






6.1 是什么
布隆过滤器(Bloom Fliter)是1970年由布隆提出的。
它实际上是一个很长的二进制数组 + 一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hashtable)等等数据结构都是这种思路。
但是随着集合中元素的增加,我们需要的存储空间也会呈现线程增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n)、O(log2n)、O(1)。这个时候,布隆过滤器就应运而生。
一句话:由一个初值都为0的bit数组和多个哈希函数构成,用来快速判断某个数据是否存在。
本质就是判断具体数据存不存在一个大的集合中
布隆过滤器是一种类似set的数据结构,只是统计结果不太准确。
在亿级系统、大数据规模级的大集合中,是否存在xxx元素,首先想到布隆过滤器
6.2 特点考点
- 高效地插入和查询,占用空间少,返回的结果是不确定性的。
- 一个元素如果判断结果为存在的时候不一定存在,但是判断结果为不存在的时候则一定不存在【有是可能有,无是一定无】
- 布隆过滤器可以添加元素,但是不能删除元素。因为删除元素会导致误判率增加。
- 误判只会发生在过滤器没有添加过的元素,对于添加过的元素不会发生误判。
6.3 布隆过滤器的使用场景
6.3.1 解决缓存穿透的问题
1)缓存穿透是什么
一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库。当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
缓存穿透带来的问题是:当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
2)可以使用布隆过滤器解决缓存穿透的问题
把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在:
- 如果布隆过滤器中不存在该条数据则直接返回。
- 如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则穿透的MySQL数据库。
6.3.2 黑名单校验
发现存在黑名单中,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。
假设黑名单的数据是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
6.4 布隆过滤器原理
6.4.1 Java中传统hash
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值。
如果两个散列值是不相同(根据同一函数)那么这两个散列值的原始输入也是不相同的。这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“哈希碰撞”。
用hash表存储大数据量时,空间效率还是很低,当只有一个hash函数时,还很容易发生哈希碰撞。
6.4.2 演示hash冲突
public class testHash{
@Test
public void test2(){
System.out.println("Aa".hashCode()); // 2112
System.out.println("BB".hashCode()); // 2112
}
@Test
public void test2(){
Set<Integer> hashCodeSet = new HashSet<>();
for (int i = 0; i < 200000; i++) {
int hashCode = new Object().hashCode();
if (hashCodeSet.contains(hashCode)){
System.out.println("出现了重复的hashCode:"+hashCode+"\t 运行到了:"+i);
}
hashCodeSet.add(hashCode);
}
}
}
6.4.3 实现原理和数据结构
布隆过滤器(Bloom Filter)是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。有一个初值都为0的bit数组和多个哈希函数构成,用来快速判断某个数据是否存在。但是跟HyperLogLog一样,它也一样有那么一点点不精确,也存在一定的误判概率。
添加key时:使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置为1就完成了add操作。
查询key时:只要有其中一位是0就表示这个key不存在;但如果都是1,则不一定存在对应的key。
结论:有,是可能有;无,是一定无
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,把它们置为1(假定有两个变量都通过3个映射函数)
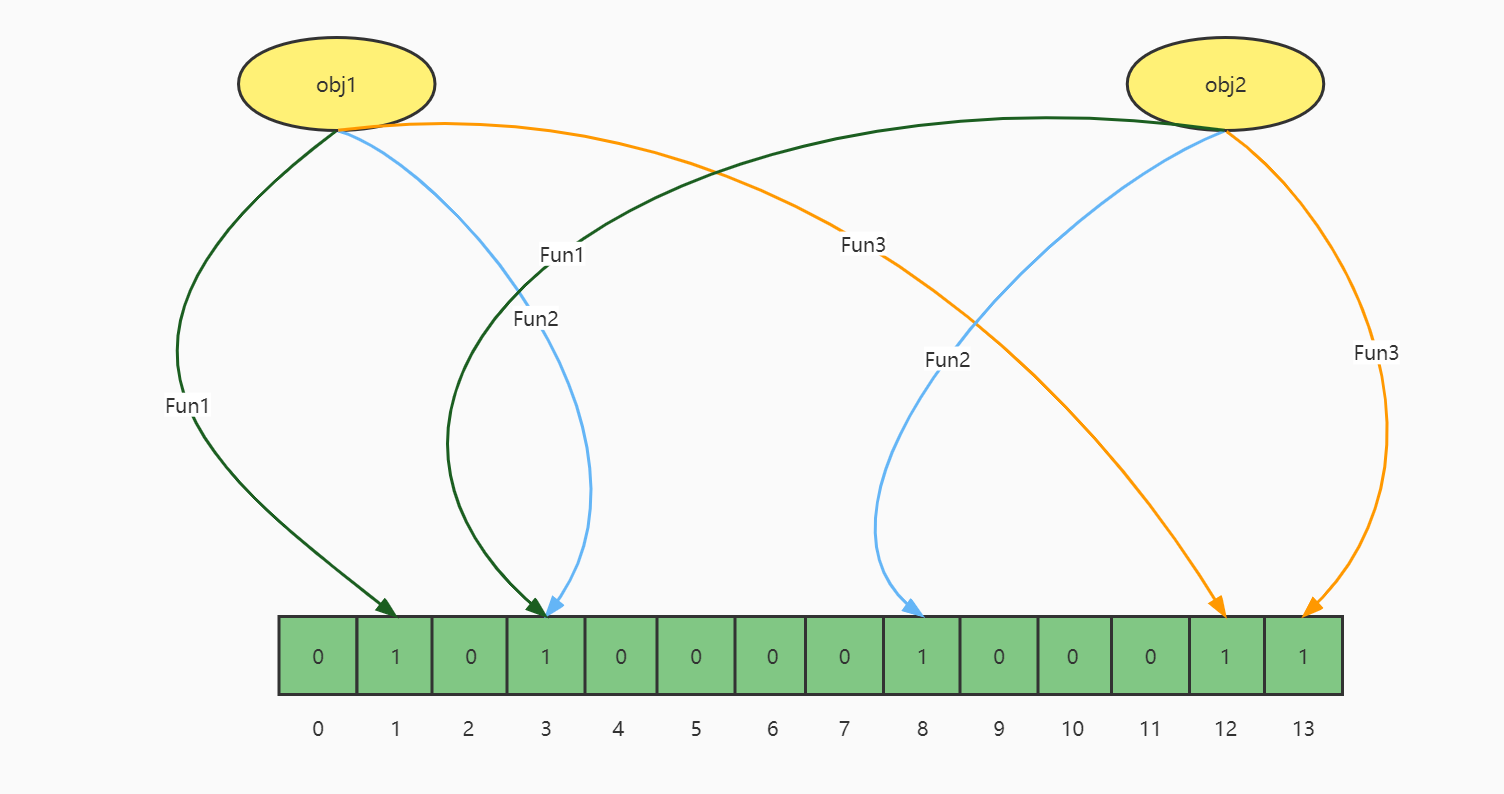
查询某个变量的时候我们只要看看这些点是不是都是1,就可以大概率知道集合中有没有它了。
如果这些点,有任何一个为0则被查询变量一定不在。
如果都是1,则被查询变量很可能存在。
为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。
正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。如果不存在,就不用在去数据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询Redis和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。
布隆过滤器可以使用Redis实现,本身就能承担较大的并发访问压力。
6.4.4 总结:三步骤
1)初始化
布隆过滤器本质上是由长度为m的位向量或位列表(仅包含0或1位值的列表)组成,最初所有的值均设置为0
2)添加
当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个hash函数对key进行运算,算得一个下标索引值,然后对数组长度进行取模运算得到一个位置,每个hash函数都会算得一个不同的位置。再把位数组的这几个位置都置为1就完成了add操作。
例如:我们添加一个字符串wmyskxz

3)判断是否存在
向布隆过滤器查询某个key是否存在时,先把这个key通过相同的多个hash函数进行运算,查看对应的位置是否都为1,只要有一个位为0,那么说明布隆过滤器中这个key不存在。
如果这几个位置全都是1,那么说明极有可能存在。因为这些位置的1可能是因为其他的key存在导致的,也就是前面说过的hash冲突。
就比如我们在add了字符串“wmyskxz”数据之后,很明显下面1/3/5这几个位置的1是因为第一次添加的“wmyskxz”而导致的。此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5,这就是误判了…
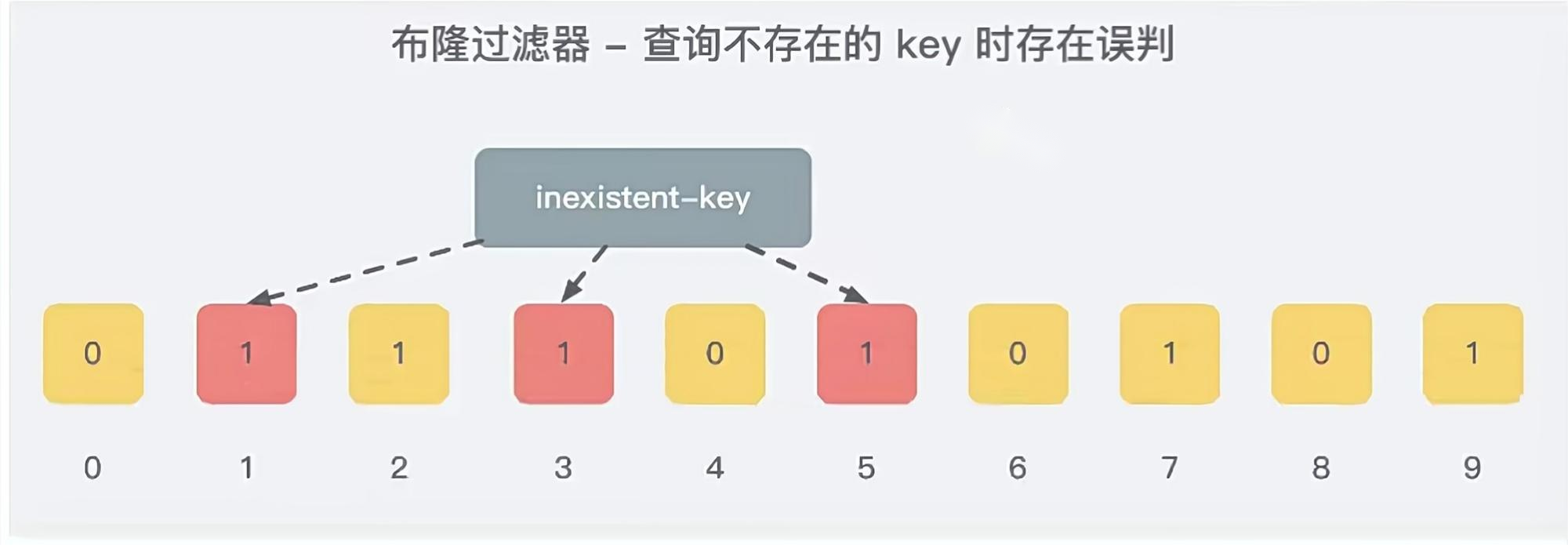
6.4.5 布隆过滤器误判率,为什么不要删除
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的bit位被多次映射且置1。
这种情况也造成了布隆过滤器删除问题,因为布隆过滤器的每一个bit并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。
总结:布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
6.4.6 小总结
➥ 是否存在:
- 有,是很可能有
- 无,是肯定无。可以保证的是,如果布隆过滤器判断一个元素不再一个集合中,那这个元素一定不会在集合中。
➥ 使用时最好不要让实际元素数量远大于初始化数量。
➥ 当实际元素数据超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个size更大的过滤器,再将所有的历史元素批量add进行。
6.5 布隆过滤器优缺点
优点:高效地插入和查询,占用空间少
缺点:不能删除元素;存在误判
6.6 布谷鸟过滤器(了解)
为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。
作者将布谷鸟过滤器和布隆过滤器进行了深入的对比。相比布谷鸟过滤器而言,布隆过滤器有以下不足:
- 查询性能弱
- 空间利用效率低
- 不支持反向操作(删除)
- 不支持计数















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









