







编译原理实验报告
实验报告分为三个部分:词法分析,语法分析,语义分析及中间代码生成
词法分析
实验目的
通过扩充已有的样例语言TINY语言的词法分析程序,为扩展TINY语言TINY+构造词法分析程序,从而掌握词法分析程序的构造方法
实验内容
了解样例语言TINY及TINY编译器的实现,了解扩展TINY语言TINY+,用C语言在已有的TINY词法分析器基础上扩展,构造TINY+的词法分析程序。
实验要求
将TINY+源程序翻译成对应的TOKEN序列,并能检查一定的词法错误。
Tiny Plus
Tiny+语言是在Tiny语言的基础上进行扩充的,下面简单描述一下tiny语言。
Here is the definition for Tiny language
- Keywords: IF ELSE WRITE READ RETURN BEGIN END MAIN INT REAL
- Single-character separators: ; , ( )
- Single-character operators:+ - * /
- Multi-character operators::= == !=
- Identifier: An identifier consists of a letter followed by any number of letters or digits. The following are examples of identifiers: x, x2, xx2, x2x, End, END2. Note that End is an identifier while END is a keyword. The following are not identifiers:
- IF, WRITE, READ, … (keywords are not counted as identifiers)
- 2x (identifier can not start with a digit)
- Strings in comments are not identifiers.
- Number is a sequence of digits, or a sequence of digits followed by a dot, and followed by digits.
Number -> Digits | Digits '.' Digits Digits -> Digit | Digit Digits Digit -> '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9' - Comments: string between /** and **/. Comments can be longer than one line.
The EBNF Grammar
-
High-level program structures
Program -> MethodDecl MethodDecl* MethodDecl -> Type [MAIN] Id '(' FormalParams ')' Block FormalParams -> [FormalParam ( ',' FormalParam )* ] FormalParam -> Type Id Type -> INT | REAL -
Statements
Block -> BEGIN Statement* END Statement -> Block | LocalVarDecl | AssignStmt | ReturnStmt | IfStmt | WriteStmt | ReadStmt LocalVarDecl -> INT Id ';' | REAL Id ';' AssignStmt -> Id := Expression ';' ReturnStmt -> RETURN Expression ';' IfStmt -> IF '(' BoolExpression ')' Statement | IF '(' BoolExpression ')' Statement ELSE Statement WriteStmt -> WRITE '(' Expression ',' QString ')' ';' ReadStmt -> READ '(' Id ',' QString ')' ';' QString is any sequence of characters except double quote itself, enclosed in double quotes. -
Expressions
Expression -> MultiplicativeExpr (( '+' | '-' ) MultiplicativeExpr)* MultiplicativeExpr -> PrimaryExpr (( '*' | '/' ) PrimaryExpr)* PrimaryExpr -> Num // Integer or Real numbers | Id | '(' Expression ')' | Id '(' ActualParams ')' BoolExpression -> Expression '==' Expression |Expression '!=' Expression ActualParams -> [Expression ( ',' Expression)*]
Tiny Plus在TINY语言的基础上进行了以下扩充:
增加关键字与单字符运算符:
- Keywords: WHILE 、DO、FOR、UPTO、DOWNTO
- Single-character operators:%(求余运算),<,>(比较运算符)
EBNF Grammar也进行了如下修改:
Statement -> Block
| LocalVarDecl
| AssignStmt
| ReturnStmt
| IfStmt
| WriteStmt
| ReadStmt
| WhileStmt
| DoWhileStmt
| ForStmt
WhileStmt -> WHILE '(' BoolExpression ')' Statement
DoWhileStmt -> DO Statement WHILE '(' BoolExpression ')'
ForStmt -> For AssignStmt UPTO Expression DO Statement
| For AssignStmt DOWNTO Expression DO Statement
MultiplicativeExpr -> PrimaryExpr (( '*' | '/' | '%' ) PrimaryExpr)*
BoolExpression -> Expression '==' Expression
| Expression '!=' Expression
| Expression '>' Expression
| Expression '<' Expression
DFA
// DFA的状态
typedef enum {
STATUS_START,
STATUS_ASSIGN,
STATUS_EQUAL,
STATUS_UNEQUAL,
STATUS_COMMENT,
STATUS_NUMBER,
STATUS_REAL,
STATUS_STR,
STATUS_ID,
STATUS_DONE
}lexStatus;
识别Token的主要过程是在确定的有限自动机的状态之间进行切换,通过检查下一个扫描的字符决定跳转到哪个状态。
例如,初始状态为STATUS_START,此时如果读取到的下一个字符为数字,根据Tiny+语言的词法定义,以数字开头的只可能为数字,所以,我们跳转到STATUS_NUMBER状态。进入该状态后,如果下一个字符还是数字,意味着这个数字还没结束,因此保持当前DFA状态不变。当得到的下一个字符为小数点.,就跳转到STATUS_REAL状态,表示可以确定这个数为小数;如果既不是数字也不是小数点,而是字母,这就意味着违反了标识符不能以数字开头的规定,把当前token设为ERROR,否则设为 NUM ,跳转到STATUS_DONE状态,意味着当前的TOKEN读取完毕,打印当前TOKEN即可,或对于ERROR进行处理。在STATUS_REAL状态中,我们只要读取到不是数字就马上结束,跳转到STATUS_DONE状态,因为不会有两个小数点。
特别的,在状态机中,我们不特别区分标识符和保留字,而是统一的跳转到STATUS_ID状态,只需要在最后查找一下识别得到的字符串是不是保留字即可。
- 词法要求
- 关键词必须以字母开头
- 字符不能包含在数字中
- 注释用方括号括起来,不能嵌套,但可以包含不止一行
- 字符串用单引号括起来
- 错误检查
- ALPHA_AFTER_NUMBER_ERROR 字母紧接数字错误
- ASSIGN_LEXICAL_ERROR 赋值符号没有打全错误
- SINGLE_QUOTES_MISSING_FOR_STRING_ERROR 字符串缺失单引号错误
- LEFT_BRACE_MISSING_FOR_COMMENTS_ERROR 注释左大括号缺失错误
- RIGHT_BRACE_MISSING_FOR_COMMENTS_ERROR 注释右大括号缺失错误
- ILLEGAL_CHARACTER非法字符
Token typeToken一共分成五类:
typedef enum
{
ENDFILE,
ERROR,
TK_TRUE, //true
TK_FALSE, //false
OR, //or
AND, //and
NOT, //not
INT, //int
BOOL, //bool
TK_STRING, //string
WHILE, //while
DO, //do
IF, //if
THEN, //then
ELSE, //else
END, //end
REPEAT, //repeat
UNTIL, //until
READ, //read
WRITE, //write
/**Multi-character tokens**/
ID, //标识符
NUM, //数字
STRING, //字符串常量
/**Special Symbols**/
GTR, // >
LEQ, // <=
GEQ, // >=
COMMA, // ,
SEMICOLON, // ;
ASSIGN, // :=
ADD, // +
SUB, // -
MUL, // *
DIV, // 除号
LP, // (
RP, // )
LSS, // <
EQU // ==
} TokenType;
词法分析scan.c文件的主函数为:getToken(),著函数的实现原理为:通过DFA的状态转换判断指向的Token的类型,然后将其交给打印函数打印出来即可。
getToken()逐个处理源程序中的词法单元,只要DNF的状态不为success或者failed,具体代码见词法分析源文件。
打印Token Flow
Token Flow输出打印的原理是每次要打印一个词法单元就调用一次,参数为词法分析程序所识别到的Token type,如果是关键字等需要打印字符的也需传参。
测试
对如下tiny源程序进行词法分析结果:
int x,fact,A,B,C,D;
bool y;
string z;
{This is a comment.}
read x;
repeat
A:=A*2
until (A+C) < (B+D);
while (A+B+C) < 10 do
B := B + 3
end;
if x < 10 and x > 5 or x < 9 then
fact := 4
else
fact := 6
end;
TOKEN FLOW:
(KEY, int)
(ID, x)
(COMMA, ,)
(ID, fact)
(COMMA, ,)
(ID, A)
(COMMA, ,)
(ID, B)
(COMMA, ,)
(ID, C)
(COMMA, ,)
(ID, D)
(SEMICOLON, ;)
(KEY, bool)
(ID, y)
(SEMICOLON, ;)
(STR, string)
(ID, z)
(SEMICOLON, ;)
(KEY, read)
(ID, x)
(SEMICOLON, ;)
(KEY, repeat)
(ID, A)
(ASSIGN, :=)
(ID, A)
(MUL, *)
(NUM, 2)
(KEY, until)
(LP, ()
(ID, A)
(ADD, +)
(ID, C)
(RP, ))
(LSS, <)
(LP, ()
(ID, B)
(ADD, +)
(ID, D)
(RP, ))
(SEMICOLON, ;)
(KEY, while)
(LP, ()
(ID, A)
(ADD, +)
(ID, B)
(ADD, +)
(ID, C)
(RP, ))
(LSS, <)
(NUM, 10)
(KEY, do)
(ID, B)
(ASSIGN, :=)
(ID, B)
(ADD, +)
(NUM, 3)
(KEY, end)
(SEMICOLON, ;)
(KEY, if)
(ID, x)
(LSS, <)
(NUM, 10)
(KEY, and)
(ID, x)
(GTR, >)
(NUM, 5)
(KEY, or)
(ID, x)
(LSS, <)
(NUM, 9)
(KEY, then)
(ID, fact)
(ASSIGN, :=)
(NUM, 4)
(KEY, else)
(ID, fact)
(ASSIGN, :=)
(NUM, 6)
(KEY, end)
(SEMICOLON, ;)
基本词法错误检查能力检测:
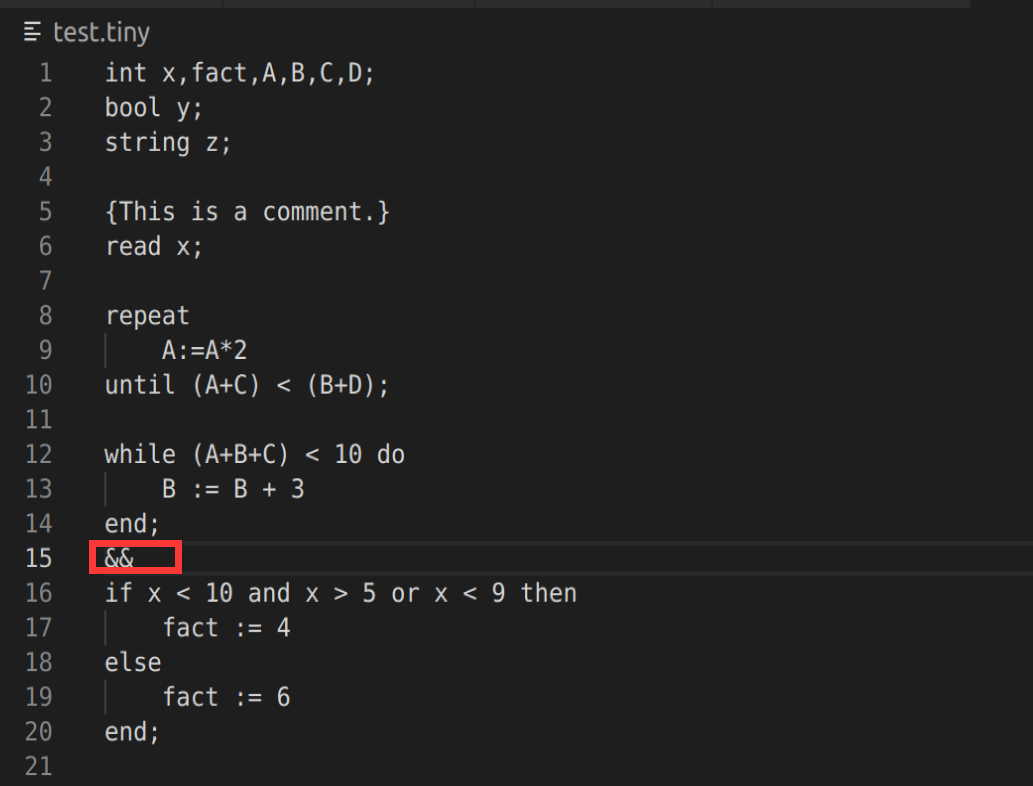
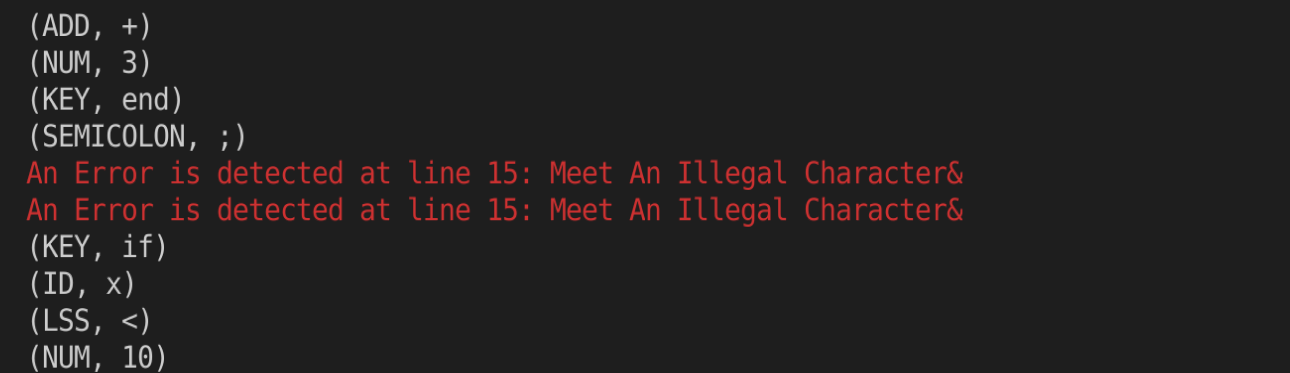
语法分析
实验目的:
为扩展TINY语言TINY+构造语法分析程序,从而掌握语法分析程序的构造方法
实验内容:
用EBNF描述TINY+的语法,构造TINY+的语法分析器
实验要求:
将TOKEN序列转换成语法分析树,并能检查一定的语法错误
语法EBNF范式定义如下:
- program -> declarations stmt-sequence
- declarations ->decl ;declarations |ε
- decl -> type-specifier varlist
- type-specifier ->int| bool |char
- varlist -> identifier { , identifier }
- stmt-sequence -> statement {; statement }
- statement ->if-stmt | repeat-stmt | assign-stmt | read-stmt | write-stmt | while-stmt
- while-stmt-> while bool-exp do stmt-sequence end
- if-stmt -> if bool-exp then stmt-sequence [else stmt-sequence]end
- repeat-stmt-> repeat stmt-sequence until bool-exp
- assign-stmt -> identifier:=exp
- read-stmt ->read identifier
- write-stmt -> writeexp
- exp -> arithmetic-exp | bool-exp | string-exp
- arithmetic-exp -> term { addop term }
- addop -> + | -
- term ->factor { mulop factor }
- mulop -> * | /
- factor ->(arithmetic-exp) | number | identifier
- bool-exp -> bterm { or bterm }
- bterm -> bfactor { and bfactor}
- bfactor ->comparison-exp
- comparison-exp -> arithmetic-exp comparison-oparithmetic-exp
- comparison-op -> < | = | > | >= | <=
- tring-exp-> string
实现
语法分析的实现采用自顶向下分析方法,使用预测分析法,向前看一个词法单元来确定对于某个非终结符号将要选择的产生式,然后采用递归的方式不断地对非终结符号展开其产生式,最终得到一颗语法树。
节点及节点类型定义
typedef enum { MethodK, TypeK, ParamK, StmtK, ExpK } NodeKind;
typedef enum { MainK, NormalK } MethodKind;
typedef enum { FormalK, ActualK, NoneK } ParamKind;
typedef enum { ReturnTypeK, IntTypeK, RealTypeK } TypeKind;
typedef enum { IfK, WhileK, DoWhileK, ForK, ReturnK, AssignK, ReadK, WriteK, IntDeclareK, RealDeclareK } StmtKind;
typedef enum { OpK, ConstK, IdK, MethodCallK} ExpKind;
// 语法分析树结构体 - 多叉树
typedef struct
{
struct TreeNode* child[MAXCHILDREN]; // 当前函数子树
struct TreeNode* sibling; // 指向下一个函数
NodeKind nodekind; // 节点类型
union { MethodKind method; TypeKind type; StmtKind stmt; ExpKind exp; } kind; // 子类型
union {
TokenType token;
int val;
char * name;
} attr;
}TreeNode;
语法树的构建
语法树的构建需要与词法分析同时进行,在语法分析实现函数中,调用getToken()函数来得到一个词法单元,将其构建为语法树的一个节点,再将其安插在合理的树位置上。
在主函数中,调用了MethodDecl_Sequence()函数,该函数会调用MethodDecl()函数,创建函数串联起来,而MethodDecl()函数,又会向下进一步调用Block()……通过这样的方式,就实现了自顶向下的语法分析。
static TreeNode* Statement(void) {
TreeNode* t = NULL;
switch (token) {
case BEGIN: t = Block(); break;
case INT: t = IntLocalVarDeclStmt(); break;
case REAL: t = RealLocalVarDeclStmt(); break;
case ID: t = AssignStmt(); break;
case RETURN: t = ReturnStmt(); break;
case IF: t = IfStmt(); break;
case WHILE: t = WhileStmt(); break;
case DO: t = DoWhileStmt(); break;
case FOR: t = ForStmt(); break;
case WRITE: t = WriteStmt(); break;
case READ: t = ReadStmt(); break;
default:
syntaxError("Unexpected token");
break;
}
return t;
}
该函数用于展开Statement,经过对于语法的分析,对于以Statement为产生式头的产生式体,不存在左公因子,这也就意味着,我们通过向前看一位(即预测)的方式,就可以确定使用哪个产生式,进而进一步展开了。上述函数的实现就是这个道理,函数中token已经是预测得到的结果。而对于产生式体中不存在的token,会直接报错。
语法错误检查
- 语法结构的开始符号以及跟随符号错误;
- 标识符错误,例如在程序的变量声明中,关键字int 后没有跟随标识符;
- 括号不匹配的错误,例如左括号(和右括号 )不匹配。
- 符号错误,例如赋值语句中要求使用的正确符号是‘:=’,而在关系比较表达式要求使用的正确符号是‘=’。
语法树的打印
对于整棵树的打印,我按照类似于先序遍历的方式打印节点,这样的顺序可以较好的还原源程序的执行顺序,同时所有的子节点会相对于父节点有一定的缩进,以更好的显示树的层次。具体见源代码中的printTree()函数,该函数根据不同的节点类型,执行不同的打印策略。
错误检测与定位
本程序在实现上述词法分析和语法分析两大功能的同时,还实现了对于错误的一定程度上的检测,不仅可以提示错误的相关类型,还可以定位错误到行、列。
在parser.h文件中声明函数,针对不同的语句,采用不同的创造节点的创操作并在parser.c中实现。具体实现太过繁杂,代码量太大就不在报告中赘述了。
TreeNode *mul_exp();
TreeNode *add_exp();
TreeNode *stmt_sequence();
TreeNode *read_stmt();
TreeNode *logical_and_exp();
TreeNode *program();
TreeNode *assign_stmt(Token id_token);
TreeNode *factor();
TreeNode *logical_or_exp();
TreeNode *if_stmt();
TreeNode *write_stmt();
TreeNode *repeat_stmt();
TreeNode *declarations();
TreeNode *comparison_exp();
TreeNode *while_stmt();
最后,在main函数中调用parser()进行语法分析,返回其root节点,调用printTree函
数进行打印。首先,解决打印空格的问题,需要根据节点的遍历情况改变空格打印的数量。
void printError(const int &error_code, const int &lineno, char *error_details)
{
printf("\033[1;;31mAn Error is detected at line %d: %s \033[0m\n", lineno,
error_items[error_code].error_description.c_str());
if (error_code != SEMANTIC_MISSING_SEMICOLON)
has_error = true;
}
在打印的循环中调用INDENT和UNINDENT就可以控制printSpaces的数量。
然后,就可以开始前序遍历整棵语法树了。
结果测试:
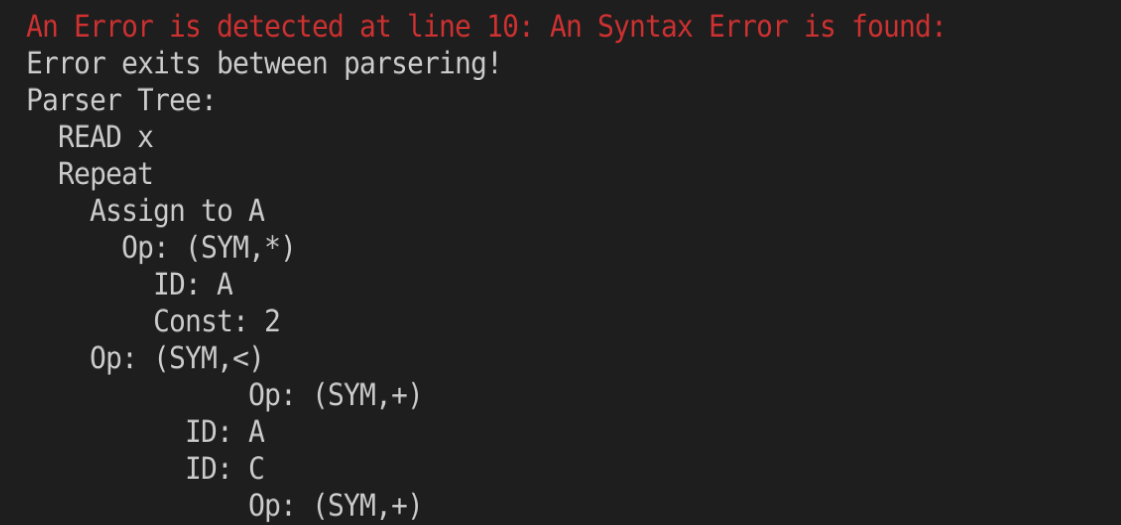
对如下tiny源程序进行语法分析结果:
int x,fact,A,B,C,D;
bool y;
string z;
{This is a comment.}
read x;
repeat
A:=A*2
until (A+C) < (B+D);
while (A+B+C) < 10 do
B := B + 3
end;
if x < 10 and x > 5 or x < 9 then
fact := 4
else
fact := 6
end;
Parser Tree:
READ x
Repeat
Assign to A
Op: (SYM,*)
ID: A
Const: 2
Op: (SYM,<)
Op: (SYM,+)
ID: A
ID: C
Op: (SYM,+)
ID: B
ID: D
While
Op: (SYM,<)
Op: (SYM,+)
ID: A
Op: (SYM,+)
ID: B
ID: C
Const: 10
Assign to B
Op: (SYM,+)
ID: B
Const: 3
If
LogicOp: (KEY,or)
LogicOp: (KEY,and)
Op: (SYM,<)
ID: x
Const: 10
Op: (SYM,>)
ID: x
Const: 5
Op: (SYM,<)
ID: x
Const: 9
Assign to fact
Const: 4
Assign to fact
Const: 6
Parser Analysis Done!
错误测试
删除;
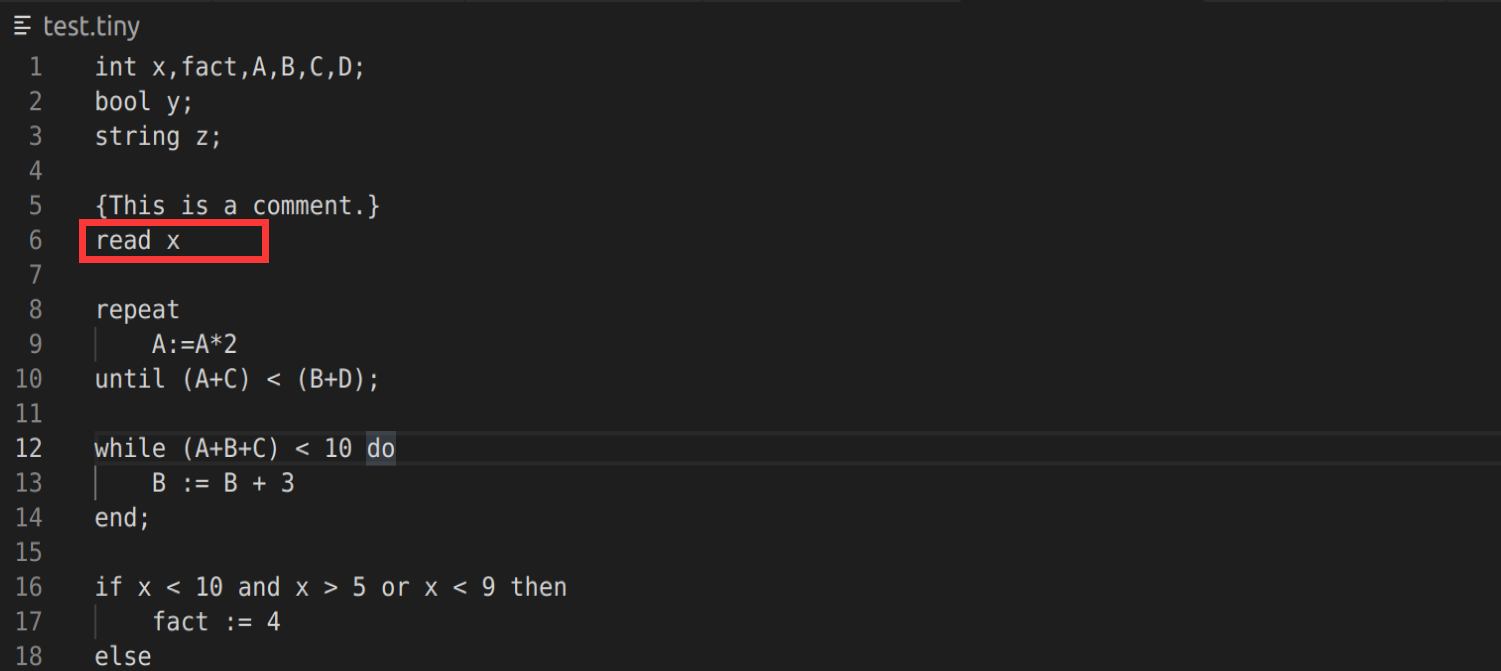

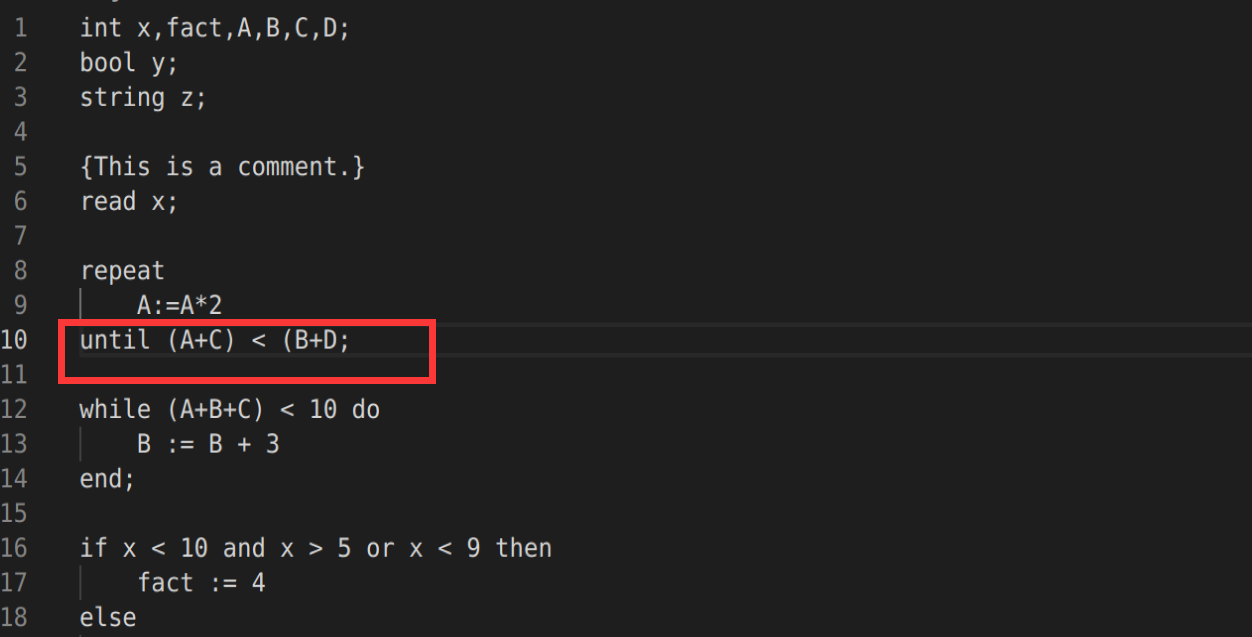
语义分析及中间代码生成
实验目的:
构造TINY+的语义分析程序并生成中间代码
实验内容:
构造符号表,构造TINY+的语义分析器,构造TINY+的中间代码生成器
实验要求:
能检查一定的语义错误,将TINY+程序转换成三地址中间代码。
实现
一个用TINY+语言编写的程序包括变量的声明和语句序列两个部分。变量声明部分可以为空,但一个TINY+程序至少要包含一条语句。
- 所有的变量在使用之前必须声明,并且每个变量只能被声明一次。
- 变量以及表达式的类型可以是整型int,布尔类型bool或者字符串类型char,必须对变量的使用和表达式进行类型检查。
构建语义分析器主要包括 :
- 符号表的设计以及符号表的相应操作
- 符号表保存信息:变量的地址信息、变量被访问的行号
- 变量以其变量名ID,通过链式hash储存查找到相应数据。
- 语义分析程序本身的操作,包括符号表的构建以及类型检查。
- 符号表的创建:
- 前序遍历语法树:
当遇到定义的语法结点时候,将其变量新增到哈希表中,并存储其行号位置;遇到含有变量的非定义语句的结点时,查找该变量位于哈希表中的位置,将该行号储存到哈希相应表项的next位置。
- 符号表的创建:
类型检查:
-
后续遍历语法树,对每一个结点进行语义判断:
- if语句结点中,if-test(child[0])的类型必定为boolean,
- while语句结点中,while-test(child[0])的类型必定为boolean
- op算术运算结点中,child[0]、child[1]必须为integer类型
- op逻辑运算结点中,child[0]、child[1]必须为boolean
- 赋值运算结点中,child[0]、child[1]的类型必须一致
-
在后续遍历语法树中,查看变量是否非法使用:
- 当结点为ID结点时候,在哈希表中查看是否已经定义。
- 如果该结点为定义语句结点,则判断此变量是否重复定义。
- 如果该变量已经定义,则将变量的type(类型)赋于定义时候的类型
- 进入上一层遍历,当其类型不符合上一层所需类型时候提示错误。(即如在赋值语句中,该变量的类型与赋值语句另一个子节点的类型不一致,提示语义错误)。
三地址中间代码生成
-
原tiny中间代码生成器的实现位于cgen.c和cgen.h中。其接口为codeGen(TreeNode* syntaxTree,char* codefile).主要功能为:
- 函数的开始,产生一些注释以及建立运行时环境的指令。
- 对语法树调用cGen函数,对每一个语法树结点生成相应指令
- Tiny+在tiny的基础上进行修改。其中codeGen函数将保持不变,修改其cGen函数即可,详细修改部分见后面实验过程。
三地址中间代码优化
-
删除没有goto到的label
-
删除goto和同一个label紧接着的语句块
语义分析 -
语义错误检查
- SEMANTIC_COND_BOOL_ERROR 条件判断语句必须是BOOL类
- SEMANTIC_UNDEFINED_IDENTIFIER 未定义的变量
- SEMANTIC_OPERATION_BETWEEN_DIFFERENT_TYPES 符号用于不同的数据类型之间
- SEMANTIC_TYPE_CANNOT_BE_OPERATED 该类型不能用于该运算符
- SEMANTIC_CANNOT_ASSIGN_DIFFERENT_TYPE 不能赋予不同类型的值
- SEMANTIC_ILLEGAL_CHARACTER 语义分析中遇到的非法字符
- SEMANTIC_MISSING_SEMICOLON 缺少末尾的双引号
- SEMANTIC_MULTIPLE_DECLARATIONS 多次声明
构建符号表
先在之前语法树的基础上前序遍历语法树构建符号表,我这里是直接添加在了之前的语法分析的parser.cpp 之中,利用符号表类实现的插入,查询等操作,可以很快实现构建。具体代码见文件
语义分析检查
根据上面的实现思路,后序遍历语法树,对于不同的节点不同的语句都要进行
分类,讨论其语义的正确性。
生成中间代码
生成中间代码我是在generate.h和generate.cpp中实现的。利用之前的parser
函数获取语法树根节点,然后对其进行后序遍历。而为了便于中间代码生成的实现我还定义MidCodeVec类来存放中间代码。那么生成完毕输出就十分简单遍历就行了。而且其中还构造了许多功能函数可用于删除不必要的中间代码进行优化。
测试
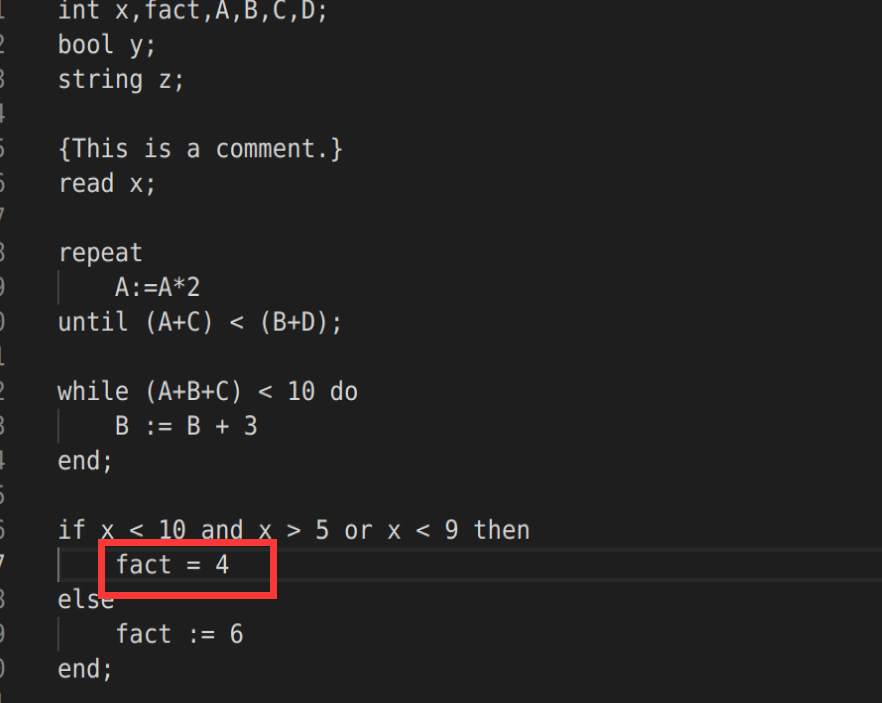
对如下tiny源程序进行语义分析及中间代码生成结果:
int x,fact,A,B,C,D;
bool y;
string z;
{This is a comment.}
read x;
repeat
A:=A*2
until (A+C) < (B+D);
while (A+B+C) < 10 do
B := B + 3
end;
if x < 10 and x > 5 or x < 9 then
fact := 4
else
fact := 6
end;
Semantic Analysis:
Variable Type ValType
------------------------
A Value Int
B Value Int
C Value Int
D Value Int
fact Value Int
x Value Int
y Value Bool
z Value Str
1) read x
2) Label L1
3) t0:=A*2
4) A:=t0
5) t1:=A+C
6) t2:=B+D
7) Label L2
8) if t1<t2 goto L3
9) goto L1
10) Label L3
11) t3:=B+C
12) t4:=A+t3
13) Label L4
14) if t4<10 goto L4
15) goto L6
16) Label L5
17) t5:=B+3
18) B:=t5
19) goto L4
20) Label L6
21) Label L7
22) if x<10 goto L8
23) goto L9
24) Label L8
25) if x>5 goto L10
26) goto L9
27) Label L9
28) if x<9 goto L10
29) goto L11
30) Label L10
31) fact:=4
32) goto L12
33) Label L11
34) fact:=6
35) Label L12
Semantic Analysis Done!
错误测试
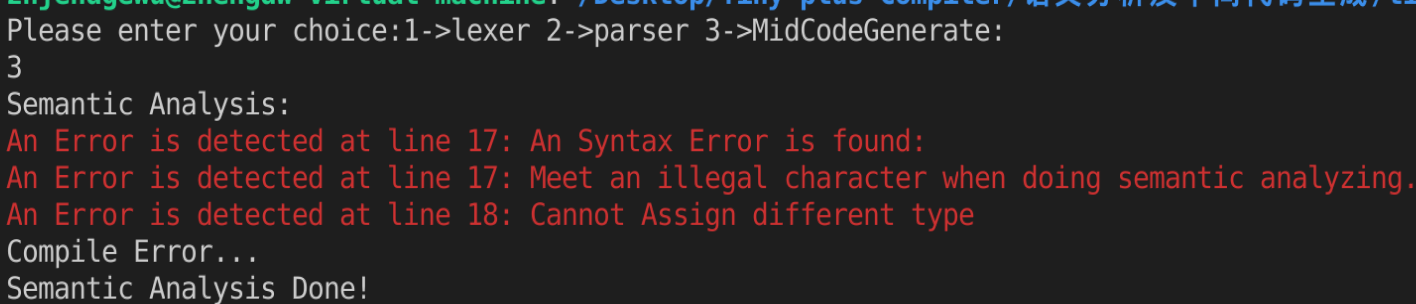















 2222
2222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









