






 本文详细介绍了如何在Linux环境下,利用Docker安装和配置开源APS软件Frepple社区版,包括下载镜像、设置数据库、启动容器以及使用步骤。
本文详细介绍了如何在Linux环境下,利用Docker安装和配置开源APS软件Frepple社区版,包括下载镜像、设置数据库、启动容器以及使用步骤。
目录
frepple简介
frepple是开源的“高级排程排产”软件(Advanced Planning and Scheduling, APS)。其开源的社区版具有如下功能或特色:
| 官方截图 | 个人理解 |
|---|---|
 | 为订单决定生产时间(考虑有限的物料和有限的产能) |
 | 进行未来销量的预测 |
 | 可以通过浏览器界面进行操作 |
 | 可通过Excel、CSV、Rest API进行数据的导入与导出 |
 | 技术框架基于apache web server, django, c++, linux,因此完全基于开源且现代的技术 |
更多的功能特点、frepple社区版和frepple收费版的区别请看官方介绍。由于博主需要学习APS软件而使用了社区版frepple,在此记录一下安装过程。
该博文受众
适合的群体
- 愿意花个一天时间来安装frepple、对linux系统和docker有些许使用经验、遇到问题愿意花时间去解决。
不适合的群体
- 想找个能快速安装并使用的APS软件。
或者
- 对linux系统或docker没怎么用过,只熟悉点击鼠标的操作。
frepple安装
前提要求
- 操作系统要求:linux系统。windows用户可以使用hyper-v、virtualbox等虚拟机,安装虚拟机的方式请另外查阅资料。
- 软件:docker。请自行查询如何在自己的linux发行版上安装docker。
下载所需的docker镜像
frepple的架构如下图所示:
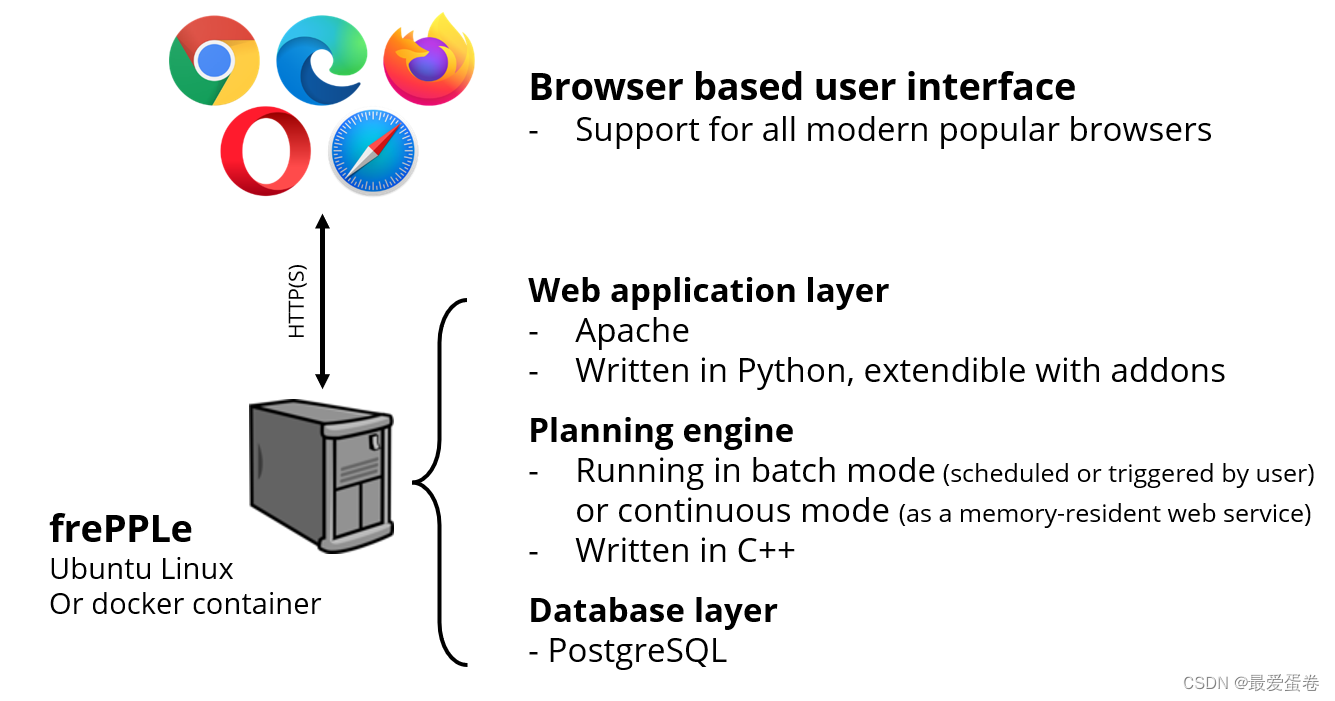
其中涉及到了4个东西:
- 浏览器(Browser based user interface),这个大家都有。
- web应用(Web application layer),这个是apache web server + django,用于接收浏览器的请求、进行数据的读写、触发其他二进制程序。这个东西包含在frepple的docker镜像中。
- 计划引擎(Planning engine),这个是用C++写的可执行文件,实现了一些算法来获得生产计划。这个东西包含在frepple的docker镜像中。
- 数据库(Database layer),需要postgresql数据库,这个东西没有包含在frepple的docker镜像中,需要另外下载并配置。
了解frepple的架构之后,我们需要下载的东西就清楚了,需要以下2个docker镜像:
- frepple的docker镜像
- postgresql的docker镜像
frepple的docker镜像下载
Step 1:拉取frepple镜像
sudo docker pull ghcr.nju.edu.cn/frepple/frepple-community:latest
这里用的是南京大学的镜像站,在博主测试的时候(2024年3月10日),30秒内就可以下载完。
如果读者发现已经无法正常下载了,那么就需要读者自行去找可以下载的镜像站了。
Step 2:检查是否下载成功
sudo docker images
你应该可以看到如下输出:

postgresql的docker镜像下载
Step 1: 拉取postgres镜像
sudo docker pull docker.nju.edu.cn/postgres:latest
这里用的是南京大学的镜像站,在博主测试的时候(2024年3月10日),30秒内就可以下载完。
如果读者发现已经无法正常下载了,那么就需要读者自行去找可以下载的镜像站了。
这里我没有按照南京大学的官方说明去设置镜像,而是直接将镜像站(docker.nju.edu.cn)的地址放在了pull的路径中。
Step 2: 检查是否下载成功
sudo docker images
你应该可以看到如下输出:

启动并配置数据库容器
在实际操作前,先看看数据库方面需要做什么事情:
1,用刚刚下载的postgres镜像启动容器。
2,进入容器,在数据库里新建数据库角色和数据库表。默认情况下,frepple会以"frepple"这个角色去数据库里访问叫做"frepple"、“scenario1”、“scenario2”, “scenario3”的数据库。而初始的数据库里既没有这个角色、也没有这些数据库,所以都要新建。
3,用docker设置一个网络,将容器分配到该网络下。由于frepple会从自己的容器向数据库所在的容器发起tcp/ip访问,因此需要让两个容器都处于一个网络下,以实现通信。
Step 1: 从postgres镜像启动容器
sudo docker run --name test_postgres -e POSTGRES_PASSWORD=postgres_passwd -p 5432:5432 -d docker.nju.edu.cn/postgres:latest
这行命令的解释为:
- docker run 表示从镜像中启动容器
- –name 后面接的是容器名(test_postgres)
- -e 设置的是容器里的环境变量,这里表示设置一个名为POSTGRES_PASSWORD的环境变量,其值为postgres_passwd(你可以改成其他的密码)。这个环境变量是用于设置数据库自带的角色(角色名为postgres)的初始密码,必须要填,否则数据库的初始化会失败、容器也会自动退出。
- -p 设置的是linux系统和容器的端口映射关系。5432:5432表示我在linux系统里对5432端口的访问(比如打开浏览器,输入localhost:5432)都会转发到容器里的5432端口(postgres数据库默认是监听5432端口)。你也可以改成xxxx:5432,只要xxxx端口没有被占用即可。
- -d 表示以后台程序运行容器,如果不加这个就会看到容器里打印出来的标准输出、且无法交互。
- docker.nju.edu.cn/postgres:latest表示镜像
检查该容器是否成功运行
sudo docker ps
你应该可以看到如下输出,最后面一列就是容器名test_postgres

如果你没看到如上输出,可以通过sudo docker logs test_postgres的方式查看启动容器过程中的输出,可能就包含了错误信息。
Step 2: 新建数据库角色和数据库表
1, 进入数据库容器
sudo docker exec -it test_postgres /bin/bash
你将看到如下输出

2, 在容器里切换成postgres用户(不仅数据库自带一个叫做postgres的角色,容器里也自带一个叫postgres的用户。只要在容器里切换成了postgres用户,就可以直接以postgres角色登陆数据库,这是数据库的一种鉴权方式)
su postgres
你将看到如下输出

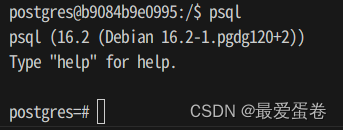
3, 登陆数据库
psql
psql会用和当前用户(postgres)同名的角色(postgres)登陆数据库,你将看到如下输出
4, 新建名叫frepple的角色
create user frepple with password 'frepple1234' createrole;
其中password后面的"frepple1234"可以修改成你想要的密码。你将看到如下输出

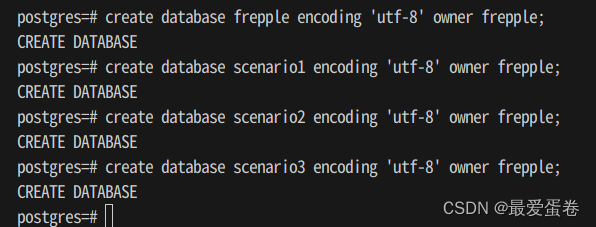
5, 新建之前提及的几个数据库
create database frepple encoding 'utf-8' owner frepple;
create database scenario1 encoding 'utf-8' owner frepple;
create database scenario2 encoding 'utf-8' owner frepple;
create database scenario3 encoding 'utf-8' owner frepple;
你将看到如下输出:
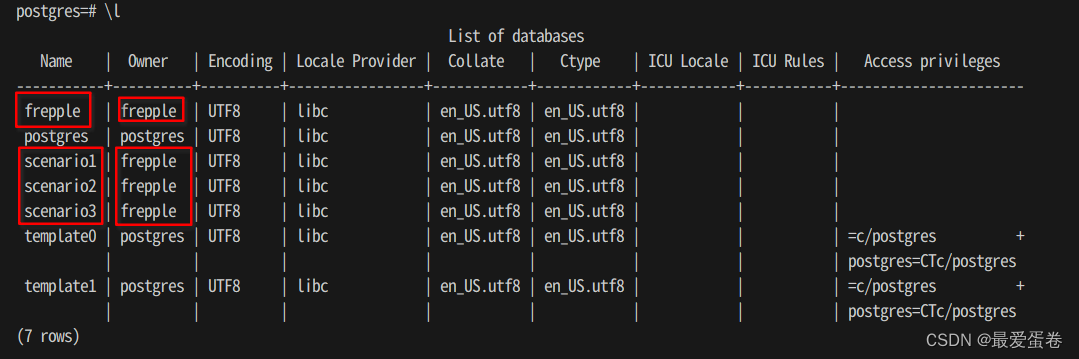
6, 检查是否角色和数据库都建立成功
\l
你将看到如下输出,第一列表示数据库的名字,这里包含了frepple, scenario1 到 scenario3这4个刚刚新建的数据库,第二列表示数据库归属的角色,也就是我们刚新建的frepple角色。
Step 3: 使用docker新建一个网络,将数据库容器添加进这个网络中
1, 退出数据库
\q
你将看到如下输出
2, 退出postgres用户
exit
你将看到如下输出
3, 退出容器
exit
你将看到如下输出,已经回到了linux系统上
4, 新建网络
sudo docker network create -d bridge test_frepple_backend
这里新建了一个名为test_frepple_backend的网络。
5, 检查网络是否建立成功
sudo docker network ls
你将看到如下输出
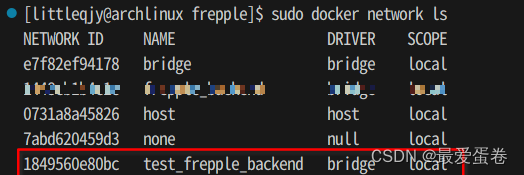
6, 将数据库容器添加到该网络下
sudo docker network connect test_frepple_backend test_postgres
7, 检查网络是否成功包含了该容器
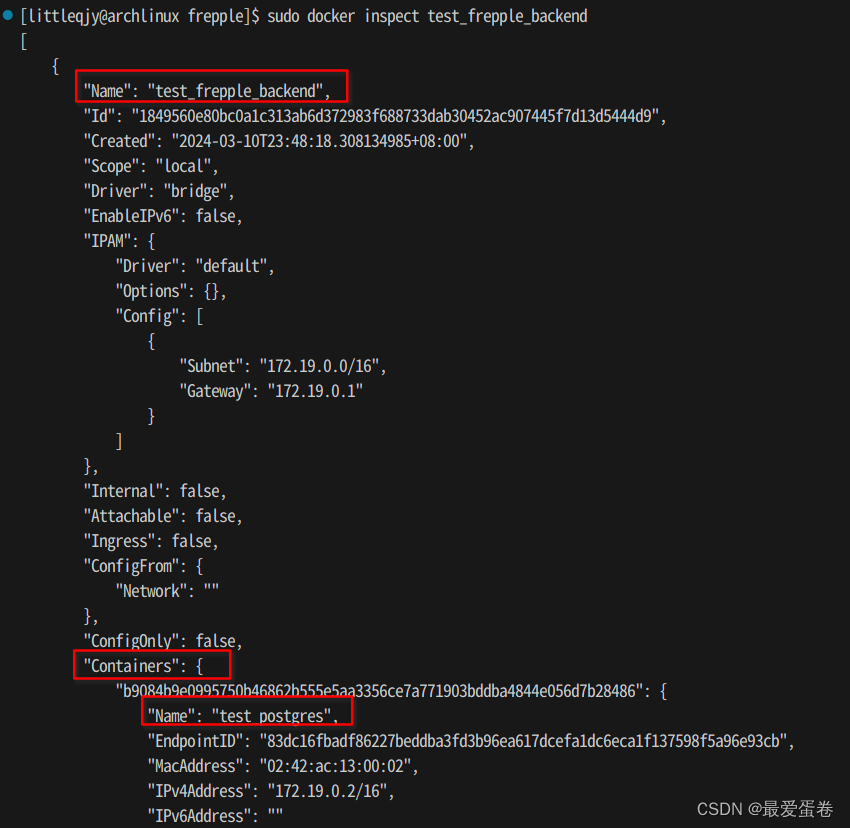
sudo docker inspect test_frepple_backend
你将看到如下输出。名叫test_frepple_backend的网络的确包含了容器test_postgres
呼~忙活了一大圈,有关数据库容器的配置,就都完成了,接下来是时候启动frepple容器了。
启动frepple容器
这一环节我们要做的事很少,就只有启动容器、然后查看是否启动成功
1, 启动frepple容器
sudo docker run \
-e POSTGRES_HOST=test_postgres \
-e POSTGRES_PORT=5432 \
-e POSTGRES_USER=frepple \
-e POSTGRES_PASSWORD=frepple1234 \
--network test_frepple_backend \
--name test_frepple \
--publish 9000:80 \
--detach \
ghcr.nju.edu.cn/frepple/frepple-community:latest
这个命令的解释为:
- -e POSTGRES_HOST=test_postgres 设置容器里的环境变量POSTGRES_HOST,其值为数据库容器的名字(test_postgres)
- -e POSTGRES_PORT=5432 设置环境变量POSTGRES_PORT,其值为数据库容器里postgres监听的端口
- -e POSTGRES_USER=frepple 设置环境变量POSTGRES_USER,其值为我们之前在数据库里建立的角色名称"frepple"
- -e POSTGRES_PASSWORD=frepple1234 设置环境变量POSTGRES_PASSWORD,其值为我们之前在数据库里建立的角色的密码
- –network test_frepple_backend 设置该容器所属的网络,要和数据库容器在同一个网络(test_frepple_backend)下
- –publish 9000:80 设置linux系统上对9000端口的访问会转发到容器里对80端口的访问(容器的80端口就是frepple web服务监听的端口)
- –detach表示以后台程序运行
- ghcr.nju.edu.cn/frepple/frepple-community:latest为镜像名
2, 检查容器是否启动成功
sudo docker ps
你将看到如下输出,可见名为test_frepple的容器已经成功运行了。

你甚至还可以通过看容器的输出来增强自信:
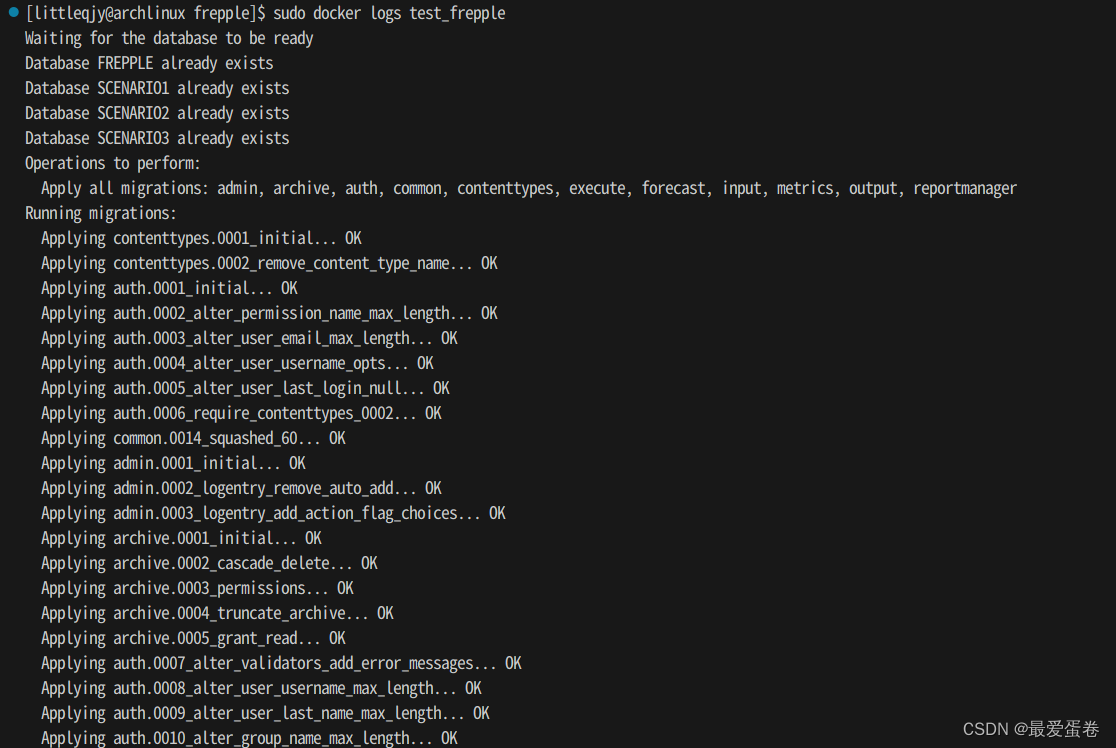
sudo docker logs test_frepple
你将看到如下输出
使用frepple
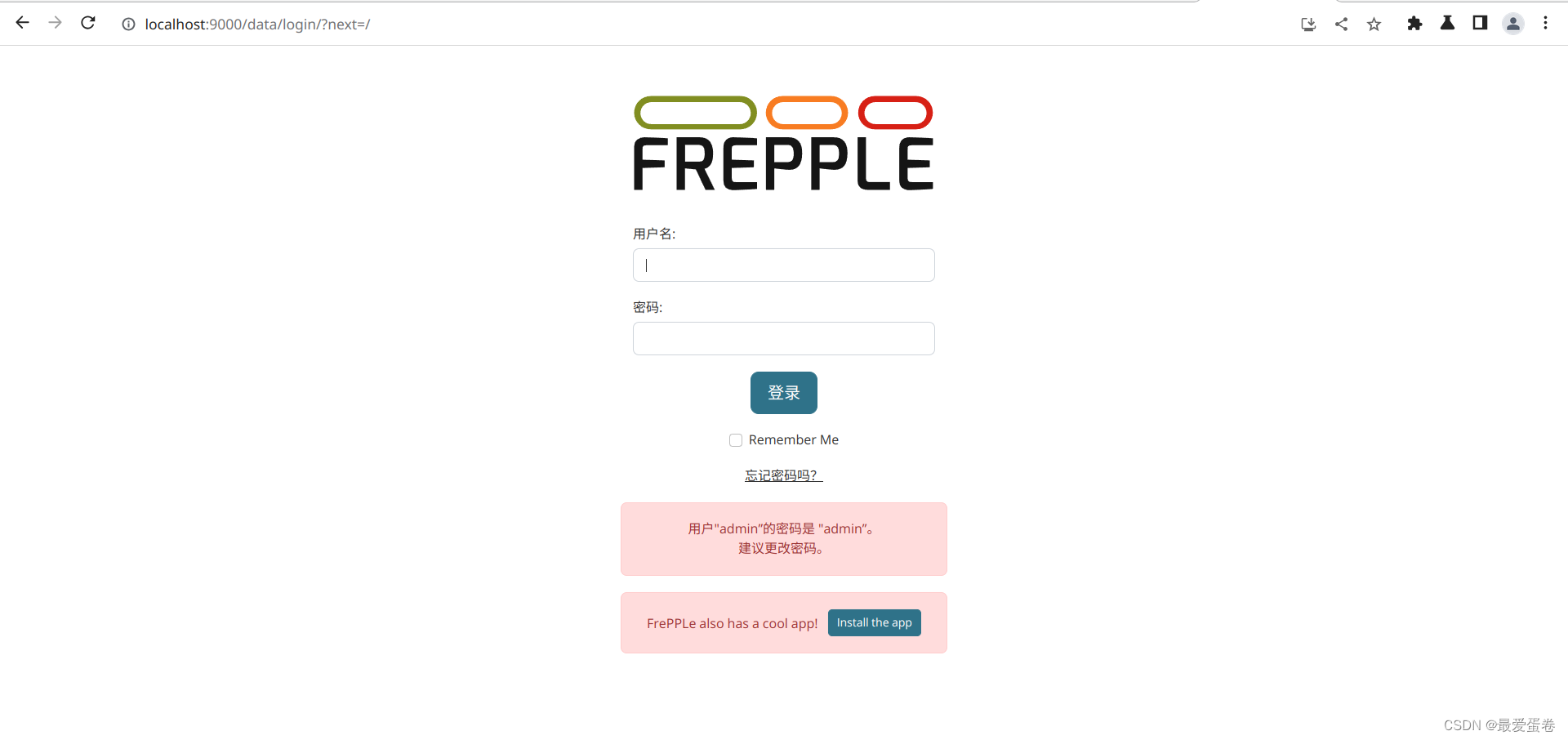
1, 如果无误地完成了以上操作,那么请打开你linux系统的浏览器,在地址栏输入localhost:9000,你将看到如下登陆界面:
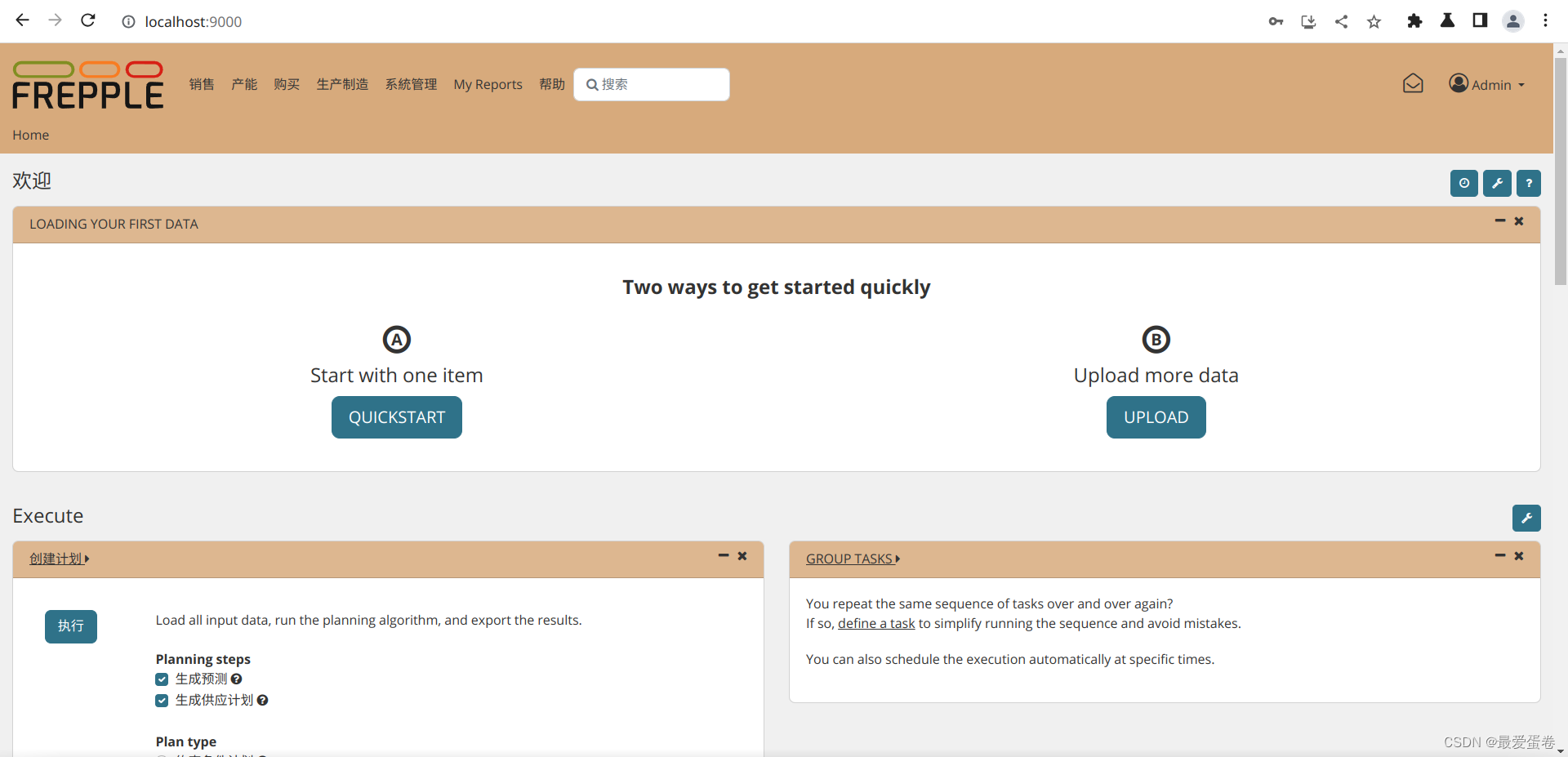
2, 输入用户名 admin 和密码 admin,你将看到如下功能界面。这里的用户名不是linux系统上的用户、也不是postgres数据库里的角色,单纯是frepple用来实现权限管理而自行设置的。
3, [非必须] 尝试一下frepple自带的样例数据。在linux系统的命令里输入
sudo docker exec test_frepple frepplectl loaddata demo
你将看到如下输出

继续回到访问localhost:9000的浏览器标签页,刷新一下,试着点击功能栏里的东西,比如说下图的“销售/销售订单”
就可以看到如下界面:
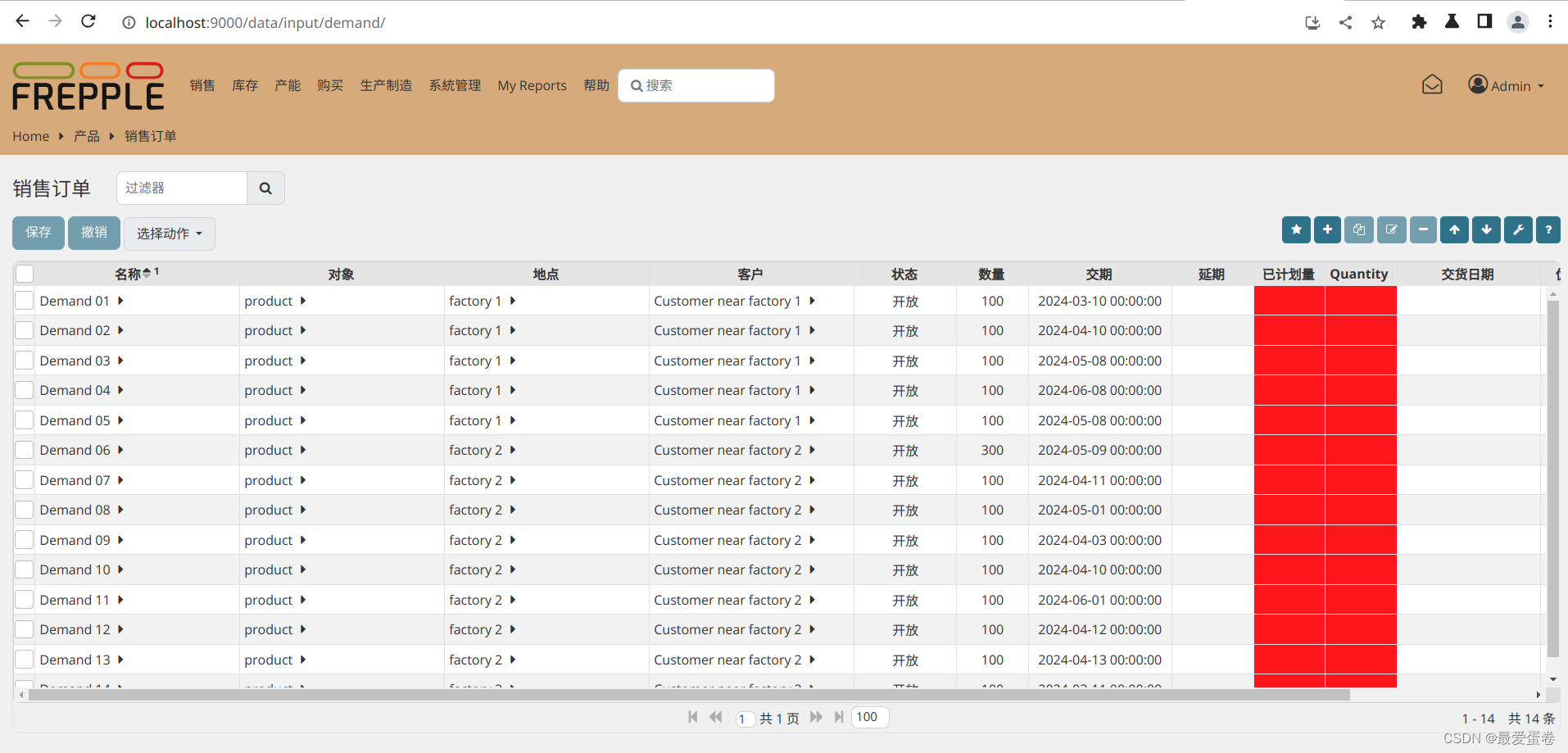
里面这么多行销售数据就是来自sudo docker exec test_frepple frepplectl loaddata demo导入的样例数据。
结束语
至此,frepple的安装就已完成。至于它的使用,请详见官方文档、并自己探索吧。
tips: 写完博文了才发现上传图片自带的水印其实是可以消除的,详见csdn文章,可惜已经上传的图片无法再消除了@_@。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









