ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式
协调/通知、集群管理、Master 选举、分布式**锁和分布式队列等功能**
分布式 协调 服务
本质 : 小型的文件存储系统 + 监听通知机制
一般 存储 状态值 或 配置信息
常见:
CAP定理 ZK满足 CP
C 一致性 P 分区容错性
C 最终一致
zookeeper本身是一个树形目录服务(名称空间),非常类似于标准文件系统,key-value 的形式存储。
临时节点: 用于心跳,服务发现
•Zookeeper
是
Apache Hadoop
项目下的一个子项目,是一个树形目录服务。
•Zookeeper
翻译过来就是 动物园管理员,他是用来管
Hadoop
(大象)、
Hive(
蜜蜂
)
、
Pig(
小 猪
)
的管 理员。简称zk
•Zookeeper
是一个分布式的、开源的分布式应用程序的协调服务。
•Zookeeper
提供的主要功能包括:
•配置管理
•分布式锁
•集群管理
•
启动
ZooKeeper
服务
: ./zkServer.sh start
•
查看
ZooKeeper
服务状态
: ./zkServer.sh status
•
停止
ZooKeeper
服务
: ./zkServer.sh stop
•
重启
ZooKeeper
服务
: ./zkServer.sh restart
•czxid
:节点被创建的事务
ID
•ctime:
创建时间
•mzxid:
最后一次被更新的事务
ID
•mtime:
修改时间
•pzxid
:子节点列表最后一次被更新的事务
ID
•cversion
:子节点的版本号
•dataversion
:数据版本号
•aclversion
:权限版本号
•ephemeralOwner
:用于临时节点,代表临时节点的事务
ID
,如果为持久节点则为
0
•dataLength
:节点存储的数据的长度
•numChildren
:当前节点的子节点个数
重点:分布式锁 的几种实现
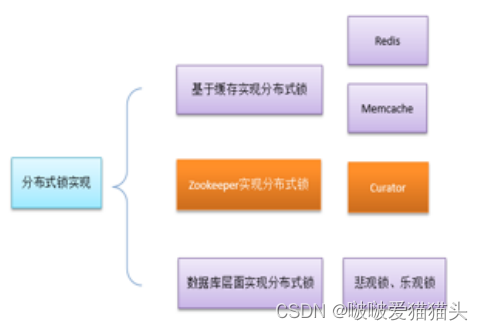
数据库的性能本身就低
redis 基于内存 ,性能较高,但是不可靠,master挂了,就有多个锁数据
而,zk实现的分布式锁的性能不差,且,可靠性较高
Zookeeper JavaAPI
操作
-Watch
监听概述
•ZooKeeper
允许用户在指定节点上注册一些
Watcher
,并且在一些特定事件触发的时候,
ZooKeeper
服务端会将事件通知到感兴趣的客户端上去,该机制是
ZooKeeper
实现分布式协调服务的重要特性。
•ZooKeeper
中引入了
Watcher
机制来实现了发布
/
订阅功能能,能够让多个订阅者同时监听某一个对 象,当一个对象自身状态变化时,会通知所有订阅者。
•ZooKeeper
原生支持通过注册
Watcher
来进行事件监听,但是其使用并不是特别方便
需要开发人员自己反复注册
Watcher
,比较繁琐。
•Curator
引入了
Cache
来实现对
ZooKeeper
服务端事件的监听
•ZooKeeper
提供了三种
Watcher
:
•NodeCache :
只是监听某一个特定的节点
•PathChildrenCache :
监控一个
ZNode
的子节点
.
•TreeCache :
可以监控整个树上的所有节点,类似于
PathChildrenCache
和
NodeCache
的组合
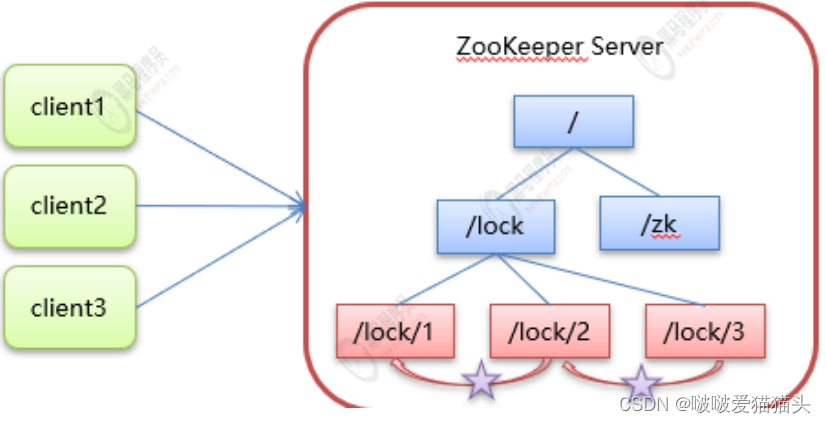
(背诵)zookeeper分布式锁原理 --- 总结
•核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点。
1.
客户端获取锁时,在
lock
节点下创建临时顺序节点。
2.
然后获取
lock
下面的所有子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号
最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
3.
如果发现自己创建的节点并非
lock
所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要
找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
4.
如果发现比自己小的那个节点被删除,则客户端的
Watcher
会收到相应通知,此时再次判断自己创建的节点
是否是
lock
子节点中序号最小的,如果是则获取到了锁,
如果不是则重复以上步骤继续获取到比自己小的一个节点
并注册监听。
为什么是临时的?
因为,不是临时的,服务在不正常挂掉后,该节点没有执行删除操作,导致所有服务都阻塞在这里
zk的节点类型有,默认创建的是持久的,还要临时的,持久顺序的,临时顺序的
为什么是创建的顺序的?
因为,在监听时要找比自己小的,顺序节点是在创建时加上生成的序号,是一种排队的思想,先进先出的提供服务
zookeeper分布式锁的代码实现 --- Curator 都封装好了
ps:dubbo,和curator是阿帕奇的顶级项目,而zk是子项目
Curator
实现分布式锁
API
在
Curator
中有五种锁方案:
InterProcessSemaphoreMutex
:分布式排它锁(非可重入锁)
InterProcessMutex
:分布式可重入排它锁
InterProcessReadWriteLock
:分布式读写锁
InterProcessMultiLock
:将多个锁作为单个实体管理的容器
InterProcessSemaphoreV2
:共享信号量
// 类变量
private InterProcessMutex lock ;
//lock初始化 --- 构造方法
lock = new InterProcessMutex(client,"/lock");
// 方法里获取锁
lock.acquire(3, TimeUnit.SECONDS);
// 释放锁
finally {
//释放锁
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
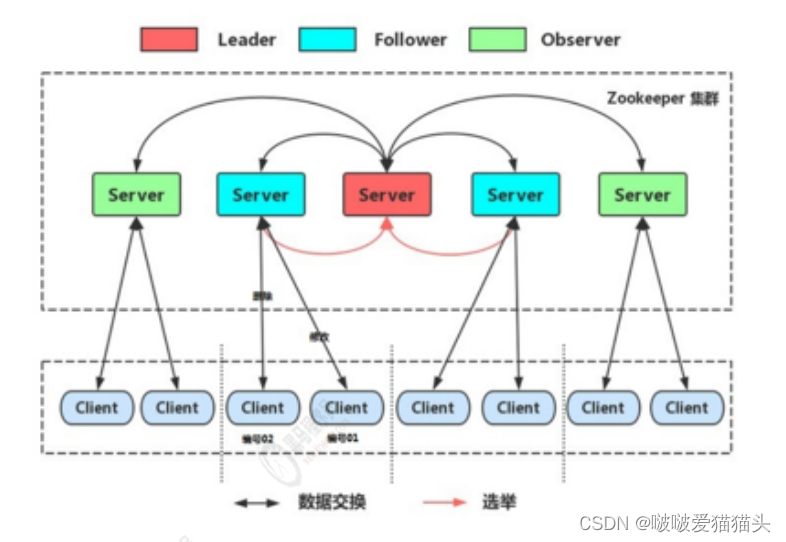
ZooKeeper 集群
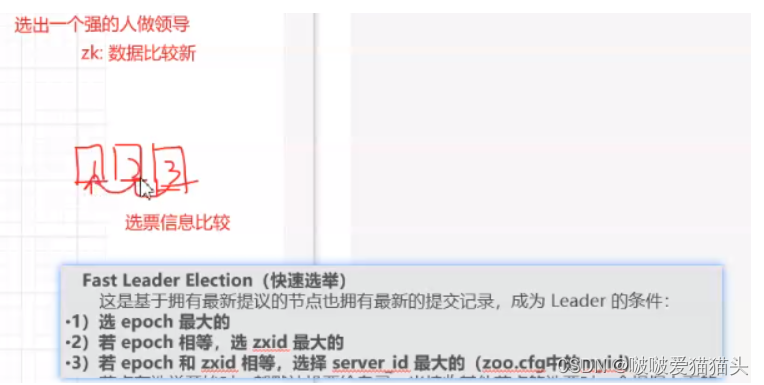
Leader选举:
•Serverid
:服务器
ID
比如有三台服务器,编号分别是
1,2,3
。
编号越大在选择算法中的权重越大。
•Zxid
:数据
ID
服务器中存放的最大数据
ID.
值越大说明数据
越新,在选举算法中数据越新权重越大。
•
在
Leader
选举的过程中,如果某台
ZooKeeper
获得了超过半数的选票,
则此
ZooKeeper
就可以成为
Leader
了。
Zookeepe
集群角色
在
ZooKeeper
集群服中务中有三个角色:
•Leader
领导者 :
1.
处理事务请求
2.
集群内部各服务器的调度者
•Follower
跟随者 :
1.
处理客户端非事务请求,转发事务请求给
Leader
服务器
2.
参与
Leader
选举投票
•Observer
观察者:
1.
处理客户端非事务请求,转发事务请求给
Leader
服务器
事务请求:增删改
非事务请求:查询,一般查询较多,当查询超过当前节点的处理能力时,转发给leader
主节点 要将更新后的 数据 同步给所有的节点
ZAB协议,定义了事务操作的统一性
ZooKeeper使用的是ZAB协议作为数据一致性的算法, ZAB(ZooKeeper Atomic Broadcast ) 全称为:原
子消息广播协议。在Paxos算法基础上进行了扩展改造而来的,ZAB协议设计了支持原子广播、崩溃恢复,
ZAB协议保证Leader广播的变更序列被顺序的处理。
四种状态,其中三种跟选举有关
➢
LOOKING:系统刚启动时或者Leader崩溃后正处于选举状态
➢
FOLLOWING:Follower节点所处的状态,同步leader状态,参与投票
➢
LEADING:Leader所处状态
➢
OBSERVING,观察状态,同步leader状态,不参与投票
选举时也是半数以上通过才算通过
client不会直连leader
ZAB协议,如果当前集群中没有leader角色,那么就会进入到崩溃模式
崩溃模式:leader挂了,或者,leader失去过半follower的联系
崩溃模式 目的:进行恢复,基于选举算法选leader,新leader先完成过半的follower完成数据同步,进入消息广播模式


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









