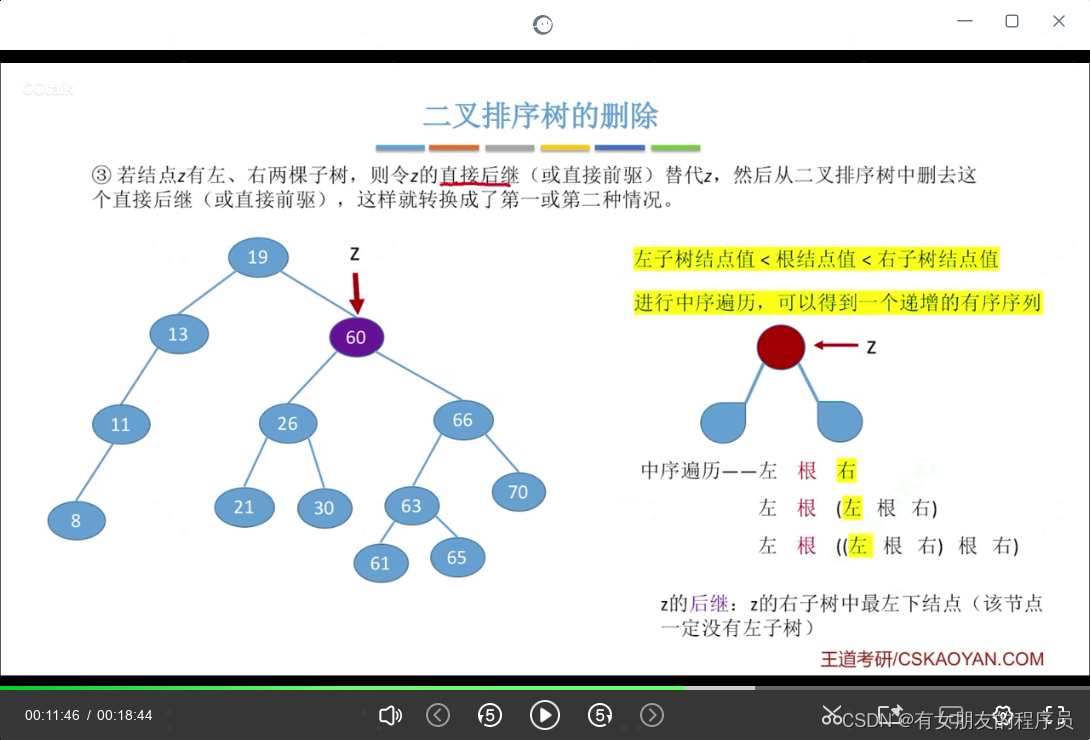
二叉排序树用删除节点的直接前驱来替代:


查找效率分析:使树的高度最小

树的长度最小:平衡二叉树

查找视频的平均查找长度 ASL值:

总结:
平衡二叉树的定义(AVL):
平衡二叉树:树上任一结点的左子树和右子树的高度只差不超过 1(结点的平衡因子 = 左子树的高度-右子树高度)

平衡二叉树的插入
每次调整的对象是:最小不平衡子树 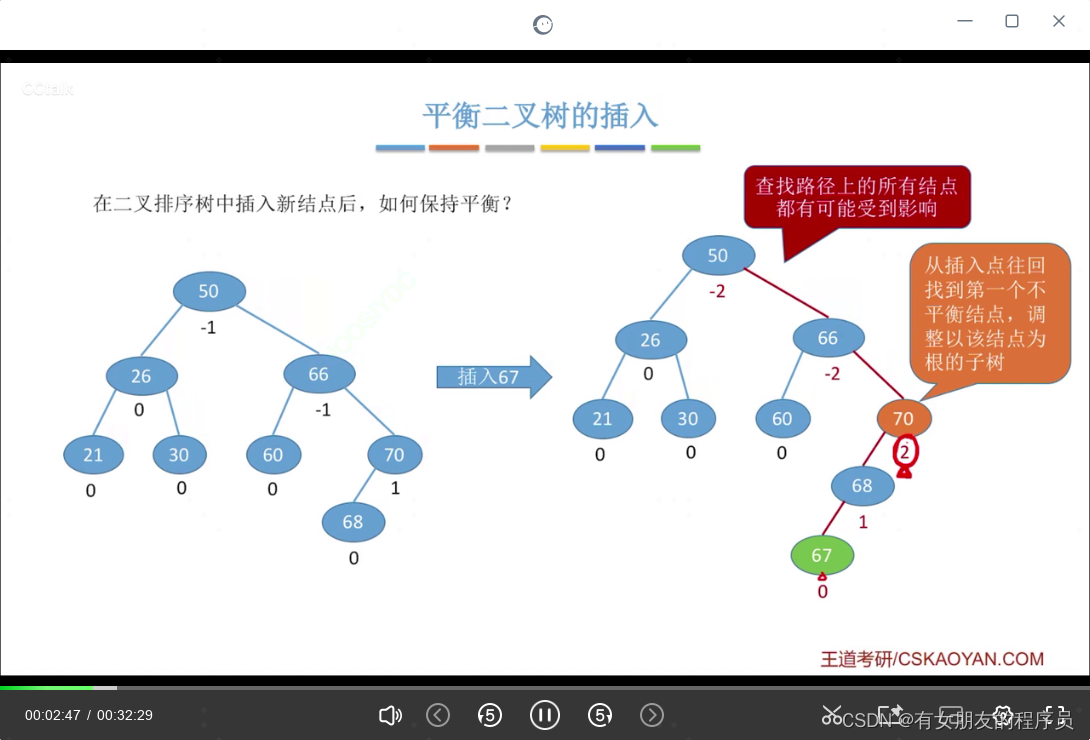
如何调整最小不平衡子树:

调整最小不平衡子树(LL):右旋
右旋操作:由于结点 A的左孩子(L)上插入了新结点,A的平衡因子由 1增至 2,导致以 A为根的子树失去平衡,需要一次向右旋转的操作。将 A的左孩子 B向右上旋转替代 A成为根节点,将 A结点向右下旋转为 B的右子树的根结点,而 B的原右子树则作为 A结点的左子树
调整最小不平衡子树(RR):左旋
左旋操作:由于结点 A的右孩子 (R)的右子树 (R)上插入了新结点,A的平衡因子由 -1减至 -2,导致 以 A为根的子树失去平衡,需要一次向左旋转的操作,将 A的右孩纸 B向左上旋转代替 A成为根结点,将 A结点向左下旋转成为 B的左子树的根结点,而 B的原左子树则作为 A结点的右子树

左旋和右旋代码思路:保持二叉排序树的特点

调整最小不平衡子树:
只有左孩子才能右上旋,只有右孩子才能左上旋转

练习:把最小不平衡子树的高度恢复,那么其他根结点都会恢复平衡

通过 RR的方式来做:

RL:型表示为 整个不平衡树中,右子树的左子树的插入导致的不平衡
总结:
















 2779
2779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









