






ElasticSearch(库、表、索引)
Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎 。
优点:适用于大数据搜索。
原始:SQL(like%李辉%),缺点:如果数据庞大就十分缓慢!采用索引的方式。
安装:
安装之前必须保证java环境配置正确且具有vue的环境,如:nodejs.
官网下载及其缓慢(可能需要翻墙下载)官网地址:(略)
这里直接提供:
**链接:https://pan.baidu.com/s/1Iq72c0h-85BKLPnxywGlbQ?pwd=8888 **
提取码:8888
注意:elasticsearch-head-master直接到github上面下载;
安装方式简单(解压即安装)

ELK:(Elasticsearch、Logstash、Kibana ):三剑客!!!
通过简单的RESTful API 来隐藏Lunene的复杂性,从而让全文搜索变得简单!!!
运行elasticserch:
目录结构:

-
bin:启动文件
-
config:配置文件
- log4j2 日志配置文件
- jvm.options java虚拟机相关配置
- elasticsearch.yml elasticsearch的配置文件! 默认端口9022 跨域
-
lib:相关jar包
-
modules:功能模块
-
plugins:插件! ik(分词器)




运行kibana:


运行head-master:
运用命令启动: **npm install ** npm run start


注意:如果访问报错,需要配置跨域。具体方法网上有这里不在记录!!!

Elasticsearch和Solr差别:
Elasticsearch:全文搜索、结构化搜索、分析!!! 有索引时就快,只支持json
Solr:用post方法向Solr服务器发送一个描述、Field及其内容的xml文档。进行增删改查。存在数据时就快.
Lucene: Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
ES的核心概念
DB ES
数据库(database) 索引(indices)
表(tables) types
行(rows) documents
字段(columns) fields

文档:就是一条条的数据
user
zhangsan 18
lihui 6
类型:可以不用设置、它会自动识别,也可以指定数据类型
索引:相当于数据库
倒排索引:重要
- 索引:
- 字段类型(mapping):
- 文档(documents):
IK分词器
如果要使用中文使用IK分词器:
安装:
官网下载:


分词器种类:
ik_smart
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YpoCgkYe-1661745685484)(C:\Users\Administrator\Desktop\1661689310170.png)]
ik_max_word

有些自己需要的词,需要自己加到我们的分词器字典中!
ik分词器增加自己的配置:


如果我们需要一些自己的词,自己在自己的dic文档中添加自己的词语就可以了
ES的基本语法(重要)
关于索引的基本操作
Rest风格
method url地址 描述
PUT XXXXXXX 创建文档(指定文档id)
POST XXXXXXX 创建文档(随机文档id)
POST XXXXXXX 修改文档
DELETE XXXXXXX 删除文档
GET XXXXXXX 查询文档通过文档id
POST XXXXXXX 查询所有数据
基本测试:
1、创建索引:
PUT /索引名/~类型名~/文档id
{
请求体
}


完成自动增加索引:(数据成功添加,相当于一个数据库)

上述已经说过:字段可以不添加类型、它能够自动识别!但是都有哪些类型呢?
- 字符串类型
- text keyword
- 数值类型
- long integer short byte double harf float scaled float
- 日期类型
- date
- 布尔值类型
- boolean
- 二进制类型
- binary
- …
如何指定字段类型?
创建规则:

通过get请求查看信息:

查看默认信息:(不指定es会默认配置字段类型)

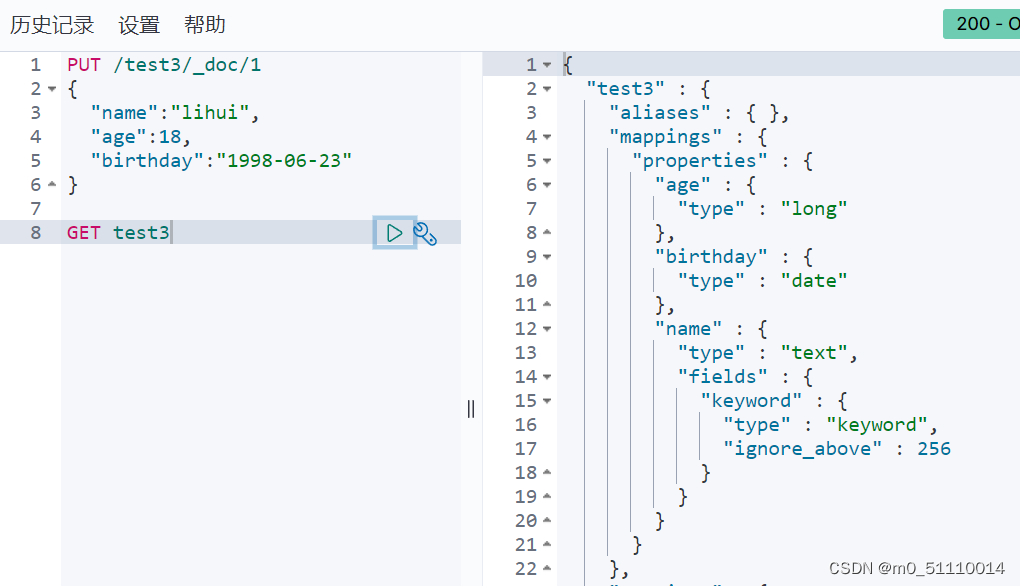
**扩展:**获取健康值代码

更新方法:
可以通过PUT命令和POST命令修改:
但是PUT命令修改有弊端:它的修改会进行覆盖,如果少字段就不存在
删除方法
通过DELETE命令来删除。根据你的请求来判断是删除索引还是删除文档。
关于文档的基本操作(重点)
基本操作:
- 添加数据:

- 查看数据

- 更新数据
- GET

- POST

复杂操作:(针对搜索的)
简单的搜索
GET lihui/user/1

复杂搜索select(排序、分页、高亮、模糊查询、精准查询)

只想查询其中的部分字段:

排序:sort
asc desc
分页查询
form:0 从第几条数据开始
size:10 返回多少条数据
/search/{current}/{pagesize}
boolean查询:
must命令:所有条件都要符合and
should命令:对应数据库的or
must_not命令:对应not
"bool":{
"must":{
"match":{
"name":"lihui"
},
"match":{
"age":12
}
//过滤 gt、gte、lt、lte
"filter":{
"range":{
"age":{
"lt":10
}
}
}
//两个条件查权重 多个条件使用空格隔开 只有满足其中一个结果就可以查出。
"tags":"男 技术";
}
}
多条件查询
精确查询
通过倒排索引查询:
term标签(效率要高一点)
关于分词:
term:直接查询精确的
match:会使用分词器解析!(先分析文档,然后在通过分析文档进行解析)
注意:keyword修饰的词不会被分词器解析
多个值匹配精确查询
高亮查询
命令:highlight(高亮)
"highlight":{
"fields":{
"name":{}
}
}
默认:<em></em>标签
自己设置:"pre_tags":"<p class="key" style:"color:red">"
"post_tags":"</p>"
- 匹配
- 按照条件匹配
- 精确匹配
- 区间范围匹配
- 匹配字段过滤
- 多条件查询
- 高亮查询
这些mysql也可以完成、只是mysql效率比较低。















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











