






重要思想
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],非特征图。
token指的是有表征能力的向量。
代码
(可能有误)注重看思想
"""A transformer for computer vision models.
"""
import functools
import math
from typing import Optional
import numpy as np
import torch
from torch import nn, Tensor
from torch.nn import functional as F
class MHAttentionMap(nn.Module):
"""This is a 2D attention module, which only returns the attention softmax (no multiplication by value)"""
def __init__(self, query_dim, hidden_dim, num_heads=1, dropout=0.0, bias=True): # 100, 256, 8
super().__init__()
self.num_heads = num_heads
self.hidden_dim = hidden_dim
self.dropout = nn.Dropout(dropout)
self.q_linear = nn.Linear(query_dim, hidden_dim, bias=bias)
self.k_linear = nn.Linear(query_dim, hidden_dim, bias=bias)
nn.init.zeros_(self.k_linear.bias)
nn.init.zeros_(self.q_linear.bias)
nn.init.xavier_uniform_(self.k_linear.weight)
nn.init.xavier_uniform_(self.q_linear.weight)
self.normalize_fact = float(hidden_dim / self.num_heads) ** -0.5
def forward(self, q, k):
q = self.q_linear(q)
k = F.conv2d(k, self.k_linear.weight.unsqueeze(-1).unsqueeze(-1), self.k_linear.bias)
qh = q.view(q.shape[0], q.shape[1], self.num_heads, self.hidden_dim // self.num_heads)
kh = k.view(k.shape[0], self.num_heads, self.hidden_dim // self.num_heads, k.shape[-2], k.shape[-1])
weights = torch.einsum("bqnc,bnchw->bqnhw", qh * self.normalize_fact, kh)
weights = F.softmax(weights.flatten(2), dim=-1).view_as(weights)
weights = self.dropout(weights)
return weights
class PositionEmbeddingSine(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, x):
mask = torch.zeros((x.shape[0],) + x.shape[2:]).byte()
assert mask is not None
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32)
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None].to(device=x.device) / dim_t
pos_y = y_embed[:, :, :, None].to(device=x.device) / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(),
pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(),
pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
class Transformer(nn.Module):
""" A transformer module used for computer vision tasks.
First project the feature map into tokens as the input of the transformer.
Parameters:
num_tokens: number of tokenizer (l)
dim_tokens: dimension of tokenizer (ct)
num_channels: channel number of the feature map (c)
num_heads: for multi-head self-attention. embed_dim must be divisible by num_heads
num_groups: group conv as linear transformation for q, k, v
- query: :math:`(L, N, E)` where L is the target sequence length, N is the batch size, E is
the embedding dimension.
- key: :math:`(S, N, E)`, where S is the source sequence length, N is the batch size, E is
the embedding dimension.
- value: :math:`(S, N, E)` where S is the source sequence length, N is the batch size, E is
the embedding dimension.
"""
def __init__(self, num_tokens, num_channels, output_channels=None, num_queries=None, num_heads=1, num_groups=1,
down_sample=(8, 8), position_encoding='points', use_decoder=True,
positional_decoder=False, attention_for_seg=False, downsampling=False):
super().__init__()
self.num_tokens = num_tokens
self.dim_tokens = down_sample[0] * down_sample[1]
self.num_channels = num_channels
self.num_heads = num_heads
self.num_groups = num_groups
self.down_sample = down_sample
self.position_encoding = position_encoding
self.use_decoder = use_decoder
self.positional_decoder = positional_decoder
self.attention_for_seg = attention_for_seg
self.downsampling = downsampling
if use_decoder and num_queries is None:
num_queries = self.num_tokens
if output_channels is None:
self.output_channels = num_channels
else:
self.output_channels = output_channels
# c -> l, get 2d attention score, It can be seen as a convolutional filter that divides
# the feature map into various regions that corresponds to different semantic concepts.
if position_encoding == 'points':
self.input_proj = nn.Conv2d(self.num_channels + 2, self.num_tokens, kernel_size=1, bias=False)
else:
self.input_proj = nn.Conv2d(self.num_channels, self.num_tokens, kernel_size=1, bias=False)
self.input_norm = nn.BatchNorm2d(self.num_tokens)
# Transformer Encoder
self.encoder = TransformerEncoderLayer(self.dim_tokens, nhead=self.num_heads)
if use_decoder:
self.query_embed = nn.Embedding(num_queries, self.dim_tokens)
self.decoder = TransformerDecoderLayer(self.dim_tokens, nhead=self.num_heads)
if positional_decoder and position_encoding == 'points':
self.num_tokens += 2
self.reverse_proj = nn.Conv2d(self.num_tokens, self.output_channels, kernel_size=1, bias=False)
self.reverse_norm = nn.BatchNorm2d(self.output_channels)
if attention_for_seg:
self.attention = MHAttentionMap(num_queries, self.dim_tokens)
self.att_proj = nn.Conv2d(self.dim_tokens, num_queries, kernel_size=1, bias=False)
self._reset_parameters()
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, input: Tensor):
batch_size, _, height, width = input.shape
feature = input
if self.down_sample is not None:
feature = resize(feature,
self.down_sample,
mode='bilinear',
align_corners=False)
if self.position_encoding == 'points':
position_embedding = torch.from_numpy(get_points_single(feature.shape[-2:])) \
.unsqueeze(0).repeat(batch_size, 1, 1, 1).to(feature.device)
feature = torch.cat([feature, position_embedding], dim=1)
feature = self.input_proj(feature)
feature = self.input_norm(feature)
feature = feature.flatten(2).permute(1, 0, 2) # l, b, hw
memory = self.encoder(feature)
if self.use_decoder:
query_embed = self.query_embed.weight.unsqueeze(1).repeat(1, batch_size, 1)
if self.positional_decoder and self.position_encoding == 'points':
feature = self.decoder(query_embed, memory, position_embedding)
else:
feature = self.decoder(query_embed, memory)
else:
feature = memory
feature = feature.view((self.num_tokens, batch_size) + self.down_sample).permute(1, 0, 2, 3)
if self.attention_for_seg:
hs = feature.flatten(2).permute(0, 2, 1)
memory = memory.view((self.num_tokens, batch_size) + self.down_sample).permute(1, 0, 2, 3)
att = self.attention(hs, memory).squeeze(2)
att = self.att_proj(att)
feature = feature * att
feature = self.reverse_proj(feature)
feature = self.reverse_norm(feature)
if self.downsampling:
height = height // 2
width = width // 2
feature = resize(feature,
(height, width),
mode='bilinear',
align_corners=False)
if self.downsampling or self.num_channels != self.output_channels:
return feature
else:
return feature + input
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, dim_feedforward=None, nhead=1, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
if dim_feedforward is None:
dim_feedforward = d_model
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, bias=False)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward, bias=False)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model, bias=False)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def forward_post(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None):
q = k = src
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2) # add self-att
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src)))) # matrix multiply
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = src2
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask)
return self.forward_post(src, src_mask, src_key_padding_mask)
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, dim_feedforward=None, nhead=1, dropout=0.1,
activation="relu"):
super().__init__()
if dim_feedforward is None:
dim_feedforward = d_model
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, bias=False)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward, bias=False)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model, bias=False)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
def forward(self, query, memory, position_embedding=None):
if position_embedding is not None:
query = torch.cat([query, position_embedding.flatten(2).permute(1, 0, 2)], dim=0)
memory = torch.cat([memory, position_embedding.flatten(2).permute(1, 0, 2)], dim=0)
tgt = self.multihead_attn(query=query,
key=memory,
value=memory)[0]
tgt = memory + self.dropout1(tgt)
tgt = self.norm1(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
return tgt
def get_points_single(size, stride=1, dtype=np.float32):
"""The vanilla version of positional encoding (2 channels)."""
height, width = size
x_range = np.arange(0, width * stride, stride, dtype=dtype)
y_range = np.arange(0, height * stride, stride, dtype=dtype)
y_channel, x_channel = np.meshgrid(y_range, x_range)
points = (np.stack((x_channel, y_channel)) + stride // 2).transpose((1, 2, 0))
points = (points - points.mean(axis=(0, 1))) / points.std(axis=(0, 1))
return points.transpose((2, 1, 0))
def _get_activation_fn(activation):
"""Return an activation function given a string"""
if activation == "relu":
return F.relu
if activation == "gelu":
return F.gelu
if activation == "glu":
return F.glu
raise RuntimeError(F"activation should be relu/gelu, not {activation}.")
def resize(input,
size=None,
scale_factor=None,
mode='nearest',
align_corners=None):
return F.interpolate(input, size, scale_factor, mode, align_corners)
位置编码的理解PositionEmbeddingSine
如果是点位置编码
输入 b c w h
那么只需记录 w,h 的位置坐标,用坐标点(x,y)表示
所以加入位置编码后的尺度变化为:
b (c+2) w,h,
这多于的两个(w,h)张量值如下
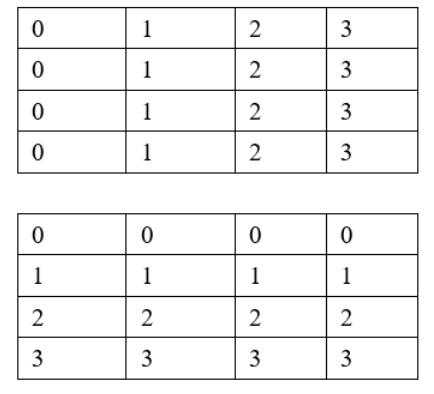
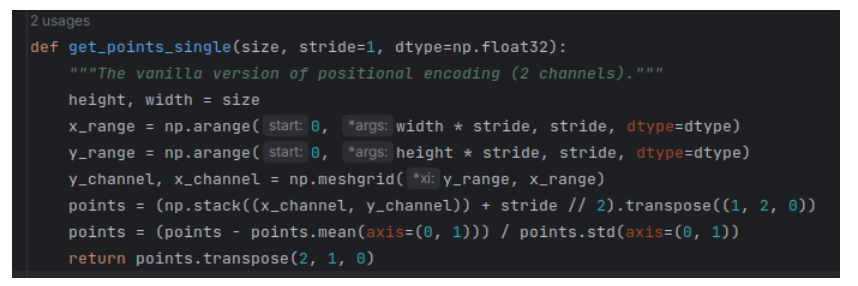
如果是余弦编码
则可能把0,1,2,3,换成用余弦代表的值,以达到能表示更多值。
b (c+dim) w,h,
这多于的dim(w,h)张量值如下

class PositionEmbeddingSine(nn.Module):
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, x):
mask = torch.zeros((x.shape[0],) + x.shape[2:]).byte()
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32)
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None].to(device=x.device) / dim_t
pos_y = y_embed[:, :, :, None].to(device=x.device) / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(),
pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(),
pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos多头注意力的理解MHAttentionMap
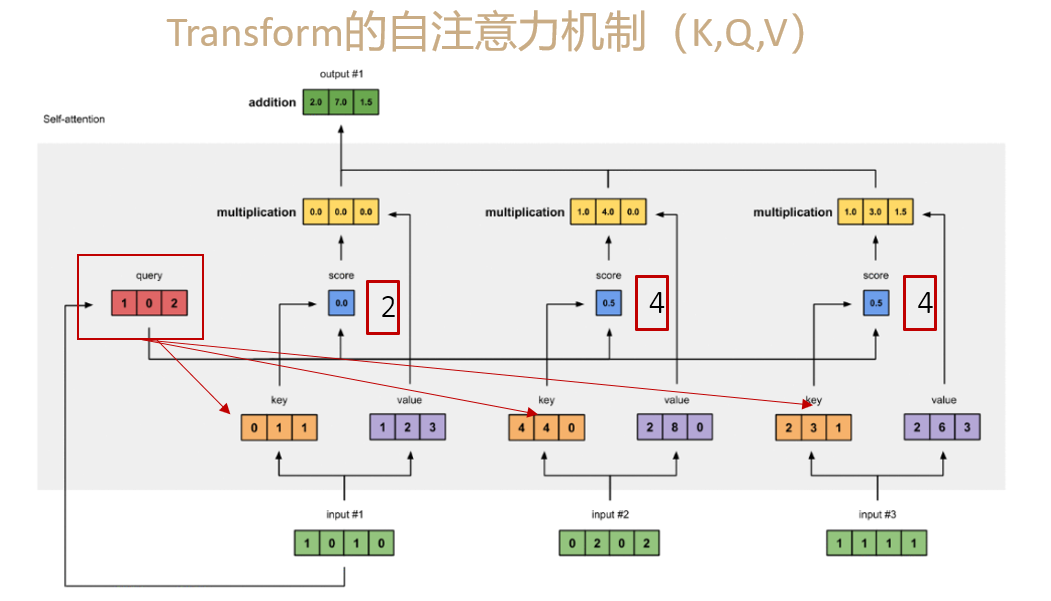
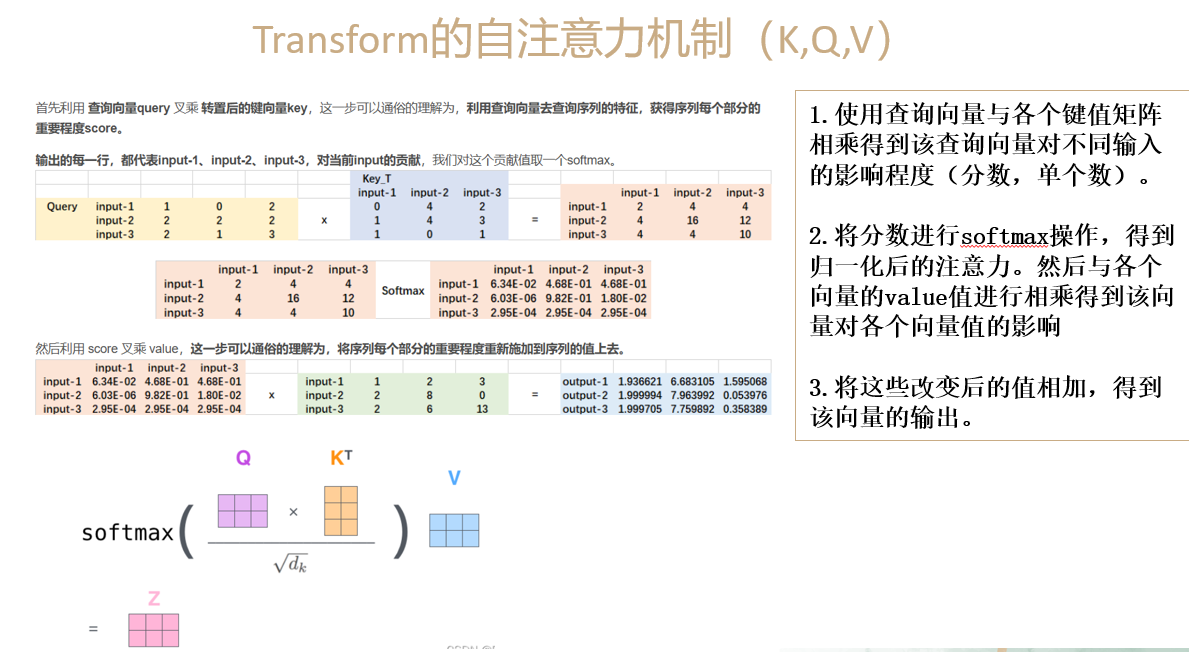
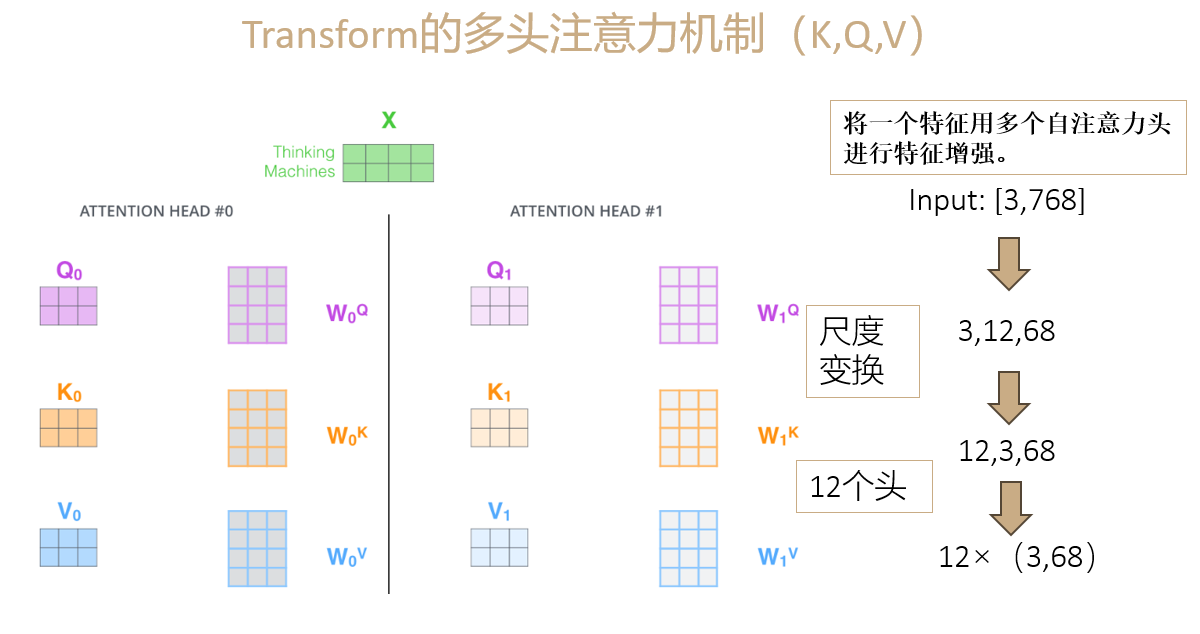
代码
class MHAttentionMap(nn.Module):
"""2D attention module, which only returns the attention softmax (no multiplication by value)."""
def __init__(self, query_dim, hidden_dim, num_heads=1, dropout=0.0, bias=True):
super().__init__()
self.num_heads = num_heads
self.hidden_dim = hidden_dim
self.dropout = nn.Dropout(dropout)
self.q_linear = nn.Linear(query_dim, hidden_dim, bias=bias)
self.k_linear = nn.Linear(query_dim, hidden_dim, bias=bias)
nn.init.zeros_(self.k_linear.bias)
nn.init.zeros_(self.q_linear.bias)
nn.init.xavier_uniform_(self.k_linear.weight)
nn.init.xavier_uniform_(self.q_linear.weight)
self.normalize_fact = float(hidden_dim / self.num_heads) ** -0.5
def forward(self, q, k):
q = self.q_linear(q)
k = self.k_linear(k)
qh = q.view(q.shape[0], q.shape[1], self.num_heads, self.hidden_dim // self.num_heads)
kh = k.view(k.shape[0], self.num_heads, self.hidden_dim // self.num_heads, k.shape[-2], k.shape[-1])
weights = torch.einsum("bqnc,bnchw->bqnhw", qh * self.normalize_fact, kh)
weights = F.softmax(weights.flatten(2), dim=-1).view_as(weights)
weights = self.dropout(weights)
return weights将Q,K,按照头的数量进行分割,分割成不同的batch
然后对他们采用QKV自注意力机制,最后返回权重
编码器
查看是否使用位置编码,如有有,则加上位置编码信息
if self.position_encoding == 'points':
position_embedding = torch.from_numpy(get_points_single(feature.shape[-2:])) \
.unsqueeze(0).repeat(batch_size, 1, 1, 1).to(feature.device)
feature = torch.cat([feature, position_embedding], dim=1) # 通道数变为 self.num_channels + 2在编码器之前通常进行映射或者下采样以减少计算量
if self.down_sample is not None:
feature = resize(feature,
self.down_sample,
mode='bilinear',
align_corners=False)feature = self.input_proj(feature)
feature = self.input_norm(feature)把hw进行展平,将输入 b,c,w,h 变为b,c,hw,输入到编码器中
feature = feature.flatten(2).permute(1, 0, 2) # l, b, hw
memory = self.encoder(feature)编码器重要组件
1.多头自注意力机制
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, bias=False)2.线性层
self.linear1 = nn.Linear(d_model, dim_feedforward, bias=False)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model, bias=False)3.归一化层
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)4.dropout层
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)定义这些组合的顺序
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask)
return self.forward_post(src, src_mask, src_key_padding_mask)
def forward_post(self, src,
src_mask: torch.Tensor = None,
src_key_padding_mask: torch.Tensor = None):-
如果
normalize_before为False,则先进行自注意力操作,然后进行归一化和前馈网络操作。
q = k = src
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2) # add self-att
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src)))) # matrix multiply
src = src + self.dropout2(src2)
src = self.norm2(src)
return srcdef forward_pre(self, src,
src_mask: torch.Tensor = None,
src_key_padding_mask: torch.Tensor = None):-
如果
normalize_before为True,则先进行归一化,然后进行自注意力操作和前馈网络操作。
src2 = self.norm1(src)
q = k = src2
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src解码器
解码器重要组件
多头注意力层。
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, bias=False)-
定义前馈网络的两层线性变换。
self.linear1 = nn.Linear(d_model, dim_feedforward, bias=False)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model, bias=False)-
定义两个归一化层和两个 Dropout 层。
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)-
定义激活函数和归一化顺序。
self.activation = F.relu
self.normalize_before = normalize_before-
输入参数
query是查询张量,memory是编码器的输出,position_embedding是位置编码(可选)。
def forward(self, query, memory, position_embedding=None): query = torch.cat([query, position_embedding.flatten(2).permute(1, 0, 2)], dim=0)
memory = torch.cat([memory, position_embedding.flatten(2).permute(1, 0, 2)], dim=0)-
如果提供了位置编码,则将其与查询和记忆张量拼接。
-
计算多头注意力,将结果与记忆张量相加,然后进行归一化和前馈网络操作。
tgt = self.multihead_attn(query=query,
key=memory,
value=memory)[0]
tgt = memory + self.dropout1(tgt)
tgt = self.norm1(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
return tgt


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









