







首先很开心你能阅读这篇文章,本篇文章我将主要向大家介绍快速排序实现。
快排的重要性不言而喻,实际上快排的实现方法有很多种,而多数人往往只掌握了一种实现方法,这不论是在未来面试还是工作实践中都是远远不够的。
这里我帮大家总结了几种常见的快排实现算法,以及各种优化思路,相信一定会为你带来帮助。
下面开始介绍
文章目录
1. 什么是快排?
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
上面就是快排的基本思想,如果纯看文字有些难以理解的话,不要着急,下面我会通过图解的方式来演示快排的过程。
将区间按照基准值划分为左右两半部分的常见方式有:
- 1.左右指针法
- 2.挖坑法
- 3.前后指针法
下面我们来看这三种方式究竟是如何实现的。
2. 三种常见实现方法
2.1 左右指针法
先来看第一种左右指针法,左右指针法是Hoare在发明快排时所使用的的方法,我们一般也将它称作Hoare版本。
以下面的数组为例,来进行升序排列。

主要思路:先从数组中找一个数,这里我将这个数称为key。而下面要做的就是找到key在这个数组中的位置,并且保证key左边的元素都比他小,key右边的元素都比他大。
来看具体做法。
一般我们选用数组最后一个元素作为key,也就是当前数组中的8.
接下来定义左右两个指针分别从数组的左右两端出发,由于当前要排的是升序,所以左边指针找比key大的值,右边指针找比key小的值,找到之后将两个指针指向位置的元素内容进行交换。这样就可以将比key大的值尽可能的换到右边,比key小的值尽可能的换到左边。
这里有一点特别重要:当左右两个指针找数的时候,应该是左指针先走,右指针后走。
当左指针和右指针相遇时,该位置就是key所在的位置,再将key换到这个位置,一趟快速排序就算结束了。
我知道上面所提的一些步骤大家可能会有一些疑惑,先不要着急,下面我会慢慢来解答。
接下来我们来看左右指针法一趟快速排序的动态演示。
排序后的最终结果如下图:

注意观察,key左边的元素全部都是比key小的,而key右边的元素全部都是比key大的,所以key当前所处的位置就是它最终排序后的位置。
这里我再来回答上面为什么要先让左指针走,再让右指针走的问题。接下来我们再来通过动态演示看看如果让右指针先走,左指针后走会出现什么情况。

最终结果如下图:
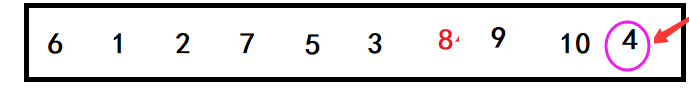
可以看到,key的右边出现了比它小的值,很显然这种做法是错误的。
下面我来分析原因。
我们知道,当两个指针相遇的时候,要将相遇位置的元素和key交换。而由于key的位置在最右端,所以这就要求相遇点的元素一定要比key大。
这里左指针是找比key大的值,如果让左指针先走,当左右两个指针相遇的时候,指向的元素肯定是比key大的值。这一点不太好理解,建议自己画图观察。
当然也要学会灵活运用,这里我们规定的key是最右边的元素,如果key是最左边元素的话,那就应该让右指针先走,左指针后走。
好了,一趟左右指针法实现快速排序的思想基本就是这样了,下面我们来看实现一趟排序的实现代码。
// 左右指针法
int PartSort1(int* a, int begin, int end)
{
int keyindex = end;
while (begin < end)
{
// begin找大
while (begin < end && a[begin] <= a[keyindex])
{
++begin;
}
// end找小
while (begin < end && a[end] >= a[keyindex])
{
--end;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[begin], &a[keyindex]);
return begin;
}
可以看到,代码的实现并不是很难,和我上面提到的思路基本一致。
一趟快排函数有三个参数,一个是数组首元素地址,一个是数组左下标,一个是数组右下标,返回值是最终key所在位置的下标,也就是左右指针相遇点的位置。至于为什么设置成这样,下面实现完整快排的时候大家就会知道了。
好,上面就是一趟左右指针法的全部思路。下面我们再来思考,一趟快排的之后,找到了key所在的位置,以及让比key小的元素处于左端,比key大的元素处于右端。那么接下来应该怎么做,才能将所有元素进行排序。
这里就要通过递归来实现了。
我们知道,一趟快排之后,比key小的元素都在key的左端,比key大的元素都在key的右端。这也意味着只要将key左边的元素排列好,再将key右边的元素排列好,这组数也就排序成功。
如下图所示:

现在我们把key左边的数当成一个新的数组,让该数组最右端的值成为新的key。再让key右边的数成为一个新的数组,同样,该数组最右端的值成为新的key。
然后不断调用一趟快排的算法进行处理,排到新数组只剩下一个数的时候,说明排序结束。
下面来看实现代码:
void QuickSort(int* a, int left, int right)
{
assert(a);
if (left >= right)
return;
int div = PartSort1(a, left, right);
QuickSort(a, left, div - 1);
QuickSort(a, div+1, right);
}
一开始先进行一趟快排,排完之后拿到函数的返回值,也就是key最终的位置。
接下来要做的就是对key的左右子数组分别进行排序,这时继续递归调用一趟快排函数,将子数组的左右下标传给一趟排序函数。这里注意,左数组的范围是[left, div - 1],右数组的范围是[div + 1, right]
以上就是左右指针法实现快速排序的全部思想。
2.2 挖坑法
挖坑法最终的结果和左右指针法相同,还是找到一个元素放到它排序之后的位置,同时让比他小的值在最左边,让比它大的值在最右边。只不过它的实现方法和左右指针法略有不同,下面我们来看它是如何实现的。
一开始先找到一个位置key,把key从当前位置挖出来存放起来,这样key的位置就变成了一个坑。然后定义两个指针分别指向左端和右端(和左右指针一样),当左指针找到比key大的值时,将左指针指向的位置埋进坑里,这样左指针指向的位置就成为了新的坑。接下来再让右指针向前找比key小的值,找到之后把该值埋进坑里,这样右指针指向的位置就成为了新的坑。
还是左指针先走,右指针后走。不断通过填坑埋坑,直到两个指针相遇的时候,将key的值放进坑里,一趟快排就结束了。
当然,这里我用语言来描述可能不太好理解,下面我们来看动图演示。
可以看到最终的效果和最右指针法是一样的。
下面我们来看实现代码:
// 挖坑法
int PartSort2(int* a, int begin, int end)
{
// 坑(坑的意思就是这位置的值被拿走了,可以覆盖填新的值)
int key = a[end];
while (begin < end)
{
while (begin < end && a[begin] <= key)
++begin;
// 左边找到比key大的填到右边的坑,begin位置就形成的新的坑
a[end] = a[begin];
while (begin < end && a[end] >= key)
--end;
// 右边找到比key小的填到左边的坑,end位置就形成的新的坑
a[begin] = a[end];
}
a[begin] = key;
return begin;
}
2.3 前后指针法
前后指针法是定义前后两个指针,前指针先往前走,找比key小的值。找到之后后指针加加向前一位,然后将前后指针指向的元素交换位置。
等到前指针指向key时,后指针再向前一位,然后再将key的值与后指针指向的位置交换。
说起来可能还是有些不好理解,下面我们一起来看动图演示:
可以看到,实际上是通过前指针找到比key小的值,后指针找到比key大的值,然后交换位置,让比key大的值尽可能的往左,比key小的值,尽可能的往右。最后再把key放到较小值和较大值之间。
实现代码如下:
// 3、前后指针法
int PartSort3(int* a, int begin, int end)
{
int prev = begin - 1;
int cur = begin;
int keyindex = end;
while (cur < end)
{
if (a[cur] < a[keyindex] && ++prev != cur)
Swap(&a[prev], &a[cur]);
++cur;
}
Swap(&a[++prev], &a[keyindex]);
return prev;
}
这段代码看起来也比较抽象,注意这里的前指针要定义为begin,后指针定义为begin-1,不要定义成0和-1,因为在递归整体时的子数组不一定是从头开始的。
当后指针找到较小值时,如果前指针加1和后指针指向同一个位置时,也就不用交换了。代码中对prev用到的是前置++,大家一定要熟悉前置++的用法。
快排的三种方法讲到这里就结束了,下面我们再来看快排的两种优化思路。
3. 快排优化思路
3.1 三数取中法选key
通过观察可以发现,如果每次选到的key是这组数的中位数话,一趟快排的效果是最好的。但是如果每次选到的key是这组数的最大值或者最小值的话,快排的效率就会变得非常低,几乎接近于O(N²)。
所以,当我们在找key的时候应该思考,即使是找不到中位数,但是也别找到最大值或者最小值,尽量的找中间的值。于是就有人发明了三数取中选key的算法。
具体实现是这样的,为了避免找到的数不是这组数的最大值或者最小值,我们可以从这组数中选出三个数来比较,找到中间大的数做key,这样就肯定不会找到最大值或者最小值了。
来看实现代码:
int GetMidIndex(int* a, int begin, int end)
{
int mid = (begin + end) / 2;
if (a[begin] < a[mid])
{
if (a[mid] < a[end])
return mid;
else if (a[begin] > a[end])
return begin;
else
return end;
}
else // a[begin] > a[mid]
{
if (a[mid] > a[end])
return mid;
else if (a[begin] < a[end])
return begin;
else
return end;
}
}
可以看到,选取的三个数一开始分别是最左边的数,最右边的数和最中间的数。选中间值的方法用if else语句来找就行了,找到之后将中间数的下标返回回去即可。
下面我们来看看左右指针法是如何来利用三数取中来选key的。
int PartSort1(int* a, int begin, int end)
{
int midIndex = GetMidIndex(a, begin, end);
Swap(&a[midIndex], &a[end]);
int keyindex = end;
while (begin < end)
{
// begin找大
while (begin < end && a[begin] <= a[keyindex])
{
++begin;
}
// end找小
while (begin < end && a[end] >= a[keyindex])
{
--end;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[begin], &a[keyindex]);
return begin;
}
首先调用三数取中选key的函数找到中间值的下标,我们在实现左右指针法时是用最右端的元素来做key的。为了不影响下面的代码,可以将选到的下标位置的元素和最右端的元素交换,从而成为key,这样就不会影响下面的算法了。
挖坑法和前后指针法一样。
3.2 递归到小的子区间时可以考虑插入排序
要知道,快排算法是不断递归来排一个数的左右两边,所以当快排算法越接近与结束的时候,左右两边数组越接近有序。
而快排算法对于接近有序的序列是没有任何效率上的提高的,但是我们知道插入排序时,如果一段序列越接近于有序,插入排序的效率就越高。
所以可以考虑,当所排序数组中的值较多时,可以考虑用快排算法。而当数组中的数较少时,可以考虑采用插入排序的算法。
实现代码如下:
void QuickSort(int* a, int left, int right)
{
assert(a);
if (left >= right)
return;
if ((right -left + 1) > 10)
{
int div = PartSort3(a, left, right);
QuickSort(a, left, div - 1);
QuickSort(a, div + 1, right);
}
else
{
// 小于等于10个以内的区间,不再递归排序
InsertSort(a + left, right - left + 1);
}
}
当数组长度大于10的时候就采用快排的递归算法,当长度小于10的时候转而使用插入排序的算法。
以上就是快速排序的全部优化过程。
4. 快排非递归实现
上面我在实现快排的时候是用递归实现的,实际中的快排大多也是用递归来实现的,毕竟递归理解和实现起来比较简单。但是,非递归同样有很大的优势,虽然是不好实现,但还是需要掌握。
非递归的实现需要借助于栈,实质上是用栈来模拟实现递归过程。
再来回顾一下递归实现快排的过程。
可以看到,实际上是通过递归数组下标来调用一趟快排函数来不断进行排序的,这个步骤我们可以用栈来模拟实现。
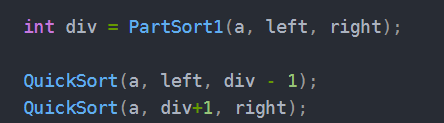
一开始先将待排数组的左右下标入栈,然后从栈中拿出两个下标传给一趟快排函数,同时让这两个数出栈,这实际上就相当于递归的第一行代码。
一趟快排之后,让[left, div - 1]和[div + 1, right]入栈重复上面的的操作,如果当前区间只剩下一个元素时就不需要再进行快排了,也就不用再入栈了。等到栈为空时,排序结束。
实现代码如下:
void QuickSortNonR(int* a, int left, int right)
{
Stack st;
StackInit(&st);
StackPush(&st, right);
StackPush(&st, left);
while (!StackEmpty(&st))
{
int begin = StackTop(&st);
StackPop(&st);
int end = StackTop(&st);
StackPop(&st);
// [begin, end]
int div = PartSort3(a, begin, end);
// [begin, div-1] div [div+1, end]
if (div + 1 < end)
{
StackPush(&st, end);
StackPush(&st, div + 1);
}
if (begin < div - 1)
{
StackPush(&st, div - 1);
StackPush(&st, begin);
}
}
StackDestory(&st);
}
栈后进先出的规则实际上和递归的处理顺序是一样的,递归调用栈帧的时候也是后进先出的,他们能达到同样的效果,所以性质是一样的。上面所调用的栈函数都是我以前写的,需要了解的话大家可以参考我的这篇文章《C语言设计实现栈》
最后再来简单总结一下。
在实际中递归改非递归有两种写法:
- 1.改循环(斐波那契数列求解) 一些简单递归才能改循环
- 2.栈模拟存储数据非递归
递归的缺陷:
递归最大缺陷是,如果栈帧的深度太深,可能会导致栈溢出。因为系统栈空间一般不大在M级别,数据结构栈模拟非递归,数据是存储在堆上的,堆是G级别的空间
非递归的优势:
提高效率(递归建立栈帧还是有消耗的,非递归可以很好的避免这一点)。
本篇文章到这里就全部结束了,最后希望这篇文章能够为大家带来帮助。















 1530
1530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









