







密码找回
首先在mysql配置文件my.cnf中,添加下面跳过密码验证语句,保存退出,并重启数据库。
skip-grant-tables
然后无密码登录mysql,重新使用下面命令设置root用户密码。
mysql> UPDATE mysql.user SET authentication_string=password('new_password') WHERE user='root' AND host='localhost';
mysql> flush privileges; #刷新权限
将配置文件中跳过密码验证语句注释并保存,然后重启服务,使用新密码登陆即可。
mysql数据类型
分为三类:数值类型、字符串类型】时间和日期类型
-
数值类型
整数类型:TINYINT、LLINT、MEDUIMINT、INT、BIGINT;
作用:用于存储用户的年龄、游戏的Level、经验值等。

浮点数类型:FLOAT DOUBLE
作用:用于存储用户的身高、体重、薪水等;
float(5.3) 宽度5,精度3,宽度不算小数点

定点数类型:DEC
定点数在MYSQL内部以字符串形式存储,比浮点数的更精准,适合用来表示货币等高精度数据;
位类型:BIT
BIT(M)可以用来存放多位二进制数,M范围从1~64,如果不写默认为1; -
字符串类型
char表示定长字符串,长度是固定的;如果插入数据的长度小于char的固定长度时,则用空格填充;因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间。
varchar表示可变长字符串,长度是可变的;插入的数据是多长,就按照多长来存储;varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间。
结合性能角度(char更快),节省磁盘空间角度(varchar更小),具体情况还需具体来设计数据库才是妥当的做法。CHAR系列 CHAR VARCHAR
TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT
BLOB系列 TINYBLOB BLOB MEDIUMBLOB LONGBLOB
BINARY系列 BINARY VARBINARY
枚举类型 ENUM
集合类型 SET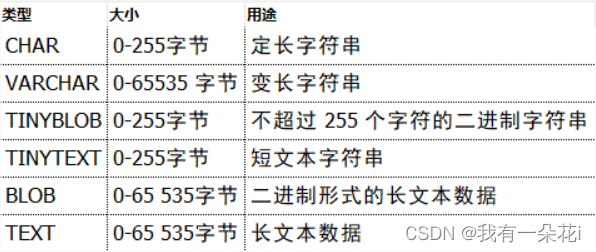
枚举类型:枚举可以把一些不重复的字符串存储成一个预定义的集合; -
日期类型
时间和日期类型:year、date、time、datetime、timestamp
户的注册时间,文章的发布时间,文章的更新时间,员工的入职时间等
注意事项:
插入年份时,尽量使用4位值
插入两位年份时:
<=69,以20开头,比如65, 结果2065;>=70,以19开头,比如82,结果1982

timestamp 类型的列还有个特性:默认情况下,在 insert, update 数据时,timestamp 列会自动以当前时间(CURRENT_TIMESTAMP)填充/更新。“自动”的意思就是,你不去管它,MySQL 会替你去处理。
库操作
系统数据库
information_schema: 虚拟库,主要存储了系统中的一些数据库对象的信息,例如用户表信息、列信息、权限信息、字符信息等
performance_schema: 主要存储数据库服务器的性能参数
mysql: 授权库,主要存储系统用户的权限信息
sys: 主要存储数据库服务器的性能参数
- 创建数据库:DDL
mysqladmin -u root -p1 password ‘123’
mysql -u root -pQianFeng@123 -e “show databases”
mysql -u root -pQianFeng@123 -e “create database sipeng”
mysql> create database dname;
数据库命名规则:区分大小写、唯一性、不能使用关键字如 create select、不能单独使用数字; - 查看数据库
mysql> show databases;
mysql> show create database xingdian;
mysql> select database(); 查看当前所在的库 - 切换数据库
mysql> use xingdian;
mysql> show tables; - 删除数据库
DROP DATABASE 数据库名;
表完整性约束
作用:用于保证数据的完整性和一致性
约束条件 说明
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录,不可以为空 UNIQUE + NOT NULL
FOREIGN KEY (FK) 标识该字段为该表的外键,实现表与表之间的关联
NULL 标识是否允许为空,默认为NULL。
NOT NULL 标识该字段不能为空,可以修改。
UNIQUE KEY (UK) 标识该字段的值是唯一的,可以为空,一个表中可以有多个UNIQUE KEY
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号,正数
表操作
-
创建表
create table 表名 (字段 类型 [宽度 约束条件]), (字段 类型 [宽度 约束条件]) 存储引擎 default charset=8(字符集);
-
查看表
select 字段 from 表名; #查看表数据
DESC 表名; show create table 表名; #查看表结构 -
插入数据
insert into 表名[字段] values(值),(值)
可以指定字段插入数据,也可以按照顺序依次插入;可以只赋值一次,也可以同时赋值多次值;如果是字符串大家一定要用引号 enum: ‘a’ set: ‘dog’ ‘dog,pig’ -
修改表
增加字段
alter table 表名 add 字段 类型 约束条件,add 字段 类型 约束条件 first(after id)
修改表名
alter table 旧表名 rename 新表名;
修改字段名
alter table 表名 change 旧字段名 新字段名 旧类型 旧约束条件
修改字段
alter table 表名 change 旧字段名 新字段名 新类型 新约束条件
alter table 表名 modify 字段 类型 约束条件 -
复制表
create table 新表名 select * from 旧表名 复制表结构和值,但是不复制主键
create table 新表名 select * from where 1=2 假条件 复制表结构,不复制主键
create table 新表名 like 旧表名 只复制表结+主键 -
删除
删除字段
alter table 表名 drop 字段名;
删除表
drop table 表名;
删除数据
delete from 表名 where id=1 删除数据需要进行匹配删除 -
更新表
update 表名 set 字段=‘修改后的值’ where id=1; 匹配的内容具有唯一性 (unique + not null )
数据查询
简单查询:
select 字段名1,字段名2 from 表名 条件
select * from 表名 ;
select * from 表名 where 查询条件;
DISTINCT 避免重复,通常仅用于某一个字段
select distinct 字段名 from 表名 ;
例:select distinct columnname from tablename
通过四则运算查询
SELECT name, salary, salary*14 FROM employee5;
定义显示格式
CONCAT() 函数用于连接字符串
例:SELECT concat(name, 's annual salary: ', salary*14) AS Annual_salary FROM employee5;
多条件查询
AND、OR
例:SELECT name,salary FROM employee5 WHERE post=‘hr’ AND salary>10000;
select * from employee5 where salary>5000 and salary<10000 or dep_id=102;
关键字BETWEEN AND
例:SELECT name,salary FROM employee5 WHERE salary BETWEEN 5000 AND 15000;
关键字IS NULL
例:SELECT name,job_description FROM employee5 WHERE job_description IS NULL;
关键字IN集合查询
例:
SELECT name, salary FROM employee5 WHERE salary IN (4000,5000,6000,9000) ;
SELECT name, salary FROM employee WHERE salary NOT IN (4000,5000,6000,9000) ;
关键字LIKE模糊查询;通配符’% ’:所有字符;通配符’_’ 一个字符
SELECT * FROM employee5 WHERE name LIKE ‘al%’;
SELECT * FROM employee5 WHERE name LIKE ‘al___’;
排序查询 order by 、asc(升序)、desc(降序)
例:
select china from t1 order by china;(默认升序,asc可不写)
select china from t1 order by china desc;
分组查询:
GROUP BY和GROUP_CONCAT()函数一起使用
例:部门ID相同,就把名字拼到一起
SELECT dep_id,GROUP_CONCAT(name) FROM employee5 GROUP BY dep_id;
GROUP BY和集合函数一起使用
例:部门最高薪资
SELECT post,max(salary) FROM employee5 GROUP BY post;
HAVING:
where是一个约束条件,在查询数据库结果返回之前对查询条件进行约束,即并由于where的执行顺序在聚合函数之前,所以where后面不能使用聚合函数;
having是在查询数据库结果返回之后进行过滤,即在结果返回值后起作用,having一般必须用在group by后面,having后面可以跟聚合函数。















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









