







大纲
一、前情提要
1、已集成的环境
-
java1.8
-
hadoop2.7.2
-
zookeeper3.4.10
-
hive1.2.1
-
hbase1.3.1
-
Jobhistory(历史服务器)
2、必要准备
- 一个已经设置好静态IP且通网的CentOS7 以上的OS
(建议配置 8G+200G)
3、必须提前获取的参数!!!!
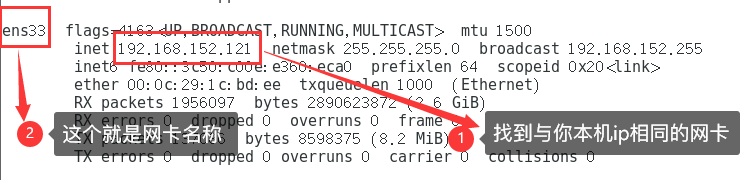
- 获取CentOS 7 的所属网段,子网掩码,网关,网卡名称
(查看方法)
-
打开虚拟网络编辑器

-
选中网卡

-
打开 NAT设置

-
查看网关、网段、子网掩码

-
查看网卡名称
在终端输入以下命令
ifconfig
特别注意!
-
请记录下网段、网关、网卡名称
-
举例
-
我的网段是 192.168.152.0
-
我的网关是 192.168.152.2
-
我的网卡名称是 ens33
二、 一键搭建hadoop集群脚本
1、将脚本导入CentOS7里面
- 方法很多,在此不做演示。
2、给脚本赋予执行权限
chmod a+x install_hadoop_Docker.sh
3、执行脚本
./install_hadoop_Docker.sh
- 输入必要参数
- 这里输入的参数要对应 刚才要求记录的网段、网关、网卡名称!!

- 在脚本执行过程中,还要输入3台容器的IP
-例如
我的网段是 192.168.152.0
我的网关是 192.168.152.2
我的主机IP是 192.168.152.121
那么我要给他们设置的IP地址格式必须为:
192.168.152.x
x的值可以是x∈{x|0<x<255,x≠2,121}
这里我设置的3台容器的IP分别是
192.168.152.201
192.168.152.202
192.168.152.203

这些参数设置完就可以坐等安装结束了!
4、脚本源码
#!/bin/bash
echo -e "\033[37;41;1m ============ 一站式安装hadoop ============\033[0m"
echo -e "\033[37;41;1m =========== Author:GongChangJL ===========\033[0m"
echo
echo -e "\033[34;1;5m ============ 请输入网段 ============\033[0m"
read netSegment
echo -e "\033[34;1;5m ============ 请输入网关 ============\033[0m"
read gateway
echo -e "\033[34;1;5m ========== 请输入网卡名称 ==========\033[0m"
read netCard
echo
echo -e "\033[34;1;5m ========= 请输入hadoop1的IP ========\033[0m"
read IPhadoop1
echo -e "\033[34;1;5m ========= 请输入hadoop2的IP ========\033[0m"
read IPhadoop2
echo -e "\033[34;1;5m ========= 请输入hadoop3的IP ========\033[0m"
read IPhadoop3
echo
echo -e "\033[37;1;42;05m ============ START ============\033[0m"
echo -e "\033[34;1m ============ 安装docker ============\033[0m"
yum update -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce
systemctl start docker
docker -v
echo -e "\033[32;1m ========== docker安装结束 ===========\033[0m" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2514
2514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











