






LIRS算法概述
全称为Low Interreference Recency Set,是一种页替换算法。相比于LRU和其他的页替换算法,LIRS算法具有更高的性能。
知识点概述
在LIRS算法中,对于每一个缓存数据块,都维护了以下两个变量来衡量数据的访问频率:
- IRR(Inter-Reference Recency): 表示一个数据块在最近的两次访问期间,有多少个不同的数据块被访问过。注:当数据块第一次被访问时,IRR初始化为无穷大;
- R(Recency):数据块最近一次访问到当前时间内有多少个不同的数据块被访问过。
LIRS原理介绍
以序列1 2 3 4 3 1 5 6 5为例
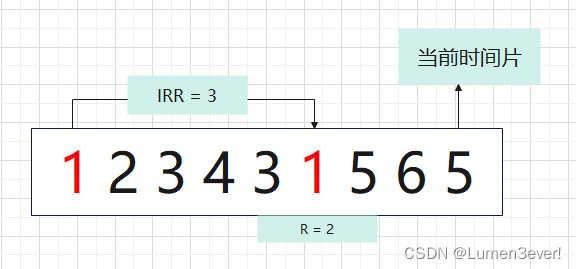
对于数据块1来说,在当前时间片共有两次访问,两次访问期间有2、3、4这三个不同的数据块被访问,所以数据块1的IRR = 3。从数据块1最近一次访问到当前时间片共有5、6两个数据块被访问过,所以数据块1的R = 2。
LIRS算法将所有的数据块分为LIR和HIR两种,算法综合比较IRR和R值来进行淘汰数据块的选择:
LIR(Low IRR) 表示具有较低的IRR值,IRR值越小,说明数据块被访问的频率越高,数据块是热数据块。
HIR(High IRR) 表示具有较高的IRR值,IRR值越高,说明数据块被访问的频率越低,数据块是冷数据块。
热数据块一般会常驻Cache,不会进行数据块淘汰,数据块淘汰只会发生在冷数据块中。
HIR又分为LIR(Low IRR)和nonresident-HIR,其中只有resident-HIR会驻留在Cache中,而nonresident-HIR不会驻留在Cache中,仅通过key值来关联查找数据块。
换言之,Cache中只会有两种数据块,一种是LIR,另一种是resident-HIR。且这两种类型数据块的占比大概是99:1。
Cache数据量 = LIR(占总量的99%)+ resident-HIR(占总量的1%)
当Cache发生未命中时,会优先淘汰resident-HIR中的数据;
当Cache命中resident-HIR,则需要更新命中数据块的IRR值,若IRR值比LIR集合中最大的R值要小,则需要将LIR的数据块变为HIR,同时将命中的这个HIR变为LIR。
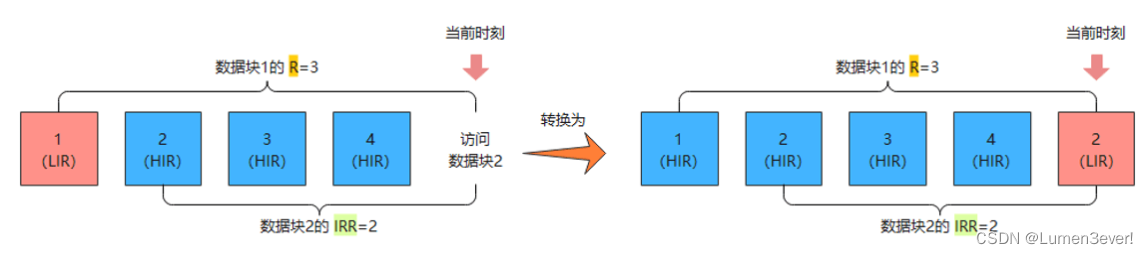 上面所说的数据置换操作,一定是HIR中数据的IRR值要小于LIR集合中最大的R值时,才会进行数据置换操作,而不是LIR集合中的IRR值,主要是基于以下两个原因:
上面所说的数据置换操作,一定是HIR中数据的IRR值要小于LIR集合中最大的R值时,才会进行数据置换操作,而不是LIR集合中的IRR值,主要是基于以下两个原因:
- IRR值其实是基于R值生成的,只是IRR值会落后于R值更新;
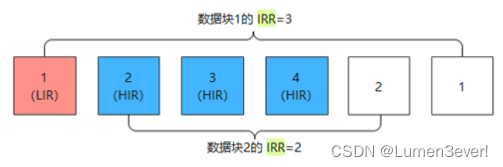
- 基于原因1,如果HIR中的IRR值小于LIR的R值,则HIR中数据块的IRR值肯定会小于LIR数据块的下一个IRR值。如下图所示,数据块1(LIR)在数据块2(HIR)之后访问,那么数据块1的IRR=3大于数据块2的IRR=2。
LIRS的实现
可以使用一个LIRS栈S和一个队列Q(软件实现上都可以使用双链表)来实现LIRS算法,通过以下访问原则,从而无需精确计算IRR值和R值:
-
LIRS栈未满时,新数据统一进入栈S,标记为LIR;
-
栈S中LIR满,但是队列Q未满时,新数据同时进入LIR栈和队列Q,标记为HIR;
-
栈S和Q都满时:
(1)若为新数据访问:- 将队列Q头部的节点淘汰;若被淘汰的节点在栈S中也存在,则将栈S中的节点变为non-resident HIR;
- 新数据同时进入栈S和队列Q,标记为HIR
(2) 若命中栈S中的LIR块(LIR块只存在于栈S):
- 则将该数据块移动到栈S顶部
- 如果原先该LIR块位于栈S底部,那么需要执行一次“栈剪枝”(栈剪枝在文末解释)
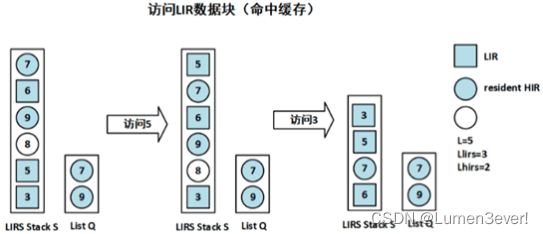
(3) 若命中栈S中的HIR块(HIR块可以仅存在于队列Q,也可同时位于栈S和队列Q):
- 将该数据块状态升级为LIR,同时移动到栈S顶部;若在Q中也存在匹配的节点,则从队列Q中删除;
- 同时将栈S底部的LIR降级为HIR,并移动到队列Q的尾部,然后执行一次“栈剪枝”
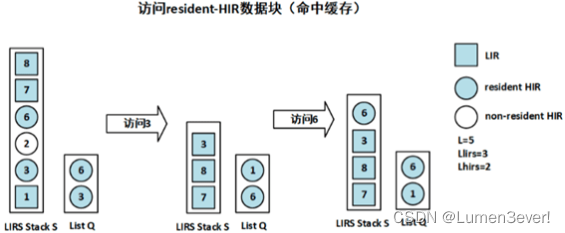
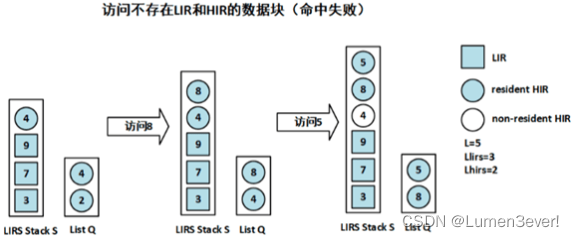
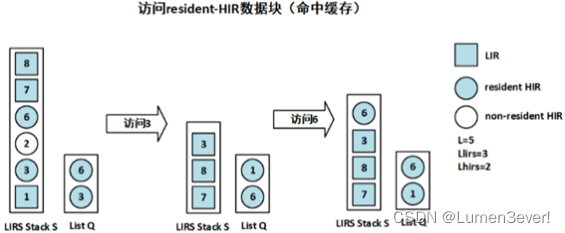
(4)若命中队列Q中的HIR块
- 将该数据块移动到队列Q尾部
- 同时在栈S顶部中也添加一个该数据块,类型为HIR
如下图中的访问6
(5)若访问的数据块为栈S中的non-resident HIR(non-resident HIR仅在栈S中存在)
- 将该数据块升级为LIR,并移动到栈S顶部
- 同时将栈S底部的LIR降级为HIR,并移动到队列Q的尾部,然后执行一次“栈剪枝”
栈剪枝
从栈S底部开始往上删除HIR和NON-HIR块,直到遇到一个LIR块为止。
目的是:
- 保证栈S底部始终为LIR;
- 栈S底部的LIR和倒数第2个LIR块之间的HIR块对应的IRR值肯定会大于倒数第2个LIR块的R值,也就是无法再从HIR状态变为LIR。
注:由于LIRS算法中未对栈S的整体大小做限制,仅对栈S中LIR块的数量做了限制,因此当数据流为持续miss时,会造成栈S中NON-HIR块的数量持续增加,这会造成搜索效率的降低。














 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









