









这是我的个人博客,欢迎访问:Kidder1的空间
在开始之前,构建AFL++LLVM模式和QEMU模式。
我假设AFL++的路径是~/AFLplusplus,如果您的安装路径不同,请在命令中更改它。
使用下载libxml2的源代码
$ git clone https://gitlab.gnome.org/GNOME/libxml2.git
$ cd libxml2
笔者注:libxml2是一个xml解析器
现在配置它禁用共享库
$ ./autogen.sh
$ ./configure --enable-shared=no
如果您想启用消毒剂,请使用适当的env变量。
在本教程中,我们将启用ASan和UBSan。
$ export AFL_USE_UBSAN=1
$ export AFL_USE_ASAN=1
使用clang包装器构建库
make CC=~/AFLplusplus/afl-clang-fast CXX=~/AFLplusplus/afl-clang-fast++ LD=~/AFLplusplus/afl-clang-fast
笔者注:CC和CXX是两个环境变量,这里是用AFL++可以插桩的编译器进行了替换,可以用export 环境变量=变量值的方式进行定义,也可以用echo $变量名的方式查看已有的环境变量值。
当作业完成后,我们开始使用工具xmllint作为线束对libxml2进行模糊处理,并从测试文件夹中获取一些测试用例作为初始种子。
$ mkdir fuzz
$ cp xmllint fuzz/xmllint_cov
$ mkdir fuzz/in
$ cp test/*.xml fuzz/in/
$ cd fuzz
在启动afl-fuzz之前,请确保使用我们的脚本配置您的系统
$ sudo ~/AFLplusplus/afl-system-config
我们来了
$ ~/AFLplusplus/afl-fuzz -i in/ -o out -- ./xmllint_cov @@
这是AFL++的默认配置,没有确定性突变和任何记忆限制。
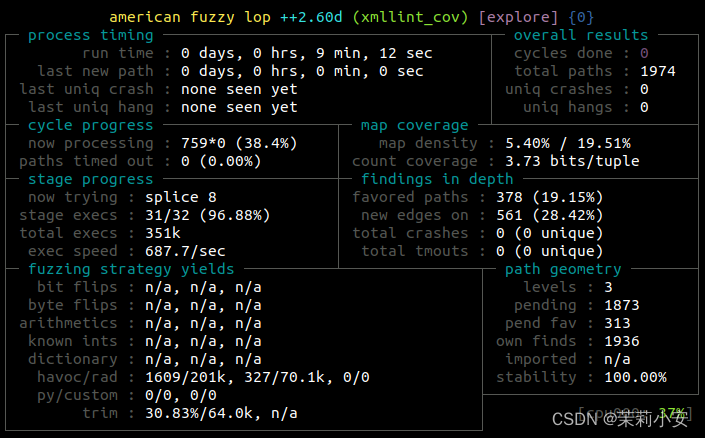
现在,知道libxml2是一个库,因此代码是可重入的,我们可以使用持久模式加快模糊处理过程。
持久模式避免了分叉的开销,并提供了很大的加速。
要启用它,我们必须选择一个可重入例程,并设置一个持久循环来修补代码。
diff --git a/xmllint.c b/xmllint.c
index 735d951d..64725e9c 100644
--- a/xmllint.c
+++ b/xmllint.c
@@ -3102,8 +3102,19 @@ static void deregisterNode(xmlNodePtr node)
nbregister--;
}
+int main(int argc, char** argv) {
+
+ if (argc < 2) return 1;
+
+ while (__AFL_LOOP(10000))
+ parseAndPrintFile(argv[1], NULL);
+
+ return 0;
+
+}
+
int
-main(int argc, char **argv) {
+old_main(int argc, char **argv) {
int i, acount;
int files = 0;
int version = 0;
在这种情况下,我选择parseAndPrintFile,这是从xmllint main调用的主要解析例程。正如你所看到的,我创建了一个新的主函数,它围绕这个函数循环。
__AFL_LOOP是我们必须告诉AFL++我们想要持久模式的方式。每个模糊迭代,而不是用不同的输入分叉并重新执行目标,只是这个循环的一次执行。
数字10000说明,在使用AFL++生成的模糊输入运行10000次后,线束必须分叉并重置目标的状态。当模糊例程是可重入的,但例如内存泄漏时,这很有用,因此我们希望在固定数量的执行后恢复目标,以避免用无用的分配内存填充堆。
要构建它,只需删除之前编译的xmllint并重新编译它。
$ cd ..
$ rm xmllint
$ make CC=~/AFLplusplus/afl-clang-fast CXX=~/AFLplusplus/afl-clang-fast++ LD=~/AFLplusplus/afl-clang-fast
$ cp xmllint fuzz/xmllint_persistent
现在重新启动模糊器
$ cd fuzz
$ ~/AFLplusplus/afl-fuzz -i in/ -o out -- ./xmllint_persistent @@
正如你所看到的,加速是令人印象深刻的。
现在,我们将使用QEMU中的纯二进制工具对xmllint进行模糊处理。
我们会表现得好像没有源代码一样,因此我们不会修补源代码中的任何内容。
首先,构建一个无乐器的二进制文件。在继续操作之前,请提醒恢复LLVM persistent应用的修补程序。
$ cd ...
$ make clean
$ make
$ cp xmllint fuzz/
要在QEMU下以简单的基于fork的方式对其进行模糊处理,只需在afl-fuzz中添加-Q标志即可。
$ cd fuzz
$ ~/AFLplusplus/afl-fuzz -i in/ -o out -Q -- ./xmllint @@
您可能已经注意到,其速度比基于LLVM fork的模糊处理更快。这是因为我们在之前基于LLVM的步骤中使用了ASan+UBSan(因此平均速度降低了2倍)。
请注意,在这种特定情况下,QEMU的速度大约是2倍,这很好。
但是,如果我们想要一个闭源二进制文件的持久模式的速度呢?
没有痛苦,有QEMU持久模式,这是AFL++中引入的一个新功能。
在持久QEMU中有两种可能性,一种是围绕函数循环(如WinAFL),另一种是绕代码的特定部分循环。
在本教程中,我们将选择简单的路径,我们将围绕parseAndPrintFile循环。
首先,定位函数的地址:
$ nm xmllint | grep parseAndPrintFile
0000000000019be0 t parseAndPrintFile
二进制是与位置无关的,QEMU持久化需要实际地址,而不是偏移量。幸运的是,QEMU在固定地址加载PIE可执行文件,x86_64为0x400000000。
我们可以使用AFL_QEMU_DEBUG_MAPS进行检查。如果您的二进制文件不是PIE,则不需要此步骤。
$ AFL_QEMU_DEBUG_MAPS=1 ~/AFLplusplus/afl-qemu-trace ./xmllint -
4000000000-400013e000 r-xp 00000000 103:06 18676576 /home/andrea/libxml2/fuzz/xmllint
400013e000-400033e000 ---p 00000000 00:00 0
400033e000-4000346000 r--p 0013e000 103:06 18676576 /home/andrea/libxml2/fuzz/xmllint
4000346000-4000347000 rw-p 00146000 103:06 18676576 /home/andrea/libxml2/fuzz/xmllint
4000347000-4000355000 rw-p 00000000 00:00 0
...
现在,我们设置必须循环的函数的地址
$ export AFL_QEMU_PERSISTENT_ADDR=0x4000019be0
我们在x86_64上,参数在寄存器中传递。在函数结束时,当我们返回到起始地址时,寄存器会被破坏,因此我们不再有指向rdi中文件名的指针。
为了避免这种情况,我们可以在每次迭代设置AFL_QEMU_PERSISTENT_GPR时保存和恢复通用寄存器的状态。
$ export AFL_QEMU_PERSISTENT_GPR=1
现在,重新运行上一个afl-fuzz命令:
$ ~/AFLplusplus/afl-fuzz -i in/ -o out -Q -- ./xmllint @@
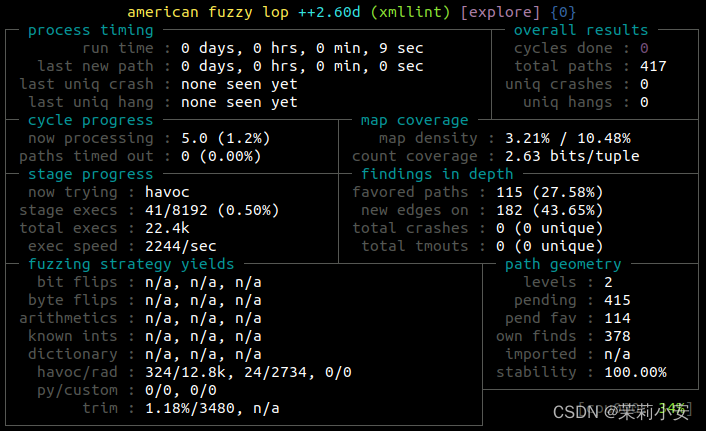
至于持久LLVM,其速度之快令人难以置信。
享受AFL++,继续关注未来其他此类初学者教程。















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









