







1.count(字段)的时候会自动过滤掉字段中值为null的数据行
场景需求,在下面表中想要过滤出来在2021年考试全部完成的学生以及考试的次数
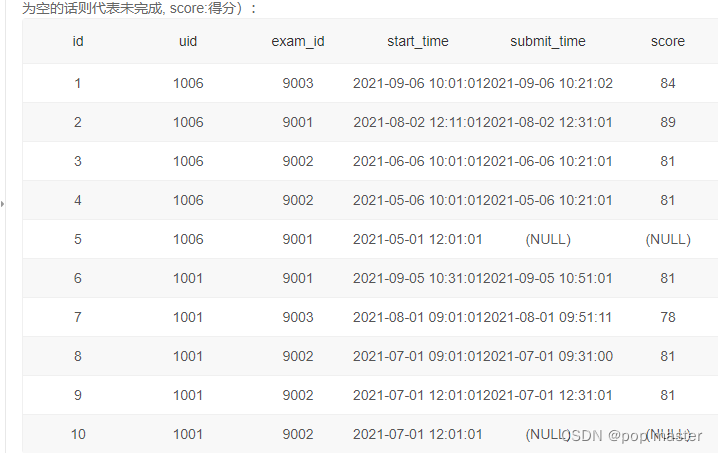
可以使用如下过滤条件将考试未提交的学生筛选出去,count(字段) 是按照该字段中非null的数量来确定的。
count(id) <> count(submit_time)
2. where与having的使用场景
where是在分组前进行过滤的
having是在分组后进行过滤的
使用场景如下所示:
select
uid,
count(uid)
from
(
select
uid,
submit_time,
dense_rank() over(partition by uid order by date_format(start_time,'%Y-%m') desc) as rk_asc
from
exam_record
) a
where
rk_asc <= 3
group by
uid
having
count(uid) = count(submit_time)
order by
count(uid) desc,
uid desc
其中 rk_asc <= 3 是只让排名值为前三个的数据行加入分组
count(uid) = count(submit_time) 是只显示分组后uid计数与submit_time计数一样多的数据
3.在写一些比较复杂的查询语句时,为了使得结构更加清晰,可以使用with tmep_name1 as(查询语句),tmep_name2 as (查询语句)
with
-- SQL试卷中未完成率较高的50%用户,并且用户为6级、7级
tb1 as (
select
d.uid uid,
d.rank_incomplete incomplete
from
(
select
a.uid as uid,
percent_rank() over(order by (count(a.uid)-count(a.score))/count(a.uid) desc) as rank_incomplete,
max(b.level) as user_level
from
exam_record a
left join
user_info b on a.uid = b.uid
left join
examination_info c on a.exam_id = c.exam_id
where
c.tag = 'SQL'
group by
uid
) d
where
d.rank_incomplete <= 0.5 and (user_level = 6 or user_level = 7)
),
-- 试卷答题记录表中近三个月中有答题记录的用户,计算其每个月的答题数量与完成数量
tb2 as (
select
uid,
start_month,
total_cnt,
complete_cnt,
rn_near
from
(
select
uid,
date_format(start_time,'%Y%m') start_month,
count(uid) as total_cnt,
count(score) as complete_cnt,
row_number() over(partition by uid order by date_format(start_time,'%Y%m') desc) as rn_near
from
exam_record
group by
uid,
date_format(start_time,'%Y%m')
) a
where rn_near <= 3
)
-- 将两个查询连接起来获得真正的条件,然后选择字段以及排序
select
b.uid uid,
b.start_month start_month,
b.total_cnt total_cnt,
b.complete_cnt complete_cnt
from
tb1 a,
tb2 b
where
a.uid = b.uid
order by
uid asc,
start_month asc
4. 使用sum的时候可以加上单独的过滤条件
select
tag,
sum(if(DATE_FORMAT(SUBMIT_TIME,'%Y-%m') BETWEEN '2020-01' AND '2020-06',1,0)) exam_cnt_20,
sum(if(DATE_FORMAT(SUBMIT_TIME,'%Y-%m') BETWEEN '2021-01' AND '2021-06',1,0)) exam_cnt_21
from
exam_record a
left join
examination_info b
on a.exam_id = b.exam_id
group by
tag
上述案例就是按照时间对求和进行过滤
5.like与regexp的区别
like 表示后面的表达式是否能匹配上该列的值,例如下面就是取account_name这一列中找’[0-9]'这一个值;
regexp 表示正则匹配,看看该列中的值中的内容是否符合后面的匹配规则,例如下面就是匹配account_name这一列中是否出现0-9之间任意一个值。
SELECT account_name,account_name REGEXP '[0-9]' as reg,account_name like '[0-9]' as lik from promotion_fee_jingdong
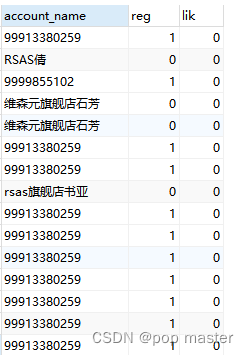
两个表达式都有返回值,匹配的到就是1,匹配不到就是0
具体的匹配规则可以搜索正则匹配进行查看
案例: 在查询中,剔除全部是数字的值
select
'666' regexp '[^0-9]' as reg,
'reg666' regexp '[^0-9]' as reg666

因此可以 通过下面的过滤条件来剔除掉纯数字的值
where (字段 regexp '[^0-9]') = 1
6. 关键字exists和not exists
参考地址:http://t.csdnimg.cn/xnsEN
用于判断主查询中的每条数据,是否在exists查询子句中有一条或多条记录,如果是返回True,否则返回False。
执行流程:
SELECT * FROM A WHERE EXISTS(SELECT * FROM B WHERE A.id = B.id);
1.先执行的是外层的查询,select * from A,然后取一行数据传递给内层查询
2.执行内层查询,根据外层传入的一行数据对内层的查询结果进行匹配,如果有存在A.id = B.id则返回True,否则返回False。
3.如果内查询返回True,则这一行数据保留,如果内层数据返回False则这一行数据不显示
4.外查询的所有数据逐行查询匹对(重复上述1-3步骤,直至所有外查询数据匹对完毕)
exists 和 in 的区别:
# 使用EXISTS方式
SELECT * FROM A WHERE EXISTS(SELECT * FROM B WHERE A.id = B.id);
# 使用IN方式
SELECT * FROM A WHERE id in (select id FROM B)
参考地址:http://t.csdnimg.cn/qYrlU
1.子查询使用 exists,会先进行主查询,将查询到的每行数据循环带入子查询校验是否存在,过滤出整体的返回数据;子查询使用 in,会先进行子查询获取结果集,然后主查询匹配子查询的结果集,返回数据;
2.外表内表相对大小情况不一样时,查询效率不一样:两表大小相当,in 和 exists 差别不大;内表大,用 exists 效率较高;内表小,用 in 效率较高。
3.不管外表与内表的大小,not exists 的效率一般要高于 not in,跟子查询的索引访问类型有关。
7.using关键字作用
USING关键字作用:
1.连接查询时如果是同名字段作为连接条件,using可以代替on出现(比on更好)
2.using 关键字使用后会自动将两个表关联的字段自动合并成同一个字段
select
*
from
A
LEFT JOIN
B using(id)
8.根据指定记录是否存在输出不同情况
实现方式 exists + not exists+ union all
select
A.COUNT
from
A
WHERE EXISTS(
select from b where b.count > 2 and b.level = 0
) and A.level = 1
union all
select
C.COUNT
from
C
WHERE NOT EXISTS(
select from b where b.count > 2 and b.level = 0
) and C.level = 2
通过判断 b表 的条件 count>2 and level = 0 是否有记录,如果有记录那么就输出A.COUNT的数据,如果没有记录就输出C.count的记录。
9.分页的使用
limit [offset] rows
offset:指定第一个返回记录行的偏移量(即从哪一行开始返回),注意:初始行的偏移量为0。
rows:返回具体行数。
# 查看A表中排序后,第七条数据开始的3条数据。
select
ID,NAME
from
A
ORDER BY
ID
LIMIT 6,3
10 mysql实现一个字段拆分成多个字段。
函数:substring_index(字符串,分隔符,第几个分隔符)
其中索引可以为负数
题目
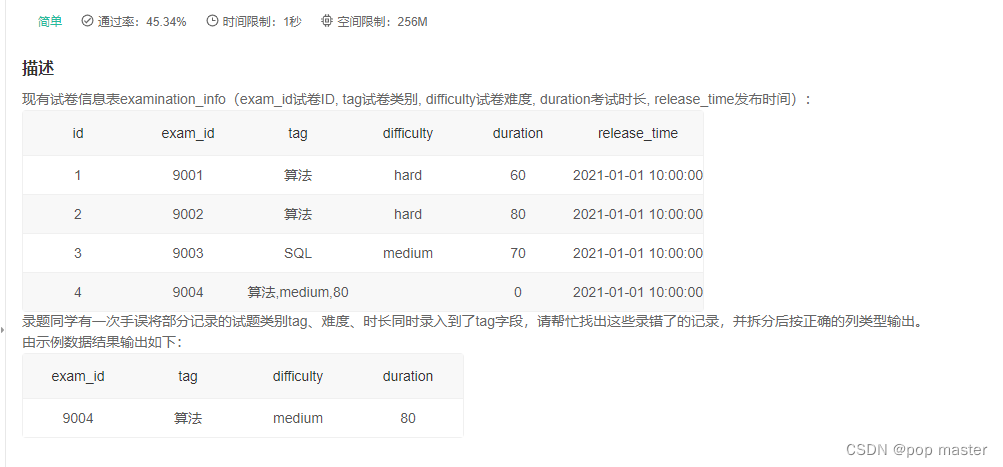
select
exam_id,
substring_index(tag,',',1) as tag,
substring_index(substring_index(tag,',',2),',',-1) as difficulty,
substring_index(tag,',',-1) as duration
from
examination_info
where
tag like '%,%'

11.按照数据行是否满足条件来动态添加关联条件
当a表中第n行的order_num是null那么就让a表的第n行和b表所有的行都进行关联,
(ps:pgsql中使用on(case when then else end)来实现)
select
a.*
from
Orders a
left join
OrderItems b
on if(a.order_num is null,1=1,a.order_num = b.order_num)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









