









介绍
日志收集的目的:
- 分布式日志数据统一收集,实现集中式查询和管理。
- 能够采集多种来源的日志数据
- 能够稳定的把日志数据解析并过滤传输到存储系统,便于故障排查
- 安全信息和事件管理
- 报表统计及展示功能
日志收集的价值:
- 日志查询,问题排查
- 应用日志分析,错误报警
- 性能分析,用户行为分析
日志收集流程:
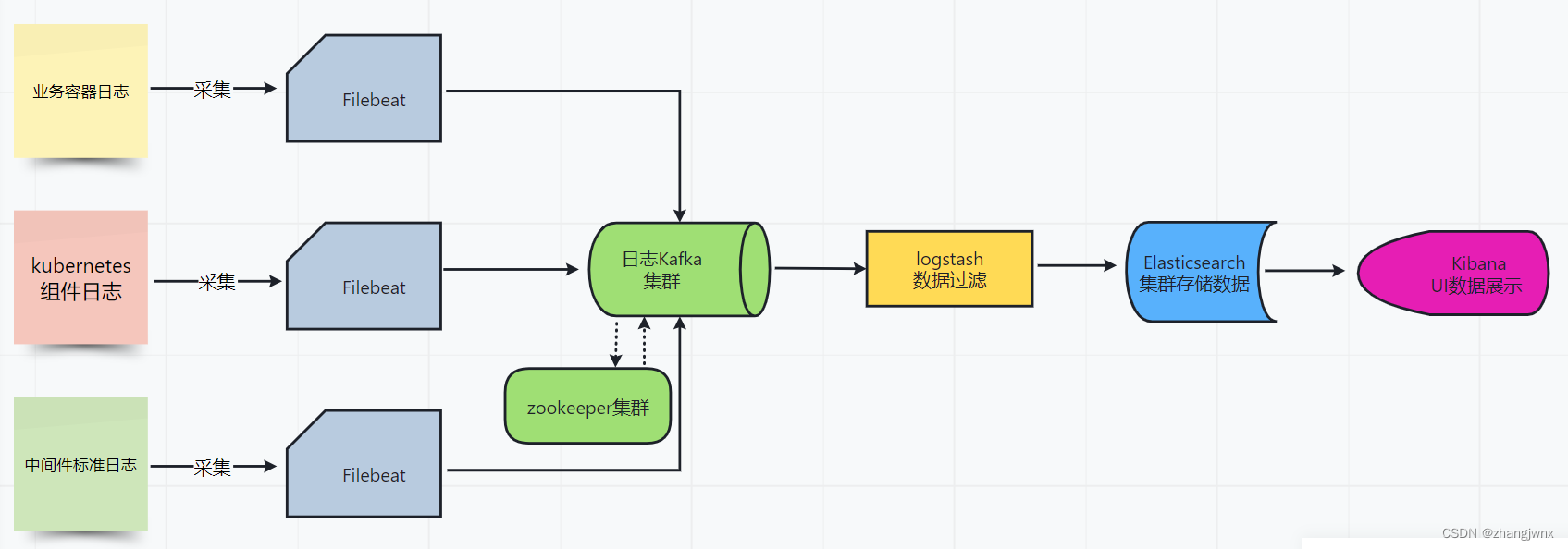
日志收集方式简介:
官方地址:https://kubernetes.io/zh/docs/concepts/cluster-administration/logging/
1、node节点收集,基于daemonset部署日志收集进程,实现json-file类型(标准输出/dev/stdout、错误输出/dev/stderr)日志收集。
2、使用sidcar容器(一个pod多容器)收集当前pod内一个或者多个业务容器的日志(通常基于emptyDir实现业务容器与sidcar之间的日志共享)。
3、在容器内置日志收集服务进程。
daemonset收集日志详介:
基于daemonset运行日志收集服务,主要收集以下两种类型的日志:
- node节点收集,基于daemonset部署日志收集进程,实现json-file类型(标准输出/dev/stdout、错误输出/dev/stderr)日志收集,即应用程序产生的标准输出和错误输出的日志。
- 宿主机系统日志等以日志文件形式保存的日志。
优缺点:
优点是资源耗费少,部署在node节点上,对应用无侵入。
缺点是只适合容器内应用日志的标准输出
containerd :
日志存储路径:
真实路径:/var/log/pods/$CONTAINER_NAMES
软连接:同时kubelet也会在/var/log/containers目录下创建软链接指向/var/log/pods/$CONTAINER_NAMES
日志配置参数:
配置文件:/etc/systemd/system/kubelet.service
配置参数:
–container-log-max-files=5 \
–container-log-max-size=“100Mi” \
–logging-format=“json” \
清理无用的镜像
nerdctl -n k8s.io image prune --all -f #不用交互
docker:
真实路径:/var/lib/docker/containers/$CONTAINERID
软连接:kubelet会在/var/log/pods和/var/log/containers创建软连接指向/var/lib/docker/containers/$CONTAINERID
配置文件:/etc/docker/daemon.json
参数:
“log-driver”: “json-file”,
“log-opts”: {
“max-file”: “5”,
“max-size”: “100m”
}
配置详解
filebeat-service-account.yaml:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat-serviceaccount-clusterrole
labels:
k8s-app: filebeat-serviceaccount-clusterrole
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat-serviceaccount-clusterrolebinding
subjects:
- kind: ServiceAccount
name: filebeat-serviceaccount-clusterrole
namespace: application
roleRef:
kind: ClusterRole
name: filebeat-serviceaccount-clusterrole
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: application
labels:
k8s-app: filebeat-serviceaccount-clusterrole
filebeat.yaml:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: application
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.autodiscover:
providers:
- type: kubernetes
node: ${NODE_NAME}
templates:
- config:
- type: container
paths:
#docker - /var/lib/docker/containers/*/*-json.log
- /var/log/pods/*/*/*.log
fields:
topic: topic-filebeat-applog
filebeat.inputs:
- type: log
paths:
- /var/log/*.log
fields:
topic: topic-filebeat-syslog
output.kafka:
enabled: true
hosts: ${KAFKA_HOST}
topic: '%{[fields.topic]}'
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: application
labels:
k8s-app: filebeat
spec:
selector:
matchLabels:
k8s-app: filebeat
template:
metadata:
labels:
k8s-app: filebeat
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
image: elastic/filebeat:7.16.3
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: KAFKA_HOST
value: '["192.168.2.131:9092","192.168.2.132:9092","192.168.2.133:9092"]'
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
cpu: 1000m
memory: 2000Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
#mountPath: /var/lib/docker/containers #docker挂载路径
mountPath: /var/log/pods
readOnly: true
- name: varlog
mountPath: /var/log
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlibdockercontainers
hostPath:
#path: /var/lib/docker/containers #docker的宿主机日志路径
path: /var/log/pods
- name: varlog
hostPath:
path: /var/log
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
# When filebeat runs as non-root user, this directory needs to be writable by group (g+w).
path: /var/lib/filebeat-data
type: DirectoryOrCreate
logstash:
vim /etc/logstash/pipelines.yml
- pipeline.id: applog
path.config: "/etc/logstash/conf.d/logstash_applog.conf"
- pipeline.id: syslog
path.config: "/etc/logstash/conf.d/logstash_syslog.conf"
vim /etc/logstash/conf.d/logstash_applog.conf
input {
kafka {
bootstrap_servers => "192.168.2.131:9092,192.168.2.132:9092,192.168.2.133:9092"
topics => ["topic-filebeat-applog"]
codec => "json"
}
}
output {
elasticsearch {
hosts => ["http://192.168.2.135:9200"]
index => "topic-filebeat-applog-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
vim /etc/logstash/conf.d/logstash_syslog.conf
input {
kafka {
bootstrap_servers => "192.168.2.131:9092,192.168.2.132:9092,192.168.2.133:9092"
topics => ["topic-filebeat-syslog"]
codec => "json"
}
}
output {
elasticsearch {
hosts => ["http://192.168.2.135:9200"]
index => "topic-filebeat-syslog-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
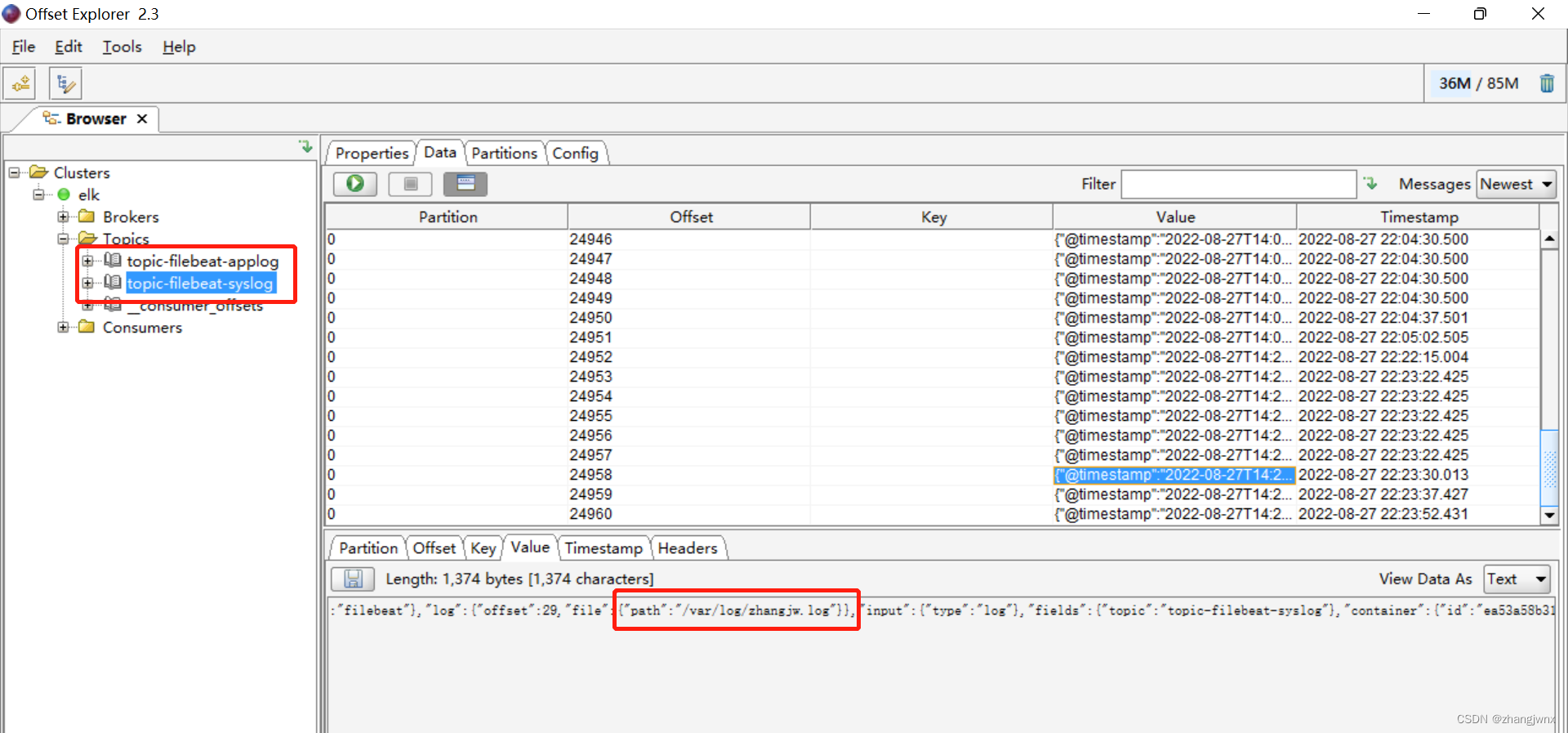

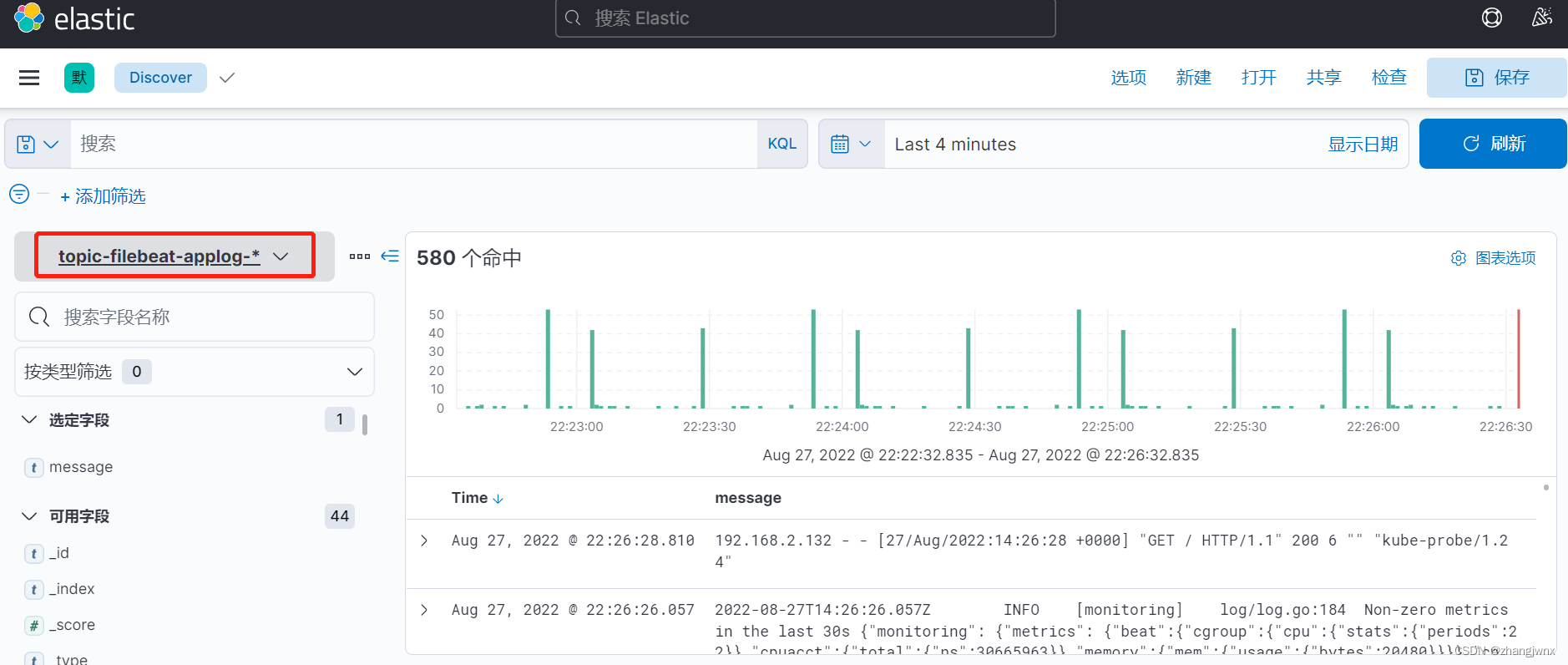
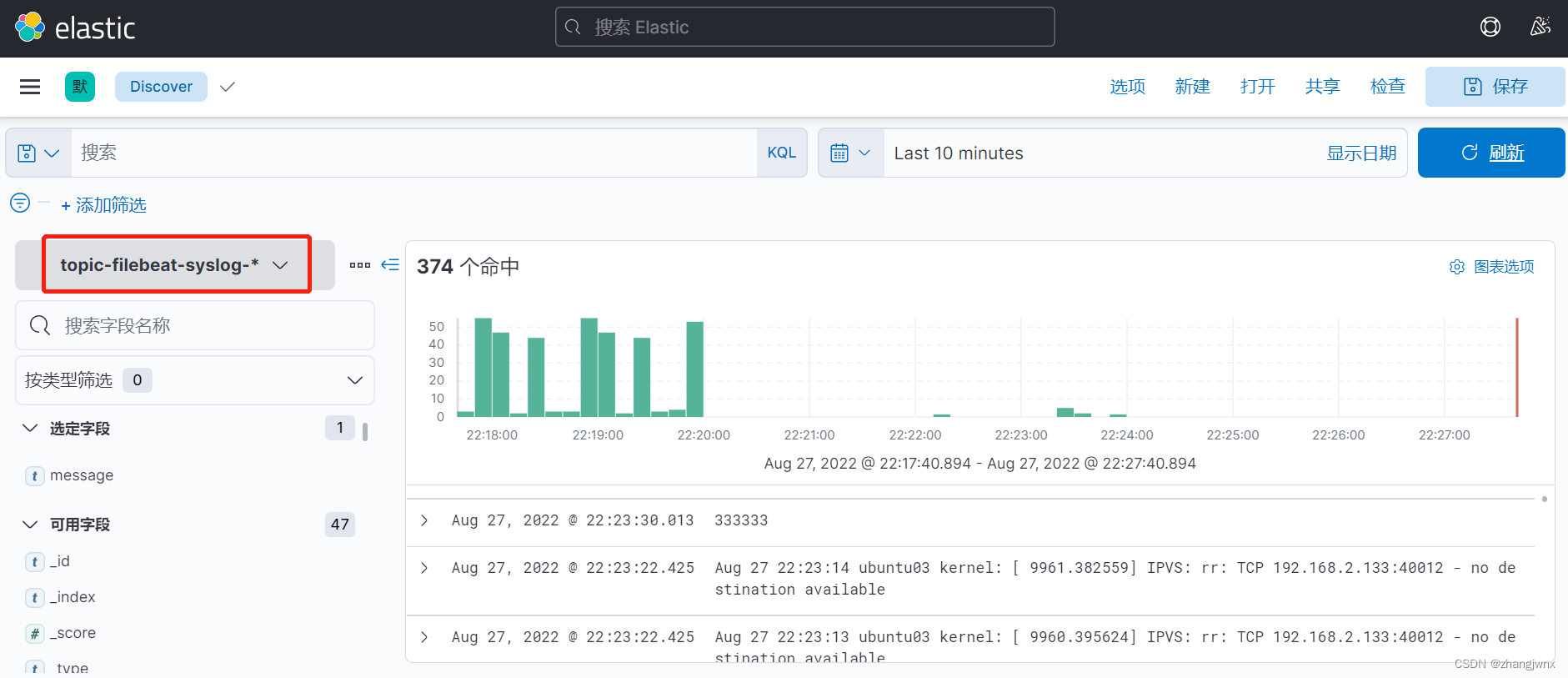
sidecar模式收集日志
使用 sidcar容器(一个pod多容器)收集当前pod内一个或者多个业务容器的日志(通常基于emptyDir实现业务容
器与 sidcar之间的日志共享)。
优缺点:
缺点是:node上会有两份相同的日志,一份是应用标准输出的,一份是sidecar收集的,对磁盘造成很大的浪费
构建filebeat-sidecar容器
Dockerfile
FROM ubuntu:20.04
WORKDIR /usr/local
ADD filebeat-7.16.3-linux-x86_64.tar.gz .
RUN ln -sv filebeat-7.16.3-linux-x86_64 filebeat
RUN cd filebeat && mkdir conf
COPY filebeat.yml /usr/local/filebeat/conf
ENTRYPOINT ["/usr/local/filebeat/filebeat","-c","/usr/local/filebeat/conf/filebeat.yml"]
filebeat.yml
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log
fields: #自定义属性输出到output
type: access-log
enabled: true
backoff: 1s # backoff 选项定义 Filebeat 在达到 EOF 之后再次检查文件之间等待的时间
backoff_factor: 2 #指定backoff尝试等待时间几次,默认是2
close_inactive: 5m #harvester读取到文件末尾后,空闲5m, 该值设置时,要大于正常写入数据的频率。
encoding: plain #编码,默认无,plain(不验证或者改变任何输入)
harvester_buffer_size: 131072 #每个harvester使用的cache大小,单位为byte
max_backoff: 5s #在达到EOF之后再次检查文件之前Filebeat等待的最长时间
max_bytes: 10485760 #单文件最大收集的字节数,单文件超过此字节数后的字节将被丢弃,默认10MB,需要增大,保持与日志输出配置的单文件最大值一致即可
scan_frequency: 10s #prospector扫描新文件的时间间隔,默认10秒
max_procs: 1 #使用最大的cpu核数
tail_lines: true #可以配置为true和false。配置为true时,filebeat将从新文件的最后位置开始读取,如果配合日志轮循使用,新文件的第一行将被跳过
- type: log
paths:
- /var/log/nginx/error.log
fields:
type: error-log
enabled: true
backoff: 1s
backoff_factor: 2
close_inactive: 1h
encoding: plain
harvester_buffer_size: 131072
max_backoff: 10s
max_bytes: 10485760
scan_frequency: 10s
max_procs: 1 #使用最大的cpu核数
tail_lines: true
output.kafka:
enable: true
hosts:
- 192.168.2.131:9092
- 192.168.2.132:9092
- 192.168.2.133:9092
partition.round_robin:
reachable_only: false
topic: 'applog-sidecar-nginx'
required_acks: 1
compression: gzip
max_message_bytes: 1000000
build-command.sh
#!/bin/bash
#docker build -t reg.zhangjw.com/library/filebeat-sidecar-nginx:v1.0 .
#docker push reg.zhangjw.com/library/filebeat-sidecar-nginx:v1.0
nerdctl build -t reg.zhangjw.com/library/filebeat-sidecar-nginx:v1.0 .
nerdctl push reg.zhangjw.com/library/filebeat-sidecar-nginx:v1.0
filebeat-sidecar-nginx.yml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: sidecar-nginx-deployment-label
name: sidecar-nginx-deployment
namespace: demo
spec:
replicas: 1
selector:
matchLabels:
app: sidecar-nginx-selector
template:
metadata:
labels:
app: sidecar-nginx-selector
spec:
containers:
- name: filebeat-sidecar-nginx
image: reg.zhangjw.com:8888/library/filebeat-sidecar-nginx:v7.0
imagePullPolicy: IfNotPresent
env:
- name: "KAFKA_SERVER"
value: "192.168.2.131:9092,192.168.2.132:9092,192.168.2.133:9092"
- name: "TOPIC_ID"
value: "filebeat-sidecar-nginx"
- name: "CODEC"
value: "json"
volumeMounts:
- name: applogs
mountPath: /var/log/nginx
- name: sidecar-nginx-container
image: nginx
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
- containerPort: 443
protocol: TCP
name: https
volumeMounts:
- name: applogs
mountPath: /var/log/nginx
volumes:
- name: applogs
emptyDir: {}
---
kind: Service
apiVersion: v1
metadata:
labels:
app: sidecar-nginx-service-label
name: sidecar-nginx-service
namespace: demo
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
nodePort: 30094
- name: https
port: 443
protocol: TCP
targetPort: 443
nodePort: 30095
selector:
app: sidecar-nginx-selector
filebeat-sidecar-nginx-logstash.conf
input {
kafka {
bootstrap_servers => "192.168.2.131:9092,192.168.2.132:9092,192.168.2.133:9092"
topics => ["applog-sidecar-nginx"]
codec => "json"
}
}
filter{
grok {
match => {
"message" => "%{IP:clientip} - (%{USERNAME:user}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:request_method} %{NOTSPACE:request_uri} HTTP/%{NUMBER:http_protocol}\" %{NUMBER:http_status} %{NUMBER:body_bytes_sent} \"-\" \"%{GREEDYDATA:http_user_agent}\" \"-\""
}}
}
output {
if [fields][type] == "access-log" {
elasticsearch {
hosts => ["http://192.168.2.135:9200"]
index => "topic-sidecar_accesslog-%{+YYYY.MM.dd}"
}}
if [fields][type] == "error-log" {
elasticsearch {
hosts => ["http://192.168.2.135:9200"]
index => "topic-sidecar_errorlog-%{+YYYY.MM.dd}"
}}
else {
elasticsearch {
hosts => ["http://192.168.2.135:9200"]
index => "topic-sidecar_unknownlog-%{+YYYY.MM.dd}"
}}
}
vim /etc/logstash/pipelines.yml
- pipeline.id: sidecar-ningx-log
path.config: "/etc/logstash/conf.d/filebeat-sidecar-nginx-logstash.conf"
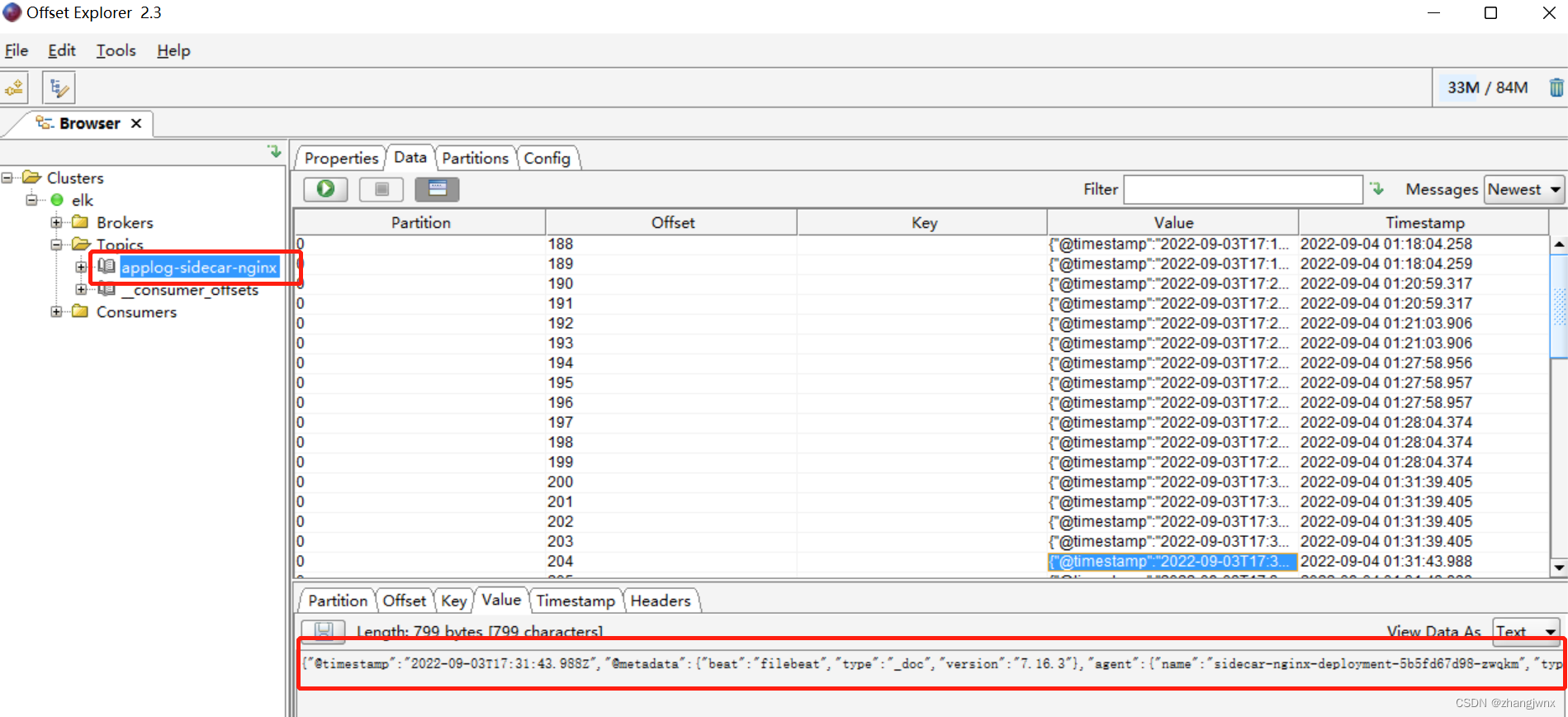
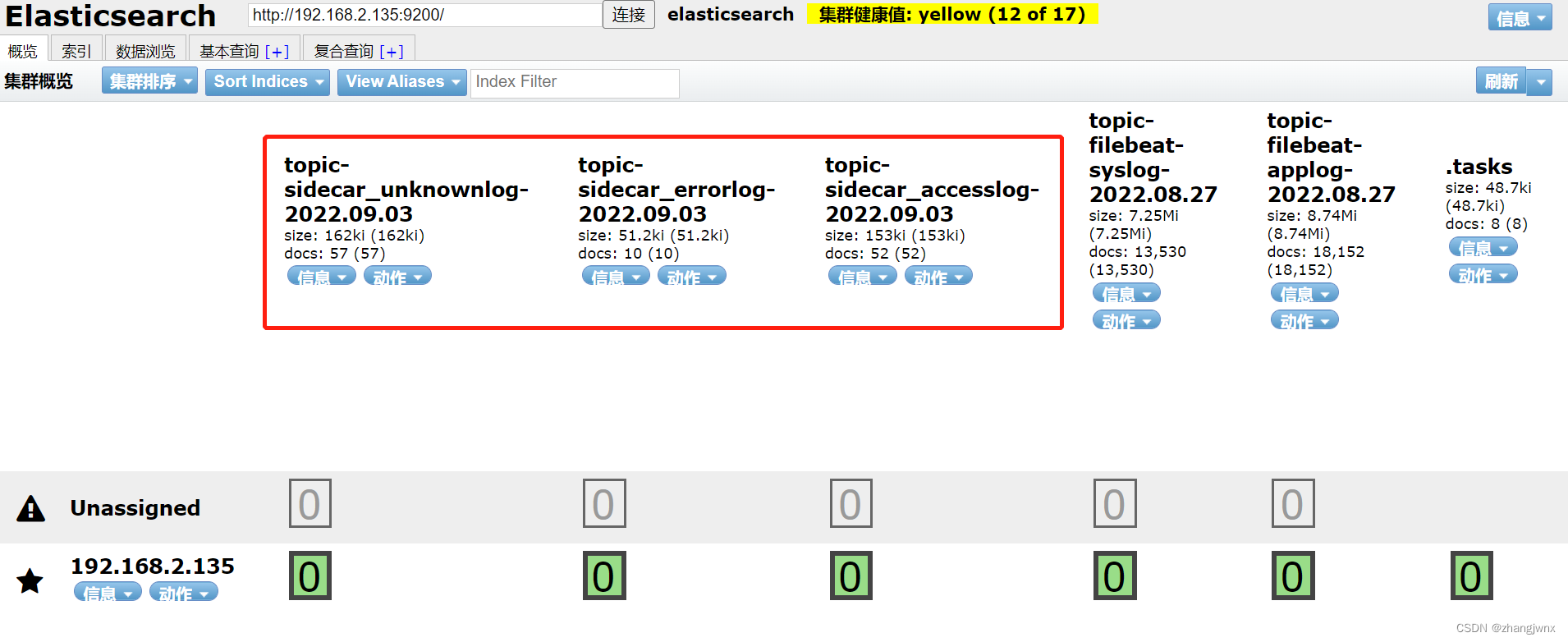
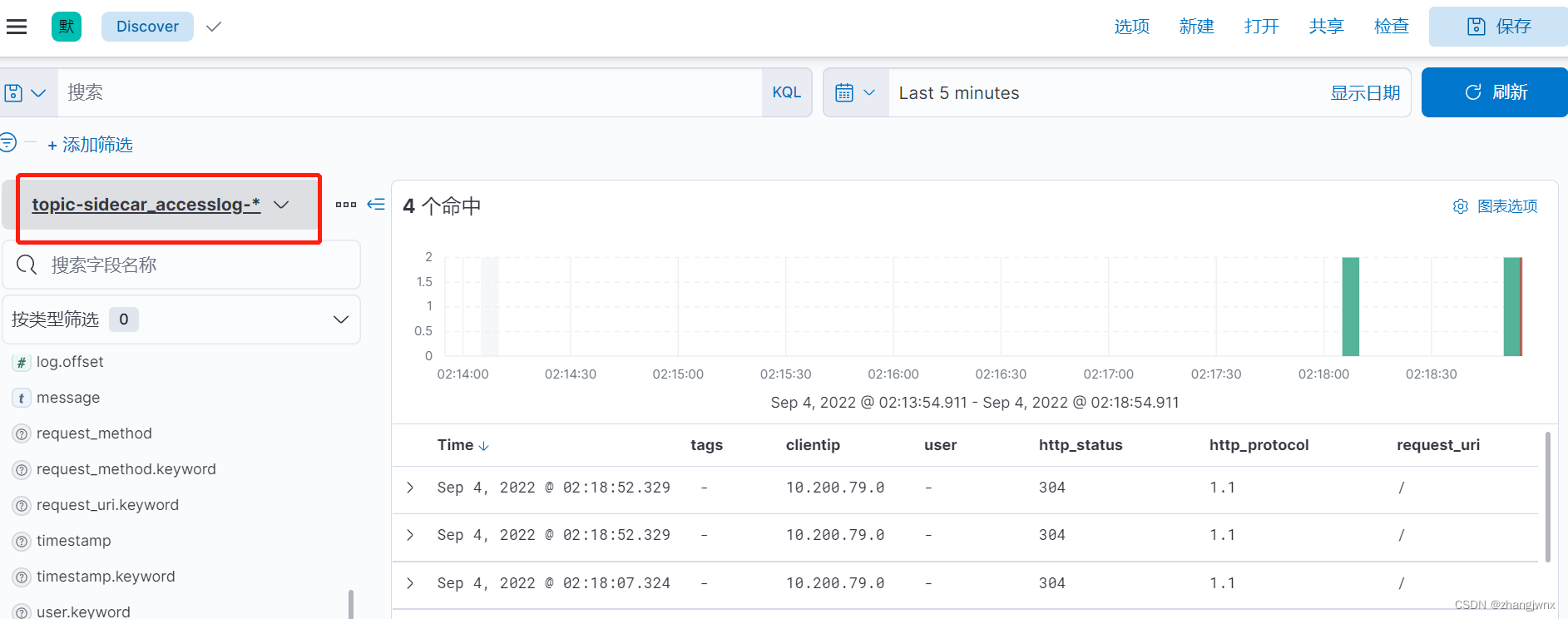
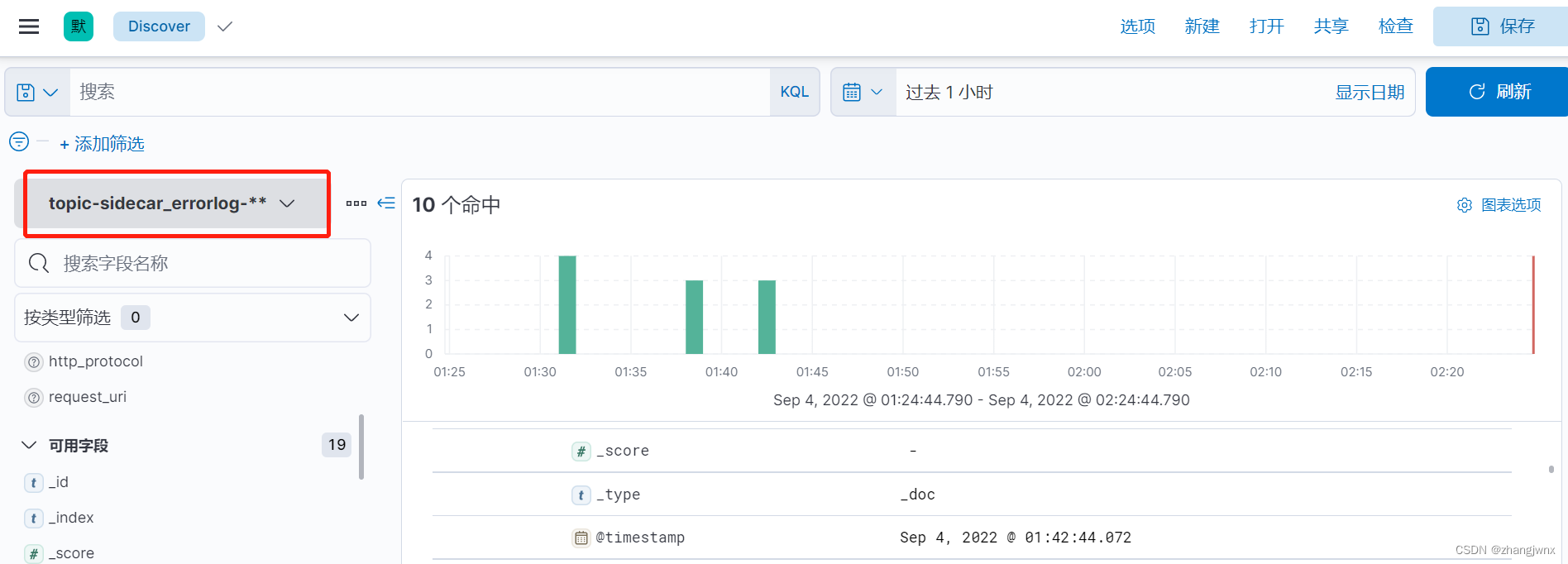
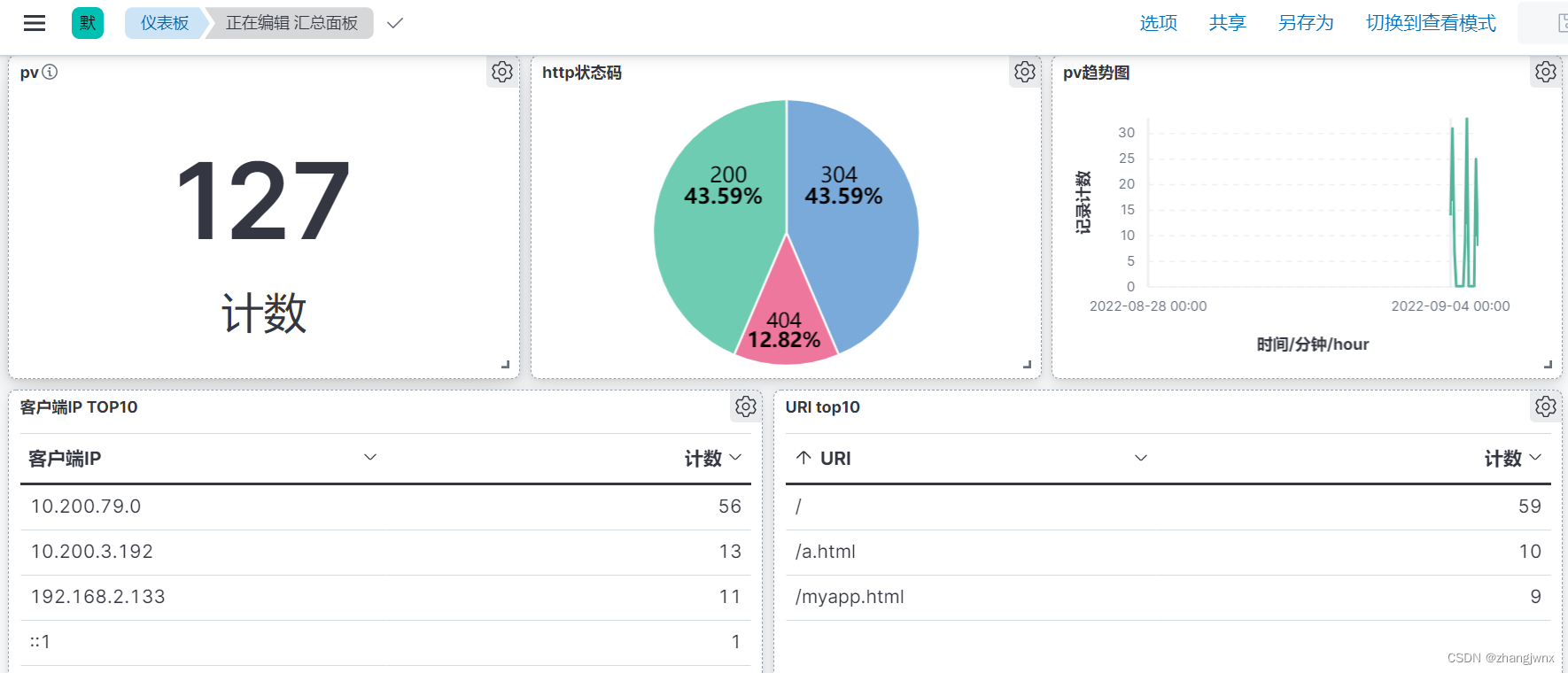
kibana汇总面板展示:
内置日志采集进程
内置日志采集进程与sidecar方式采集类似,只是把采集程序打在业务容器镜像中,这种方式耦合性太高,一般不使用,此处不再详述















 1703
1703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









