







大家好我是木木,只从2022年11月30日发布ChatGPT后,大模型迅速火热起来,人工智能作为当下最火的行业之一,很多人对它充满了好奇,上一篇文章使用鸢尾花进行KNN初体验,在体验过程中使用到数据切分:将一个数据集按照一定比例划分为多个子集。接下来我们手动实现train_test_split方法,本次主要实现方法功能,不对方法中的信息做相关的逻辑判断。
train_test_split是一个sklearn机器学习库中的一个方法,使用方法通过from sklearn.model_selection import train_test_split进行导入。
train_test_split方法里面有一些常用参数:
X:输入的特征
y:输入的标签与X特征样本数据一一对应
test_size:一般是0.1-1之前,如设置为0.8,那么80%用于训练、20%测试集用于评估模型的性能
shuffle:用于确定是否需要去打乱数据集
random_state:设置随机种子。确保每次结果得到的结果相同,一般做实验都是通过相同的数据做比较判断。
初版train_test_split方法:不带随机数——实现分割数据方法
import numpy as np
#初版:不带随机数——实现分割数据集方法
def train_test_split(X, y, test_size=1):
n_samples = X.shape[0]
test_size = int(n_samples * test_size)
train_size = n_samples - test_size
X_train = X[:train_size,:]
X_test = X[train_size:,:]
y_train = y[:train_size]
y_test = y[train_size:]
return X_train, X_test, y_train, y_test验证测试:
特征和标签切分之后是否还是一一对应,是否有特征和标签的错乱。
#生成X和y的特征与标签,并进行数据集划分
X = np.random.randn(50, 4)
y = np.random.randn(50)
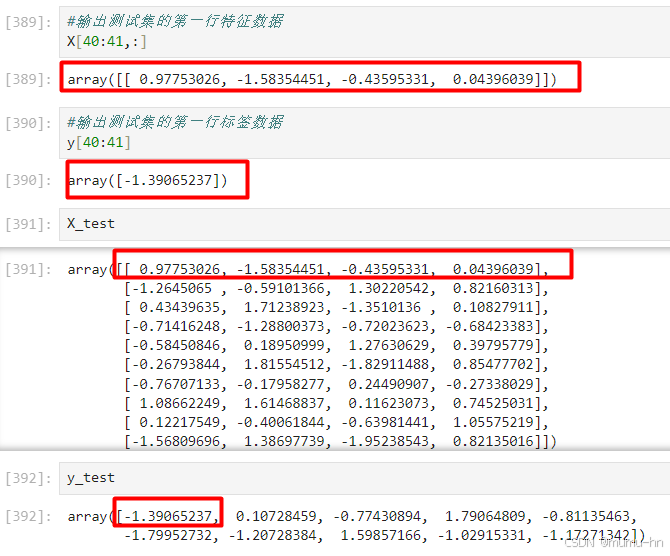
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.8)通过图片可以看到,数据集分为训练和测试,测试集占20%,那么测试集的数据(50*0.8=40)从40行到最后。
通过获得原始数据X的40行与y的40行的输出结果和直接输出X和y的测试集中返回的第一个结果的值相同,如此我们可以判断我们的初版train_test_split方法实现完成。
通过上面的初版,我们手动实现数据集切分的方法,但缺少部分参数,用于打乱数据集和固定随机种子,接下来我们继续优化。
第二版:带随机数——实现分割数据集方法
#第二版:带随机数——实现分割数据集方法
def train_test_split(X, y, test_size=1, random_size=0, shuffle=True):
if shuffle:
# 生成随机索引数组
indices = np.arange(len(y))
# 创建随机数生成器实例并设置种子以确保结果可重复
rng = np.random.RandomState(seed=random_size)
# 打乱索引数组的顺序
rng.shuffle(indices)
# 使用打乱后的索引数组来打乱数据集X和y的顺序
X_shuffled = X[indices,:]
y_shuffled = y[indices]
n_samples = X.shape[0]
test_size = int(n_samples * test_size)
train_size = n_samples - test_size
X_train = X[:train_size,:]
X_test = X[train_size:,:]
y_train = y[:train_size]
y_test = y[train_size:]
return X_train, X_test, y_train, y_test
验证测试:
完成train_test_split方法的优化,对功能进行验证测试,看分割完的数据中特征和标签是否还是一致,有没有错乱。
X = np.random.randn(30,4)
y = np.random.randn(30)
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.8,shuffle=True)如图左边为原始数据集;右边为打乱后的数据集展示
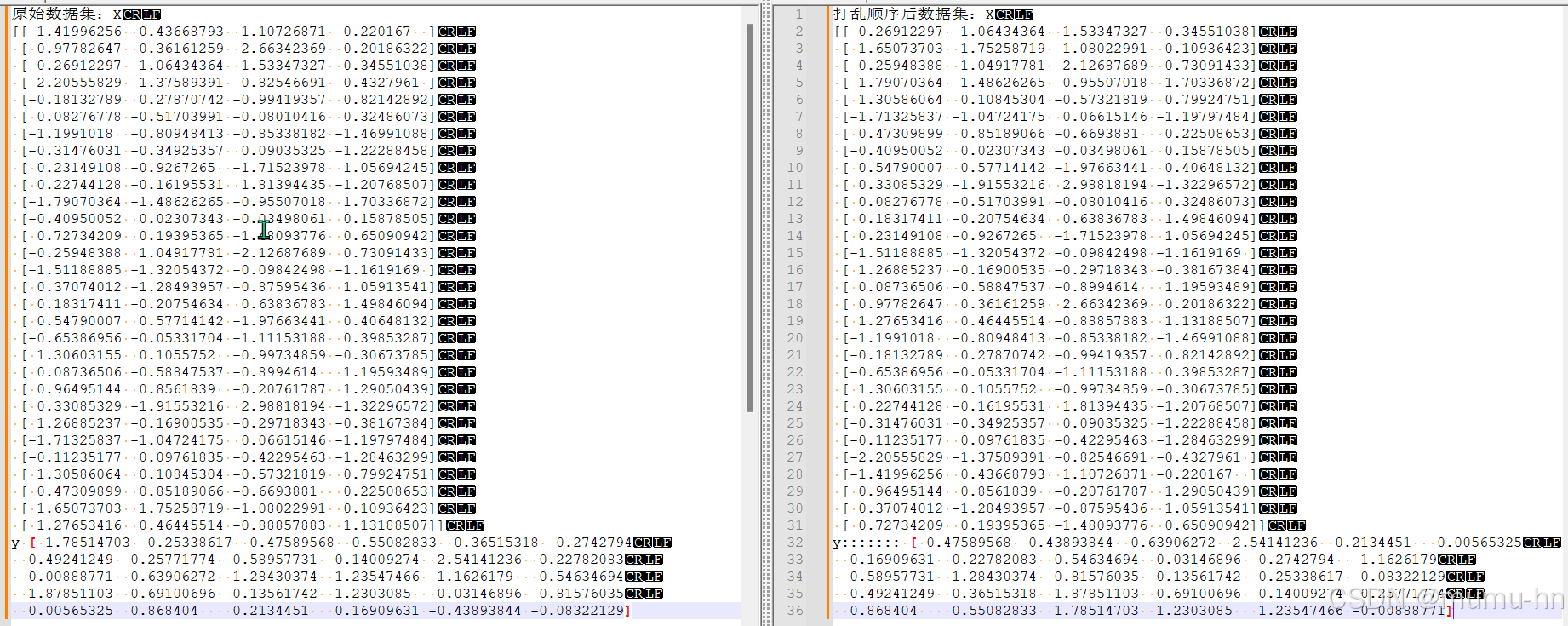
验证打乱后的数据集中特征和标签是否一致
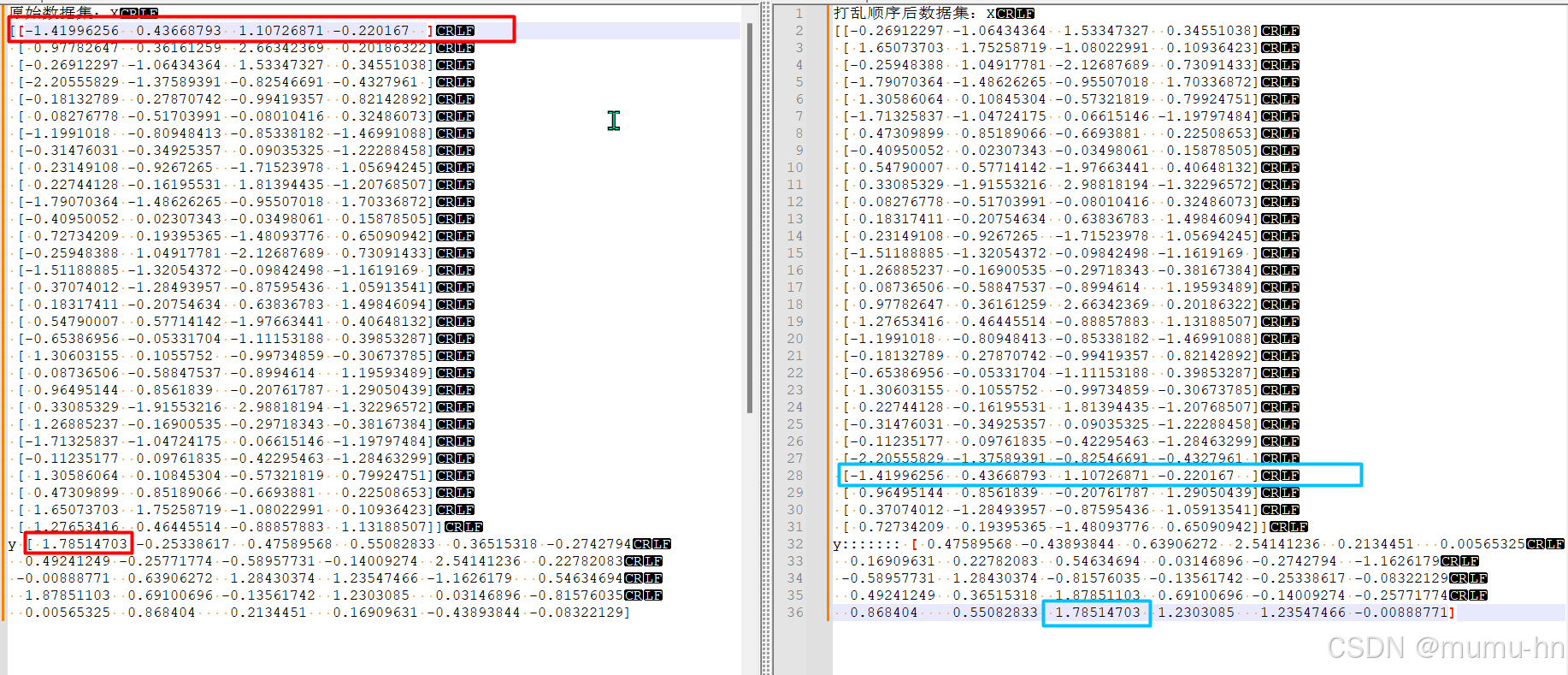
1、通过图片我们可以随意抽取1、2行原始数据集的信息和打乱后的数据集查看比对数据内容是否一致。
2、通过抽取训练集的某一行数据和原始数据对比查看比对数据内容是否一致。
X_train[3:4,:]
#输出:array([[-2.20555829, -1.37589391, -0.82546691, -0.4327961 ]])
y_train[3]
#0.5508283260754867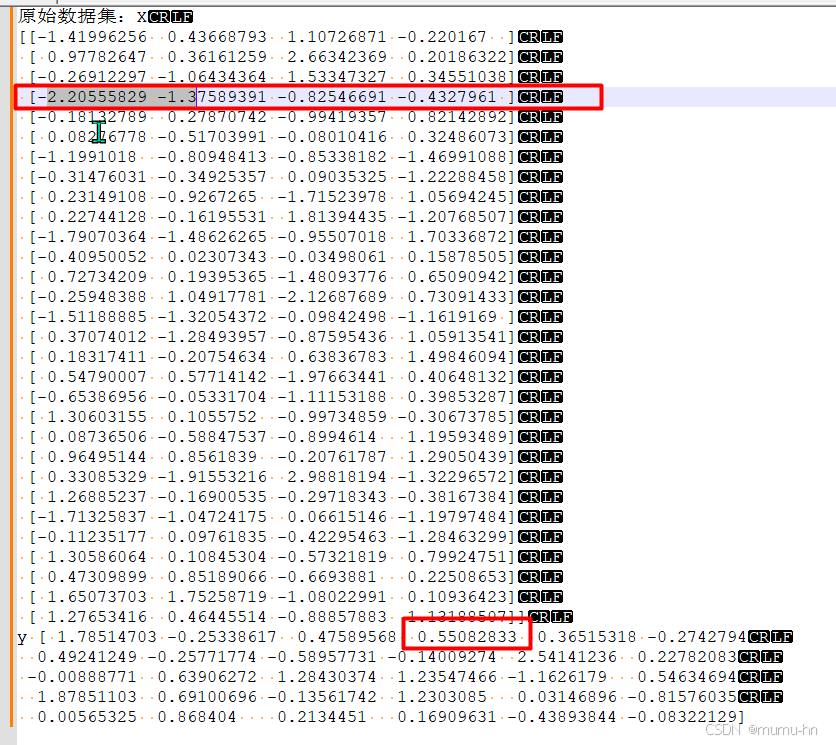
到此,本次手动实现train_test_split方法完成。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











