







-
语料库必须是数字化的、有一定规模的、能被计算机程序处理的语料集合。
-
语料库研究的主题演变
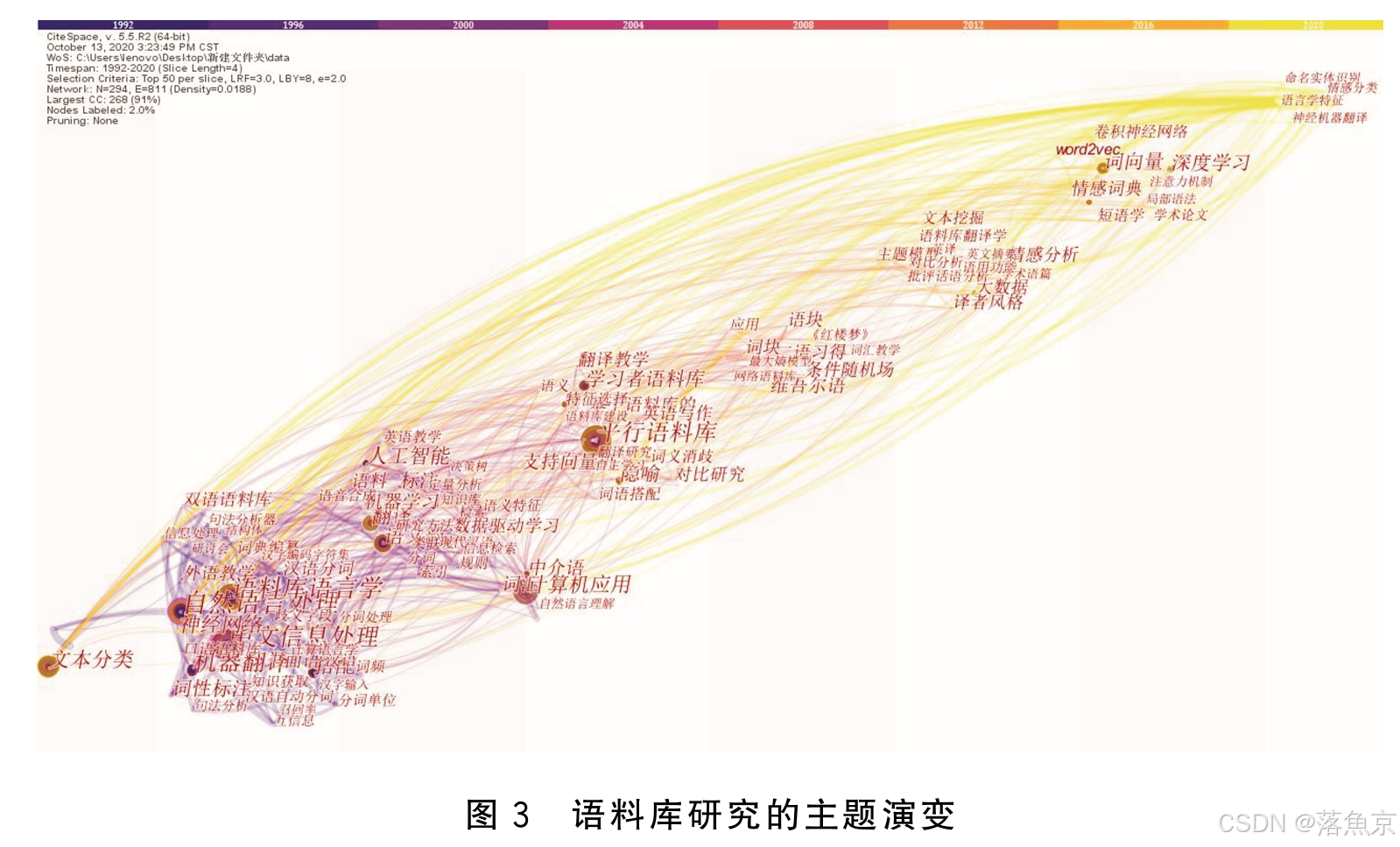
-
构建流程
构建语料库一般需要经过语料库设计、语料采集、数据标注、数据存储、数据更新和维护等步骤 -
数据来源
文献数据库、专业新闻网站、用户发布在网络上的产品评论、古籍文本、行业数据库等 -
数据标注
- 语料库数据标注粒度
- 语料库数据标注策略
-
应用
- 郑艳群从语料库建设、加工和应用方面总结了语料库技术在汉语教学中取得的成绩,比如在语料库加工中的错别字及语音语料标注技术、语法偏误自动识别技术等。
- 郑艳群从语料库建设、加工和应用方面总结了语料库技术在汉语教学中取得的成绩,比如在语料库加工中的错别字及语音语料标注技术、语法偏误自动识别技术等。
- 郝国生等基于语料库构建了语义解释空间原型系统,并将其应用于语义关联词汇检索
-
优秀语料库
- 清华TH语料库
清华TH语料库于1994年6月建成,其总库根据对语料加工深度的不同采用分级管理的原则,分成了生语料和熟语料两大类,其中0级生语料分库涵盖了一般书、报纸、论文、杂志、工具书等五类子库语料素材。经过近年来不断的升级和更新,已更名为THCHS-30语料库。
http://www.openslr.org/18 - 人民日报标注语料库
该语料库是我国第一个大型的现代汉语标注语料库,以《人民日报》1998年的纯文本语料为基础,完成词语切分、词性标注、专有名词标注、语素子类标注、动词和形容词特殊用法标注、短语型标注等加工工作,现已扩充至3500万字的规模。后来北京大学计算语言学研究所在此基础上完成了另外100万字语料的词语切分、词性标注和汉语拼音标注的加工任务,还利用所研制的《现代汉语语义词典》、参照《现代汉语词典》,根据语料实际使用情况对词义描写进行调整,研发了一个大规模、高质量的现代汉语词义标注语料库(Chinese Word Sense Tagging Corpus,STC)。为了弥补北京大学人民日报语料库用于处理当前文本时的不足,2019年开始南京农业大学人文与社会计算研究中心以2015年至2018年《人民日报》发表的文章为对象,构建了新时代人民日报语料库,目前该语料库涵盖了《人民日报》2015 年1-5 月、2016年1月、2017年1月、2018 年1月共9个月的分词语料,并且后续将不断补充最新语料 。
http://corpus.njau.edu.cn/
- 清华TH语料库
- more
37个国内常用语料库集锦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









