







P. V. Giampouras, A. A. Rontogiannis and K. D. Koutroumbas, "Low-rank and sparse NMF for joint endmembers' number estimation and blind unmixing of hyperspectral images," 2017 25th European Signal Processing Conference (EUSIPCO), 2017, pp. 1430-1434, doi: 10.23919/EUSIPCO.2017.8081445.
摘要:
对场景中存在的端元数量的估计是高光谱解混过程中的一项关键任务。该估计的准确性在后续的无监督解混步骤中起着至关重要的作用,即端元光谱特征的推导(端元的提取)和像素的丰度分数的估计。文献中普遍采用的做法是将端元数估计和解混作为两个独立的任务,将前者的结果作为后者的输入。在本文中,我们超越了这种需要计算的策略。更精确地说,我们提出了一个多约束优化框架,该框架将终端成员的数量估计和无监督解混封装在一个单一任务中。这是通过一个低秩稀疏非负矩阵分解原理适当地表述问题来实现的,其中使用复杂的“1/”2范数惩罚项来提升低秩性。在此基础上,提出了一种交替近端算法来最小化新出现的代价函数。仿真和实际数据实验结果验证了该方法的有效性。
本文介绍:
在本文中,我们提出了一种多重约束NMF方法,以同时实现a)确定端元个数,b)提取端元光谱特征,c)估计像素的丰度值。为此,我们引入了一个基于群稀疏性' L1/ L 2'诱导范数的复杂的低秩提升项。这一项通过在它们的列上加强联合稀疏性来惩罚端元矩阵和丰度矩阵。这样,我们就超越了仅仅揭示秩的范畴,因为我们进一步鼓励对这些矩阵列空间的真基的估计。同时,稀疏性在丰度矩阵上更受青睐,因为它在物理上是有意义的。综上所述,采用稀疏和低秩NMF方法实现了端元数估计和解混。据我们所知,这是第一次将这两个问题同时封装在一个任务中。新提出的最小化问题通过交替近端牛顿型算法有效地解决。仿真和实际数据验证了该算法的良好性能。
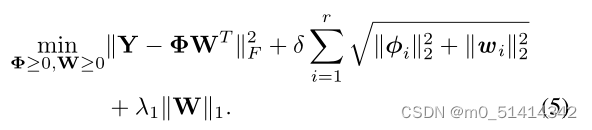
(5)中的第一项对数据矩阵Y及其双线性表示ΦWT进行拟合,第二项为一种新的低秩提升惩罚,(5)中的最后一项为' 1稀疏诱导范数。参数δ和λ1分别为低秩项的正则化系数和稀疏项的正则化系数。简单地说,(5)定义了一个多重约束优化问题的代价函数,它同时考虑了a)因子Φ, W的非负性,b)ΦWT乘积的低秩和c)丰度矩阵W上的稀疏性。















 3337
3337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









