






CSAPP BombLab详解
实验环境
OS: Ubuntu18.04LTS 64位
实验开始前的准备
本次实验需要大家熟悉GDB的用法,使用如下命令调试bomb二进制程序
当打算使用标准输入(Stdin)作为输入调试时
gdb ./bomb
当打算使用文件做输入调试时,使用如下命令(文件输入的文件名记得换成自己的)
gdb --args ./bomb input.txt
关于GDB的使用,只需要掌握基本的即可,在Lab以及实践中常用的命令如break,print,display,examine,info register。具体可见GDB Tutorial。
使用如下命令生成bomb二进制文件的反汇编代码。
objdump -d bomb >> ass.txt
在GDB中同样可以用disassemble 函数名生成函数对应的反汇编代码:
从什么地方开始
使用objdump命令生成的汇编文件中许多内容是库函数相关的指令代码,我们无需关注。我们需要找到main函数的入口。浏览后可知main函数调用了函数phase_1 ~ phase_6,这6个phase就是我们需要去解的。
phase1
顺腾摸瓜,找到了phase_1的反汇编代码。

根据汇编,可以看出phase1要做的是比较两个字符串是否相同。那么这两个字符串是从何而来?
在main函数中有指令如下:
400e32: e8 67 06 00 00 callq 40149e <read_line>
400e37: 48 89 c7 mov %rax,%rdi
400e3a: e8 a1 00 00 00 callq 400ee0 <phase_1>
在开始前复习知识点:
函数调用
首先在main函数中,我们先找到这个片段,这个代码片段实际上做了2件事。
- 调用read_line,读入你输入的字符串。并把字符串的首地址放到%rax中,
- 为了调用只有一个参数的phase_1函数,需要把参数放到%rdi中。最后进行函数调用。
进入到phase_1中,此时%rdi中存放的是我们输入的字符串首地址(回忆书中内容。strings_not_equal函数是比较两个字符串是否相等,自然应该有两个参数,且在C语言中,更具体来说,参数是字符串的首地址。那么另一个字符串首地址就应当在%rsi(在x86架构中,若对寄存器的低4字节执行mov指令,则高四字节自动设置为0) 中。
在gdb中输入:
p (char *)$rsi
可得到:Border relations with Canada have never been better.
至此,只需要把我们的输入调整到和它一样,就可以完成phase1。
phase_2
假设我在phase_2的输入是:
1 2 4 8 16 32
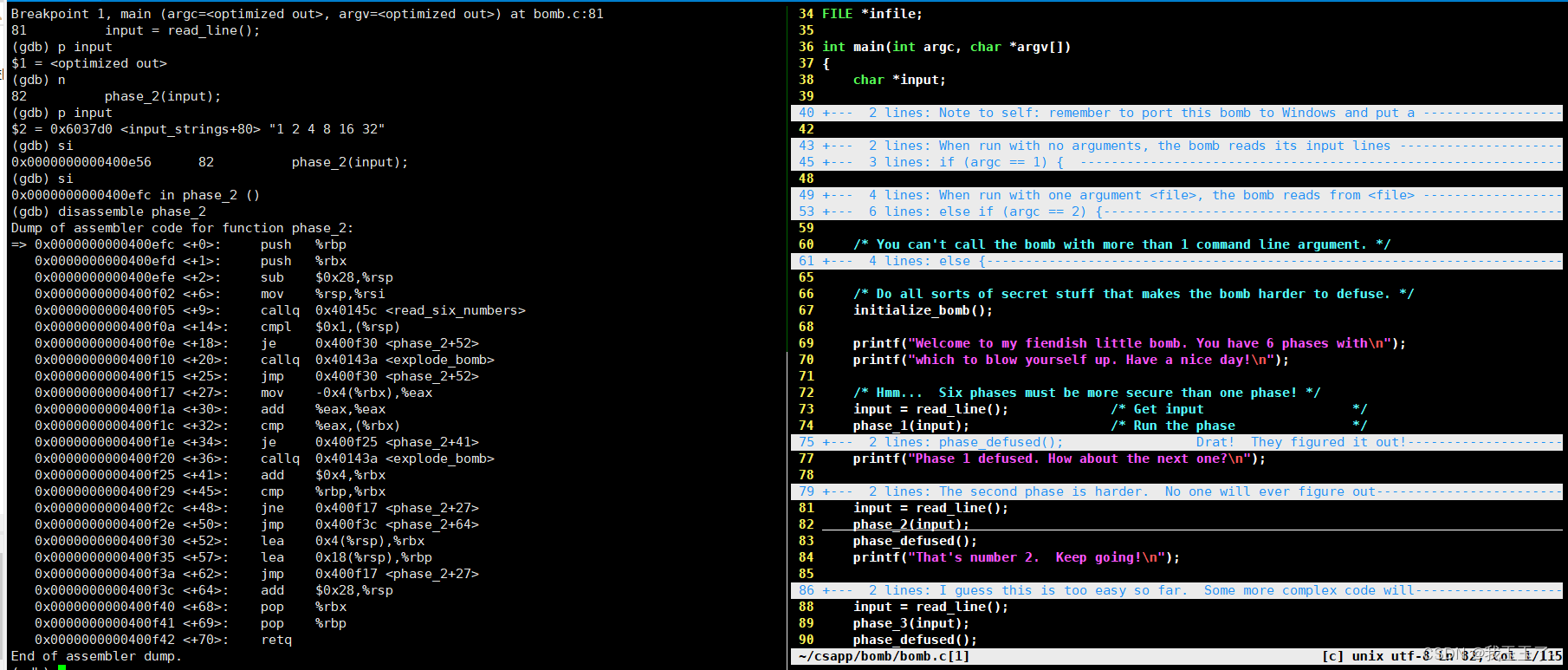
在左边的汇编代码注意看这条:
0x0000000000400efe <+2>: sub $0x28,%rsp
它将栈顶指针向下移动0x28,也就是40字节,可以理解成开辟了一块空间,<read_six_number>函数将读取到的数字放到这块空间里。
当<read_six_number>执行完毕后,使用x(实际上也就是examine命令)查看内存布局。发现数字确实都读入进去了。读取的每个数字是int类型占四字节

接着分析下面的汇编代码,如果第一个数字是1,那么跳转到<+52>处。
<+52> 与 <+57> 使用lea指令计算地址。取一条来分析其含义:
lea 0x4(%rsp),%rbx
它的意思就是将%rsp寄存器中存储的地址值+4后,再存入%rbx。
下一条指令:
lea 0x18(%rsp),%rbp
看到%rbp的值被设置为%rsp + 24, 正好是我们读取到的6个数字所占字节数,这不是巧合,通过设置%rbp,可理解为设置了循环的边界。
接着向下执行,函数跳转到<+27>处。这是关键的几步代码。
0x0000000000400f17 <+27>: mov -0x4(%rbx),%eax
0x0000000000400f1a <+30>: add %eax,%eax
0x0000000000400f1c <+32>: cmp %eax,(%rbx)
0x0000000000400f1e <+34>: je 0x400f25 <phase_2+41>
0x0000000000400f20 <+36>: callq 0x40143a <explode_bomb>
注意%rbx实际上现在指向的是我们输入序列中的第二个数字(2)
实际上做了这么几件事情:
- 找到%rbx所指向数字的前一个输入数字,放入%rax中
- 自己+自己,在没溢出的情况下相当于乘2倍
- 比较%rbx所指向的数字与第二步得到的乘积
- 相等则跳转到<+41>:%rbx += 4为接下来判断后面的数字做准备。不相等则引爆炸弹,程序终止。
看到现在,我们可以确定:这六个数字是一个首项为1,公比为2 的等比数字序列。 这就是phase_2的全部内容。
phase_3
假设我在phase_3的输入是:
1 311
phase_3反汇编代码如图所示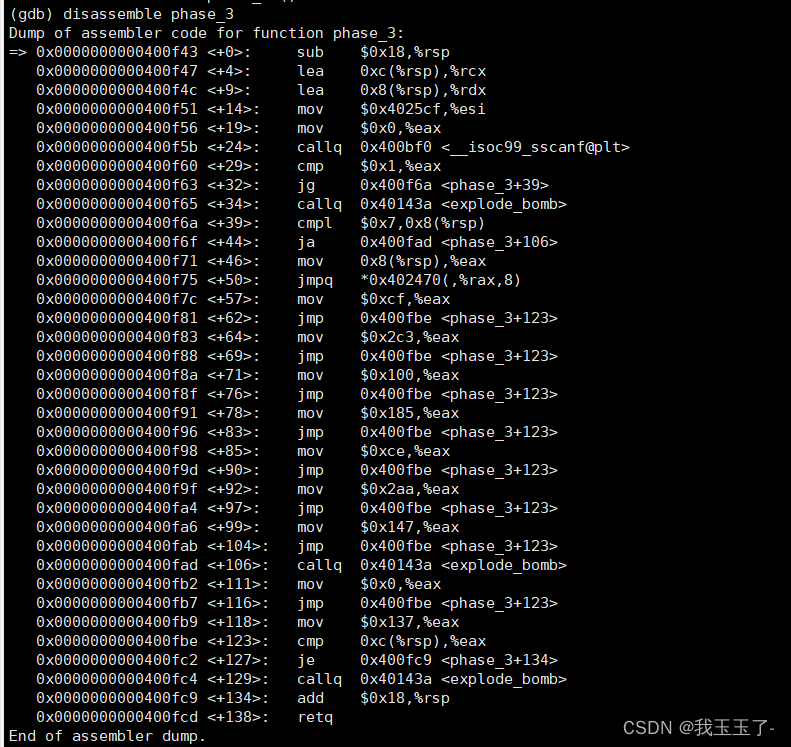
发现调用了sscanf函数,去查了sscanf的函数原型:
int sscanf(const char *str, const char *format, ...)
结合函数传参使用寄存器的规则,可知:
- 形参str存放在%rdi中
- 形参format存在%rsi中
- 第一个可变参数放在%rdx中
- 第二个可变参数放在%rcx中
验证一下:


执行完sscanf后的结果,可以看出确实在phase_3中我们要输入两个数字进行拆弹。
在(%rsp+8)的地址处存放的是输入的第一个数字,在(%rsp+12)的地方存放的是第二个数字。
下面这段代码告诉我们第一个数应当一定是处于[0, 7]之间。
0x0000000000400f6a <+39>: cmpl $0x7,0x8(%rsp)
0x0000000000400f6f <+44>: ja 0x400fad <phase_3+106>
接着向下执行遇到这条指令,顺腾摸瓜我们看看这个地址里放的是什么东西
0x0000000000400f75 <+50>: jmpq *0x402470(,%rax,8)
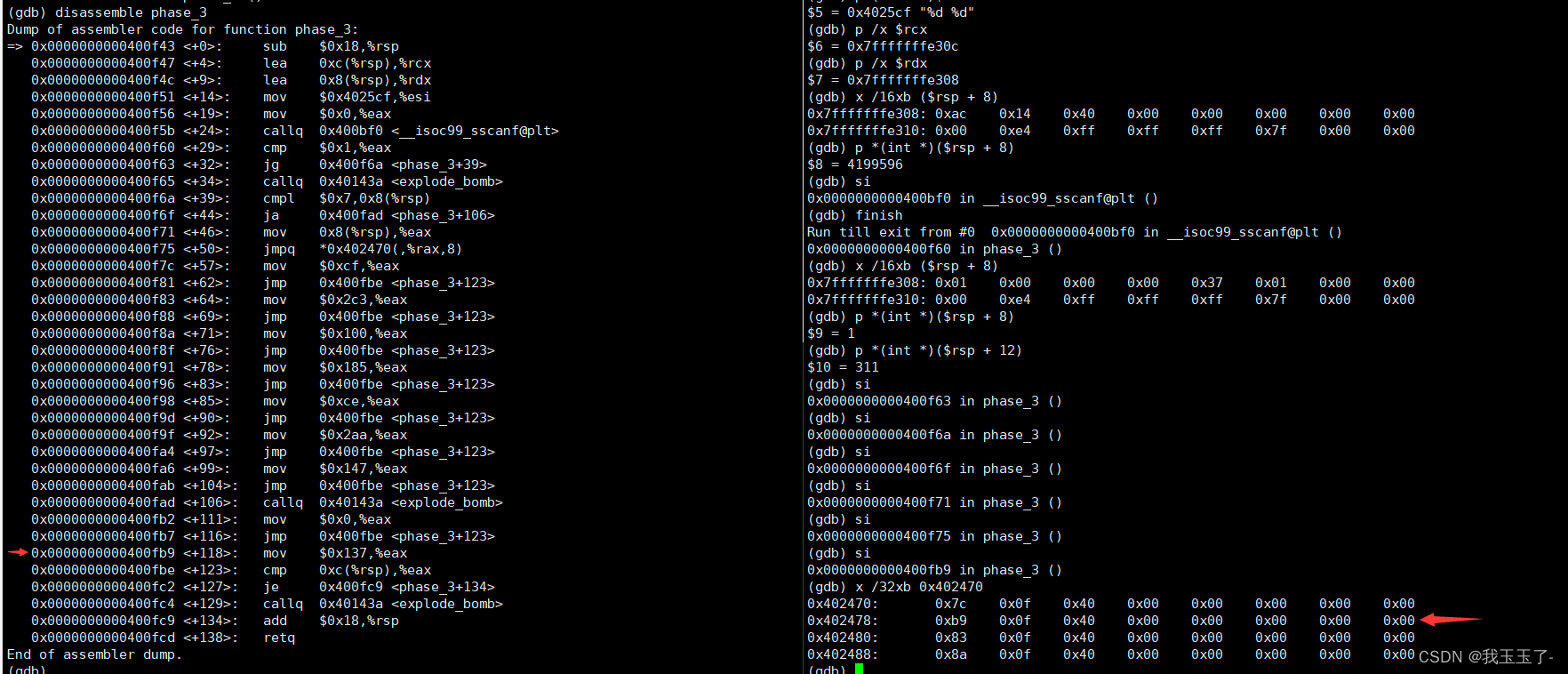
仔细看,在地址0x402478中存放的内容是:
指令mov $0x137,%eax 的地址 0x0000000000400fb9。
跳转后,将我们输入的第二个数字与0x137比较。发现相等,成功解决phase_3。
划重点:成段汇编程序的结构,明显对应着课上讲过的Switch-case语句汇编后的格式。Switch-case语句的底层实现构造了跳转表。jmpq *0x402470(,%rax,8)中的0x402470就是跳转表的首地址。
我们输入的数字相当于是一个数组下标,用来选出跳转表的表项,并把表项当成一个地址,进行进一步的跳转。
在phase_3中,需要保证第一个数字在[0,7]之间,第二个数字是什么取决于第一个数字,故本phase答案不唯一。读者可另作尝试。
phase_4
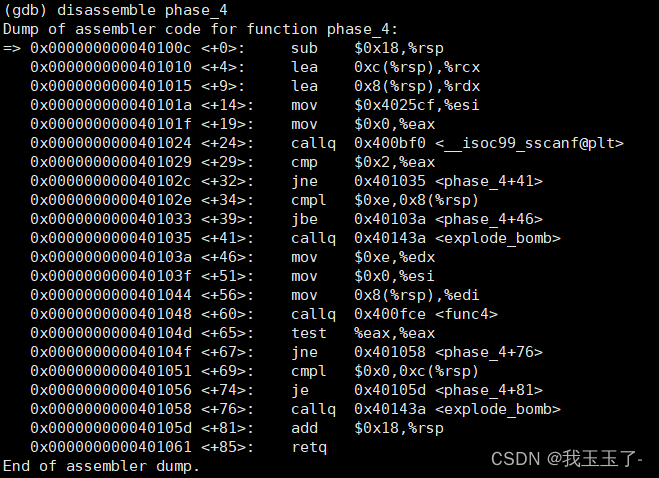
phase_4的输入部分phase_3很像,同样是输入两个数字。
在(%rsp+8)的地址处存放的是输入的第一个数字,在(%rsp+12)的地方存放的是第二个数字。
jbe指令是用于无符号数小于等于则跳转的意思。故下面的代码段透露的信息是第一个数字应该属于[0,14]。
0x000000000040102e <+34>: cmpl $0xe,0x8(%rsp)
0x0000000000401033 <+39>: jbe 0x40103a <phase_4+46>
接着执行,phase_4函数调用了func_4,func_4汇编代码如下:
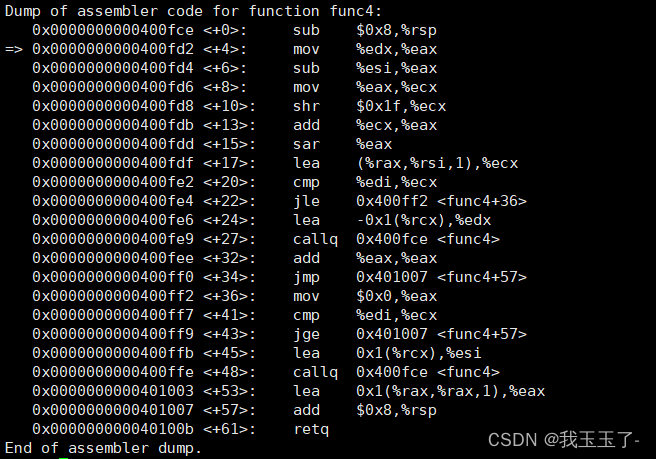
func4函数具体没有什么确切的含义,只是一系列操作。
它以我们输入的第一个数为第一个参数参数,常数14为第二个参数,常数0为第三个参数。
注意到phase_4函数中有
0x0000000000401048 <+60>: callq 0x400fce <func4>
0x000000000040104d <+65>: test %eax,%eax
0x000000000040104f <+67>: jne 0x401058 <phase_4+76>
0x0000000000401051 <+69>: cmpl $0x0,0xc(%rsp)
0x0000000000401056 <+74>: je 0x40105d <phase_4+81>
0x0000000000401058 <+76>: callq 0x40143a <explode_bomb>
0x000000000040105d <+81>: add $0x18,%rsp
说明函数func4的返回值存入%rax中,且其值需要是0才能不会引爆炸弹。考虑到func4它的确没有什么具体的含义,且我们输入的第一个数是[0,14]可以一个一个去试。
在func4中要学会的是:
- SHL,SHR 对应着逻辑左移,逻辑右移
- SAL, SAL 对应着算数左移,算数右移
此外,我们输入的第二个数一定得是0。如果不是0,在<+74>处就不会跳转,从而引爆炸弹。
phase_5
假设我的输入是:
ionefg
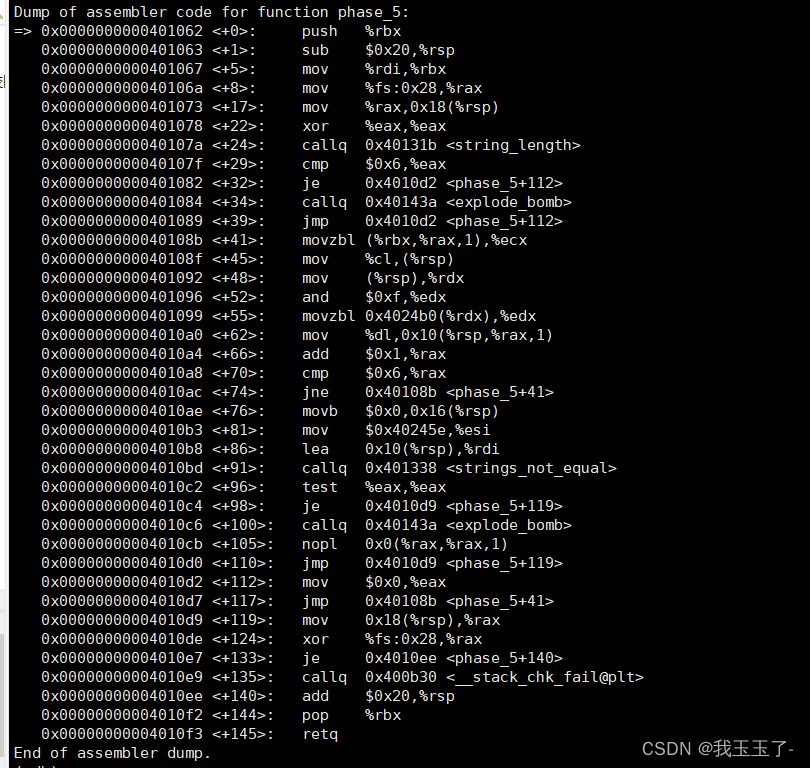
大致浏览后可以发现,本次任务又是要比较字符串是否相等。不过不同于phase_1,这次的字符串被“加密”过,不能直接从%rsi中获取。
核心代码在这段:
0x000000000040108b <+41>: movzbl (%rbx,%rax,1),%ecx
0x000000000040108f <+45>: mov %cl,(%rsp)
0x0000000000401092 <+48>: mov (%rsp),%rdx
0x0000000000401096 <+52>: and $0xf,%edx
0x0000000000401099 <+55>: movzbl 0x4024b0(%rdx),%edx
0x00000000004010a0 <+62>: mov %dl,0x10(%rsp,%rax,1)
0x00000000004010a4 <+66>: add $0x1,%rax
0x00000000004010a8 <+70>: cmp $0x6,%rax
0x00000000004010ac <+74>: jne 0x40108b <phase_5+41>
0x00000000004010ae <+76>: movb $0x0,0x16(%rsp)
0x00000000004010b3 <+81>: mov $0x40245e,%esi
0x00000000004010b8 <+86>: lea 0x10(%rsp),%rdi
0x00000000004010bd <+91>: callq 0x401338 <strings_not_equal>
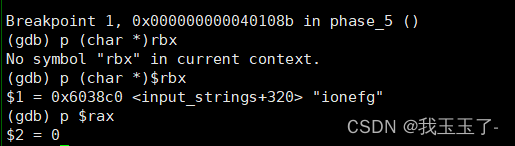
%rbx寄存器中存放的是我们输入字符串的首地址,%rax存放的是相对于该输入字符串的下标偏移量,用人话解释就是如果把我们的输入看作是一个字符数组,%rbx中存放的是“数组名”,%rax中存放的是数组下标。我们看看上述核心代码做了什么?
- 从输入的字符数组中取出一个字符,将其ascii二进制表示写入%rcx中
- 将%rcx的低8位写入%rsp所指向内存空间,把该数也写道%rdx中
- 把除了%rdx中的低4位全都置0,保留低4位
- 把(0x4024b0+%rdx) 地址处的值放入%rdx中。这里为什么突然来一个0x4024b0呢?检查一下这块地址。看起来一头雾水

没办法,接着向下执行,模仿phase_1的操作,看看调用string_not_equal前%rsi寄存器,它应该保存了正确的“密码”

OK,聪明的读者应该已经看出来了,我们所输入的字符串中的字符,并不是“最终的字符”而是要把这个字符的低4位看作是一个数组下标,在以0x4024b0为首地址的字符数组上用这个下标找到新的字符。我们在0x4024b0这个字符数组中分别找字符f、l、y、e、r、s相对于0x4024b0的偏移量,偏移量分别是:9(1001 二进制表示,下同)、15(1111)、14(1110)、5(0101)、6(0111)、7(0111)。最后,我们只需要去网上找一个ascii字母表,看哪个字母它的二进制表示的后4位能和上面五个数字之一匹配。这个phase答案不唯一,读者可自行尝试。
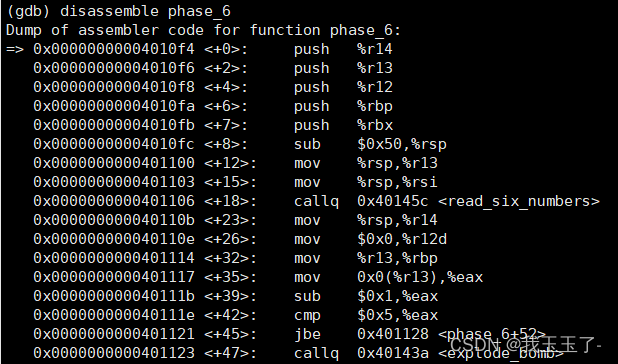
phase_6
(gdb) disassemble phase_6
Dump of assembler code for function phase_6:
=> 0x00000000004010f4 <+0>: push %r14
0x00000000004010f6 <+2>: push %r13
0x00000000004010f8 <+4>: push %r12
0x00000000004010fa <+6>: push %rbp
0x00000000004010fb <+7>: push %rbx
0x00000000004010fc <+8>: sub $0x50,%rsp
0x0000000000401100 <+12>: mov %rsp,%r13
0x0000000000401103 <+15>: mov %rsp,%rsi
0x0000000000401106 <+18>: callq 0x40145c <read_six_numbers>
0x000000000040110b <+23>: mov %rsp,%r14
0x000000000040110e <+26>: mov $0x0,%r12d
0x0000000000401114 <+32>: mov %r13,%rbp
0x0000000000401117 <+35>: mov 0x0(%r13),%eax
0x000000000040111b <+39>: sub $0x1,%eax
0x000000000040111e <+42>: cmp $0x5,%eax
0x0000000000401121 <+45>: jbe 0x401128 <phase_6+52>
0x0000000000401123 <+47>: callq 0x40143a <explode_bomb>
0x0000000000401128 <+52>: add $0x1,%r12d
0x000000000040112c <+56>: cmp $0x6,%r12d
0x0000000000401130 <+60>: je 0x401153 <phase_6+95>
0x0000000000401132 <+62>: mov %r12d,%ebx
0x0000000000401135 <+65>: movslq %ebx,%rax
0x0000000000401138 <+68>: mov (%rsp,%rax,4),%eax
0x000000000040113b <+71>: cmp %eax,0x0(%rbp)
0x000000000040113e <+74>: jne 0x401145 <phase_6+81>
0x0000000000401140 <+76>: callq 0x40143a <explode_bomb>
0x0000000000401145 <+81>: add $0x1,%ebx
0x0000000000401148 <+84>: cmp $0x5,%ebx
0x000000000040114b <+87>: jle 0x401135 <phase_6+65>
0x000000000040114d <+89>: add $0x4,%r13
0x0000000000401151 <+93>: jmp 0x401114 <phase_6+32>
0x0000000000401153 <+95>: lea 0x18(%rsp),%rsi
0x0000000000401158 <+100>: mov %r14,%rax
0x000000000040115b <+103>: mov $0x7,%ecx
0x0000000000401160 <+108>: mov %ecx,%edx
0x0000000000401162 <+110>: sub (%rax),%edx
0x0000000000401164 <+112>: mov %edx,(%rax)
0x0000000000401166 <+114>: add $0x4,%rax
0x000000000040116a <+118>: cmp %rsi,%rax
0x000000000040116d <+121>: jne 0x401160 <phase_6+108>
0x000000000040116f <+123>: mov $0x0,%esi
0x0000000000401174 <+128>: jmp 0x401197 <phase_6+163>
0x0000000000401176 <+130>: mov 0x8(%rdx),%rdx
0x000000000040117a <+134>: add $0x1,%eax
0x000000000040117d <+137>: cmp %ecx,%eax
0x000000000040117f <+139>: jne 0x401176 <phase_6+130>
0x0000000000401181 <+141>: jmp 0x401188 <phase_6+148>
0x0000000000401183 <+143>: mov $0x6032d0,%edx
0x0000000000401188 <+148>: mov %rdx,0x20(%rsp,%rsi,2)
0x000000000040118d <+153>: add $0x4,%rsi
0x0000000000401191 <+157>: cmp $0x18,%rsi
0x0000000000401191 <+157>: cmp $0x18,%rsi
0x0000000000401195 <+161>: je 0x4011ab <phase_6+183>
0x0000000000401197 <+163>: mov (%rsp,%rsi,1),%ecx
0x000000000040119a <+166>: cmp $0x1,%ecx
0x000000000040119d <+169>: jle 0x401183 <phase_6+143>
0x000000000040119f <+171>: mov $0x1,%eax
0x00000000004011a4 <+176>: mov $0x6032d0,%edx
0x00000000004011a9 <+181>: jmp 0x401176 <phase_6+130>
0x00000000004011ab <+183>: mov 0x20(%rsp),%rbx
0x00000000004011b0 <+188>: lea 0x28(%rsp),%rax
0x00000000004011b5 <+193>: lea 0x50(%rsp),%rsi
0x00000000004011ba <+198>: mov %rbx,%rcx
0x00000000004011bd <+201>: mov (%rax),%rdx
0x00000000004011c0 <+204>: mov %rdx,0x8(%rcx)
0x00000000004011c4 <+208>: add $0x8,%rax
0x00000000004011c8 <+212>: cmp %rsi,%rax
0x00000000004011cb <+215>: je 0x4011d2 <phase_6+222>
0x00000000004011cd <+217>: mov %rdx,%rcx
0x00000000004011d0 <+220>: jmp 0x4011bd <phase_6+201>
0x00000000004011d2 <+222>: movq $0x0,0x8(%rdx)
0x00000000004011da <+230>: mov $0x5,%ebp
0x00000000004011df <+235>: mov 0x8(%rbx),%rax
0x00000000004011e3 <+239>: mov (%rax),%eax
0x00000000004011e5 <+241>: cmp %eax,(%rbx)
0x00000000004011e7 <+243>: jge 0x4011ee <phase_6+250>
0x00000000004011e9 <+245>: callq 0x40143a <explode_bomb>
0x00000000004011ee <+250>: mov 0x8(%rbx),%rbx
0x00000000004011f2 <+254>: sub $0x1,%ebp
0x00000000004011f5 <+257>: jne 0x4011df <phase_6+235>
0x00000000004011f7 <+259>: add $0x50,%rsp
0x00000000004011fb <+263>: pop %rbx
0x00000000004011fc <+264>: pop %rbp
0x00000000004011fd <+265>: pop %r12
0x00000000004011ff <+267>: pop %r13
0x0000000000401201 <+269>: pop %r14
0x0000000000401203 <+271>: retq
End of assembler dump.
phase_6是最麻烦也是最难的一个phase了,首先本phase读取6个数字。
下面代码都是对这读取到的六个数字做检查,比如这6个数字的范围需要在[1,6],数字两两不能相同。
0x000000000040110b <+23>: mov %rsp,%r14
0x000000000040110e <+26>: mov $0x0,%r12d
0x0000000000401114 <+32>: mov %r13,%rbp
0x0000000000401117 <+35>: mov 0x0(%r13),%eax
0x000000000040111b <+39>: sub $0x1,%eax
0x000000000040111e <+42>: cmp $0x5,%eax
0x0000000000401121 <+45>: jbe 0x401128 <phase_6+52>
0x0000000000401123 <+47>: callq 0x40143a <explode_bomb>
0x0000000000401128 <+52>: add $0x1,%r12d
0x000000000040112c <+56>: cmp $0x6,%r12d
0x0000000000401130 <+60>: je 0x401153 <phase_6+95>
0x0000000000401132 <+62>: mov %r12d,%ebx
0x0000000000401135 <+65>: movslq %ebx,%rax
0x0000000000401138 <+68>: mov (%rsp,%rax,4),%eax
0x000000000040113b <+71>: cmp %eax,0x0(%rbp)
0x000000000040113e <+74>: jne 0x401145 <phase_6+81>
0x0000000000401140 <+76>: callq 0x40143a <explode_bomb>
0x0000000000401145 <+81>: add $0x1,%ebx
0x0000000000401148 <+84>: cmp $0x5,%ebx
0x000000000040114b <+87>: jle 0x401135 <phase_6+65>
0x000000000040114d <+89>: add $0x4,%r13
接下来作者来了一个小把戏,下面汇编代码的意思是输入数字顺序不变,使用7 - 输入的数字。
比如我的输入序列为1 2 3 4 5 6。经过这个小把戏的处理后我的数字序列就变成了6 5 4 3 2 1。
这串数字序列下面分析会用到。
0x0000000000401153 <+95>: lea 0x18(%rsp),%rsi
0x0000000000401158 <+100>: mov %r14,%rax
0x000000000040115b <+103>: mov $0x7,%ecx
0x0000000000401160 <+108>: mov %ecx,%edx
0x0000000000401162 <+110>: sub (%rax),%edx
0x0000000000401164 <+112>: mov %edx,(%rax)
0x0000000000401166 <+114>: add $0x4,%rax
0x000000000040116a <+118>: cmp %rsi,%rax
0x000000000040116d <+121>: jne 0x401160 <phase_6+108>
0x000000000040116f <+123>: mov $0x0,%esi
剩下这段代码是什么意思呢?这是本phase的核心代码段
0x000000000040116f <+123>: mov $0x0,%esi
0x0000000000401174 <+128>: jmp 0x401197 <phase_6+163>
0x0000000000401176 <+130>: mov 0x8(%rdx),%rdx
0x000000000040117a <+134>: add $0x1,%eax
0x000000000040117d <+137>: cmp %ecx,%eax
0x000000000040117f <+139>: jne 0x401176 <phase_6+130>
0x0000000000401181 <+141>: jmp 0x401188 <phase_6+148>
0x0000000000401183 <+143>: mov $0x6032d0,%edx
0x0000000000401188 <+148>: mov %rdx,0x20(%rsp,%rsi,2)
0x000000000040118d <+153>: add $0x4,%rsi
0x0000000000401191 <+157>: cmp $0x18,%rsi
0x0000000000401191 <+157>: cmp $0x18,%rsi
0x0000000000401195 <+161>: je 0x4011ab <phase_6+183>
0x0000000000401197 <+163>: mov (%rsp,%rsi,1),%ecx
0x000000000040119a <+166>: cmp $0x1,%ecx
0x000000000040119d <+169>: jle 0x401183 <phase_6+143>
0x000000000040119f <+171>: mov $0x1,%eax
0x00000000004011a4 <+176>: mov $0x6032d0,%edx
0x00000000004011a9 <+181>: jmp 0x401176 <phase_6+130>
建议小伙伴们在调试这一段时一定要细扣函数的内存布局,你会清楚很多。
注意到这条指令引用了一个奇怪的地址,打印出来看看:
0x00000000004011a4 <+176>: mov $0x6032d0,%edx
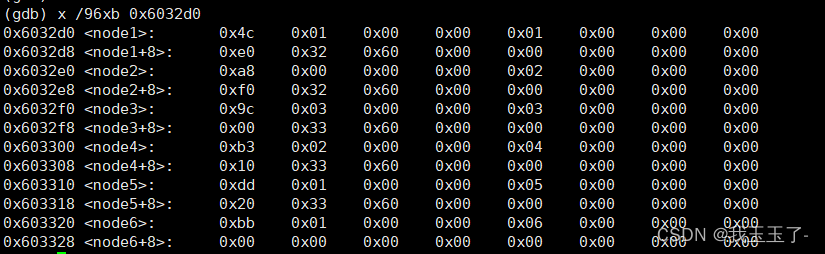
这段代码执行完是什么效果呢,就是按着6 5 4 3 2 1的顺序,从(%rsp+32)的位置开始,分别记录node6 node5 node4 node3 node2 node1 的地址。
我举得例子是这个顺序,换个例子比如此时经过作者恶作剧处理过后的数字序列为3 4 5 6 1 2。
那么自(%rsp+32)的位置开始,分别记录node3 node4 node5 node6 node1 node2 的地址。检查下内存布局,看看是不是我们想的这样:
(这里举一个额外的例子,下面我们还用6 5 4 3 2 1为例)
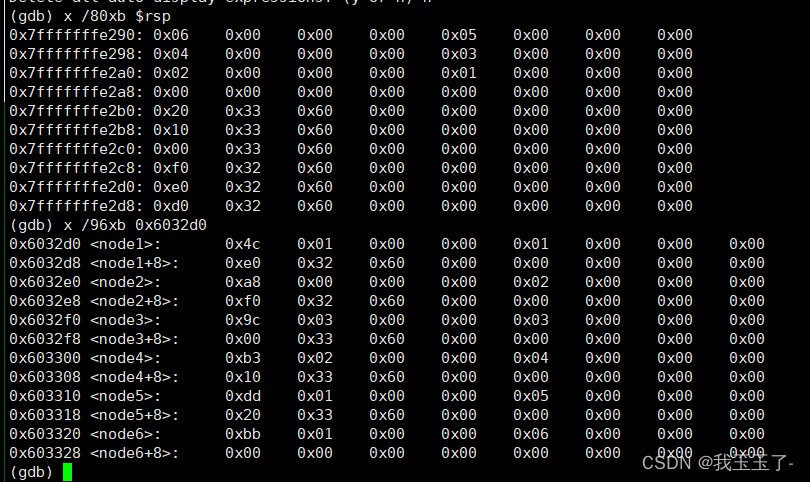
可以看到和我们想的一样,0x7fffffffe2b0处所存储的地址正是node6的地址
接着执行,处理下面的代码段:
0x00000000004011ab <+183>: mov 0x20(%rsp),%rbx
0x00000000004011b0 <+188>: lea 0x28(%rsp),%rax
0x00000000004011b5 <+193>: lea 0x50(%rsp),%rsi
0x00000000004011ba <+198>: mov %rbx,%rcx
0x00000000004011bd <+201>: mov (%rax),%rdx
0x00000000004011c0 <+204>: mov %rdx,0x8(%rcx)
0x00000000004011c4 <+208>: add $0x8,%rax
0x00000000004011c8 <+212>: cmp %rsi,%rax
0x00000000004011cb <+215>: je 0x4011d2 <phase_6+222>
0x00000000004011cd <+217>: mov %rdx,%rcx
0x00000000004011d0 <+220>: jmp 0x4011bd <phase_6+201>
回顾上面的对node1 ~ node6处内存检查,<node + 8>这前面一直没有用到,在这里终于用到了。
回顾上一代码段我们得到自(%rsp + 32)开始,内存中分别放入了node6 node5 node4 node3 node2 node1 的地址。我们可以把这个地址序列,当成是逻辑上的序列,即我们希望node的排布顺序是这样的
但是实际上我们检查内存看到了,物理上node们的排布顺序是实打实地按1 2 3 4 5 6的顺序。
怎么办?**联系链表的思想,我们在<node+8>处放后继元素的地址就好了!**实际上上述代码段做的就是这个工作。至此node的含义也搞清楚了,node中含有两个元素,一个元素是自身的value,另一个元素是后继元素的地址。
0x00000000004011d2 <+222>: movq $0x0,0x8(%rdx)
0x00000000004011da <+230>: mov $0x5,%ebp
0x00000000004011df <+235>: mov 0x8(%rbx),%rax
0x00000000004011e3 <+239>: mov (%rax),%eax
0x00000000004011e5 <+241>: cmp %eax,(%rbx)
0x00000000004011e7 <+243>: jge 0x4011ee <phase_6+250>
0x00000000004011e9 <+245>: callq 0x40143a <explode_bomb>
0x00000000004011ee <+250>: mov 0x8(%rbx),%rbx
0x00000000004011f2 <+254>: sub $0x1,%ebp
0x00000000004011f5 <+257>: jne 0x4011df <phase_6+235>
0x00000000004011f7 <+259>: add $0x50,%rsp
0x00000000004011fb <+263>: pop %rbx
0x00000000004011fc <+264>: pop %rbp
0x00000000004011fd <+265>: pop %r12
0x00000000004011ff <+267>: pop %r13
0x0000000000401201 <+269>: pop %r14
0x0000000000401203 <+271>: retq
最后一段代码,比较简单了,按前面的分析,我们直到node们实际上是链表中的节点。这部分代码段的功能是判断相邻两个节点中,靠近头节点的节点要比靠近尾节点的value大。
用人话解释就是,假设链表头在左,链表尾在右,对相邻节点来说,左边value域中的值要比右边value域中的值要大。答案是序列4 3 2 1 6 5
至此phase_6已经全部分析完成。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









