







文章目录
补充:来自oracle 9i的经典测试表
表1:emp员工表
员工表创建语句如下:
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
接下来向员工表中插入一些数据:
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
结果显示:
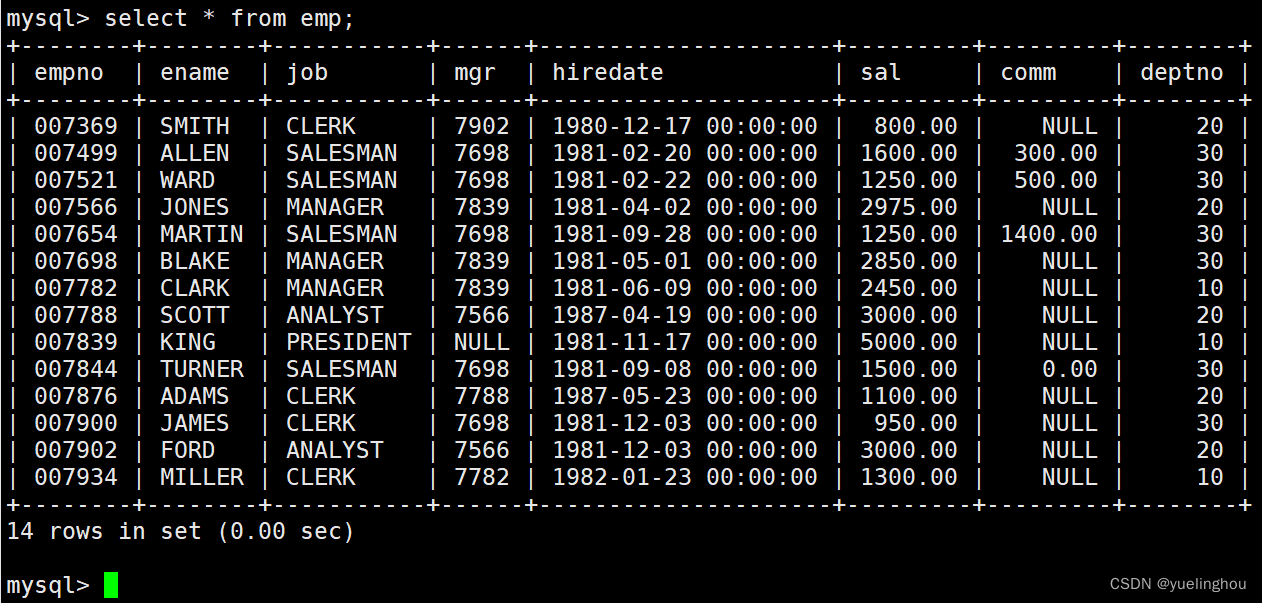
表2:dept部门表
部门表创建语句如下:
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',
`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
部门表数据插入:
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');
结果显示:
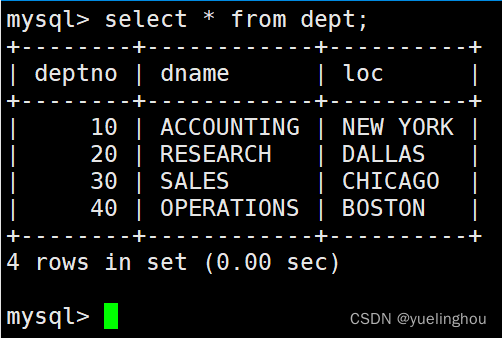
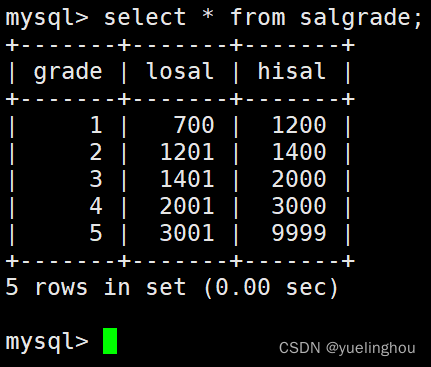
表3:salgrade工资等级表
工资等级表创建语句如下:
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (
`grade` int(11) DEFAULT NULL COMMENT '等级',
`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',
`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);
数据插入:
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
结果显示:
一. 聚合函数
1. 函数介绍
聚合函数又叫组函数,通常是对表中的数据进行统计和计算,一般结合分组(group by)来使用,用于统计和计算分组数据。
函数特点
- 每个组函数只能接收一个参数(字段名或者表达式) 统计结果中默认忽略字段为NULL的记录,要想列值为NULL的行也参与组函数的计算,必须使用IFNULL函数对NULL值做转换。
- 不允许嵌套使用组函数,比如sum(max(xx))。
- 可以在参数前加上DISTINCT先进行数据去重,然后在执行函数。
函数概览
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
2. 使用举例
为了方便举例,在这里新建一张学生成绩表,它包括如下5个字段:
id:学生的学号,设为自增长主键。name:学生姓名,不允许为空。chinese:语文成绩,可以为空,默认0.0分。math:数学成绩,可以为空,默认0.0分。english:英语成绩,可以为空,默认0.0分。
mysql> create table if not exists TestScores(
-> id int unsigned primary key auto_increment,
-> name varchar(20) not null,
-> chinese float default 0.0,
-> math float default 0.0,
-> english float default 0.0
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> desc TestScores;
+---------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| chinese | float | YES | | 0 | |
| math | float | YES | | 0 | |
| english | float | YES | | 0 | |
+---------+------------------+------+-----+---------+----------------+
5 rows in set (0.00 sec)
接下来向该表中插入一些数据:
mysql> insert into TestScores(name, chinese, math, english) values
-> ('曹操', 67, 98, 56),
-> ('孙权', 87, 78, 77),
-> ('孙策', 88, 98, 90),
-> ('刘备', 82, 84, 67),
-> ('程咬金', 55, 85, 45),
-> ('孙尚香', 70, 73, 78),
-> ('诸葛亮', 75, 65, 30);
Query OK, 7 rows affected (0.01 sec)
Records: 7 Duplicates: 0 Warnings: 0
1、统计班级共有多少同学
使用 * 做统计:
mysql> select * from TestScores;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 曹操 | 67 | 98 | 56 |
| 2 | 孙权 | 87 | 78 | 77 |
| 3 | 孙策 | 88 | 98 | 90 |
| 4 | 刘备 | 82 | 84 | 67 |
| 5 | 程咬金 | 55 | 85 | 45 |
| 6 | 孙尚香 | 70 | 73 | 78 |
| 7 | 诸葛亮 | 75 | 65 | 30 |
+----+-----------+---------+------+---------+
7 rows in set (0.00 sec)
mysql> select count(*) from TestScores;
+----------+
| count(*) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)
当然我们也可以把统计出来的结果重命名:
mysql> select count(*) as count_num from TestScores;
+-----------+
| count_num |
+-----------+
| 7 |
+-----------+
1 row in set (0.00 sec)
2、统计本次考试的数学成绩分数个数
以math字段为参数做统计,如果有NULL的话不会计入结果:
mysql> select * from TestScores;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 曹操 | 67 | 98 | 56 |
| 2 | 孙权 | 87 | 78 | 77 |
| 3 | 孙策 | 88 | 98 | 90 |
| 4 | 刘备 | 82 | 84 | 67 |
| 5 | 程咬金 | 55 | 85 | 45 |
| 6 | 孙尚香 | 70 | 73 | 78 |
| 7 | 诸葛亮 | 75 | 65 | 30 |
+----+-----------+---------+------+---------+
7 rows in set (0.00 sec)
mysql> select count(math) from TestScores;
+-------------+
| count(math) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)
此外,我们还可以使用DISTINCT先去重再统计,得到的是去重后的成绩数量:
mysql> select count(distinct math) from TestScores;
+----------------------+
| count(distinct math) |
+----------------------+
| 6 |
+----------------------+
1 row in set (0.00 sec)
3、统计数学成绩总分
使用sum聚合函数来计算数据的和。
mysql> select sum(math) from TestScores;
+-----------+
| sum(math) |
+-----------+
| 581 |
+-----------+
1 row in set (0.00 sec)
4、统计总平均分
使用avg聚合函数来计算平均值。
mysql> select avg(chinese+math+english) from TestScores;
+---------------------------+
| avg(chinese+math+english) |
+---------------------------+
| 221.14285714285714 |
+---------------------------+
1 row in set (0.00 sec)
5、返回英语最高分
使用max聚合函数来统计数据中的最大值。
mysql> select max(english) from TestScores;
+--------------+
| max(english) |
+--------------+
| 90 |
+--------------+
1 row in set (0.00 sec)
PS:对应的还有个min聚合函数用来统计数据中的最小值。
3. group by子句的使用
在select中使用group by子句可以对指定列进行分组查询,聚合函数常常需要结合group by子句一起使用。
举例:使用文章最开始的oracle 9i经典测试表
1、显示每个部门的平均工资和最高工资
// 1、查看emp表的数据
mysql> select * from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.00 sec)
// 2、按照部门号对所有员工分组,然后以组为单位计算组内所有员工的平均工资和最高工资
mysql> select deptno, avg(sal), max(sal) from emp group by deptno;
+--------+-------------+----------+
| deptno | avg(sal) | max(sal) |
+--------+-------------+----------+
| 10 | 2916.666667 | 5000.00 |
| 20 | 2175.000000 | 3000.00 |
| 30 | 1566.666667 | 2850.00 |
+--------+-------------+----------+
3 rows in set (0.01 sec)
PS:这里必须使用group by字句进行分组然后才能计算,因为我们最开始还查询了部门号deptno。
// error:没有分组的话聚合函数默认统计所有员工的数据,但是这里select又查询了部门号deptno
// 这样同时显示出来会有歧义,所以要使用group by进行分组
mysql> select deptno, avg(sal), max(sal) from emp;
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'scott.emp.deptno'; this is incompatible with sql_mode=only_full_group_by
// 不查询部门号deptno的话就没什么问题,这时统计的是所有员工的数据
mysql> select avg(sal), max(sal) from emp;
+-------------+----------+
| avg(sal) | max(sal) |
+-------------+----------+
| 2073.214286 | 5000.00 |
+-------------+----------+
1 row in set (0.00 sec)
2、显示每个部门的每种岗位的平均工资和最低工资

使用group by先对部门分组然后内部进行岗位分组,最后使用聚合函数计算结果:
// 1、查询emp中表的数据
mysql> select * from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.00 sec)
// 2、group by后面跟需要分组的字段,有先后顺序
mysql> select avg(sal) 平均工资, min(sal) 最低工资, job, deptno from emp group by deptno, job;
+--------------+--------------+-----------+--------+
| 平均工资 | 最低工资 | job | deptno |
+--------------+--------------+-----------+--------+
| 1300.000000 | 1300.00 | CLERK | 10 |
| 2450.000000 | 2450.00 | MANAGER | 10 |
| 5000.000000 | 5000.00 | PRESIDENT | 10 |
| 3000.000000 | 3000.00 | ANALYST | 20 |
| 950.000000 | 800.00 | CLERK | 20 |
| 2975.000000 | 2975.00 | MANAGER | 20 |
| 950.000000 | 950.00 | CLERK | 30 |
| 2850.000000 | 2850.00 | MANAGER | 30 |
| 1400.000000 | 1250.00 | SALESMAN | 30 |
+--------------+--------------+-----------+--------+
9 rows in set (0.00 sec)
PS:在select后面的列名称(除聚合函数外),如果后续我们要进行group by分组,那么凡是在select中出现的原表中的列名称,也必须在group by中出现。
// error:查询了select字段,但是没有以它进行分组
mysql> select avg(sal) 平均工资, min(sal) 最低工资, job, deptno from emp group by deptno;
ERROR 1055 (42000): Expression #3 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'scott.emp.job' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
// succeed:使用了聚合函数,查询的字段必须都分组
mysql> select avg(sal) 平均工资, min(sal) 最低工资, job, deptno from emp group by deptno, job;
+--------------+--------------+-----------+--------+
| 平均工资 | 最低工资 | job | deptno |
+--------------+--------------+-----------+--------+
| 1300.000000 | 1300.00 | CLERK | 10 |
| 2450.000000 | 2450.00 | MANAGER | 10 |
| 5000.000000 | 5000.00 | PRESIDENT | 10 |
| 3000.000000 | 3000.00 | ANALYST | 20 |
| 950.000000 | 800.00 | CLERK | 20 |
| 2975.000000 | 2975.00 | MANAGER | 20 |
| 950.000000 | 950.00 | CLERK | 30 |
| 2850.000000 | 2850.00 | MANAGER | 30 |
| 1400.000000 | 1250.00 | SALESMAN | 30 |
+--------------+--------------+-----------+--------+
9 rows in set (0.00 sec)
3、显示平均工资低于2000的部门和它的平均工资
// 1、以部门为单位分组,统计每个部门的平均工资
mysql> select avg(sal), deptno from emp group by deptno;
+-------------+--------+
| avg(sal) | deptno |
+-------------+--------+
| 2916.666667 | 10 |
| 2175.000000 | 20 |
| 1566.666667 | 30 |
+-------------+--------+
3 rows in set (0.00 sec)
// error:分组后的数据不能使用where进行筛选
mysql> select avg(sal), deptno from emp group by deptno where avg(sal)<2000;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'where avg(sal)<2000' at line 1
// succeed:分组后的数据只能用having字句进行筛选
mysql> select avg(sal), deptno from emp group by deptno having avg(sal)<2000;
+-------------+--------+
| avg(sal) | deptno |
+-------------+--------+
| 1566.666667 | 30 |
+-------------+--------+
1 row in set (0.00 sec)
知识点补充
- where适用于原表数据的筛选;having适用于对分组后的表进行筛选。
- select时各种SQL字句的执行顺序:

4. 聚合函数使用注意事项
聚合函数是做统计用的,必须严格匹配格式:select 聚合函数(字段) from 表名使用,而不能单独作为表达式去使用,除非有进行分组。
举例1:显示工资最高的员工的名字和工作岗位
// 错误用法,聚合函数不能单独作为表达式去使用
mysql> select ename, max(sal) from emp;
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'scott.emp.ename'; this is incompatible with sql_mode=only_full_group_by
// 错误用法:
mysql> select ename, sal from emp where sal=max(sal);
ERROR 1111 (HY000): Invalid use of group function
// 正确用法
mysql> select ename, sal from emp where sal=(select max(sal) from emp);
+-------+---------+
| ename | sal |
+-------+---------+
| KING | 5000.00 |
+-------+---------+
1 row in set (0.02 sec)
举例二:显示每个部门的平均工资和最高工资
mysql> select deptno, avg(sal), max(sal) from emp group by deptno;
+--------+-------------+----------+
| deptno | avg(sal) | max(sal) |
+--------+-------------+----------+
| 10 | 2916.666667 | 5000.00 |
| 20 | 2175.000000 | 3000.00 |
| 30 | 1566.666667 | 2850.00 |
+--------+-------------+----------+
3 rows in set (0.01 sec)
二. 日期函数
1. 函数概览
| 函数名称 | 描述 |
|---|---|
| current_date() | 当前日期 |
| current_time() | 当前时间 |
| current_timestamp | 当前日期时间 |
| date_add(data, interval, d_value_type) | 在date中添加日期或时间 interval后的数值单位可以是:year day minute second |
| date_sub(date, interval d_value_type) | 在date中减去日期或时间 interval后的数值单位可以是:year day minute second |
| datediff(date1, date2) | 两个日期的差,单位是天 |
| now() | 当前日期时间 |
| date(datetime) | 只显示日期部分 |
| time | 只显示时间部分 |
2. 使用举例
1、获得当前日期
// 使用函数current_date()函数
mysql> select current_date();
+----------------+
| current_date() |
+----------------+
| 2022-06-30 |
+----------------+
1 row in set (0.00 sec)
2、获得当前时间
// 使用current_time()函数
mysql> select current_time();
+----------------+
| current_time() |
+----------------+
| 12:57:46 |
+----------------+
1 row in set (0.00 sec)
3、获得当前时间日期
// 方法一:使用current_timestamp()函数
mysql> select current_timestamp();
+---------------------+
| current_timestamp() |
+---------------------+
| 2022-06-30 12:58:54 |
+---------------------+
1 row in set (0.00 sec)
// 方法二:使用now()函数
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2022-06-30 12:59:48 |
+---------------------+
1 row in set (0.00 sec)
4、date_add()的使用
// 正整数的话就执行加操作
mysql> select date_add('2001-07-10', interval 3 day);
+----------------------------------------+
| date_add('2001-07-10', interval 3 day) |
+----------------------------------------+
| 2001-07-13 |
+----------------------------------------+
1 row in set (0.02 sec)
// 负整数的话就是执行减操作
mysql> select date_add('2001-07-10', interval -3 day);
+-----------------------------------------+
| date_add('2001-07-10', interval -3 day) |
+-----------------------------------------+
| 2001-07-07 |
+-----------------------------------------+
1 row in set (0.00 sec)
// interval后面数据的单位可以是year day minute second
mysql> select date_add('2001-07-10', interval 3 second);
+-------------------------------------------+
| date_add('2001-07-10', interval 3 second) |
+-------------------------------------------+
| 2001-07-10 00:00:03 |
+-------------------------------------------+
1 row in set (0.00 sec)
5、date_sub()的使用
mysql> select date_sub('2001-07-10', interval 3 day);
+----------------------------------------+
| date_sub('2001-07-10', interval 3 day) |
+----------------------------------------+
| 2001-07-07 |
+----------------------------------------+
1 row in set (0.00 sec)
mysql> select date_sub('2001-07-10', interval -3 day);
+-----------------------------------------+
| date_sub('2001-07-10', interval -3 day) |
+-----------------------------------------+
| 2001-07-13 |
+-----------------------------------------+
1 row in set (0.00 sec)
mysql> select date_sub('2001-07-10', interval 3 second);
+-------------------------------------------+
| date_sub('2001-07-10', interval 3 second) |
+-------------------------------------------+
| 2001-07-09 23:59:57 |
+-------------------------------------------+
1 row in set (0.00 sec)
6、计算两个日期之间相差多少天
// 左边的日期 - 右边的日期
mysql> select datediff('2001-07-29', '2001-07-10');
+--------------------------------------+
| datediff('2001-07-29', '2001-07-10') |
+--------------------------------------+
| 19 |
+--------------------------------------+
1 row in set (0.00 sec)
7、只显示日期或只显示时间
// 1、date函数只显示日期部分,如果参数没有日期就显示NULL
mysql> select date('2001-07-09 12:59:48');
+-----------------------------+
| date('2001-07-09 12:59:48') |
+-----------------------------+
| 2001-07-09 |
+-----------------------------+
1 row in set (0.00 sec)
mysql> select date('12:59:48');
+------------------+
| date('12:59:48') |
+------------------+
| NULL |
+------------------+
1 row in set, 1 warning (0.00 sec)
// 2、time函数只显示时间部分,如果没有时间的话显示的数据不确定(可能为空,也能为其他时间)
mysql> select time('2001-07-09 12:59:48');
+-----------------------------+
| time('2001-07-09 12:59:48') |
+-----------------------------+
| 12:59:48 |
+-----------------------------+
1 row in set (0.00 sec)
8、设计一个留言表
表的内容包括以下三个字段:
id:用户的id,设为自增长主键。content:用户的留言内容,不能为空。sendtime:留言日期时间,可以为空,默认是当前的。
mysql> create table if no exists msg(
-> id int primary key auto_increment comment '用户id',
-> content varchar(30) not null comment '留言内容',
-> sendtime datetime default now() comment '留言日期时间'
-> );
Query OK, 0 rows affected (0.03 sec)
向留言表中间隔一分钟插入一条数据:
mysql> insert into msg (content) values ('张三我爱你!!!');
Query OK, 1 row affected (0.00 sec)
mysql> insert into msg (content) values ('祝李四生日快乐');
Query OK, 1 row affected (0.01 sec)
mysql> insert into msg (content) values ('祝妈妈母亲节快乐');
Query OK, 1 row affected (0.00 sec)
mysql> insert into msg (content) values ('熊猫太可爱了');
Query OK, 1 row affected (0.01 sec)
mysql> select * from msg;
+----+--------------------------+---------------------+
| id | content | sendtime |
+----+--------------------------+---------------------+
| 1 | 张三我爱你!!! | 2022-06-30 13:50:48 |
| 2 | 祝李四生日快乐 | 2022-06-30 13:51:32 |
| 3 | 祝妈妈母亲节快乐 | 2022-06-30 13:52:55 |
| 4 | 熊猫太可爱了 | 2022-06-30 13:53:46 |
+----+--------------------------+---------------------+
4 rows in set (0.00 sec)
- 显示所有留言信息,发布日期只显示日期,不用显示时间
mysql> select content, date(sendtime) from msg;
+--------------------------+----------------+
| content | date(sendtime) |
+--------------------------+----------------+
| 张三我爱你!!! | 2022-06-30 |
| 祝李四生日快乐 | 2022-06-30 |
| 祝妈妈母亲节快乐 | 2022-06-30 |
| 熊猫太可爱了 | 2022-06-30 |
+--------------------------+----------------+
4 rows in set (0.00 sec)
- 查询在2分钟内发布的帖子
// 1、查询留言板的数据
mysql> select * from msg;
+----+--------------------------+---------------------+
| id | content | sendtime |
+----+--------------------------+---------------------+
| 1 | 张三我爱你!!! | 2022-06-30 13:50:48 |
| 2 | 祝李四生日快乐 | 2022-06-30 13:51:32 |
| 3 | 祝妈妈母亲节快乐 | 2022-06-30 13:52:55 |
| 4 | 熊猫太可爱了 | 2022-06-30 13:53:46 |
+----+--------------------------+---------------------+
4 rows in set (0.00 sec)
// 2、显示当前时间
mysql> select now();
+---------------------+
| now() |
+---------------------+
| 2022-06-30 13:54:26 |
+---------------------+
1 row in set (0.00 sec)
// 3、查询在2分钟内发布的帖子
mysql> select * from msg where date_add(sendtime, interval 2 minute) > now();
+----+--------------------------+---------------------+
| id | content | sendtime |
+----+--------------------------+---------------------+
| 3 | 祝妈妈母亲节快乐 | 2022-06-30 13:52:55 |
| 4 | 熊猫太可爱了 | 2022-06-30 13:53:46 |
+----+--------------------------+---------------------+
4 rows in set (0.00 sec)
三. 字符串函数
1. 函数概览
| 函数名称 | 描述 |
|---|---|
| charset(str) | 返回字符串的字符集类型 |
| concat(string [, …]) | 拼接字符串 |
| instr(string, substring) | 返回substring在string中出现的位置,没有返回0 |
| ucase(string) | 把string中的字符都转换成大写 |
| lcase(string) | 把string中的字符都转换成小写 |
| left(string, length) | 从string中的左边起取length个字符 |
| length(string) | 返回string所占的空间大小,单位是字节 |
| replace(str, search_str, replace_str) | 在str中用replace_str替换search_str |
| strcmp(string1, string2) | 逐字符比较两字符串大小 |
| substring(str, position [, length]) | 从str的position开始,取length个字符 |
| ltrim(string) rtrim(string) trim(string) | 去除前空格或后空格 |
2. 使用举例
下面使用oracle 9i的emp表举例,该表数据如下:
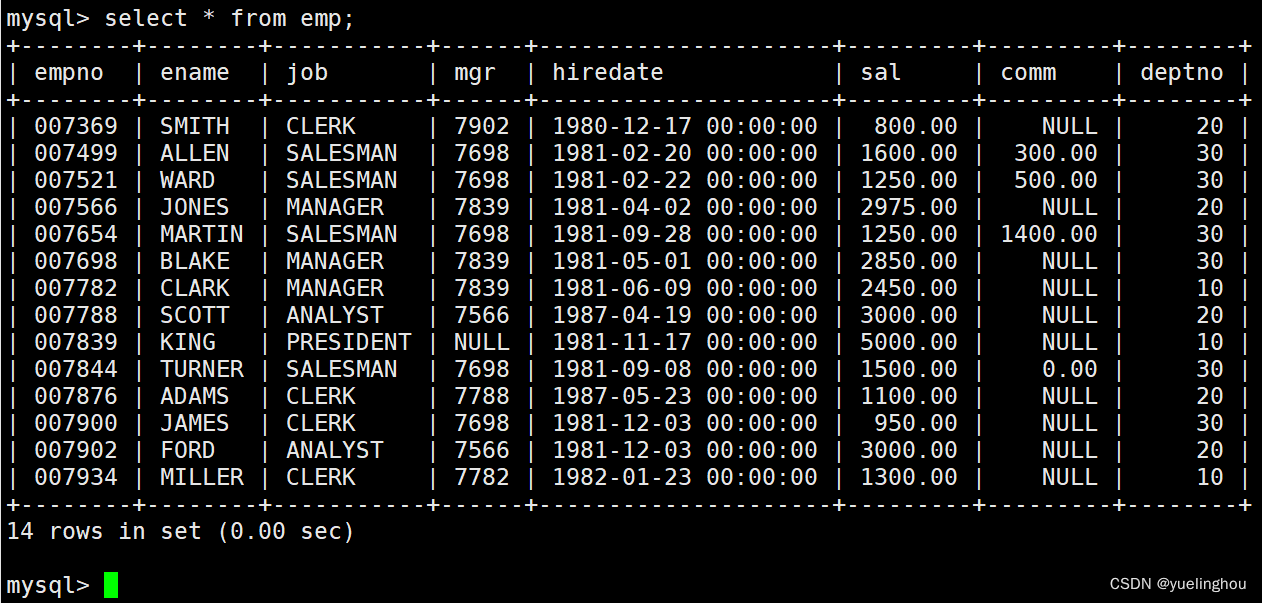
- 获取emp表中ename字段的字符集
mysql> select ename, charset(ename) from emp;
+--------+----------------+
| ename | charset(ename) |
+--------+----------------+
| SMITH | utf8 |
| ALLEN | utf8 |
| WARD | utf8 |
| JONES | utf8 |
| MARTIN | utf8 |
| BLAKE | utf8 |
| CLARK | utf8 |
| SCOTT | utf8 |
| KING | utf8 |
| TURNER | utf8 |
| ADAMS | utf8 |
| JAMES | utf8 |
| FORD | utf8 |
| MILLER | utf8 |
+--------+----------------+
14 rows in set (0.00 sec)
- 要求显示emp表中的信息,显示格式:“XXX的工号是XXX,岗位是XXX”
mysql> select concat(ename, '的工号是', empno, ',岗位是', job) from emp;
+-----------------------------------------------------------+
| concat(ename, '的工号是', empno, ',岗位是', job) |
+-----------------------------------------------------------+
| SMITH的工号是007369,岗位是CLERK |
| ALLEN的工号是007499,岗位是SALESMAN |
| WARD的工号是007521,岗位是SALESMAN |
| JONES的工号是007566,岗位是MANAGER |
| MARTIN的工号是007654,岗位是SALESMAN |
| BLAKE的工号是007698,岗位是MANAGER |
| CLARK的工号是007782,岗位是MANAGER |
| SCOTT的工号是007788,岗位是ANALYST |
| KING的工号是007839,岗位是PRESIDENT |
| TURNER的工号是007844,岗位是SALESMAN |
| ADAMS的工号是007876,岗位是CLERK |
| JAMES的工号是007900,岗位是CLERK |
| FORD的工号是007902,岗位是ANALYST |
| MILLER的工号是007934,岗位是CLERK |
+-----------------------------------------------------------+
14 rows in set (0.00 sec)
- 求emp表中员工姓名占用的字节数
mysql> select ename, length(ename) from emp;
+--------+---------------+
| ename | length(ename) |
+--------+---------------+
| SMITH | 5 |
| ALLEN | 5 |
| WARD | 4 |
| JONES | 5 |
| MARTIN | 6 |
| BLAKE | 5 |
| CLARK | 5 |
| SCOTT | 5 |
| KING | 4 |
| TURNER | 6 |
| ADAMS | 5 |
| JAMES | 5 |
| FORD | 4 |
| MILLER | 6 |
+--------+---------------+
14 rows in set (0.00 sec)
- 将EMP表中所有员工名字中带有S的替换成’上海’
mysql> select ename, replace(ename, 'S', '上海') from emp;
+--------+-------------------------------+
| ename | replace(ename, 'S', '上海') |
+--------+-------------------------------+
| SMITH | 上海MITH |
| ALLEN | ALLEN |
| WARD | WARD |
| JONES | JONE上海 |
| MARTIN | MARTIN |
| BLAKE | BLAKE |
| CLARK | CLARK |
| SCOTT | 上海COTT |
| KING | KING |
| TURNER | TURNER |
| ADAMS | ADAM上海 |
| JAMES | JAME上海 |
| FORD | FORD |
| MILLER | MILLER |
+--------+-------------------------------+
14 rows in set (0.00 sec)
- 截取EMP表中ename字段的第二个到第三个字符
mysql> select ename, substring(ename, 2, 2) from emp;
+--------+------------------------+
| ename | substring(ename, 2, 2) |
+--------+------------------------+
| SMITH | MI |
| ALLEN | LL |
| WARD | AR |
| JONES | ON |
| MARTIN | AR |
| BLAKE | LA |
| CLARK | LA |
| SCOTT | CO |
| KING | IN |
| TURNER | UR |
| ADAMS | DA |
| JAMES | AM |
| FORD | OR |
| MILLER | IL |
+--------+------------------------+
14 rows in set (0.00 sec)
- 以首字母小写的方式显示所有员工的姓名
mysql> select concat(lcase(substring(ename, 1, 1)), substring(ename, 2)) from emp;
+------------------------------------------------------------+
| concat(lcase(substring(ename, 1, 1)), substring(ename, 2)) |
+------------------------------------------------------------+
| sMITH |
| aLLEN |
| wARD |
| jONES |
| mARTIN |
| bLAKE |
| cLARK |
| sCOTT |
| kING |
| tURNER |
| aDAMS |
| jAMES |
| fORD |
| mILLER |
+------------------------------------------------------------+
14 rows in set (0.00 sec)
四. 数学函数
1. 函数概览
| 函数名称 | 描述 |
|---|---|
| abs(number) | 绝对值函数 |
| bin(decimal_number) | 把十进制数字转换成二进制 |
| hex(decimal_number) | 把十进制数字转换成十六进制 |
| conv(number, from_base, to_base) | 指定进制转换 |
| ceiling(number) | 向上取整 |
| floor(number) | 向下取整 |
| format(number, decimal_places) | 四舍五入,decimal_places表示保留的小数位数 |
| rand() | 返回随机浮点数,范围[0.0, 1.0] |
| mod(number, denominator) | 取模,求余 |
2. 使用举例
- 计算绝对值
mysql> select abs(-3.14);
+------------+
| abs(-3.14) |
+------------+
| 3.14 |
+------------+
1 row in set (0.00 sec)
- 向上取整(往大的数方向上取整)
mysql> select ceiling(3.14), ceiling(-3.14), ceiling(3);
+---------------+----------------+------------+
| ceiling(3.14) | ceiling(-3.14) | ceiling(3) |
+---------------+----------------+------------+
| 4 | -3 | 3 |
+---------------+----------------+------------+
1 row in set (0.00 sec)
- 向下取整(往小的数方向上取整)
mysql> select floor(3.14), floor(-3.14), floor(3);
+-------------+--------------+----------+
| floor(3.14) | floor(-3.14) | floor(3) |
+-------------+--------------+----------+
| 3 | -4 | 3 |
+-------------+--------------+----------+
1 row in set (0.00 sec)
- 四舍五入(需要指定小数位数)
mysql> select format(3.5, 0), format(-3.5, 0), format(3.4, 0), format(-3.4, 0);
+----------------+-----------------+----------------+-----------------+
| format(3.5, 0) | format(-3.5, 0) | format(3.4, 0) | format(-3.4, 0) |
+----------------+-----------------+----------------+-----------------+
| 4 | -4 | 3 | -3 |
+----------------+-----------------+----------------+-----------------+
1 row in set (0.00 sec)
- 产生1~100之间的随机数
// 因为rand()函数得到的是随机浮点数,范围[0.0, 1.0]
// rnad()再乘上100后向下取整得到范围[0, 99]
// 最后再加上1得到范围[1, 100]
mysql> select floor(rand()*100)+1;
+---------------------+
| floor(rand()*100)+1 |
+---------------------+
| 95 |
+---------------------+
1 row in set (0.00 sec)
mysql> select floor(rand()*100)+1;
+---------------------+
| floor(rand()*100)+1 |
+---------------------+
| 24 |
+---------------------+
1 row in set (0.00 sec)
mysql> select floor(rand()*100)+1;
+---------------------+
| floor(rand()*100)+1 |
+---------------------+
| 34 |
+---------------------+
1 row in set (0.00 sec)
- 十进制数字转为二进制和十六进制
// 转为二进制
mysql> select bin(10);
+---------+
| bin(10) |
+---------+
| 1010 |
+---------+
1 row in set (0.00 sec)
// 转为十六进制
mysql> select hex(10);
+---------+
| hex(10) |
+---------+
| A |
+---------+
1 row in set (0.00 sec)
- 执行取模运算
// 发现取模后结果的正负号取决于被除数
mysql> select mod(10, 3);
+------------+
| mod(10, 3) |
+------------+
| 1 |
+------------+
1 row in set (0.00 sec)
mysql> select mod(-10, -3);
+--------------+
| mod(-10, -3) |
+--------------+
| -1 |
+--------------+
1 row in set (0.00 sec)
mysql> select mod(-10, 3);
+-------------+
| mod(-10, 3) |
+-------------+
| -1 |
+-------------+
1 row in set (0.00 sec)
mysql> select mod(10, -3);
+-------------+
| mod(10, -3) |
+-------------+
| 1 |
+-------------+
1 row in set (0.00 sec)
五. 其它函数
1、user() 查询当前用户
mysql> select user();
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
1 row in set (0.00 sec)
2、database()显示当前正在使用的数据库
// 1、查看当前正在使用的数据库
mysql> select database();
+------------+
| database() |
+------------+
| ForTest |
+------------+
1 row in set (0.00 sec)
// 2、切换数据库
mysql> use scott;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
// 3、重新查看当前正在使用的数据库
mysql> select database();
+------------+
| database() |
+------------+
| scott |
+------------+
1 row in set (0.00 sec)
3、md5(str)对一个字符串进行md5摘要,摘要后得到一个32位字符串
// 不论字符串长度有多长,摘要后得到的都是一个32位字符串
mysql> select md5('5201314');
+----------------------------------+
| md5('5201314') |
+----------------------------------+
| 723d505516e0c197e42a6be3c0af910e |
+----------------------------------+
1 row in set (0.02 sec)
mysql> select md5('admin');
+----------------------------------+
| md5('admin') |
+----------------------------------+
| 21232f297a57a5a743894a0e4a801fc3 |
+----------------------------------+
1 row in set (0.00 sec)
4、ifnull(val1, val2)如果val1不为null,返回val1,否则返回val2的值
PS:val可以是任意类型的数据。
// ifnull的作用类似于C/C++中的三目运算符
mysql> select ifnull('abc', '123');
+----------------------+
| ifnull('abc', '123') |
+----------------------+
| abc |
+----------------------+
1 row in set (0.00 sec)
mysql> select ifnull(null, '123');
+---------------------+
| ifnull(null, '123') |
+---------------------+
| 123 |
+---------------------+
1 row in set (0.00 sec)















 2241
2241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









