






博客:cbb777.fun
全平台账号:安妮的心动录
github: https://github.com/anneheartrecord
下文中我说的可能对,也可能不对,鉴于笔者水平有限,请君自辨。有问题欢迎大家找我讨论
什么是消息队列
消息队列,我们一般会称为MQ(Message Queue),也就是说消息队列的本质就是一个队列,而队列是一种先进先出的数据结构,提供消息传递和消息排队模型,可以在分布式环境下提供应用解耦、弹性伸缩、流量削峰、异步通信、数据同步、微服务之间通信等功能,作为分布式系统架构中的一个重要组件,有着举足轻重的地位 我们会将要传输的数据、消息放在消息队列中 其中,往MQ里放东西的叫做生产者 从MQ里面取消息的叫做消费者
为什么要用消息队列
解耦
现在有一个系统A,A可以产生一个UserId 然后有系统B和系统C都需要这个UserId去做相关的操作
然后有系统B和系统C都需要这个UserId去做相关的操作 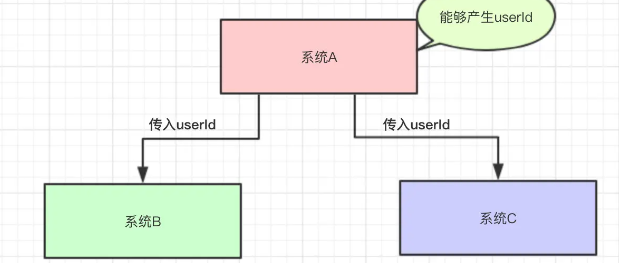 这样就会有一个问题,每当出现改动的时候,我都要改动整个系统,比如B不需要A的消息了,那么就要改A、B,新来的一个D服务,需要用到A的消息,那么又需要修改,整个系统的冗余度很高 引入消息队列之后:系统A将id写到消息队列中,BC服务从消息队列中拿数据
这样就会有一个问题,每当出现改动的时候,我都要改动整个系统,比如B不需要A的消息了,那么就要改A、B,新来的一个D服务,需要用到A的消息,那么又需要修改,整个系统的冗余度很高 引入消息队列之后:系统A将id写到消息队列中,BC服务从消息队列中拿数据
系统A只负责写数据,不关心数据的消费、处理,而BC服务只负责拿数据,即使BC服务挂了,也和系统A没关系,只和消息队列有关,这样就能做到多个服务之间的解耦
异步
 如果是同步的话,A必须要等待B C D 处理完之后才能返回,整个时间比较久
如果是同步的话,A必须要等待B C D 处理完之后才能返回,整个时间比较久  如果是异步的话,A(比如注册服务)将消息写道消息队列之后就可以返回,之后再发给邮件服务和短信服务消费
如果是异步的话,A(比如注册服务)将消息写道消息队列之后就可以返回,之后再发给邮件服务和短信服务消费
限流、削峰
当请求来的时候,先把请求放在消息队列中,然后系统再根据自己能够处理的请求数去消息队列里面拿数据,这样即使每秒请求数很大,也不会把系统打崩
流量控制
消息队列通常有很多种方式来实现流量控制
1.配额控制:通过为每个生产者或者消费者分配配额,限制它们可以发送或者接受的消息数量。这可以保证消息队列中的资源不会被过度使用,并确保系统在高负载情况下的稳定性
2.窗口机制:当生产者将消息发送到消息队列的时候,消息队列会给每个生产和分配一个发送窗口,当消费者确认之后把对应的消息从窗口里面删除
3.缓冲区:消息队列把消息往缓冲区里丢,消费者从缓冲区里去取
4.速率限制:这个一般是在客户端实现的,可以实现生产者在每秒、每分钟生产多少条消息
如何保证消息不被重复消费
常见的消息队列都有确认机制(ACK机制),当消费者消费数据之后会给消息队列中间件发送一个确认消息,消息队列收到之后就会把这条消息从队列中删除。
当出现网络传输等故障,ACK没有传送到消息队列,导致消息队列不知道消费者已经消费过该消息了,再次将消息分发给其他的消费者
解决:
1.看场景,如果场景不需要幂等,那么可以不管,比如这条消息拿去插入数据库,重复插入主键相同的数据是会自动出错的,再比如做redis的set操作,也不需要管,多次set之后仍然是幂等的
2.准备第三方介质做消费记录,比如加个redis,给消息分配一个全局id,只要消费过该消息就将<id,message>写入redis。消费者消费之前先去redis中查有没有消费记录即可
如何保证消息的可靠性传输
消息队列丢数据主要有三个可能
1.生产者丢数据
2.消息队列组件丢数据
3.消费者丢数据
生产者:可以采用transaction机制,开启事务来发送消息,如果发送失败就回滚。但是生产中用的不多,因为会导致吞吐量的下降,一般都是用confirm机制,如果生产者成功把消息发送给队列,队列会回一个ack,否则回一个nack
消息队列:可以开启持久化,而且一般是集群部署的,有master和slave节点,一般都是同步复制,只有主节点和从节点都写入成功才返回ack给生产者
消费者:取消自动确认,自动确认后消息队列收到ACK会立马把消息从队列中删掉,而是手动确认(即处理后才回ACK)。
消息队列需要考虑的问题
高可用
消息队列肯定不是单机的,这样可用性和健壮性都非常差,所以项目中使用的消息队列都得集群或者分布式
数据问题
消息丢失:当消费者拿了数据还没使用的时候,服务就挂掉了,就会导致消息的丢失,一般会使用ACK应答机制,当消费者拿到消息发送确认ACK信号,消息队列才会把对应的消息删掉
消息堆积:消息堆积分为客户端堆积和服务端堆积 一般都会设置告警规则来通知开发者消息堆积的问题
如果是客户端消息堆积,那可以考虑扩大消费线程或者节点来解决, 针对于某些特殊场景,如果消息堆积已经影响到业务,并且堆积的消息可以跳过不消费,那么可以重置消费消息位置为最新位置开始消费,快速恢复业务。
如果是服务端消息堆积,考虑服务端宕机的情况,快速恢复之后重新可用
消费者取数据
两种方法
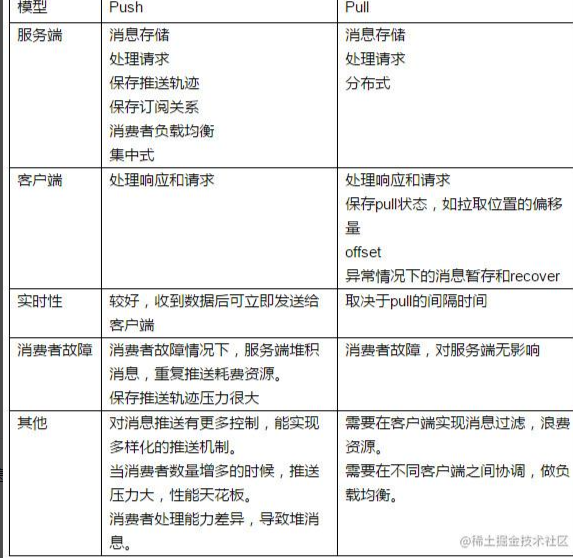
1.push 消息队列有新消息的时候主动叫消费者去拿,实时性强。如果消费者故障,服务端堆积消息。
2.pull 消费者不断的轮询消息队列,看看有没有新数据,如果有就消费,实时性弱。
消息队列的传输模式
点对点模型
用于消息生产者和消息消费者之间点到点的通信,消息生产者将消息发送到某个特定的消费者 特点: 1.每个消息只有一个消费者 2.发送者和接收者都没有时间依赖 3.接受者确认消息接受和处理成功

发布订阅模型
发布订阅模型支持向一个特定的消息主题产生消息,在这种模型下,发布和订阅者彼此不知道对方的存在,多个消费者可以获得消息,在发布者和订阅者之间存在时间依赖性,发布者publish需要建立一个订阅subscription,以便消费者能够订阅。订阅者必须保持持续的活动状态并接受消息
主题、订阅、消费者(组)之间的关系为 M:N:O
在这种情况下,订阅者未连接时,发布的消息将在订阅者重新连接的时候重新发布 特点: 1.每个消息可以有多个订阅者 2.客户端只有订阅之后才能收到消息 3.持久订阅和非持久订阅
持久订阅:订阅关系建立之后,消息就不会消失,不管订阅者是否在线 非持久订阅:订阅者为了接受消息,必须一直在线,当只有一个订阅者的时候等于点对点模式
pub-sub vs queue
发布订阅和队列模式是消息队列中的两种不同的消息模式
发布-订阅模式:发布者将消息发送到特定的主题(topic)上,订阅者可以选择订阅感兴趣的主题,从而接受与该主题相关的消息。在该模式中,消息被广播给所有订阅者,每个订阅者可以独立处理消息,订阅者之间不会相互干扰。发布-订阅模式通常用于广播消息或者通知
队列模式:消息发送到队列中,然后一个或者多个消费者从队列中收取并处理消息。在该模式中,每条消息只能被一个消费者接收和处理。如果有多个消费者,消息将被平均分配给它们。队列模式通常用于实现任务分配或者负载均衡等场景

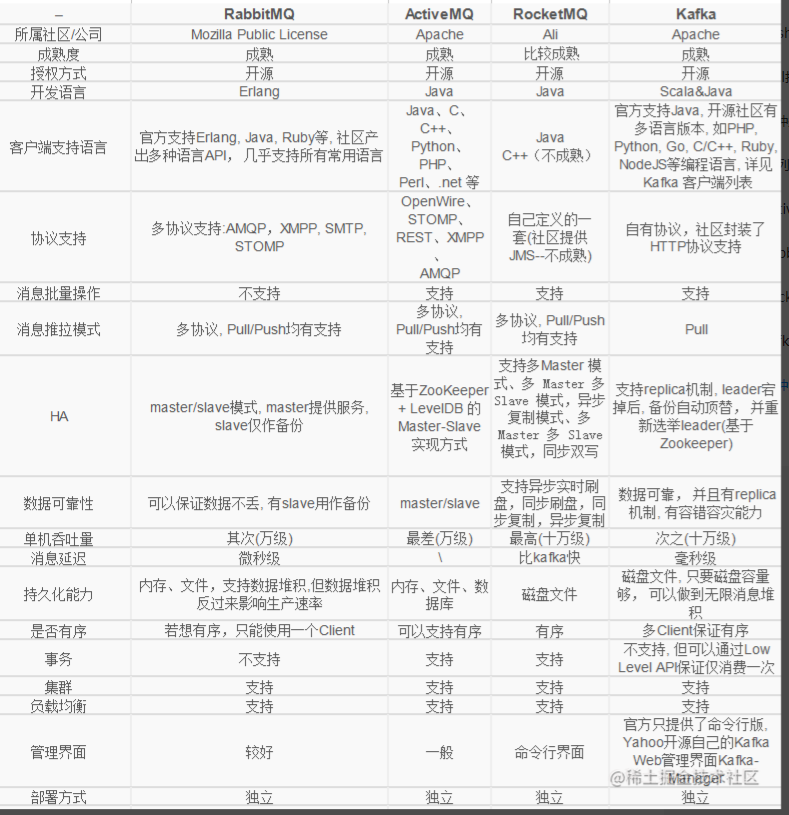
市面上消息队列对比
记住两个最常见的MQ的对比就可以,硬盘MQ代表是Kafka 内存MQ代表是RabbitMQ
Kafka的优点是客户端支持多语言、使用pull模式,支持消息批量操作,支持replica机制,Zookeeper自动选举leader恢复能力,数据可靠,有容错容灾的能力,单机吞吐量为10W级,延迟毫秒,数据基于硬盘层面存储,多Client支持有序,不支持事务,但是可以通过LOW LEVEL API的方式保证消息只支持消费一次
RabbitMQ的优点是客户端支持多语言,多协议支持,不支持消息批量操作,有pull和push两种模式,使用的主从模式master/slave,master提供服务,slave做备份,数据可靠(因为有备份),单机吞吐量为万级别,消息延迟为微秒级,内存级别,可以主动开启持久化,支持集群和负载均衡,不保证多Client消息有序
pulsar kafka rabbitmq nsq的异同
1.pulsar 和 kafka基于发布订阅模式,而rabbitmq 和 nsq基于的是队列模式
2.pulsar和kafka都采用了持久化机制,以支持高吞吐量和高可靠性,而rabbitmq和nsq则将数据存储在内存中,以支持更低的延迟和更高的吞吐量
3.pulsar和kafka都支持 多租户和多数据中心部署,可以轻松地在多个数据中心或者云平台上进行扩展,而rabbitmq和nsq则更加适合单个数据中心的部署
4.pulsar和kafka都具有出色的可伸缩性和高可用性,处理数据单位是百万级别的;而rabbitmq和nsq则更加适合小规模的应用程序,具有更低的延迟和更高的性能
5.pulsar和kafka都提供了消息流的处理程序,使用户可以对消息进行实时分析和处理
总的来说:pulsar和kafka更适合处理大量消息和数据流,rabbitmq和nsq则更适合小规模应用程序,具有更低的延迟和更高的性能
Pulsar底层实现
Pulsar是Apache基金会的顶级项目,是云原生的分布式消息队列,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据恢复机制,具有强一致性、高吞吐、低时延及高可扩展性等流数据存储特性
-
云原生MQ -
单个Pulsar实例原生支持多集群,可跨机房完成消息复制 -
支持超过一百万个topic -
支持多语言客户端 -
主题多种订阅模式(独占、共享和故障转移) -
通过Book Keeper来实现持久化存储,保证消息传递 -
分层式存储,可在数据陈旧时将数据从热存储卸载到冷存储中
消息
Messages有很多的部分组成, 下面是几个值得注意的
-
value/payload 消息的数据 -
properties 可选的属性,是一个key->value的键值对 -
producer name 生产者名称 -
publish time 发布时间戳 -
sequence id 在topic中 每个msg属于一个有序的队列 sequence id是它在序列中的次序
Pulsar和其他的MQ一样,会对消息的大小做出限制
这个限制通过broker.conf中的maxMessageSize 决定
不设置的话,默认为5MB
生产者
生产者是关联到topic的程序,它发布消息到Pulsar的broker上
发送模式
-
异步发送:生产者发送消息之后会等待broker的确认,如果没有收到确认则认为是发送失败 -
同步发送:会把消息放在阻塞队列中,然后立马返回,然后这个阻塞队列会往broker中发消息
主题访问模式
-
Shared(共享) 多个生产者可以发布一个主题,这是默认设置 -
Exclusive(独占) 一个主题只能由一个生产者发布,如果已经有生产者链接,其他生产者试图发布该主题将立即得到错误。如果"老"的生产者与broker发生网络分区,"老"生产者将被驱逐,"新"生产者将被选为下一个唯一的生产者 -
WaitForExclusive(独占等待) 如果已经有一个生产者连接,生产者的创建是未决的,直到生产者获得独占访问。成功成为排他性的生产者被视为领导者,因此,如果想实现leader选举方案,可以使用这种模式
压缩、批处理与分块 压缩:我们可以主动压缩生产者在传输期间发布的消息,Pulsar目前支持以下类型的压缩
-
LZ4 -
ZLIB -
ZSTD -
SNAPPY
批处理:如果批处理开启,producer将会积累一批消息,然后通过一次请求发送出去。批处理的大小取决于最大的消息数量及最大的延迟发布
分块:分块和批处理不能同时启用,要启用分块,必须提前禁用批处理。Chunking只支持持久化的主题
一个producer与一个订阅consumer的分块消息 当生产者向主题发送一批大的分块消息和普通的非分块消息时。将M1切成分块M1-C1、M1-C2、M1-C3。这个broker在其管理的ledger里面保存所有的三个块消息,然后以相同的顺序分发给消费者(独占/灾备)。消费者将在内存缓存所有的块消息,直到收到所有的消息快。将这些消息合并成为原始的消息M1,发送给处理进程 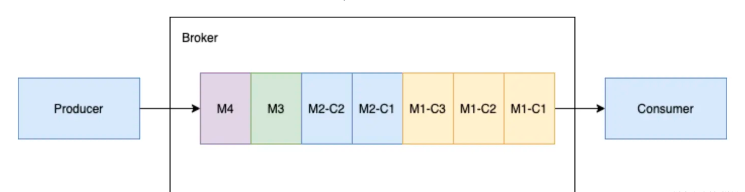
消费者
消费者通过订阅关联到主题,然后接受消息的程序
接收模式
消息可以通过同步或者异步的方式从broker接受
同步:同步接收将会阻塞,直到消息可用
异步:异步接收立刻返回future值,一旦新消息可用,它将即可完成
监听
客户端类库提供了它们对于consumer的监听实现,在这个接口中,一旦接受到新的消息,received方法将被调用
确认
消费者成功处理消息之后需要发送确认(ack)给broker,以让broker丢掉这条消息(否则将一直存储)。消息的确认可以逐个进行,也可以累积到一起。累计确认的时候,消费者只需要确认最后一条它收到的消息,所有之前的消息都认为被成功消费。累积确认不能用于shared模式,因为shared订阅为同一个订阅引入了多个消费者
主题
和其他的MQ一样,Pulsar中的topic是带有名称的通道,用来从producer到consumer传输消息,topic的名称是符合良好结构的URL
{persistent|non-persistent}://tenant/namespace/topic
-
peisistent|non-persistent 定义了topic的类型,Pulsar支持两种不同的topic:持久化和非持久化,默认是持久化类型,也就是会保存到硬盘上的类型 -
tenant 实例中topic的租户,tenant是Pulsar多租户的基本要素,可以被跨集群的传播 -
namespace topic的管理单元,与topic组的管理机制相关。大多数的topic配置在namespace层面生效,每个tenant可以有多个namespace -
topic 主题的最后组成部分
Partitioned topics 分区主题
普通的主题只由单个broker提供服务,这限制了主题的最大吞吐量,分区主题是由多个broker处理的一种特殊类型的主题,因此允许更高的吞吐量 分区主题实际上实现为N个主题,N是分区的数量。当消息发布到分区主题的时候,每个消息都被路由到几个Broker中的一个。分区在broker之间的分布由Pulsar自动的进行处理 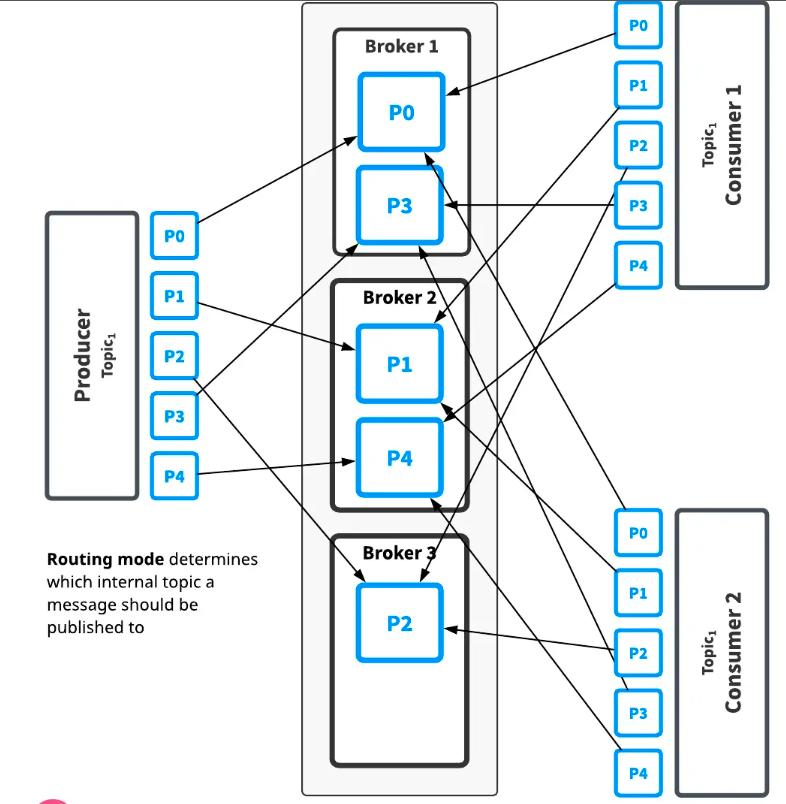 如上图,Topic有五个分区,划分在3个broker上,因为分区比broker多,前两个broker分别处理两个分区,而第三个broker只处理一个分区(Pulsar自动处理分区的分布) 此主题的消息将广播给两个消费者,路由模式决定将每个消息发布到哪个分区,而订阅模式决定将哪些消息发送到哪个消费者
如上图,Topic有五个分区,划分在3个broker上,因为分区比broker多,前两个broker分别处理两个分区,而第三个broker只处理一个分区(Pulsar自动处理分区的分布) 此主题的消息将广播给两个消费者,路由模式决定将每个消息发布到哪个分区,而订阅模式决定将哪些消息发送到哪个消费者
路由模式
-
RoundRobinPartition message无key则轮询,有key则hash指定分区(默认模式) -
SinglePartition message 无key 则producer将会随机选择一个分区,将所有的消息都发送给该分区。如果message有key,那么会hash指定分区 -
CustomParition 使用自定义消息路由实现
顺序保证
消息的顺序与路由模式和消息的key有关
-
Per-key-partition (按key分区) 具有相同key的所有消息将被顺序放置在同一个分区中 -
Per-producer (按照Producer) 来自同一生产者的所有消息都是有序的
哈希方案
HashingScheme是一个enum,表示在选择要为特定消息使用的分区时可用的标准哈希函数集
有两种类型的标准哈希函数可用:JavaStringHash和Murmur3_32Hash,生产者的默认哈希函数是Java,但是当生产者的客户端是多语言的时候,Java是没用的
持久/非持久化主题
默认情况下,Pulsar会保存所有没确认的消息到Book Keeper中,持久Topic消息会在broker重启或者consumer出问题的时候保存下来
Pulsar也支持非持久化Topic 这些Topic的消息只存在于内存中,不会存储到磁盘
因为Broker不会对消息进行持久化存储,当Producer将消息发送给Broker时,Broker可以立即将ack返回给Producer,所以非持久化的消息传递会比持久化的更快。相对的,当Broker因为一些原因宕机、重启后,非持久化的Topic消息都会消失,订阅者将无法收到这些消息。
Dead letter topic 死信主题
死信主题允许你在用户无法成功消费某些消息时使用新消息。在这种机制中,无法使用的消息存储在单独的主题中,成为死信主题。
死信主题依赖于消息的重新投递,由于确认超时或者否认确认,消息将被重新发送。如果要对消息使用否定确认,请确保在确认超时之前对齐进行否定确认。
Retry letter topic 重试主题
对于许多在线业务系统,由于业务逻辑处理中出现异常,消息会被重复消费。
若要配置重新消费失败消息的延迟时间,可以配置生产者将消息发送到业务主题和重试主题,并在消费者上启用自动重试。当在消费者上启用自动重试的时候,如果消息没有被消费,那么就会存储到重试主题中,在指定的延迟时间后,消费者会主动接受来自重试主题的失败消息
订阅模式
Pulsar支持exclusive (独占) failover(灾备) shared(共享) 和 key_shared(Key共享)四种消息订阅模式,示意图如下 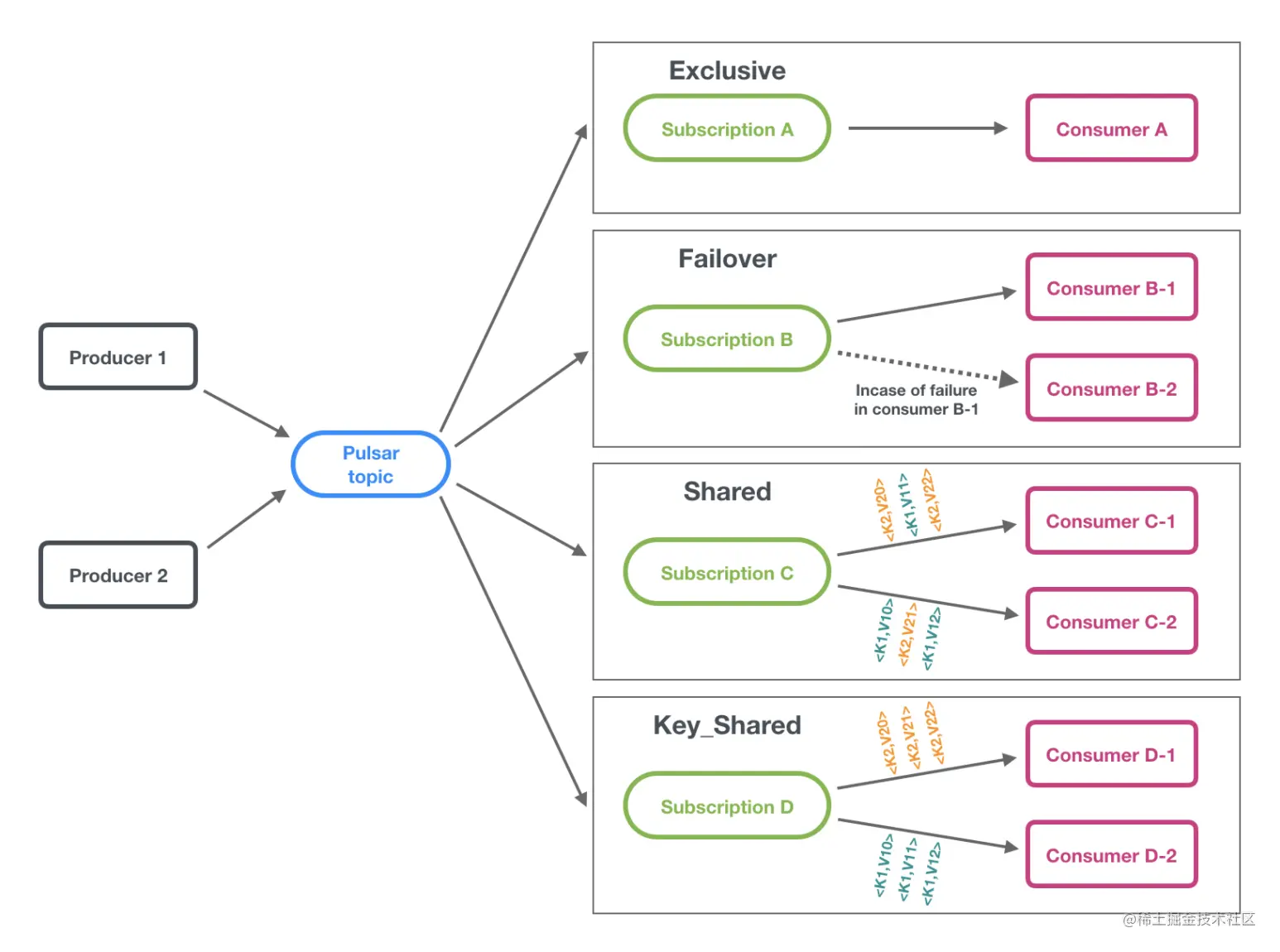
独占模式 默认的消息订阅模式。只能有一个消费者消费消息 
灾备模式 灾备模式下,一个topic也是只有单个consumer消费一个订阅关系的消息,但是在这个模式下,每个消费者会被排序,当前面的消费者无法连接上broker后,消息会由下一个消费者进行消费 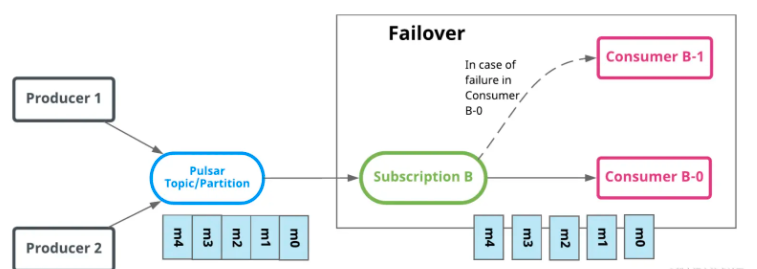 共享模式 共享模式下,消息可被多个consumer同时消费,无法保证消费的顺序,消息通过roundrobin的方式投递到每一个消费者
共享模式 共享模式下,消息可被多个consumer同时消费,无法保证消费的顺序,消息通过roundrobin的方式投递到每一个消费者 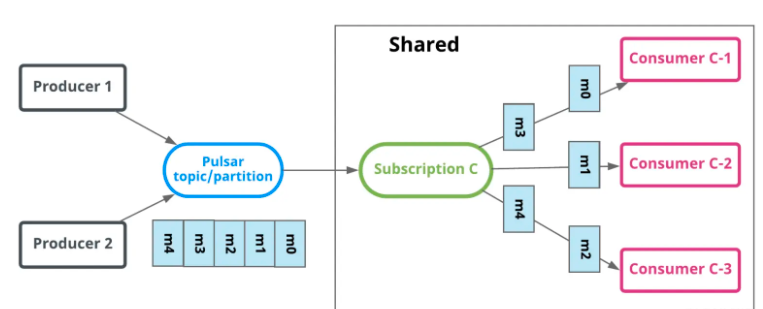 key共享模式 按照key对消息进行投递,相同的key的消息会被投递到同一个consumer上,消费示意图如下
key共享模式 按照key对消息进行投递,相同的key的消息会被投递到同一个consumer上,消费示意图如下 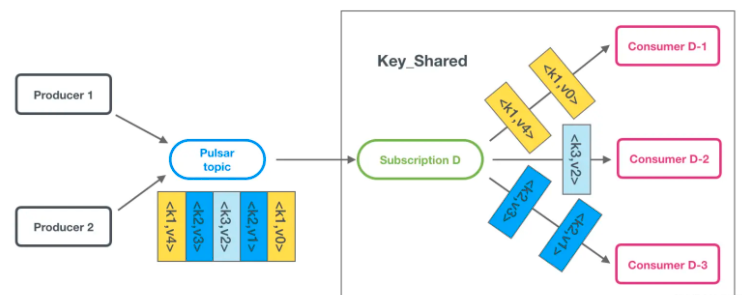
消息保留与过期 默认策略
-
立即删除所有被消费者确认过的消息 -
以backlog的形式,持久化保存所有未被确认的消息
两个特性
-
消息保留可以让你保存consumer确认过的消息 -
消息过期可以让你给未被确认的消息设置ttl
消息保留和过期是针对namesapce层面进行设置和管理的
消息去重
实现消息去重的一种方式是确保消息只生产一次,即生产者幂等,这种方式的缺点在于把消息去重的工作交给应用来做。 在pulsar中,broker支持配置开启消息去重,用户不需要主动在代码中保证Producer只生产一次,启动之后即使消息被多次发送到topic上,也只会被持久化到磁盘一次
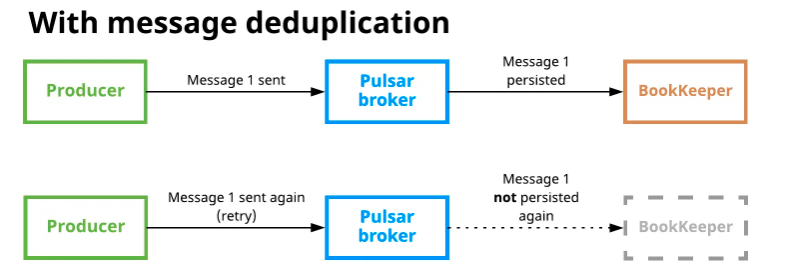
原理:Producer对每一个发送的消息,都会采用递增的方式生成一个唯一的sequence ID,这个消息会放在message的元数据中传递给broker。
同时,broker也会维护一个pendingmessage队列,当broker返回发送成功ack之后,producer会将pendingmessage队列中的sequence id删除,标识producer任务这个消息生产成功。
broker会记录针对每个producer接受到的最大sequence id和已经处理完的最大sequence id
当broker开启消息去重之后,Broker会针对每个消息请求进行是否去重的判断,如果消息重复,则直接返回ack,不走后续存储的流程
延时消息
延时消息功能允许Consumer能够在消息发送到topic之后,过一段时间之后才能消费到这条消息。在这种集中中,消息在发布到broker之后,会被存储在book keeper中,当到消息特定的延迟时间时,消息就会传递给consumer
broker不会在存储的时候做特殊处理,而是会把设置了延迟时间的消息加入到DelayedDeliveryTracker中,当到了指定的发送时间时,Tracker才会把这条消息推送给消费者
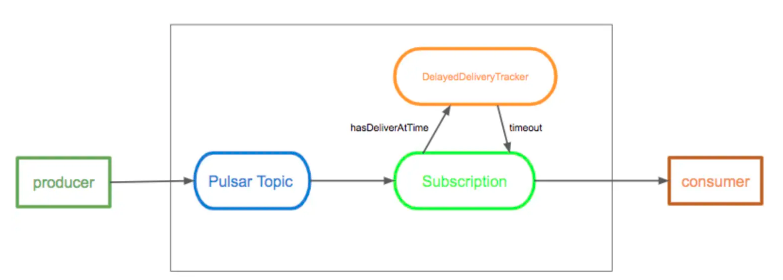 原理:
原理:
在Pulsar中有两种方式实现延迟消息,分别为deliverAfter和deliverAt
deliverAfter可以指定在多长时间之后进行消费
deliverAt可以指定具体的延迟消费时间戳
DelayedDeliveryTracker会记录所有需要延迟投递的消息的index,index由timestamp、 ledger id 、和entry id三部分组成,其中ledger id 和 entry id用来定位该消息
timestamp除了记录需要投递的时间,还用于延迟优先级队列排序。tracker会根据延迟时间对消息进行排序 
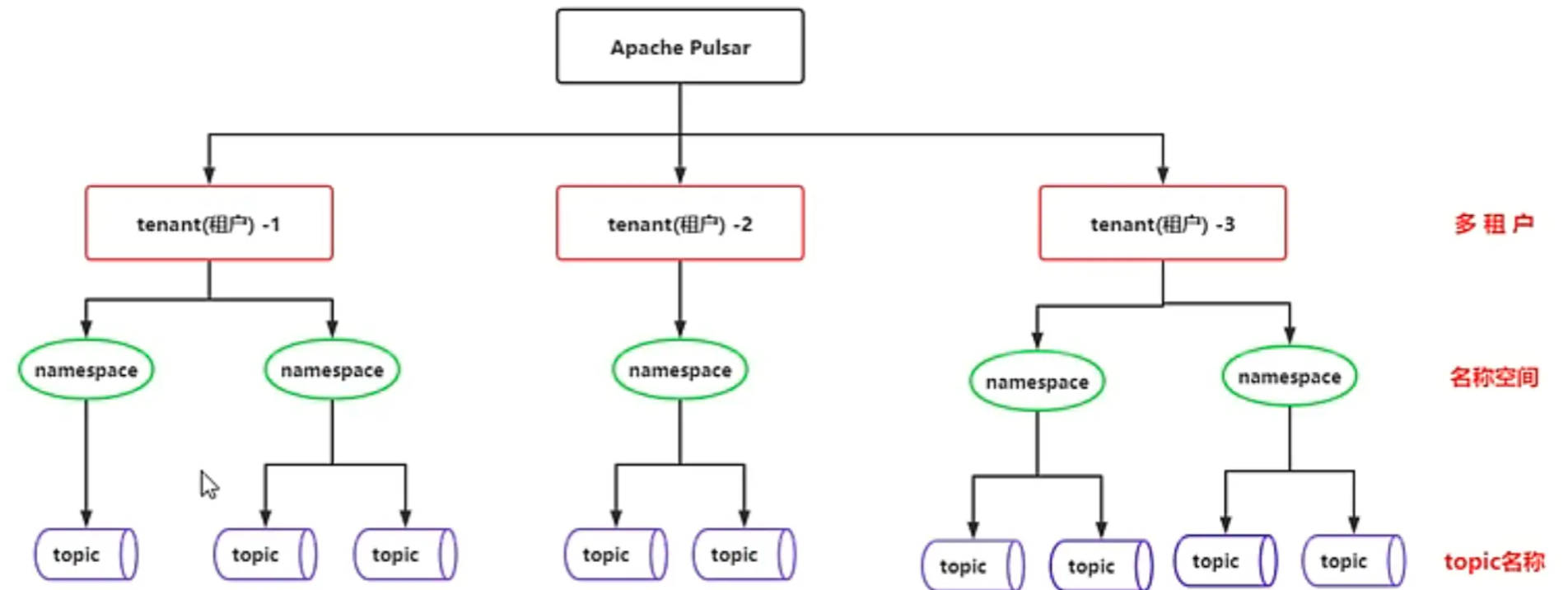
多租户模式
Pulsar的云原生架构天然支持多租户,每个租户下还支持多Namespace,非常适合做共享大集群,方便维护。此外Pulsar天然支持租户之间的逻辑隔离,防止互相干扰,还能实现大集群资源的充分利用
-
Tenant(租户)和 Namespace是Pulsar支持多租户的两个核心概念 -
在租户级别,Pulsar为特定的租户预留合适的存储空间、应用授权和认证机制 -
在namespace级别,Pulsar有一系列的配置策略(policy),包括存储配额、流控、消息过期策略等等
统一消息模型
Pulsar做了队列模型和流模型的统一,在topic级别只需要保存一份数据,同一份数据可多次消费。以流式、队列等方式计算不同的订阅模型,大大的提升了灵活度
同时Pulsar通过事务采用Exactly-Once刚好一次的语义,在进行消息传输过程中,可以确保消息不重不丢 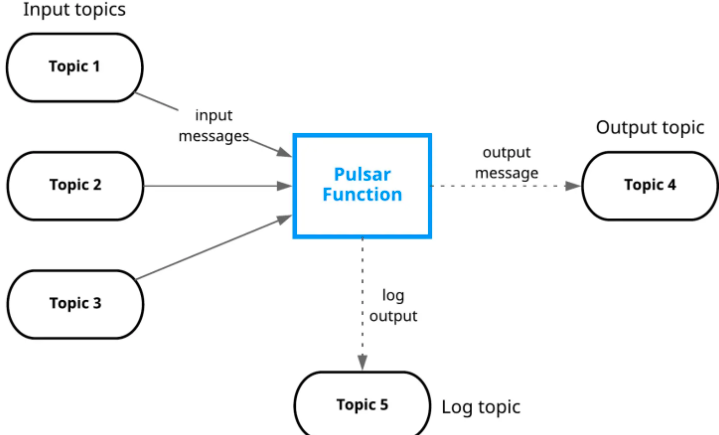
分片流
Pulsar将无界的数据看作是分片的流,分片分散存储在分层存储(tiered storage)、BookKeeper集群和Broker节点上,而对外提供一个统一的、无界数据的视图
不需要用户显示迁移数据,对用户无感知,减少存储成本并保持近似无限的存储 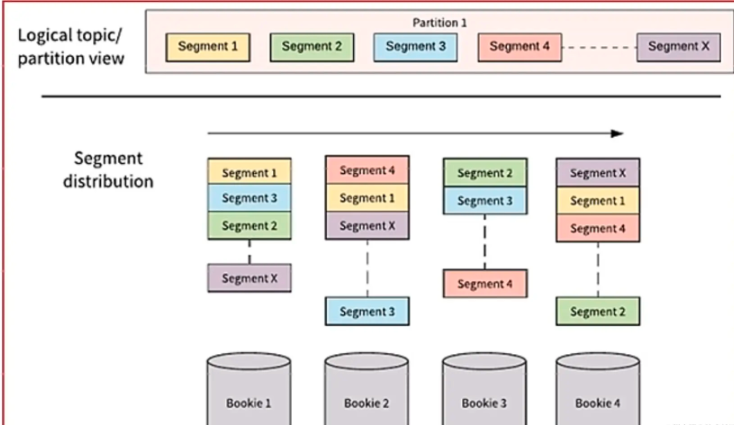
跨地域复制
Pulsar中的跨地域复制是将Pulsar中持久化的消息在多个集群之间备份 在Pulsar2.4.0中新增了复制订阅模式,在某个集群失效情况下,该功能可以在其他集群恢复消费者的消费状态,从而达到热备模式下的消息服务高可用 
架构
单个Pulsar集群由以下三部分组成
-
一个或者多个broker 用于负责处理和负载均衡producer发出的消息 并将这些消息分派给consumer。Broker 和 Pulsar配置存储交互来处理相应的任务,并将消息存储在BookKeeper实例中(bookies);Broker底层依赖的是Zookeeper集群来处理特定的任务 -
包含一个或者多个bookie的BookKeeper负责消息的持久化存储 -
一个ZooKeeper集群用来处理多个Pulsar集群之间的协调任务
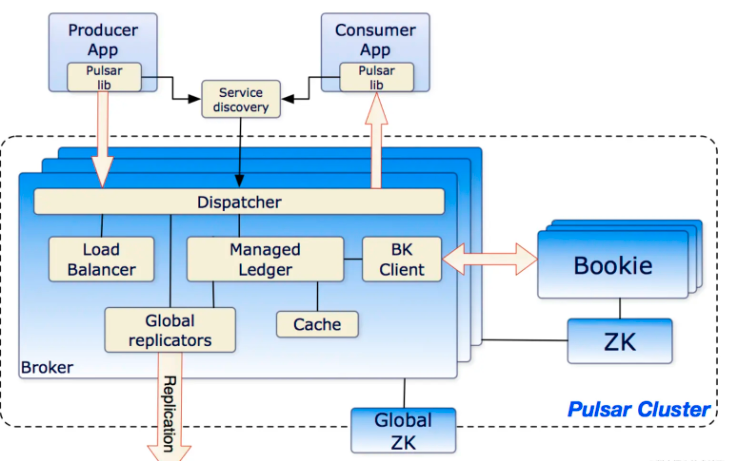
Pulsar分离出Broker和Bookie两层架构,Broker为无状态的服务,用于发布和消费消息,而BookKeeper专注于存储,Pulsar存储是分片的,这种架构可以避免扩容时受到限制,实现数据的独立拓展和快速恢复
Brokers Pulsar的broker是一个无状态的组件,主要负责运行另外的两个组件
-
一个HTTP服务器(service discovery) 它暴露了REST系统管理接口以及在生产者和消费者之间进行Topic查找的API -
一个调度分发器(Dispatcher) 它是一个异步的TCP服务器 通过自定义二进制协议应用与所有相关的数据传输
出于性能考虑,消息通常从Managed Ledger缓存中分派出去,除非积压超过缓存大小。如果积压的消息对于缓存来说太大了,则Broker开始从BookKeeper中读取Entries
为了支持全局Topic异地复制,Broker会控制Replicators追踪本地发布的条目
ZooKeeper元数据存储
Pulsar使用ZooKeeper进行元数据存储、集群配置和协调
-
配置存储Quorum存储了租户、命名空间、和其他需要全局一致的配置项 -
每个集群有自己独立的本地ZooKeeper保存集群内部的配置,例如broker负责哪几个主题及所有权归属元数据、broker负载报告ledger元数据等等
BookKeeper持久化存储
Apache Pulsar为应用程序提供有保障的信息传递,如果消息成功到达broker,就认为其预期达到了目的地
为了提供这种保证,未确认送达的消息需要持久化直到它们被确认送达。这种消息传递模式通常成为持久消息传递,在Pulsar内部,没分新消息都被保存并同步N份
BookKeeper是一个分布式的预写日志(WAL)系统,有如下几个特性
-
使得Pulsar能够利用独立的日志,称为ledgers,随着时间的推移可以为topic创建多个ledgers -
保证多系统挂掉时的ledgers的读取一致性 -
提供不同Boookies之间均匀的IO分布的特性 -
容量和吞吐量都具有水平伸缩性,能够通过增加bookies立即增加容量到集群中

本文由 mdnice 多平台发布















 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









