







一. 窗口函数
理解: group by 分组合并
窗口函数 : 分组不合并
MySQL 官方网站窗口函数的网址为 https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptio ns.html#function_row-number 。
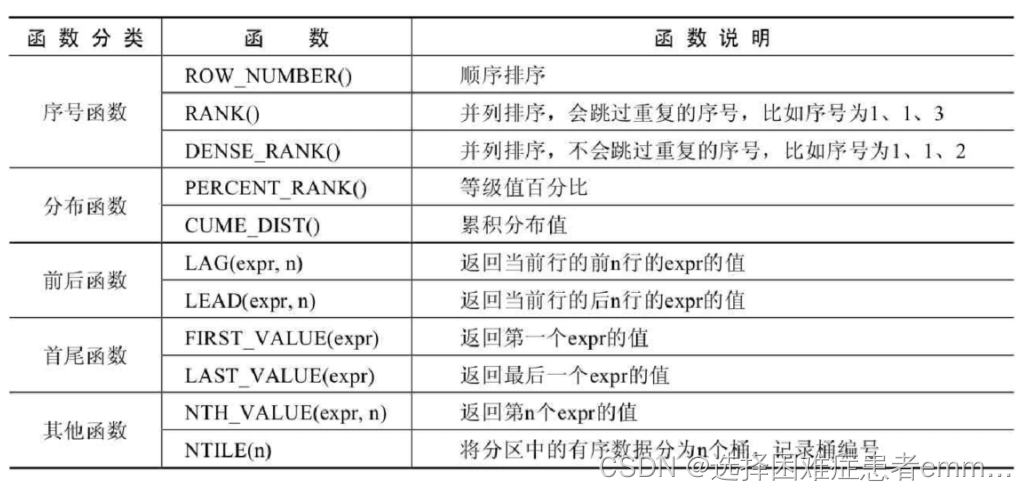
1.1 分类
1.2 语法结构
函数 OVER([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])CREATE TABLE goods(
id INT PRIMARY KEY AUTO_INCREMENT,
category_id INT, category VARCHAR(15),
NAME VARCHAR(30), price DECIMAL(10,2),
stock INT,
upper_time DATETIME );
INSERT INTO goods(category_id,category,NAME,price,stock,upper_time)
VALUES (1, '女装/女士精品', 'T恤', 39.90, 1000, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '连衣裙', 79.90, 2500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '卫衣', 89.90, 1500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '牛仔裤', 89.90, 3500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '百褶裙', 29.90, 500, '2020-11-10 00:00:00'),
(1, '女装/女士精品', '呢绒外套', 399.90, 1200, '2020-11-10 00:00:00'),
(2, '户外运动', '自行车', 399.90, 1000, '2020-11-10 00:00:00'),
(2, '户外运动', '山地自行车', 1399.90, 2500, '2020-11-10 00:00:00'),
(2, '户外运动', '登山杖', 59.90, 1500, '2020-11-10 00:00:00'),
(2, '户外运动', '骑行装备', 399.90, 3500, '2020-11-10 00:00:00'),
(2, '户外运动', '运动外套', 799.90, 500, '2020-11-10 00:00:00'),
(2, '户外运动', '滑板', 499.90, 1200, '2020-11-10 00:00:00');
###### 1. 序号函数
1. ROW_NUMBER()函数能够对数据中的序号进行顺序显示
#举例:查询 goods 数据表中每个商品分类下价格降序排列的各个商品信息。
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods;
#举例:查询 goods 数据表中每个商品分类下价格最高的3种商品信息。
SELECT *
FROM (
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods) t
WHERE row_num <= 3;
2.RANK()函数
使用RANK()函数能够对序号进行并列排序,并且会跳过重复的序号,比如序号为1、1、3。
#举例:使用RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息
SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods;
举例:使用RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息。
SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods
WHERE category_id = 1 AND row_num <= 4;
3.DENSE_RANK()函数
DENSE_RANK()函数对序号进行并列排序,并且不会跳过重复的序号,比如序号为1、1、2。
#举例:使用DENSE_RANK()函数获取 goods 数据表中各类别的价格从高到低排序的各商品信息。
SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods;
#举例:使用DENSE_RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息。
SELECT *
FROM(
SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods) t
WHERE category_id = 1 AND row_num <= 3;
-- 2. 分布函数
1.PERCENT_RANK()函数
PERCENT_RANK()函数是等级值百分比函数。按照如下方式进行计算。
(RANK - 1) / (ROWS - 1)
rank的值为使用RANK()函数产生的序号,rows的值为当前窗口的总记录数
#举例:计算 goods 数据表中名称为“女装/女士精品”的类别下的商品的PERCENT_RANK值
#写法一:
SELECT RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS r,
PERCENT_RANK() OVER (PARTITION BY category_id ORDER BY price DESC) AS pr,
id, category_id, category, NAME, price, stock
FROM goods
WHERE category_id = 1;
#写法二:
SELECT RANK() OVER w AS r,
PERCENT_RANK() OVER w AS pr,
id, category_id, category, NAME, price, stock
FROM goods
WHERE category_id = 1 WINDOW w AS (PARTITION BY category_id ORDER BY price DESC);
2.CUME_DIST()函数
CUME_DIST()函数主要用于查询小于或等于某个值的比例。
#举例:查询goods数据表中小于或等于当前价格的比例。
SELECT CUME_DIST() OVER(PARTITION BY category_id ORDER BY price ASC) AS cd,
id, category, NAME, price
FROM goods;
-- 3. 前后函数
1.LAG(expr,n)函数
LAG(expr,n)函数返回当前行的前n行的expr的值。
举例:查询goods数据表中前一个商品价格与当前商品价格的差值。
SELECT id, category, NAME, price, pre_price, price - pre_price AS diff_price
FROM (
SELECT id, category, NAME, price,LAG(price,1) OVER w AS pre_price
FROM goods
WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;
2.LEAD(expr,n)函数
LEAD(expr,n)函数返回当前行的后n行的expr的值。
举例:查询goods数据表中后一个商品价格与当前商品价格的差值。
SELECT id, category, NAME, behind_price, price,behind_price - price AS diff_price
FROM(
SELECT id, category, NAME, price,LEAD(price, 1) OVER w AS behind_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price)) t;
-- 4. 首尾函数
1.FIRST_VALUE(expr)函数
FIRST_VALUE(expr)函数返回第一个expr的值。
举例:按照价格排序,查询第1个商品的价格信息。
SELECT id, category, NAME, price, stock,FIRST_VALUE(price) OVER w AS
first_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
2.LAST_VALUE(expr)函数
LAST_VALUE(expr)函数返回最后一个expr的值。
#举例:按照价格排序,查询最后一个商品的价格信息。
SELECT id, category, NAME, price, stock,LAST_VALUE(price) OVER w AS last_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
-- 5. 其他函数
1.NTH_VALUE(expr,n)函数
NTH_VALUE(expr,n)函数返回第n个expr的值。
#举例:查询goods数据表中排名第2和第3的价格信息
SELECT id, category, NAME, price,NTH_VALUE(price,2) OVER w AS second_price,
NTH_VALUE(price,3) OVER w AS third_price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
2.NTILE(n)函数
NTILE(n)函数将分区中的有序数据分为n个桶,记录桶编号。
#举例:将goods表中的商品按照价格分为3组。
SELECT NTILE(3) OVER w AS nt,id, category, NAME, price
FROM goods WINDOW w AS (PARTITION BY category_id ORDER BY price);
1.3 小结
窗口函数的特点是可以分组,而且可以在分组内排序。另外,窗口函数不会因为分组而减少原表中的行数,这对我们在原表数据的基础上进行统计和排序非常有用。
二. 新特性2:公用表表达式
公用表表达式(或通用表表达式)简称为 CTE (Common Table Expressions)。 CTE 是一个命名的临时结果集,作用范围是当前语句。CTE 可以理解成一个可以复用的子查询,当然跟子查询还是有点区别的,CTE 可以引用其他 CTE ,但子查询不能引用其他子查询。所以,可以考虑代替子查询。(子查询类似于局部变量,表达式类似于会话用户变量)依据语法结构和执行方式的不同,公用表表达式分为 普通公用表表达式 和 递归公用表表达式 2 种
2.1 普通公用表表达式
WITH CTE名称
AS (子查询)
SELECT|DELETE|UPDATE 语句;普通公用表表达式类似于子查询,不过,跟子查询不同的是,它可以被多次引用,而且可以被其他的普通公用表表达式所引用。
# 举例:查询员工所在的部门的详细信息。
SELECT * FROM departments
WHERE department_id IN (
SELECT DISTINCT department_id
FROM employees
);
或者
WITH emp_dept_id
AS (SELECT DISTINCT department_id FROM employees)
SELECT *
FROM departments d JOIN emp_dept_id e
ON d.department_id = e.department_id;
例子说明,公用表表达式可以起到子查询的作用。以后如果遇到需要使用子查询的场景,你可以在查询之前,先定义公用表表达式,然后在查询中用它来代替子查询。而且,跟子查询相比,公用表表达式有 一个优点,就是定义过公用表表达式之后的查询,可以像一个表一样多次引用公用表表达式,而子查询 则不能。
2.2 递归公用表表达式
递归公用表表达式也是一种公用表表达式,只不过,除了普通公用表表达式的特点以外,它还有自己的 特点,就是 可以调用自己 。它的语法结构是:WITH RECURSIVE CTE名称 AS (子查询) SELECT|DELETE|UPDATE 语句;递归公用表表达式由 2 部分组成,分别是种子查询和递归查询,中间通过关键字 UNION [ALL] 进行连接。这里的 种子查询,意思就是获得递归的初始值 。这个查询只会运行一次,以创建初始数据集,之后递归 查询会一直执行,直到没有任何新的查询数据产生,递归返回
#案例:针对于我们常用的employees表,包含employee_id,last_name和manager_id三个字段。如果a是b
的管理者,那么,我们可以把b叫做a的下属,如果同时b又是c的管理者,那么c就是b的下属,是a的下下
属。
找出公司中所有下下属
WITH RECURSIVE cte AS
(
SELECT employee_id,last_name,manager_id,1 AS n FROM employees WHERE employee_id = 100 -- 种子查询,找到第一代领导
UNION ALL
SELECT a.employee_id,a.last_name,a.manager_id,n+1
FROM employees AS a JOIN cte
ON (a.manager_id = cte.employee_id) -- 递归查询,找出以递归公用表表达式的人为领导的人
)
SELECT employee_id,last_name FROM cte WHERE n >= 3;总之,递归公用表表达式对于查询一个有共同的根节点的树形结构数据,非常有用。它可以不受层级的 限制,轻松查出所有节点的数据。如果用其他的查询方式,就比较复杂了
2.3 小结
公用表表达式的作用是可以替代子查询,而且可以被多次引用。递归公用表表达式对查询有一个共同根节点的树形结构数据非常高效,可以轻松搞定其他查询方式难以处理的查询。
三. 练习
#1. 创建students数据表,如下
CREATE TABLE students(
id INT PRIMARY KEY AUTO_INCREMENT,
student VARCHAR(15),
points TINYINT );
#2. 向表中添加数据如下
INSERT INTO students(student,points)
VALUES ('张三',89),
('李四',77),
('王五',88),
('赵六',90),
('孙七',90),
('周八',88);
#3. 分别使用RANK()、DENSE_RANK() 和 ROW_NUMBER()函数对学生成绩降序排列情况进行显示
#方式一
SELECT
RANK() OVER (ORDER BY points DESC) AS '排序1',
DENSE_RANK() OVER (ORDER BY points DESC) AS '排序2',
ROW_NUMBER() OVER (ORDER BY points DESC) AS '排序3',
student,points
FROM students;
方式二
SELECT
RANK() OVER w AS '排序1',
DENSE_RANK() OVER w AS '排序2',
ROW_NUMBER() OVER w AS '排序3',
student,points
FROM students WINDOW w AS (ORDER BY points DESC);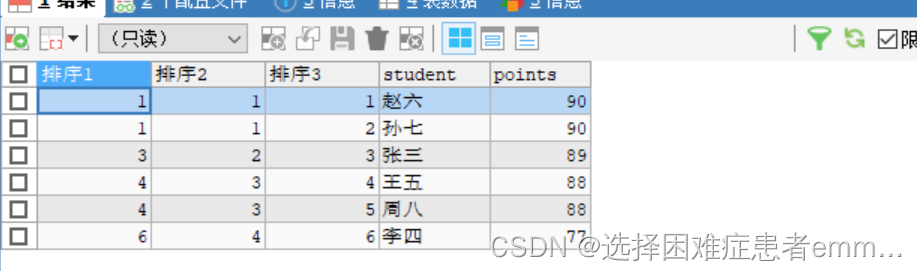















 1895
1895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









