







Diffusion扩散模型(上)
1.模型简介
如果将Diffusion与其他生成模型(如Normalizing Flows、GAN或VAE)进行比较,它并没有那么复杂,它们都将噪声从一些简单分布转换为数据样本,Diffusion也是从纯噪声开始通过一个神经网络学习逐步去噪,最终得到一个实际图像。 Diffusion对于图像的处理包括以下两个过程:
-
我们选择的固定(或预定义)正向扩散过程𝑞𝑞:它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声
-
一个学习的反向去噪的扩散过程𝑝𝜃𝑝𝜃:通过训练神经网络从纯噪声开始逐渐对图像去噪,直到最终得到一个实际的图像

(1)扩散模型实现原理
包括Diffusion 前向过程,所谓前向过程,即向图片上加噪声的过程。
Diffusion 逆向过程,逆向过程(reverse)就是diffusion的去噪推断过程
U-Net神经网络预测噪声
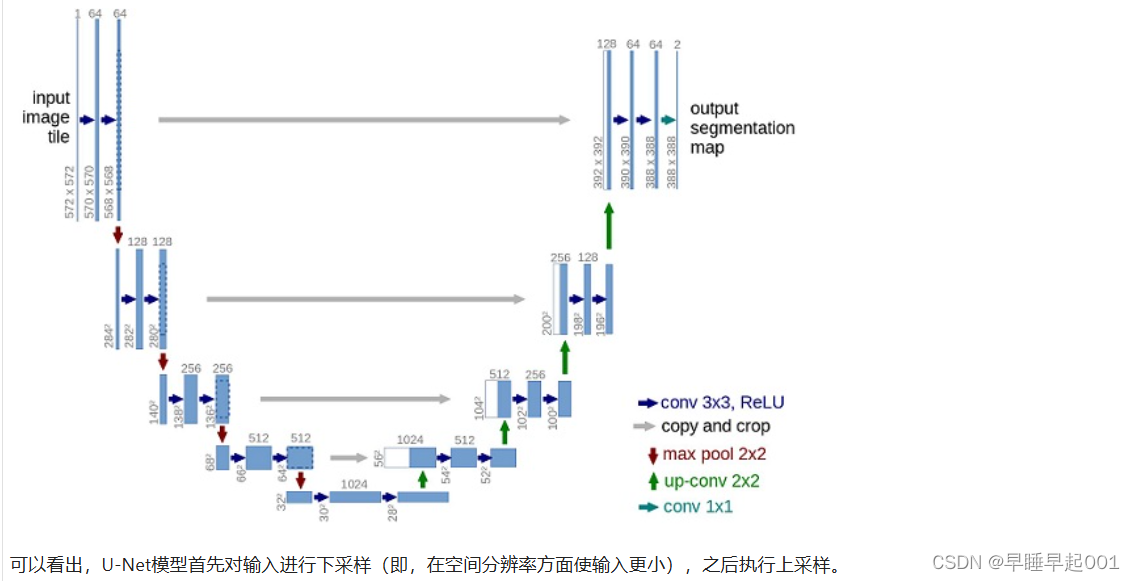
2.构建Diffusion模型

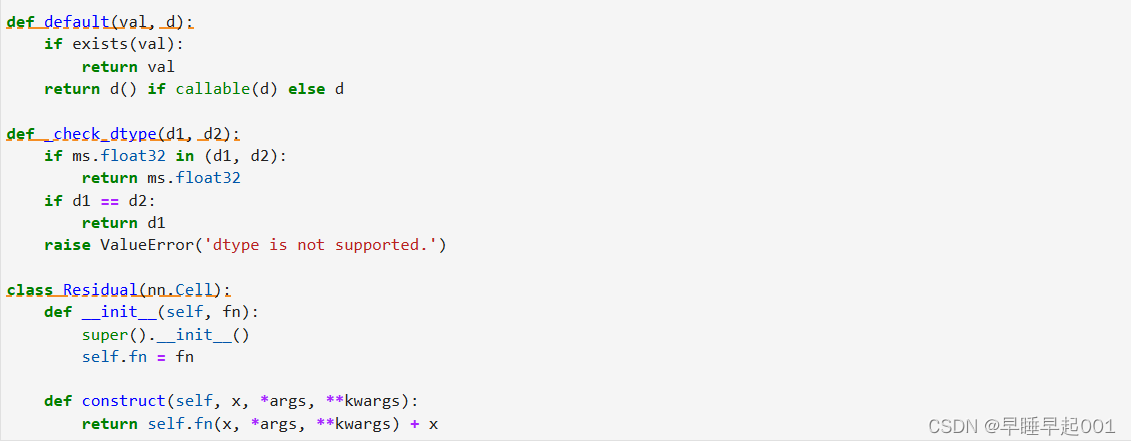

(1)位置向量

(2)ResNet/ConvNeXT块
U-Net模型的核心构建块,选择ConvNeXT块构建U-Net模型。
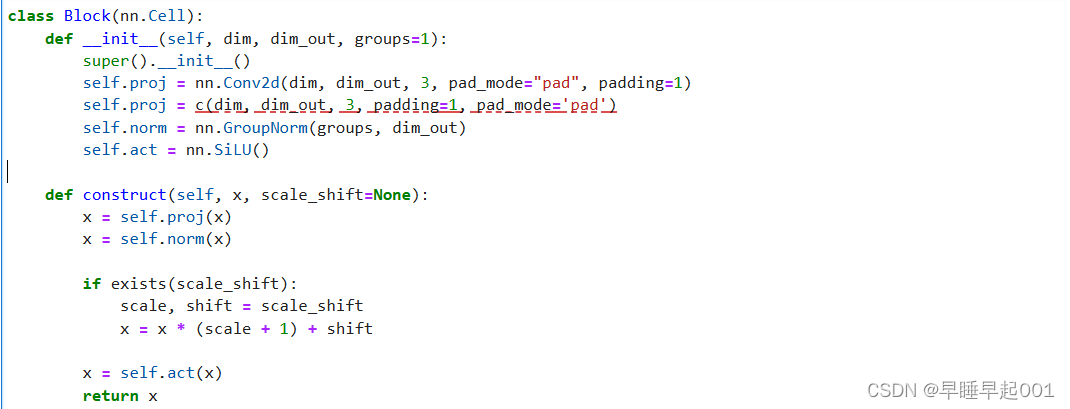
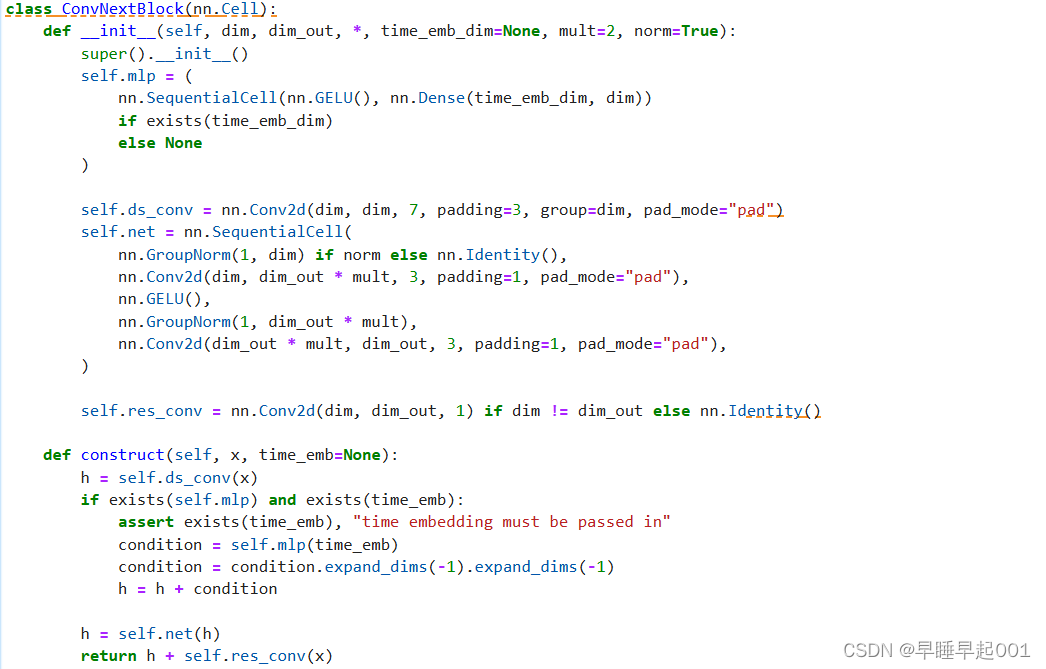
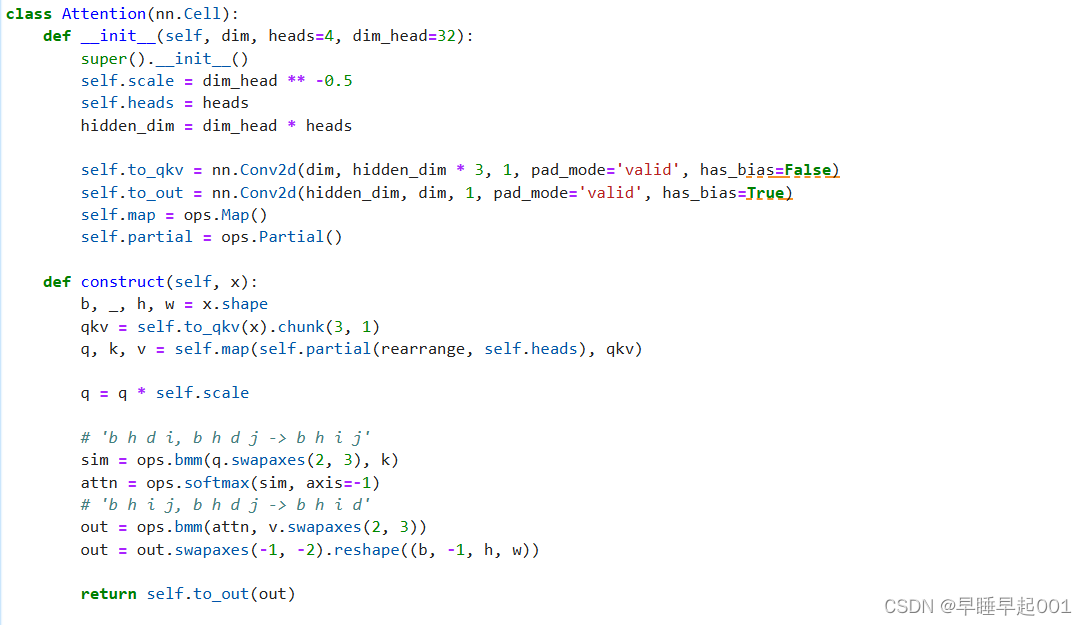
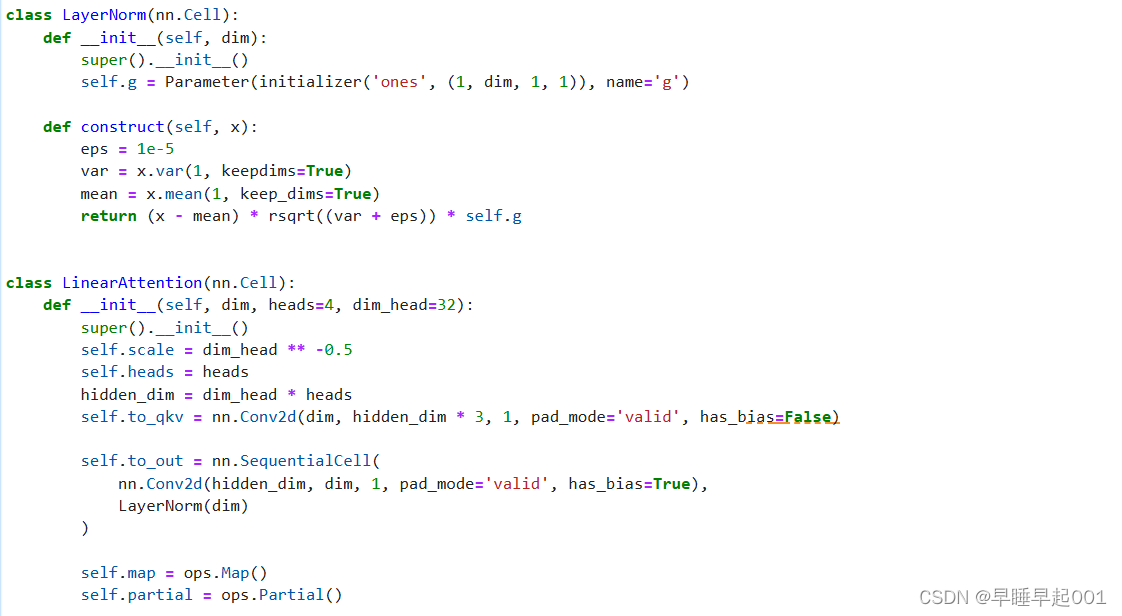
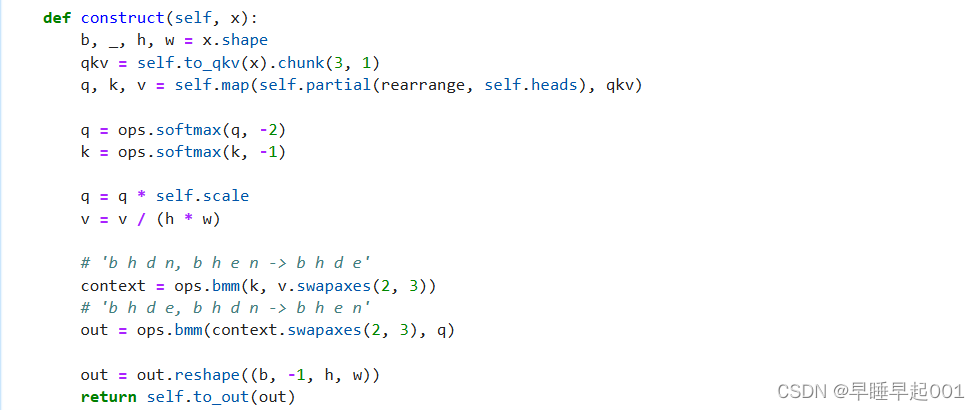
(3)Attention模块
Attention是著名的Transformer架构,在人工智能的各个领域都取得了巨大的成功,从NLP到蛋白质折叠。
Phil Wang使用了两种注意力变体:一种是常规的多头自我关注(如Transformer中使用的),另一种是LinearAttention,,其时间和内存要求在序列长度上线性缩放,而不是在常规注意力中缩放。
学习时间及id:
















 218
218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









