









Kafka+zookeeper
kafka是通过zookeeper来管理集群。
kafka 软件包内虽然包括了一个简版的 zookeeper,但是感觉功能有限。在生产环境下,建议还是直接下载官方zookeeper软件。
下载镜像:
可以先curl查看下需要的版本,然后wget进行下载
curl http://mirrors.cnnic.cn/apache/zookeeper/
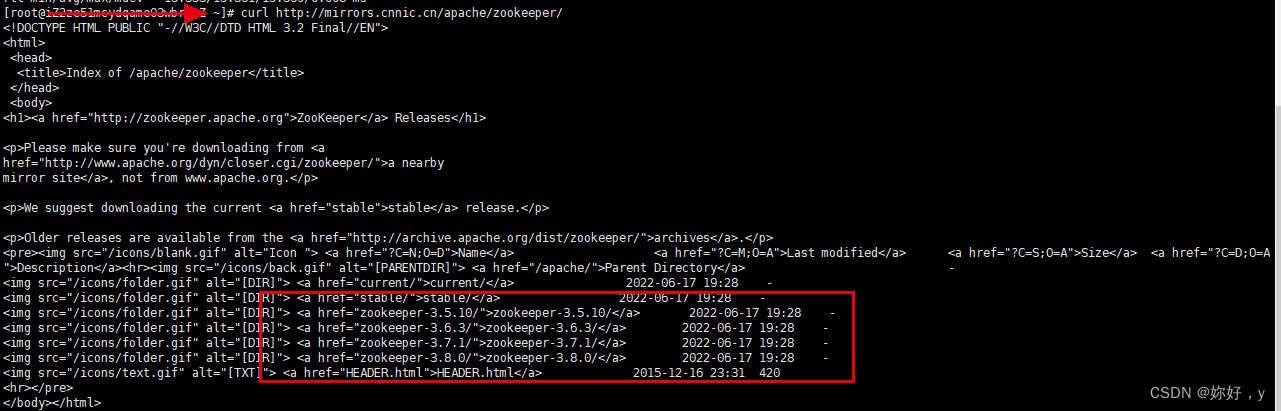
wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
目录结构:

mkdir /root/data/zookeeper/server1
mkdir /root/data/zookeeper/server2
mkdir /root/data/zookeeper/server3
因为是单节点部署集群,所以分别将二进制包解压到前面创建的三个目录中
在zookeeper的目录下面新建data文件夹创建myid文件(三个都需要,myid依次为 1,2,3)
cd /root/data/zookeeper/server1/apache-zookeeper-3.6.3-bin
mkdir data
touch data/myid
echo 1 > data/myid
修改zk的配置文件 zoo_sample.cfg 为 zoo.cfg
cd /root/data/zookeeper/server1/apache-zookeeper-3.6.3-bin/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改data目录路径,端口,添加server:
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890
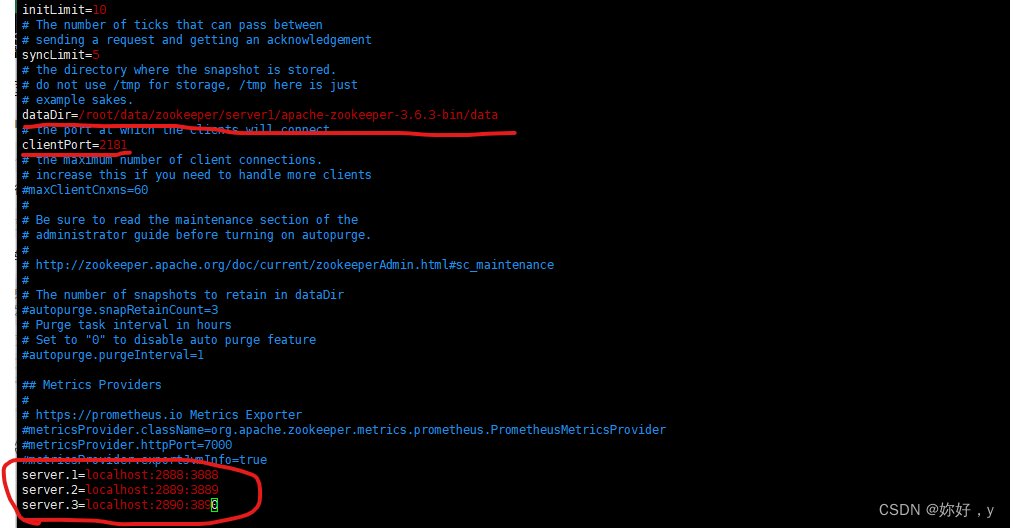
配置文件最后内容:
#间隔都是使用tickTime的倍数来表示的,例如initLimit=10就是tickTime的十倍等于2W毫秒
tickTime=2000
# The number of ticks that can pass between, sending a request and getting an acknowledgement
# 心跳最大延迟时间,如果leader在规定的时间内无法获取到follow的心跳检测响应,则认为节点已脱离
syncLimit=5
# the directory where the snapshot is stored. do not use /tmp for storage, /tmp here is just. example sakes.
# 用于存放内存数据库快照的文件夹,同时用于集群的myid文件也存在这个文件夹里
dataDir=/root/data/zookeeper/server1/apache-zookeeper-3.6.3-bin/data
# the port at which the clients will connect,ZK端口
clientPort=2181
# the maximum number of client connections. increase this if you need to handle more clients
# 允许连接的客户端数目,0-不限制,通过 IP 来区分不同的客户端
maxClientCnxns=60
#将管理机器把事务日志写入到“ dataLogDir ”所指定的目录,而不是“ dataDir ”所指定的目录。避免日志和快照之间的竞争
#dataLogDir=/root/zookeeper-3.4.14/log/data_log
# The number of snapshots to retain in dataDir
#用于配置zookeeper在自动清理的时候需要保留的快照数据文件数量和对应的事务日志文件,最小值时三,如果比3小,会自动调整为3
#autopurge.snapRetainCount=3
# Purge task interval in hours. Set to "0" to disable auto purge feature
#配套snapRetainCount使用,用于配置zk进行历史文件自动清理的频率,如果参数配置为0或者小于零,就表示不开启定时清理功能,默认不开启
#autopurge.purgeInterval=1
##集群配置
# The number of ticks that the initial, synchronization phase can take
# follow服务器在启动的过程中会与leader服务器建立链接并完成对数据的同步,leader服务器允许follow在initLimit时间内完成,默认时10.集群量增大时
#同步时间变长,有必要适当的调大这个参数, 当超过设置倍数的 tickTime 时间,则连接失败
initLimit=10
#只有集群才需要一下配置
#server.A=B:C:D:其中 A 数字,表示是第几号服务器. dataDir目录下必有一个myid文件,里面只存储A的值,ZK启动时读取此文件,与下面列表比较判断是哪个server
# B 是服务器 ip ;C表示与 Leader 服务器交换信息的端口;D 表示的是进行选举时的通信端口。
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
# 配置成observer模式
#peerType=observer
# 注意观察者角色的末尾,需要拼接上observer
#server.4=10.2.143.38:2886:3886:observer
然后server2和server3按照1的方式修改,端口改为2182和2183
到这里,zookeeper安装就基本完成了,接着安装Kafka
这里有一个坑,Kafka和zookeeper装好之后可能因为版本原因有些命令不兼容,可以提前查看他俩得版本对应表
kafka broker配置文件修改
cd /root/data/kafka/kafka_2.13-2.7.1/config
vim server.properties
broker.id=0 #整个集群内唯一id号,整数,一般从0开始
listeners=PLAINTEXT://172.19.33.221:9092 #协议、当前broker机器ip、端口,此值可以配置多个,应该跟SSL等有关系,更多用法尚未弄懂,这里修改为ip和端口。
port=9092 #broker端口
host.name=172.19.33.221 #broker 机器ip
log.dirs=log.dirs=/root/data/kafka/kafka-logs/kafka00 #kafka存储数据的目录
zookeeper.connect=172.19.33.221:2181,172.19.33.221:2182,172.19.33.221:2183 #zookeeper 集群列表
- kafka broker多节点配置
kafka多节点配置,可以像zookeeper一样把软件目录copy多份,修改各自的配置文件。这里介绍另外一种方式:同一个软件目录程序,但使用不同的配置文件启动
使用不同的配置文件启动多个broker节点,这种方式只适合一台机器下的伪集群搭建,在多台机器的真正集群就没有意义了
cp server.properties server-1.properties
cp server.properties server-2.properties
server-2.properties:
broker.id=1
listeners=PLAINTEXT://172.19.33.221:9093
port=9093
host.name=172.19.33.221
log.dirs=/root/data/kafka/kafka-logs/kafka01
zookeeper.connect=172.19.33.221:2181,172.19.33.221:2182,172.19.33.221:2183
server-3.properties:
broker.id=2
listeners=PLAINTEXT://172.19.33.221:9094
port=9094
host.name=172.19.33.221
log.dirs=/root/data/kafka/kafka-logs/kafka02
zookeeper.connect=172.19.33.221:2181,172.19.33.221:2182,172.19.33.221:2183
开始启动集群
- 启动zookeeper集群:
分别进到zookeeper集群的bin目录,执行启动脚本
cd /root/data/zookeeper/server1/apache-zookeeper-3.6.3-bin/bin
cd /root/data/zookeeper/server2/apache-zookeeper-3.6.3-bin/bin
cd /root/data/zookeeper/server3/apache-zookeeper-3.6.3-bin/bin
./zkServer.sh start
如果启动报错,查看zkEnv.sh
找到:JAVA_HOME变量,写上对应的jdk安装目录即可

- 启动Kafka集群:
进入到kafka目录,执行启动脚本
sh ../bin/kafka-server-start.sh -daemon server.properties
sh ../bin/kafka-server-start.sh -daemon server-1.properties
sh ../bin/kafka-server-start.sh -daemon server-2.properties
全部启动成功后就可以测试集群了
创建主题
进入到kafka目录,创建“test1”topic主题:分区为3、备份为3的
bin/kafka-topics.sh --create --zookeeper 172.19.33.221:2181,172.19.33.221:2182,172.19.33.221:2183 --replication-factor 3 --partitions 3 --topic test1
zookeeper : zookeeper集群列表,用英文逗号分隔。可以不用指定zookeeper整个集群内的节点列表,只指定某个或某几个zookeeper节点列表也是你可以的
replication-factor : 复制数目,提供failover机制;1代表只在一个broker上有数据记录,一般值都大于1,代表一份数据会自动同步到其他的多个broker,防止某个broker宕机后数据丢失。
partitions : 一个topic可以被切分成多个partitions,一个消费者可以消费多个partitions,但一个partitions只能被一个消费者消费,所以增加partitions可以增加消费者的吞吐量。kafka只保证一个partitions内的消息是有序的,多个一个partitions之间的数据是无序的。
启动生产者(Kafka)、消费者(zookeeper)
- 启动生产者:
bin/kafka-console-producer.sh --broker-list 172.19.33.221:9092 --topic test1
- 启动消费者
bin/kafka-console-consumer.sh --zookeeper 172.19.33.221:2181 --topic test1 --from-beginning
我们可以发现,在生产者下输入一个消息,回车后可以在消费者下输出,说明我们集群搭建的没问题
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











