







一 名词解析
1.1 Broker
Broker 是组成 Kafka 集群的服务器节点,可能有一个或多个(当然一个节点没有意义),负责接收和处理客户端发送的请求及对消息进行持久化。尽管多个 Broker 可以运行在同一个服务器上,但是为了高可用性通常都是一个机器一个 Broker。
多个 Broker 保证了高可用特性。
1.2 Topic(主题)
承载消息的逻辑容器,同类消息集合。可理解为关系型数据库中的表(Table),不同的 Topic 下的消息在磁盘上存放位置是独立的。
1.3 Partitioning(分区)
Kafka 将每个主题划分为多个分区(Partition),每个分区是一组有序的消息日志,生产者生产的每条消息只会被发送到一个分区中。
每个分区中数据使用多个日志段(Log Segment) 文件存储,单个分区中数据是有序的,但是不同分区间的数据是无序的。所以若业务需要保证严格数据的顺序,则需要将分区数设置为 1。
消息分散在多个 Partitioning 中,保证了高性能特性的同时也提高了服务的伸缩性(Scalability)。
1.4 Replica(副本)
Kafka 定义了两类副本:领导者副本(LeaderReplica)和追随者副本(Follower Replica)。其中领导者副本提供对外服务(与客户端交互),追随者副本仅是被动追随领导者副本,提供数据冗余之用。
直白描述就是:生产者往领导者副本写消息,消费者向领导者副本读消息;追随者副本仅向领导者副本发送请求,同步最新的消息。再次强调的是追随者不能想 MySQL 主从下从节点还能提供读服务。
多个 Replica 保证了高可用特性。
1.5 Offset(消息位移)
表示分区中每条消息的位置信息,是一个单调递增且不变的值。Kafka 存储文件是按照 offset.kafka 来命名,如第一个文件:00000000000.kafka。
1.6 Producer(生产者)
消息生产者,将消息发布到 Kafka 的 Topic 中。按不同的设置又分为:幂等Producer、事务Producer等。
支持三种分区策略:
- Round-robin - 轮询策略(默认),保证消息最大限度地被平均分配到所有分区上。
- Randomness - 随机策略,消息放置到任意一个分区上。
- key-ordering - 消息键保序策略,同属一个 key 的消息会被写到相同的分区里。
1.7 Consumer Group(消费组)
将多个消费者(Consumer)组成一个组来消费一组主题,这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它。
引入消费者组是为了提升消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)。
1.8 Consumer Offset(消费者位移)
记录消费者消费分区上消息的位置,不要和消息位移弄混淆了。消息位移是分区内的消息位置,它是不变的,即一旦消息被成功写入到一个分区上,它的位移值就是固定的了;消费者位移可能是随时变化的,指示消费者消费进度。
1.9 Rebalance(重平衡)
消费者组内某个消费者挂掉后,其他消费者自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 实现高可用的重要手段之一。
1.10 结构图

二 分区策略
Kafka 的消息组织方式为三级结构:主题-分区-消息。主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。常用的消息分区策略有三种:Round-robin - 轮询策略(默认)、Randomness - 随机策略、key-ordering - 按键分组策略。
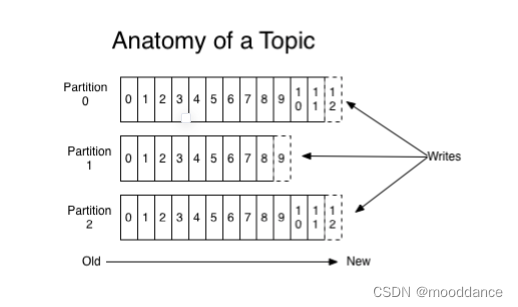
2.1 Round-robin - 轮询策略(默认)
轮询策略保证消息最大限度地被平均分配到所有分区上,有非常优秀的负载均衡表现,总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是最常用的分区策略之一。
2.2 Randomness - 随机策略
随机策略将消息随机放置到任意一个分区上,随机效果不如轮询策略。
2.3 key-ordering - 按键分组策略
Kafka 允许为每条消息定义消息键,简称为 Key,如地区代码、游戏ID等具有分组意义的 Key。按键分组策略将同属一个 Key 的消息会被写到相同的分区里。
注意:如果指定了 Key,那么默认实现按消息键保序策略;如果没有指定 Key,则使用轮询策略。
三 消息压缩
Kafka 的消息层次分为两层:消息集合(message set)以及消息(message)。一个消息集合中包含若干条日志项(record item),日志项才是真正存储消息的地方。
Kafka 底层的消息日志由一系列消息集合日志项组成。Kafka 通常不会直接操作具体的一条条消息,总是在消息集合这个层面上进行写入操作。
3.1 在哪压缩
生产者端和 Broker 端都可能会发生压缩操作。生产者压缩是开发者自己控制,Broker 端则会在以下两种情况下发生压缩。
- 若 Broker 端和 Producer 端使用不同的压缩算法,Broker 会先解压在使用 Broker 设定的压缩算法进行压缩。
- Broker 端发生了消息格式转换。
3.2 压缩算法
Kafka 支持 3 种压缩算法:GZIP、Snappy 和 LZ4。从 2.1.0 开始,Kafka 正式支持 Zstandard 算法(简写为 zstd)。
下图是 Facebook Zstandard 官网提供的一份压缩算法 benchmark 比较结果:
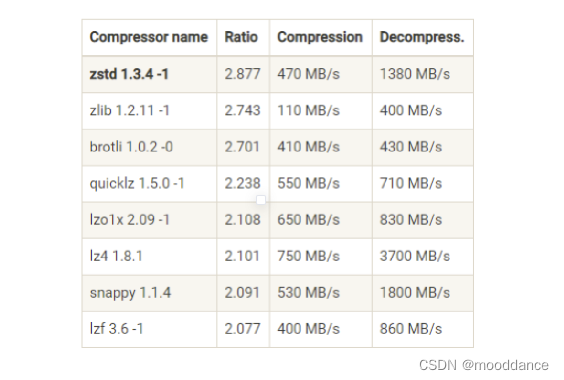
从上如可得到以下结论:
- 吞吐量:LZ4 > Snappy > zstd 和 GZIP。
- 压缩比:zstd > LZ4 > GZIP > Snappy。
- 物理资源使用:Snappy 算法占用的网络带宽最多,zstd 最少。
- CPU 使用率:都差不多,压缩时Snappy 算法相对高一些。解压缩时 GZIP 算法相对较高。
四 消息交付
4.1 消息交付语义
消息交付可靠性保障一般有以下几种情况,Kafka 默认提供第二种,即至少一次。
- 最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
- 至少一次(at least once):消息不会丢失,但有可能被重复发送。
- 精确一次(exactly once):消息不会丢失,也不会被重复发送。
4.2 消息丢失
Kafka 只对 已提交的消息(committed message) 做有限度的持久化保证。当 Kafka 的若干个 Broker 成功地接收到一条消息并写入到日志文件后,它们会告诉生产者程序这条消息已成功提交。此时,这条消息在 Kafka 看来就正式变为“已提交”消息了。
所以有以下情况(不仅限于)可能导致消息丢失:
1. 生产者丢失数据
网络抖动,导致消息压根就没有发送到 Broker 端;或者消息本身不合格导致 Broker 拒绝接收(比如消息太大了,超过了 Broker 的承受能力)等。
当然也有一些解决方案尽可能避免这写情况发生:
- Producer 永远要使用带有回调通知的发送 API,也就是说不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。
- 设置 Producer 参数 acks = all,所有副本 Broker 都要接收到消息,该消息才算是“已提交”。
- 设置 Producer 参数 retries 稍大一些,增加重试次数。尽量避免网络问题导致的失败。
2. 消费者丢失数据
消费者丢失数据主要体现在对偏移量的少读、漏读方面,解决方案:关闭自动提交位移,消费者程序手动提交位移(当然这可能导致多次消费的情况,需要在业务上进行去重来)。
合理设置下面一些参数也能尽可能避免消息丢失的可能:
- 设置 Broker 参数 unclean.leader.election.enable = false,避免落后太多的 Broker 竞选分区的 Leader。
- 设置 Broker 参数 replication.factor >= n,n 可以多几份,代表备份多处。
- 设置 Broker 参数 min.insync.replicas > 1,控制的是消息至少要被写入多少个副本才算是“已提交”。该值尽可能大一些。
五 如何保证 精确一次 提交
上一小节说到了消息丢失可能性和一些简单的处理方案,其实 Kafka 可以通过两种机制:**幂等性(Idempotence)和事务(Transaction)**保证精确一次消息提交。
5.1 幂等型 Producer
0.11.0.0 版本引入幂等性 Producer,参数指定 enable.idempotence = true 开启。enable.idempotence 被设置成 true 后,Producer 自动升级成幂等性 Producer。
1. 实现原理
在 Broker 端多保存一些字段。当 Producer 发送了具有相同字段值的消息后,Broker 能够自动知晓这些消息已经重复了,于是
在后台默默地把它们“丢弃”掉。
2. 作用范围
- 只能保证单分区上的幂等性,即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。
- 它只能实现单会话上的幂等性,不能实现跨会话的幂等性。
5.2 事务型 Producer
事务型 Producer 能够保证将消息原子性地写入到多个分区中。这批消息要么全部写入成功,要么全部失败。另外,事务型 Producer 也不担心进程的重启。Producer 重启后,Kafka 依然保证它们发送消息的精确一次处理。
事务型建立在 幂等型 Producer 上,即需要将参数 enable.idempotence = true 。除此之外还需要制定一个事务ID,通过参数 transctional.id = id(ID 值需要有代表性些) 设置。
下面用 Java 和 PHP 举例子:
- java
// 事务的初始化
producer.initTransactions();
try {
// 事务开始
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
// 事务提交
producer.commitTransaction();
} catch (KafkaException e) {
// 事务终止
producer.abortTransaction();
}
- php
$conf = new RdKafka\Conf();
$conf->set('metadata.broker.list', 'localhost:9092');
$conf->set('transactional.id', 'some-id');
$producer = new RdKafka\Producer($conf);
$topic = $producer->newTopic("test");
$producer->initTransactions(10000);
try {
$producer->beginTransaction();
for ($i = 0; $i < 10; $i++) {
$topic->produce(RD_KAFKA_PARTITION_UA, 0, "Message $i");
$producer->poll(0);
}
// 提交事务
$error = $producer->commitTransaction(10000);
if (RD_KAFKA_RESP_ERR_NO_ERROR !== $error) {
}
} catch (KafkaException e) {
// 事务终止
$producer->abortTransaction();
}
5.3 Consumer 如何应对?
Consumer 怎么应对事务型和非事务型 Producer 的消息?可以设置参数 isolation.level 。
-
read_uncommitted(默认):Consumer 能够读取到 Kafka 写入的任何消息,无论事务型 Producer 提交事务还是非事务型 Producer ,其写入的消息都可以读取(写入中,但是最后终止的也会被读到。脏读)。如果你用了事务型 Producer,那么对应的 Consumer 就不要使用这个值。可理解为:不可重复读。
-
read_committed:Consumer 只会读取提交的消息,包括事务型 Producer 成功提交事务写入的消息和非事务型写入的。可理解为:可重复读。
5.4 小节
幂等型 Producer 和事务型 Producer 都是 Kafka 实现精确一次处理语义所提供的工具,只是它们的作用范围是不同的。
幂等型 Producer 只能保证单分区、单会话上的消息幂等性;而事务型 Producer 能够保证跨分区、跨会话间的幂等性。从交付语义上来看,自然是事务型 Producer 更为精准。
但是比起幂等性 Producer,事务型 Producer 的性能要更差。所以要结合业务实际选择。
六 消费组
Consumer Group 是 Kafka 提供的可扩展且具有容错性的消费者机制。具有相同的组ID(参数 group.id 指定)的消费者都同属一个消费组,不过每个分区只能由同一个消费者组内的一个 Consumer 实例来消费。
6.1 消费分发模型
一般常见的消息分发模型有:点对点模型、发布 / 订阅模型等,各有优缺点。
- 点对点模型:只能被下游的一个Consumer消费。一旦被消费,消息就没了,伸缩性(scalability)很差。
- 发布 / 订阅模型:可以被多个 Consumer 消费,但它的问题也是伸缩性不高,因为每个订阅者都必须要订阅主题的所有分区。
但是 Kafka Consumer Group 机制拥有上面两种优点的同时避免了其缺点,Consumer Group 订阅了多个主题后,组内的每个实例不要求一定要订阅主题的所有分区,它只会消费部分分区中的消息。
Consumer Group 之间彼此独立,互不影响,它们能够订阅相同的一组主题而互不干涉。避免了伸缩性差的问题。
如果所有实例都属于同一个 Group,那么 Kafka 实现的就是消息队列模型;如果所有实例分别属于不同的 Group,那么 Kafka 实现的就是发布 / 订阅模型。
6.2 如何确定消费者数量
理想情况下,Consumer 实例的数量应该等于 Group 订阅主题的分区总数。一般不推荐设置大于总分区数的 Consumer 实例。设置多余的实例只会浪费资源,而没有任何好处。
七 位移(Offset)
在 Consumer Group 看来,Offset 是一个 KV 对。Key 是分区,V 对应Consumer消费该分区的最新位移。
老版本的 Consumer Group 把位移保存在 ZooKeeper 中,但 ZooKeeper 这类元框架并不适合进行频繁的写更新,而 Consumer Group 的位移更新却是一个非常频繁的操作。所以这种大吞吐量的写操作会极大地拖慢 ZooKeeper 集群的性能。
新版本的 Consumer Group 将位移保存在 Kafka 内部主题(__consumer_offsets 位移主题)中,位移主题一般由 Kafka 创建。
当Kafka 集群中的第一个 Consumer 程序启动时,Kafka 会自动创建位移主题。
- 参数 offsets.topic.num.partitions 控制了该主题的分区数,默认为 50 。
- 参数 offsets.topic.replication.factor 控制了该主题的副本数,默认为 3 。
7.1 实现原理
可以简单地理解 Offset 是一个 KV 对。Key 和 Value 分别表示消息的键值和消息体。
Key 中保存 3 部分内容:<GroupID,主题名,分区号 >,独立 Consumer(Standalone Consumer)也有自己的 Group ID 来标识,所以也适用于这套消息格式。
7.2 消息格式
在 Kafka 中消息体可分为3类:
- 存储偏移量信息的消息,包含偏移量、时间戳、自定义信息等。
- 保存 Consumer Group 信息的消息,用来注册 Consumer Group。
- tombstone 消息(墓碑消息、delete mark),消息体是 null,空消息体。当某个 Consumer Group 下的所有 Consumer 实例都停止了,而且它们的位移数据都已被删除时,Kafka 会向位移主题的对应分区写入tombstone 消息,表明要彻底删除这个 Group 的信息。
7.3 位移提交
Consumer 需要向 Kafka 汇报自己的位移数据,这个汇报过程被称为提交位移(Committing Offsets)。因为 Consumer 能够同时消费多个分区的数据,所以位移的提交实际上是在分区粒度上进行的,即 Consumer 需要为分配给它的每个分区提交各自的位移数据。
其中提交位移方式又分为:自动提交、手动提交 两种。
1. 自动提交
设置 enable.auto.commit = true, Consumer 在后台定期提交位移,提交周期由参数:auto.commit.interval.ms 控制。
2. 手动提交
设置 enable.auto.commit = false,调用类似 consumer.commitSync、 consumer.commit 等 API 进行提交。
7.4 Log Cleaner
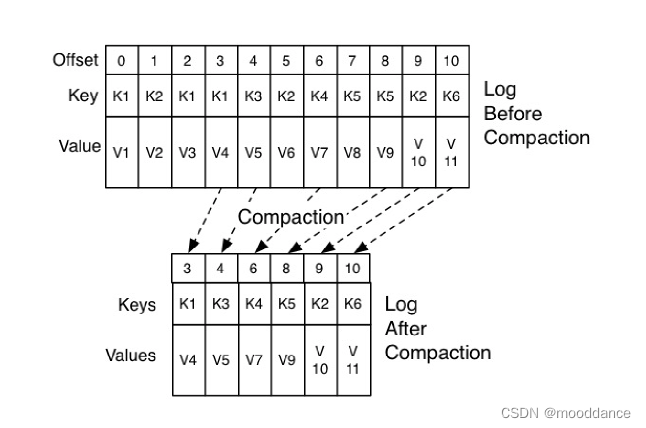
手动提交位移下,尽管没有消息可以消费,只要 Consumer 一直启动着,就会无限期地向位移主题写入消息。理论上这类消息会一直重复下去,但是Kafka 使用Compact 策略来删除位移主题中的过期消息,避免该主题无限期膨胀。
Kafka 提供了专门的**后台线程( Log Cleaner)**定期地巡检待 Compact 的主题,看看是否存在满足条件的可删除数据。
如下图中位移为 0、2 和 3 的消息的 Key 都是 K1。Compact 之后,分区只需要保存位移为 3 消息,因为它是最新发送的。
八 重平衡(Rebalance)
Rebalance 对于 KafKa 来说是一个噩梦,效率非常之不高。所以要尽可能避免 Rebalance 的发生。
Kafka 有一个**协调者(Coordinator)**它专门为 Consumer Group 服务,负责为 Group 执行Rebalance 以及提供位移管理和组成员管理等。

















 2568
2568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











