







文章目录
1. 数据库基本概念
1.1 数据库最基本的单位
数据库中最基本的单元是表:table;
姓名 性别 年龄(列 column:字段 field)
张三 男 20 ------>行 row(记录 record)
李四 女 19 ------>行(记录)
王五 男 22 ------>行(记录)
1.2 mysql的数据类型
1、 varchar(255) 可变长度的字符串
优点:节省空间
缺点:需要动态分配空间,速度慢
2、 char(255) 定长字符串
优点:不需要动态分配空间,速度快
缺点:使用不当可能会导致空间的浪费
// varchar 和 char 我们应该怎么选择?
性别字段你选什么?
因为性别是固定长度的字符串,所以选择 char
姓名字段你选什么?
每一个人的名字长度不同,所以选择 varchar
3、 int(11)
数字中的整数型。等同于java的int
4、 bigint
数字中的长整型。等同于java中的long
5、 float
单精度浮点型数据
6、 double
双精度浮点型数据
7、 date :%Y-%m-%d
短日期类型
8、 datetime :%Y-%m-%d %h:%i:%s;
长日期类型
9、 clob
字符大对象
最多可以存储4G的字符串。
比如:存储一篇文章,存储一个说明。
超过255个字符的都要采用CLOB字符大对象来存储。
Character Large OBject:CLOB
10、 blob
二进制大对象
专门用来存储图片、声音、视频等流媒体数据。
往BLOB类型的字段上插入数据的时候,例如插入一个图片、视频等,
你需要使用IO流才行。
Binary Large OBject:blob
2. SQL语句概述
1、DQL:(数据查询语句)
凡是带有select关键字的都是查询语句
select...
2、DML:(数据操作语句)
凡是对表当中的数据进行增删改的都是DML
insert delete update
insert 增
delete 删
update 改
这个主要是操作表中的数据data
3、DDL:(数据定义语句)
凡是带有create、drop、alter都是DDL
create:新建(=增)
drop:删除
alter:修改
这个增删改和DML不同,这个主要是针对表(table)结构进行操作
4、TCL:(事务控制语句)
包括:
事务提交: commit;
事务回滚: rollback;
5、DCL:(数据控制语言)
例如:授权 grant、撤销权限 revoke......
3. MySQL常用命令
3.1 基本用法
3.1.1 启动/停止MySQL服务
net start MySQL
net start MySQL
(要用管理员身份打开cmd)
3.1.2 登录MySQL
mysql -uroot -p
(-h主机名 -P端口号 -u用户名 -p密码)
3.1.3 查看数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| helloworld |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.00 sec)
3.1.4 使用数据库
mysql> use test;
Database changed
3.1.5 创建数据库
mysql> create database javase;
Query OK, 1 row affected (0.00 sec)
3.1.6 查看数据库的表
//前提是已经使用了某数据库
mysql> use test;
Database changed
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| db1 |
+----------------+
1 row in set (0.00 sec)
3.1.7 导入数据演示
//前提是已经使用了某数据库
mysql> use test;
Database changed
//将数据传输到test数据库中
mysql> source E:\bjpowernode.sql
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
......
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| db1 |
| dept | --->部门表
| emp | --->员工表
| salgrade | --->工资等级表
+----------------+
4 rows in set (0.00 sec)
查看表中的数据
//select * from 表名; --->统一执行这个SQL语句
mysql> select * from dept;
+--------+------------+----------+
| DEPTNO | DNAME | LOC |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+ -->部门编号、部门姓名、部门地址
查看表中的结构
//desc 表名;
mysql> desc dept;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| DEPTNO | int(2) | NO | PRI | NULL | |
| DNAME | varchar(14) | YES | | NULL | |
| LOC | varchar(13) | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
-->部门编号、部门姓名、部门地址
//注释:varchar对于java中的String
3.2 不常用命令
3.2.1 检查mysql版本号
mysql> select version();
+------------+
| version() |
+------------+
| 5.6.35-log |
+------------+
1 row in set (0.00 sec)
3.2.2 查看正在使用的数据库
mysql> select database();
+------------+
| database() |
+------------+
| test |
+------------+
1 row in set (0.00 sec)
4. DQL(数据查询语句)
4.1 简单查询
4.1.1 查询某个表中的字段
//查询表中的数据结构
mysql> desc dept;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| DEPTNO | int(2) | NO | PRI | NULL | |
| DNAME | varchar(14) | YES | | NULL | |
| LOC | varchar(13) | YES | | NULL | |
+--------+-------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
//查询某个结构的数据
mysql> select dname from dept;
+------------+
| dname |
+------------+
| ACCOUNTING |
| RESEARCH |
| SALES |
| OPERATIONS |
+------------+
4 rows in set (0.00 sec)
4.1.2 查询多个字段
//逗号隔开
mysql> select dname,loc,deptno from dept;
+------------+----------+--------+
| dname | loc | deptno |
+------------+----------+--------+
| ACCOUNTING | NEW YORK | 10 |
| RESEARCH | DALLAS | 20 |
| SALES | CHICAGO | 30 |
| OPERATIONS | BOSTON | 40 |
+------------+----------+--------+
4 rows in set (0.00 sec)
4.1.3 给查询的列(字段)起别名
//使用as关键字该别名
mysql> select dname as ddname from dept;
+------------+
| ddname |
+------------+
| ACCOUNTING |
| RESEARCH |
| SALES |
| OPERATIONS |
+------------+
4 rows in set (0.01 sec)
//可以省略as关键字
//如果别名中有空格怎么办
mysql> select dname 'hello world' from dept;
+-------------+
| hello world |
+-------------+
| ACCOUNTING |
| RESEARCH |
| SALES |
| OPERATIONS |
+-------------+
4 rows in set (0.00 sec)
//加''或""即可,但''是标准
4.1.4 列参与数学运算
//改英文
mysql> select ename,sal*12 sal from emp;
+--------+----------+
| ename | sal |
+--------+----------+
| SMITH | 9600.00 |
| ALLEN | 19200.00 |
| WARD | 15000.00 |
| JONES | 35700.00 |
+--------+----------+
14 rows in set (0.01 sec)
//改中文
mysql> select ename,sal*12 '年薪' from emp;
+--------+----------+
| ename | 年薪 |
+--------+----------+
| SMITH | 9600.00 |
| ALLEN | 19200.00 |
| WARD | 15000.00 |
| JONES | 35700.00 |
+--------+----------+
14 rows in set (0.00 sec)
4.2 条件查询
4.2.1 查询特定工资
//1、查询特定工资
mysql> select empno ,ename from emp where sal=800;
+-------+-------+
| empno | ename |
+-------+-------+
| 7369 | SMITH |
+-------+-------+
1 row in set (0.01 sec)
4.2.2 查询特定姓名
//2、查询特定姓名
mysql> select empno ,ename from emp where ename = 'CLARK';
+-------+-------+
| empno | ename |
+-------+-------+
| 7782 | CLARK |
+-------+-------+
1 row in set (0.00 sec)
4.2.3 查询工资范围
//3、查询工资范围
mysql> select empno,ename,sal from emp where sal>2500 && sal<5000;
+-------+-------+---------+
| empno | ename | sal |
+-------+-------+---------+
| 7566 | JONES | 2975.00 |
| 7698 | BLAKE | 2850.00 |
| 7788 | SCOTT | 3000.00 |
| 7902 | FORD | 3000.00 |
+-------+-------+---------+
4 rows in set (0.00 sec)
4.2.4 null注意事项
//4、null注意事项
mysql> select empno,ename,sal,comm from emp where comm is null;
+-------+--------+---------+------+
| empno | ename | sal | comm |
+-------+--------+---------+------+
| 7369 | SMITH | 800.00 | NULL |
| 7566 | JONES | 2975.00 | NULL |
| 7698 | BLAKE | 2850.00 | NULL |
| 7782 | CLARK | 2450.00 | NULL |
| 7788 | SCOTT | 3000.00 | NULL |
| 7839 | KING | 5000.00 | NULL |
| 7876 | ADAMS | 1100.00 | NULL |
| 7900 | JAMES | 950.00 | NULL |
| 7902 | FORD | 3000.00 | NULL |
| 7934 | MILLER | 1300.00 | NULL |
+-------+--------+---------+------+
10 rows in set (0.00 sec)
mysql> select empno,ename,sal,comm from emp where comm is not null;
+-------+--------+---------+---------+
| empno | ename | sal | comm |
+-------+--------+---------+---------+
| 7499 | ALLEN | 1600.00 | 300.00 |
| 7521 | WARD | 1250.00 | 500.00 |
| 7654 | MARTIN | 1250.00 | 1400.00 |
| 7844 | TURNER | 1500.00 | 0.00 |
+-------+--------+---------+---------+
4 rows in set (0.00 sec)
4.2.5 and与or的用法
//5、and优先级大于or
mysql> select sal,deptno from emp where sal>2500 and (deptno=10 or deptno=20);
+---------+--------+
| sal | deptno |
+---------+--------+
| 2975.00 | 20 |
| 3000.00 | 20 |
| 5000.00 | 10 |
| 3000.00 | 20 |
+---------+--------+
4 rows in set (0.00 sec) --->deptno为部门编号
4.2.6 in注意事项
//in的用法
mysql> select ename,sal from emp where sal in(800,5000);
+-------+---------+
| ename | sal |
+-------+---------+
| SMITH | 800.00 |
| KING | 5000.00 |
+-------+---------+
2 rows in set (0.00 sec)
//相当于 select ename,sal from emp where sal=800 or sal=5000;
//not in的用法
mysql> select ename,sal from emp where sal not in(800,5000,3000);
+--------+---------+
| ename | sal |
+--------+---------+
| ALLEN | 1600.00 |
| WARD | 1250.00 |
| JONES | 2975.00 |
| MARTIN | 1250.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| TURNER | 1500.00 |
| ADAMS | 1100.00 |
| JAMES | 950.00 |
| MILLER | 1300.00 |
+--------+---------+
10 rows in set (0.00 sec)
4.2.7 like(模糊查询)
// _ 表示匹配一个任意字符
// % 表示匹配多个任意字符
//1、找出名字中有o的?
mysql> select ename from emp where ename like '%o%';
+-------+
| ename |
+-------+
| JONES |
| SCOTT |
| FORD |
+-------+
3 rows in set (0.00 sec)
//2、找出名字结尾有T的?
mysql> select ename from emp where ename like '%T';
+-------+
| ename |
+-------+
| SCOTT |
+-------+
1 row in set (0.00 sec) --->不区分大小写
//3、找出名字开头有C的?
mysql> select ename from emp where ename like 'C%';
+-------+
| ename |
+-------+
| CLARK |
+-------+
1 row in set (0.00 sec)
//4、找出第三个字母是R的?(_)
mysql> select ename from emp where ename like '__R%';
+--------+
| ename |
+--------+
| WARD |
| MARTIN |
| TURNER |
| FORD |
+--------+
4 rows in set (0.00 sec)
//5、找出名字中有_的数据 --->转义用\
mysql> select name from t_student where name like '%\_%';
+---------+
| name |
+---------+
| jack_ma |
+---------+
1 row in set (0.00 sec)
4.3 排序功能
4.3.1 升序与降序
//工资升序
mysql> select ename,job,sal from emp order by sal;(asc)(3)
+--------+-----------+---------+
| ename | job | sal |
+--------+-----------+---------+
| SMITH | CLERK | 800.00 |
| JAMES | CLERK | 950.00 |
| ADAMS | CLERK | 1100.00 |
| WARD | SALESMAN | 1250.00 |
| MARTIN | SALESMAN | 1250.00 |
| MILLER | CLERK | 1300.00 |
| TURNER | SALESMAN | 1500.00 |
| ALLEN | SALESMAN | 1600.00 |
| CLARK | MANAGER | 2450.00 |
| BLAKE | MANAGER | 2850.00 |
| JONES | MANAGER | 2975.00 |
| FORD | ANALYST | 3000.00 |
| SCOTT | ANALYST | 3000.00 |
| KING | PRESIDENT | 5000.00 |
+--------+-----------+---------+
14 rows in set (0.01 sec)
//工资降序
mysql> select ename,job,sal from emp order by sal desc;
+--------+-----------+---------+
| ename | job | sal |
+--------+-----------+---------+
| KING | PRESIDENT | 5000.00 |
| SCOTT | ANALYST | 3000.00 |
| FORD | ANALYST | 3000.00 |
| JONES | MANAGER | 2975.00 |
| BLAKE | MANAGER | 2850.00 |
| CLARK | MANAGER | 2450.00 |
| ALLEN | SALESMAN | 1600.00 |
| TURNER | SALESMAN | 1500.00 |
| MILLER | CLERK | 1300.00 |
| MARTIN | SALESMAN | 1250.00 |
| WARD | SALESMAN | 1250.00 |
| ADAMS | CLERK | 1100.00 |
| JAMES | CLERK | 950.00 |
| SMITH | CLERK | 800.00 |
+--------+-----------+---------+
14 rows in set (0.00 sec)
4.3.2 多个字段排序
//先按薪资排序,再按名字排序
mysql> select ename,sal from emp order by sal,ename;
+--------+---------+
| ename | sal |
+--------+---------+
| SMITH | 800.00 |
| JAMES | 950.00 |
| ADAMS | 1100.00 |
| MARTIN | 1250.00 |
| WARD | 1250.00 |
| MILLER | 1300.00 |
| TURNER | 1500.00 |
| ALLEN | 1600.00 |
| CLARK | 2450.00 |
| BLAKE | 2850.00 |
| JONES | 2975.00 |
| FORD | 3000.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
+--------+---------+
14 rows in set (0.00 sec)
4.3.3 综合案例
//小案例
mysql> select ename,sal,job from emp where sal>=1250 && sal<=3000 order by sal;
+--------+---------+----------+
| ename | sal | job |
+--------+---------+----------+
| WARD | 1250.00 | SALESMAN |
| MARTIN | 1250.00 | SALESMAN |
| MILLER | 1300.00 | CLERK |
| TURNER | 1500.00 | SALESMAN |
| ALLEN | 1600.00 | SALESMAN |
| CLARK | 2450.00 | MANAGER |
| BLAKE | 2850.00 | MANAGER |
| JONES | 2975.00 | MANAGER |
| SCOTT | 3000.00 | ANALYST |
| FORD | 3000.00 | ANALYST |
+--------+---------+----------+
10 rows in set (0.00 sec)
4.4 单行处理函数
4.4.1 lower 转换小写
//1、lower 转换小写
mysql> select lower(ename) ename from emp;
+--------+
| ename |
+--------+
| smith |
| allen |
| ward |
| jones |
| martin |
| blake |
| clark |
| scott |
| king |
| turner |
| adams |
| james |
| ford |
| miller |
+--------+
14 rows in set (0.00 sec)
4.4.2 upper 转换大写
4.4.3 substr 取子串
//3、substr 取子串
mysql> select ename from emp where substr(ename,1,1)='A';
+-------+
| ename |
+-------+
| ALLEN |
| ADAMS |
+-------+
2 rows in set (0.00 sec)
4.4.4 length 取长度
4.4.5 concat 字符串的拼接
//小综合案例:首字母大写
//5、concat 函数进行字符串的拼接
mysql> select concat(upper(substr(name,1,1)),substr(name,2,length(name)-1)) as result from t_student;
+---------+
| result |
+---------+
| Jack_ma |
| 张三 |
+---------+
2 rows in set (0.00 sec)
4.4.6 trim 去空格
//6、trim 去空格
mysql> select ename from emp where ename =trim(' king ');
+-------+
| ename |
+-------+
| KING |
+-------+
1 row in set (0.00 sec)
4.4.7 round 四舍五入
//保留一位小数
mysql> select round(1234.567,1) as result from emp;
+--------+
| result |
+--------+
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
| 1234.6 |
+--------+
14 rows in set (0.00 sec)
//保留到十位
mysql> select round(1234.567,-1) as result from emp;
+--------+
| result |
+--------+
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
| 1230 |
+--------+
14 rows in set (0.00 sec)
4.4.8 rand 生成随机数
//一百以内的随机数
mysql> select round(rand()*100,0) as rand from emp;
+------+
| rand |
+------+
| 8 |
| 36 |
| 58 |
| 80 |
| 29 |
| 2 |
| 22 |
| 5 |
| 59 |
| 79 |
| 17 |
| 50 |
| 99 |
| 47 |
+------+
14 rows in set (0.00 sec)
4.4.9 ifnull 避免null参与运算
//对null进行处理
//问题来源
mysql> select ename,sal,comm from emp;
+--------+---------+---------+
| ename | sal | comm |
+--------+---------+---------+
| SMITH | 800.00 | NULL |
| ALLEN | 1600.00 | 300.00 |
| WARD | 1250.00 | 500.00 |
| JONES | 2975.00 | NULL |
| MARTIN | 1250.00 | 1400.00 |
| BLAKE | 2850.00 | NULL |
| CLARK | 2450.00 | NULL |
| SCOTT | 3000.00 | NULL |
| KING | 5000.00 | NULL |
| TURNER | 1500.00 | 0.00 |
| ADAMS | 1100.00 | NULL |
| JAMES | 950.00 | NULL |
| FORD | 3000.00 | NULL |
| MILLER | 1300.00 | NULL |
+--------+---------+---------+
14 rows in set (0.00 sec)
mysql> select ename,sal+comm sal from emp;
+--------+---------+
| ename | sal |
+--------+---------+
| SMITH | NULL |
| ALLEN | 1900.00 |
| WARD | 1750.00 |
| JONES | NULL |
| MARTIN | 2650.00 |
| BLAKE | NULL |
| CLARK | NULL |
| SCOTT | NULL |
| KING | NULL |
| TURNER | 1500.00 |
| ADAMS | NULL |
| JAMES | NULL |
| FORD | NULL |
| MILLER | NULL |
+--------+---------+
14 rows in set (0.00 sec)
//凡是null了参加运算结果皆为null
//解决:计算每个员工的年薪
mysql> select ename,(sal+ifnull(comm,0))*12 from emp;
+--------+-------------------------+
| ename | (sal+ifnull(comm,0))*12 |
+--------+-------------------------+
| SMITH | 9600.00 |
| ALLEN | 22800.00 |
| WARD | 21000.00 |
| JONES | 35700.00 |
| MARTIN | 31800.00 |
| BLAKE | 34200.00 |
| CLARK | 29400.00 |
| SCOTT | 36000.00 |
| KING | 60000.00 |
| TURNER | 18000.00 |
| ADAMS | 13200.00 |
| JAMES | 11400.00 |
| FORD | 36000.00 |
| MILLER | 15600.00 |
+--------+-------------------------+
14 rows in set (0.00 sec)
4.4.10 case 语法
//case语法模板
case..when..then..when..then..else..end
//需求:当工作岗位是Manager时工资乘于1.1
//老工资和新工资
mysql> select ename,job,sal oldsal,(case job when 'MANAGER' then sal*1.1 else sal end)as newsal from emp;
+--------+-----------+---------+---------+
| ename | job | oldsal | newsal |
+--------+-----------+---------+---------+
| SMITH | CLERK | 800.00 | 800.00 |
| ALLEN | SALESMAN | 1600.00 | 1600.00 |
| WARD | SALESMAN | 1250.00 | 1250.00 |
| JONES | MANAGER | 2975.00 | 3272.50 |
| MARTIN | SALESMAN | 1250.00 | 1250.00 |
| BLAKE | MANAGER | 2850.00 | 3135.00 |
| CLARK | MANAGER | 2450.00 | 2695.00 |
| SCOTT | ANALYST | 3000.00 | 3000.00 |
| KING | PRESIDENT | 5000.00 | 5000.00 |
| TURNER | SALESMAN | 1500.00 | 1500.00 |
| ADAMS | CLERK | 1100.00 | 1100.00 |
| JAMES | CLERK | 950.00 | 950.00 |
| FORD | ANALYST | 3000.00 | 3000.00 |
| MILLER | CLERK | 1300.00 | 1300.00 |
+--------+-----------+---------+---------+
14 rows in set (0.00 sec)
4.4.11 format 格式化数字
mysql> select ename,format(sal,'$999,999') as sal from emp;
+--------+-------+
| ename | sal |
+--------+-------+
| SMITH | 800 |
| ALLEN | 1,600 |
| WARD | 1,250 |
| JONES | 2,975 |
| MARTIN | 1,250 |
| BLAKE | 2,850 |
| CLARK | 2,450 |
| SCOTT | 3,000 |
| KING | 5,000 |
| TURNER | 1,500 |
| ADAMS | 1,100 |
| JAMES | 950 |
| FORD | 3,000 |
| MILLER | 1,300 |
+--------+-------+
4.5 分组函数
【多行处理函数】
4.5.1 单行处理函数与多行处理函数
//单行处理函数
mysql> select ename,sal*12 from emp;
+--------+----------+
| ename | sal*12 |
+--------+----------+
| SMITH | 9600.00 |
| ALLEN | 19200.00 |
| WARD | 15000.00 |
| JONES | 35700.00 |
| MARTIN | 15000.00 |
| BLAKE | 34200.00 |
| CLARK | 29400.00 |
| SCOTT | 36000.00 |
| KING | 60000.00 |
| TURNER | 18000.00 |
| ADAMS | 13200.00 |
| JAMES | 11400.00 |
| FORD | 36000.00 |
| MILLER | 15600.00 |
+--------+----------+
14 rows in set (0.00 sec)
//多行处理函数
mysql> select sum(sal) from emp;
+----------+
| sum(sal) |
+----------+
| 29025.00 |
+----------+
1 row in set (0.01 sec)
4.5.2 常用的分组函数
1、 min 最小值
2、 max 最大值
3、 sum 和
4、 avg 平均值
5、 count 个数
4.5.3 分组函数需要注意什么?
//1、分组函数自动忽略null
mysql> select sum(comm) from emp;
+-----------+
| sum(comm) |
+-----------+
| 2200.00 |
+-----------+
1 row in set (0.00 sec)
//2、分组函数中count(*)与count(字段)的区别
mysql> select count(*) from emp;
+----------+
| count(*) |
+----------+
| 14 |
+----------+
1 row in set (0.00 sec)
mysql> select count(comm) from emp;
+-------------+
| count(comm) |
+-------------+
| 4 |
+-------------+
1 row in set (0.00 sec)
//3、分组函数不能直接使用在where子句上
mysql> select ename,sal from emp where sal>min(sal);
ERROR 1111 (HY000): Invalid use of group function
//4、所有的分组函数可以组合起来使用
mysql> select sum(ename),sum(sal),avg(comm),count(ename) from emp;
+------------+----------+------------+--------------+
| sum(ename) | sum(sal) | avg(comm) | count(ename) |
+------------+----------+------------+--------------+
| 0 | 29025.00 | 550.000000 | 14 |
+------------+----------+------------+--------------+
1 row in set, 14 warnings (0.00 sec)
4.6 分组查询
4.6.1 分组查询的模板
//1、模板:
group by
//2、将前面的关键字全部组合起来
select...from...where...group by...having...order by
//3、执行顺序(优先级)
1、from
2、where
3、group by
4、having
5、select
6、order by
4.6.2 分组查询的用法
//1、按照工作岗位分组,对工资进行求和
mysql> select job,sum(sal) from emp group by job;
+-----------+----------+
| job | sum(sal) |
+-----------+----------+
| ANALYST | 6000.00 |
| CLERK | 4150.00 |
| MANAGER | 8275.00 |
| PRESIDENT | 5000.00 |
| SALESMAN | 5600.00 |
+-----------+----------+
5 rows in set (0.01 sec)
mysql> select job,sum(sal) from emp;
+-------+----------+
| job | sum(sal) |
+-------+----------+
| CLERK | 29025.00 |
+-------+----------+
1 row in set (0.00 sec)
//2、 查询最高工资(先部门排序,再工作排序)
mysql> select deptno,job,max(sal) from emp group by deptno,job;
+--------+-----------+----------+
| deptno | job | max(sal) |
+--------+-----------+----------+
| 10 | CLERK | 1300.00 |
| 10 | MANAGER | 2450.00 |
| 10 | PRESIDENT | 5000.00 |
| 20 | ANALYST | 3000.00 |
| 20 | CLERK | 1100.00 |
| 20 | MANAGER | 2975.00 |
| 30 | CLERK | 950.00 |
| 30 | MANAGER | 2850.00 |
| 30 | SALESMAN | 1600.00 |
+--------+-----------+----------+
9 rows in set (0.00 sec)
//
补充:having的使用
//1、 having 对于 group by 分完组的数据进行处理
mysql> select deptno,max(sal) from emp group by deptno having max(sal)>3000;
+--------+----------+
| deptno | max(sal) |
+--------+----------+
| 10 | 5000.00 |
+--------+----------+
1 row in set (0.00 sec)
//但是效率低下
//2、 改进,优先使用 where
mysql> select deptno,max(sal) from emp where sal>3000 group by deptno;
+--------+----------+
| deptno | max(sal) |
+--------+----------+
| 10 | 5000.00 |
+--------+----------+
1 row in set (0.00 sec)
//3、 只能使用 having 的情况
mysql> select deptno,avg(sal) from emp group by deptno having avg(sal)>2500;
+--------+-------------+
| deptno | avg(sal) |
+--------+-------------+
| 10 | 2916.666667 |
+--------+-------------+
1 row in set (0.00 sec)
4.6.3 分组查询案例
//找出每个岗位的平均工资,要求显示平均工资大于1500的,除manager岗位以外,要求按照平均工资降序排
mysql> select job,avg(sal) from emp where job!='manager' group by job having avg(sal)>1500 order by avg(sal) desc;
+-----------+-------------+
| job | avg(sal) |
+-----------+-------------+
| PRESIDENT | 5000.000000 |
| ANALYST | 3000.000000 |
+-----------+-------------+
2 rows in set (0.00 sec)
4.6.4 去除重复记录
// 关键字 distinct + 字段
mysql> select distinct job from emp;
+-----------+
| job |
+-----------+
| CLERK |
| SALESMAN |
| MANAGER |
| ANALYST |
| PRESIDENT |
+-----------+
5 rows in set (0.00 sec)
//联合去除重复记录
mysql> select distinct job,deptno from emp;
+-----------+--------+
| job | deptno |
+-----------+--------+
| CLERK | 20 |
| SALESMAN | 30 |
| MANAGER | 20 |
| MANAGER | 30 |
| MANAGER | 10 |
| ANALYST | 20 |
| PRESIDENT | 10 |
| CLERK | 30 |
| CLERK | 10 |
+-----------+--------+
9 rows in set (0.00 sec)
//统计一下工作岗位的数量
mysql> select count(distinct job) from emp;
+---------------------+
| count(distinct job) |
+---------------------+
| 5 |
+---------------------+
1 row in set (0.01 sec)
4.7 连接查询
4.7.1 连接查询的概念
//某数据库(DB)中多个表之间联合起来查询数据
例:emp中取员工(ename)名字,dept表中取部门(dname)名字
4.7.2 两张表连接问题
//笛卡尔积现象
mysql> select ename,dname from emp,dept;
+--------+------------+
| ename | dname |
+--------+------------+
| SMITH | ACCOUNTING |
| SMITH | RESEARCH |
| SMITH | SALES |
| SMITH | OPERATIONS |
| ALLEN | ACCOUNTING |
| ALLEN | RESEARCH |
| ALLEN | SALES |
| ALLEN | OPERATIONS |
...
56 rows in set (0.00 sec)
//没有条件限制会发生笛卡尔积现象
//解决方案:
连接时加条件
mysql> select ename,dname from emp,dept where emp.deptno=dept.deptno;
+--------+------------+
| ename | dname |
+--------+------------+
| CLARK | ACCOUNTING |
| KING | ACCOUNTING |
| MILLER | ACCOUNTING |
| SMITH | RESEARCH |
| JONES | RESEARCH |
| SCOTT | RESEARCH |
| ADAMS | RESEARCH |
| FORD | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| MARTIN | SALES |
| BLAKE | SALES |
| TURNER | SALES |
| JAMES | SALES |
+--------+------------+
14 rows in set (0.00 sec)
//匹配次数没有减少,执行效率低
改进方案
//【内连接之等值连接】
//SQL92语法
mysql> select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno;
4.7.3 内连接
1、等值连接
//SQL99语法
mysql> select e.ename,d.dname from emp e join dept d on e.deptno=d.deptno;
+--------+------------+
| ename | dname |
+--------+------------+
| CLARK | ACCOUNTING |
| KING | ACCOUNTING |
| MILLER | ACCOUNTING |
| SMITH | RESEARCH |
| JONES | RESEARCH |
| SCOTT | RESEARCH |
| ADAMS | RESEARCH |
| FORD | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| MARTIN | SALES |
| BLAKE | SALES |
| TURNER | SALES |
| JAMES | SALES |
+--------+------------+
14 rows in set (0.00 sec)
//不占用where,表连接的条件是独立的
2、非等值连接
//salgrade 工资等级表
mysql> select * from salgrade;
+-------+-------+-------+
| GRADE | LOSAL | HISAL |
+-------+-------+-------+
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
+-------+-------+-------+
5 rows in set (0.00 sec)
//查询员工薪资等级
mysql> select e.ename,e.sal,s.grade from emp e join salgrade s on e.sal between s.losal and s.hisal;
+--------+---------+-------+
| ename | sal | grade |
+--------+---------+-------+
| SMITH | 800.00 | 1 |
| ALLEN | 1600.00 | 3 |
| WARD | 1250.00 | 2 |
| JONES | 2975.00 | 4 |
| MARTIN | 1250.00 | 2 |
| BLAKE | 2850.00 | 4 |
| CLARK | 2450.00 | 4 |
| SCOTT | 3000.00 | 4 |
| KING | 5000.00 | 5 |
| TURNER | 1500.00 | 3 |
| ADAMS | 1100.00 | 1 |
| JAMES | 950.00 | 1 |
| FORD | 3000.00 | 4 |
| MILLER | 1300.00 | 2 |
+--------+---------+-------+
14 rows in set (0.00 sec)
3、自连接
//案例:查询员工的上级领导,显示员工、上级的名字
mysql> select empno,ename,mgr from emp;
+-------+--------+------+
| empno | ename | mgr |
+-------+--------+------+
| 7369 | SMITH | 7902 |
| 7499 | ALLEN | 7698 |
| 7521 | WARD | 7698 |
| 7566 | JONES | 7839 |
| 7654 | MARTIN | 7698 |
| 7698 | BLAKE | 7839 |
| 7782 | CLARK | 7839 |
| 7788 | SCOTT | 7566 |
| 7839 | KING | NULL |
| 7844 | TURNER | 7698 |
| 7876 | ADAMS | 7788 |
| 7900 | JAMES | 7698 |
| 7902 | FORD | 7566 |
| 7934 | MILLER | 7782 |
+-------+--------+------+
14 rows in set (0.00 sec)
//技巧:一张表看成两张表
mysql> select a.ename '打工仔',b.ename '老板' from emp a join emp b on a.mgr=b.empno;
+--------+-------+
| 打工仔 | 老板 |
+--------+-------+
| SMITH | FORD |
| ALLEN | BLAKE |
| WARD | BLAKE |
| JONES | KING |
| MARTIN | BLAKE |
| BLAKE | KING |
| CLARK | KING |
| SCOTT | JONES |
| TURNER | BLAKE |
| ADAMS | SCOTT |
| JAMES | BLAKE |
| FORD | JONES |
| MILLER | CLARK |
+--------+-------+
13 rows in set (0.00 sec)
4.7.4 外连接
1、外连接与内连接区别
//内连接
mysql> select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno;
+--------+------------+
| ename | dname |
+--------+------------+
| CLARK | ACCOUNTING |
| KING | ACCOUNTING |
| MILLER | ACCOUNTING |
| SMITH | RESEARCH |
| JONES | RESEARCH |
| SCOTT | RESEARCH |
| ADAMS | RESEARCH |
| FORD | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| MARTIN | SALES |
| BLAKE | SALES |
| TURNER | SALES |
| JAMES | SALES |
+--------+------------+
14 rows in set (0.00 sec)
//外连接
mysql> select e.ename,d.dname from emp e right join dept d on e.deptno = d.deptno;(或 left)
+--------+------------+
| ename | dname |
+--------+------------+
| SMITH | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| JONES | RESEARCH |
| MARTIN | SALES |
| BLAKE | SALES |
| CLARK | ACCOUNTING |
| SCOTT | RESEARCH |
| KING | ACCOUNTING |
| TURNER | SALES |
| ADAMS | RESEARCH |
| JAMES | SALES |
| FORD | RESEARCH |
| MILLER | ACCOUNTING |
| NULL | OPERATIONS | --->以dept为主表
+--------+------------+
15 rows in set (0.00 sec)
//内连接(A、B平等,取交集)
//外连接(A、B有主次关系)
2、外连接案例
//查询每个员工的上级领导,要求显示所有员工的名字和领导名
mysql> select e.ename,d.ename from emp e left join emp d on e.mgr=d.empno;
+--------+-------+
| ename | ename |
+--------+-------+
| SMITH | FORD |
| ALLEN | BLAKE |
| WARD | BLAKE |
| JONES | KING |
| MARTIN | BLAKE |
| BLAKE | KING |
| CLARK | KING |
| SCOTT | JONES |
| KING | NULL |
| TURNER | BLAKE |
| ADAMS | SCOTT |
| JAMES | BLAKE |
| FORD | JONES |
| MILLER | CLARK |
+--------+-------+
14 rows in set (0.00 sec)
4.7.5 多表联查
1、模板
select...from A表
join B表 on A与B的连接关系
join C表 on A与C的连接关系
Join D表 left on A与D的连接关系(A为主表)
2、案例
//三张表连接
//案例:找出员工名,部门名,薪资水平(三个表中的数据)
mysql> select e.ename,d.dname,s.grade from emp e left join dept d on e.deptno=d.deptno join salgrade s on e.sal between s.losal and s.hisal order by s.grade desc;
+--------+------------+-------+
| ename | dname | grade |
+--------+------------+-------+
| KING | ACCOUNTING | 5 |
| FORD | RESEARCH | 4 |
| CLARK | ACCOUNTING | 4 |
| JONES | RESEARCH | 4 |
| SCOTT | RESEARCH | 4 |
| BLAKE | SALES | 4 |
| TURNER | SALES | 3 |
| ALLEN | SALES | 3 |
| MILLER | ACCOUNTING | 2 |
| MARTIN | SALES | 2 |
| WARD | SALES | 2 |
| SMITH | RESEARCH | 1 |
| ADAMS | RESEARCH | 1 |
| JAMES | SALES | 1 |
+--------+------------+-------+
14 rows in set (0.00 sec)
//一条SQL中可以内连接和外连接
4.8 子查询
4.8.1 概念与模板
//什么是子查询?
//select语句中嵌套select语句,被嵌套的select语句称为子查询
//模板
select
..(select).
from
..(select).
where
..(select).
4.8.2 where语句中的子查询
//案例:查询比最低工资高的员工姓名和工资?
mysql> select ename,sal from emp where sal > (select min(sal) from emp);
+--------+---------+
| ename | sal |
+--------+---------+
| ALLEN | 1600.00 |
| WARD | 1250.00 |
| JONES | 2975.00 |
| MARTIN | 1250.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| TURNER | 1500.00 |
| ADAMS | 1100.00 |
| JAMES | 950.00 |
| FORD | 3000.00 |
| MILLER | 1300.00 |
+--------+---------+
13 rows in set (0.01 sec)
4.8.3 from语句中的子查询
//案例:找出每个岗位的平均薪资的薪资等级
mysql> select e.avgsal,s.grade from (select ename,job,avg(sal) avgsal from emp group by job) e join salgrade s on e.avgsal between s.losal and s.hisal order by s.grade;
+-------------+-------+
| avgsal | grade |
+-------------+-------+
| 1037.500000 | 1 |
| 1400.000000 | 2 |
| 3000.000000 | 4 |
| 2758.333333 | 4 |
| 5000.000000 | 5 |
+-------------+-------+
5 rows in set (0.00 sec)
4.8.4 select语句中的子查询
//【了解即可】
mysql> select e.ename,(select d.dname from dept d where e.deptno=d.deptno) dname from emp e;
+--------+------------+
| ename | dname |
+--------+------------+
| SMITH | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| JONES | RESEARCH |
| MARTIN | SALES |
| BLAKE | SALES |
| CLARK | ACCOUNTING |
| SCOTT | RESEARCH |
| KING | ACCOUNTING |
| TURNER | SALES |
| ADAMS | RESEARCH |
| JAMES | SALES |
| FORD | RESEARCH |
| MILLER | ACCOUNTING |
+--------+------------+
14 rows in set (0.00 sec)
4.9 关键字
4.9.1 union
//union连接
mysql> select ename,job from emp where job='manager'
-> union
-> select ename,job from emp where job='salesman';
+--------+----------+
| ename | job |
+--------+----------+
| JONES | MANAGER |
| BLAKE | MANAGER |
| CLARK | MANAGER |
| ALLEN | SALESMAN |
| WARD | SALESMAN |
| MARTIN | SALESMAN |
| TURNER | SALESMAN |
+--------+----------+
7 rows in set (0.01 sec)
//union优点:把乘法变成了加法运算
4.9.2 limit
//1、将查询结果取出一部分
mysql> select ename,sal from emp order by sal desc limit 0,5;
+-------+---------+
| ename | sal |
+-------+---------+
| KING | 5000.00 |
| FORD | 3000.00 |
| SCOTT | 3000.00 |
| JONES | 2975.00 |
| BLAKE | 2850.00 |
+-------+---------+
5 rows in set (0.00 sec)
//注意:limit 在 order by后执行
//2、取工资排名在[3,5]的员工
mysql> select ename,sal from emp order by sal desc limit 2,3;
+-------+---------+
| ename | sal |
+-------+---------+
| SCOTT | 3000.00 |
| JONES | 2975.00 |
| BLAKE | 2850.00 |
+-------+---------+
3 rows in set (0.00 sec)
//3、分页效果
//需求:每页显示三条记录
第一页: limit 0,3;
第二页: limit 3,3;
第三页: limit 6,3;
//每页的数据有i条,第x页公式为:limit (x-1)*i,i;
4.10 小总结
//1、DQL语句
select
...
from
...
where
...
group by
...
having
...
order by
...
limit
...
//2、执行顺序
from...where...group by...having...select...order by...limit
5. DML(数据操作语句)
5.1 insert 增加数据
5.1.1 insert 插入数据
//模板:
insert into tablename() values();
//加入第一条数据
mysql> insert into t_student(no,name,sex,age,email) values(1,'zhangsan','m','20','zhangsan@123.com');
Query OK, 1 row affected (0.01 sec)
//加入第二条数据
mysql> insert into t_student(name,sex,no) values('lisi','n',2);
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_student;
+------+----------+------+------+------------------+
| no | name | sex | age | email |
+------+----------+------+------+------------------+
| 1 | zhangsan | m | 20 | zhangsan@123.com |
| 2 | lisi | n | NULL | NULL |
+------+----------+------+------+------------------+
2 rows in set (0.00 sec)
//可以省略字段名
mysql> insert into t_student values(3,'wangwu','n',18,'wangwu@123.com');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_student;
+------+----------+------+------+------------------+
| no | name | sex | age | email |
+------+----------+------+------+------------------+
| 1 | zhangsan | m | 20 | zhangsan@123.com |
| 2 | lisi | n | NULL | NULL |
| 3 | wangwu | n | 18 | wangwu@123.com |
+------+----------+------+------+------------------+
3 rows in set (0.00 sec)
5.1.2 insert 插入日期
//1、mysql的日期格式:
%Y 年 --->注意:大写!!!
%m 月
%d 日
%h 时
%i 分
%s 秒
//2、创建生日表
mysql> create table t_user(
-> id int,
-> name varchar(32),
-> birth date
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> desc t_user;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(32) | YES | | NULL | |
| birth | date | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
//3、运用 str_to_date 函数
mysql> insert into t_user(id,name,birth) values(1, 'zhangsan', str_to_date('01-10-1990','%d-%m-%Y'));
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_user;
+------+----------+------------+
| id | name | birth |
+------+----------+------------+
| 1 | zhangsan | 1990-10-01 |
+------+----------+------------+
1 row in set (0.00 sec)
//但是:如果你提供的日期字符串是这个格式,str_to_date函数就不需要了!!!
insert into t_user(id,name,birth) values(2, 'lisi', '1990-10-01');
//4、data_format 日期格式化
mysql> select id,name,date_format(birth, '%m/%d/%Y') as birth from t_user;
+------+----------+------------+
| id | name | birth |
+------+----------+------------+
| 1 | zhangsan | 10/01/1990 |
| 1 | zhangsan | 10/15/2020 |
+------+----------+------------+
2 rows in set (0.00 sec)
//5、now() 函数
mysql> insert into t_user(id,name,birth,create_time) values(2,'lisi','1991-10-01',now());
Query OK, 1 row affected (0.02 sec)
mysql> select * from t_user;
+------+------+------------+---------------------+
| id | name | birth | create_time |
+------+------+------------+---------------------+
| 2 | lisi | 1991-10-01 | 2021-10-27 22:30:17 |
+------+------+------------+---------------------+
1 row in set (0.00 sec)
//获取的时间带有:时分秒信息!!!!是datetime类型的
5.1.3 insert 插入多条记录
//案例:
mysql> insert into t_user(id,name,birth,create_time) values
(1,'zhangsan','1200-12-12',now()),
(1,'zhangsan','1200-12-12',now()),
(1,'zhangsan','1200-12-12',now());
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t_user;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 2 | zhangsan | 2020-10-10 | 2021-10-27 22:36:24 |
| 1 | zhangsan | 1200-12-12 | 2021-10-28 10:25:48 |
| 1 | zhangsan | 1200-12-12 | 2021-10-28 10:25:48 |
| 1 | zhangsan | 1200-12-12 | 2021-10-28 10:25:48 |
+------+----------+------------+---------------------+
4 rows in set (0.00 sec)
5.2 delete 删除数据
5.2.1 delete 用法
//模板:
delete from 表名 where 条件;
//案例:
//原先表中数据
mysql> select id,name,birth,create_time from t_user order by id;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 1 | lisi | NULL | NULL |
| 2 | zhangsan | 2020-10-10 | 2021-10-27 22:36:24 |
+------+----------+------------+---------------------+
2 rows in set (0.00 sec)
//修改后数据
mysql> delete from t_user where id=1;
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_user;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 2 | zhangsan | 2020-10-10 | 2021-10-27 22:36:24 |
+------+----------+------------+---------------------+
1 row in set (0.00 sec)
//注意:没有条件,整张表的数据会全部删除!
5.2.2 delete与truncate
delete语句删除数据的原理?(delete属于DML语句!!!)
表中的数据被删除了,但是这个数据在硬盘上的真实存储空间不会被释放!!!
这种删除缺点是:删除效率比较低。
这种删除优点是:支持回滚,后悔了可以再恢复数据!!!
truncate语句删除数据的原理?(truncate属于DDL语句!)
这种删除效率比较高,表被一次截断,物理删除。
这种删除缺点:不支持回滚。
这种删除优点:快速。
用法:truncate table dept_bak;
// delete 和 truncate是删除表中的数据,表还在!
5.3 update 修改数据
//模板:
update 表名 set 字段名1=值1,字段名2=值2,字段名3=值3... where 条件;
//案例:
//原先表中数据
mysql> select * from t_user;
+------+------+------------+---------------------+
| id | name | birth | create_time |
+------+------+------------+---------------------+
| 2 | lisi | 1991-10-01 | 2021-10-27 22:30:17 |
+------+------+------------+---------------------+
1 row in set (0.00 sec)
//修改后数据
mysql> update t_user set name='zhangsan',birth='2020-10-10',create_time=now() where id=2;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t_user;
+------+----------+------------+---------------------+
| id | name | birth | create_time |
+------+----------+------------+---------------------+
| 2 | zhangsan | 2020-10-10 | 2021-10-27 22:36:24 |
+------+----------+------------+---------------------+
1 row in set (0.00 sec)
//注意:没有条件限制会导致所有数据全部更新
5.4 transaction 事务
5.4.1 概念&特性
//1、概述
一个事务其实就是一个完整的业务逻辑。
是一个最小的工作单元。不可再分。
什么是一个完整的业务逻辑?
假设转账,从A账户向B账户中转账10000.
将A账户的钱减去10000(update语句)
将B账户的钱加上10000(update语句)
这就是一个完整的业务逻辑。
以上的操作是一个最小的工作单元,要么同时成功,要么同时失败,不可再分。
这两个update语句要求必须同时成功或者同时失败,这样才能保证钱是正确的。
//2、本质
说到底,说到本质上,一个事务其实就是多条DML语句同时成功,或者同时失败!
//3、注意:只有DML语句才会有事务这一说,其它语句和事务无关!!!
//事务包括4个特性:
A:原子性(Atomicity)
说明事务是最小的工作单元。不可再分。
C:一致性(Consis)
所有事务要求,在同一个事务当中,所有操作必须同时成功,或者同时失败,以保证数据的一致性。
I:隔离性(Isolation) ***
A事务和B事务之间具有一定的隔离。
教室A和教室B之间有一道墙,这道墙就是隔离性。
A事务在操作一张表的时候,另一个事务B也操作这张表会怎样???
D:持久性(Durability)
事务最终结束的一个保障。事务提交,就相当于将没有保存到硬盘上的数据保存到硬盘上!
5.4.2 事务的工作原理
//1、事务是怎么做到多条DML语句同时成功和同时失败的呢?
InnoDB存储引擎:提供一组用来记录事务性活动的日志文件
事务开启了:
insert
insert
insert
delete
update
update
update
事务结束了!
在事务的执行过程中,每一条DML的操作都会记录到“事务性活动的日志文件”中。
在事务的执行过程中,我们可以提交事务,也可以回滚事务。
1-1、提交事务?
清空事务性活动的日志文件,将数据全部彻底持久化到数据库表中。
提交事务标志着,事务的结束。并且是一种全部成功的结束。
1-2、回滚事务?
将之前所有的DML操作全部撤销,并且清空事务性活动的日志文件
回滚事务标志着,事务的结束。并且是一种全部失败的结束。
5.4.3 事务的使用方法
1、补充
//1、补充
提交事务:commit; 语句
回滚事务:rollback; 语句
(回滚永远都是只能回滚到上一次的提交点!)
mysql默认情况下是支持自动提交事务的。
每执行一条DML语句,则提交一次!
2、开启回滚事务
mysql> use bjpowernode;
Database changed
mysql> select * from dept_bak;
Empty set (0.00 sec)
mysql> start transaction; --->开启事务
Query OK, 0 rows affected (0.00 sec)
mysql> insert into dept_bak values(10,'abc', 'tj');
Query OK, 1 row affected (0.00 sec)
mysql> insert into dept_bak values(10,'abc', 'tj');
Query OK, 1 row affected (0.00 sec)
mysql> select * from dept_bak;
+--------+-------+------+
| DEPTNO | DNAME | LOC |
+--------+-------+------+
| 10 | abc | tj |
| 10 | abc | tj |
+--------+-------+------+
2 rows in set (0.00 sec)
mysql> rollback; --->开启回滚
Query OK, 0 rows affected (0.00 sec)
mysql> select * from dept_bak;
Empty set (0.00 sec)
3、开启提交事务
mysql> use bjpowernode;
Database changed
mysql> select * from dept_bak;
+--------+-------+------+
| DEPTNO | DNAME | LOC |
+--------+-------+------+
| 10 | abc | bj |
+--------+-------+------+
1 row in set (0.00 sec)
mysql> start transaction; --->开启事务
Query OK, 0 rows affected (0.00 sec)
mysql> insert into dept_bak values(20,'abc')
Query OK, 1 row affected (0.00 sec)
mysql> insert into dept_bak values(20,'abc')
Query OK, 1 row affected (0.00 sec)
mysql> insert into dept_bak values(20,'abc')
Query OK, 1 row affected (0.00 sec)
mysql> commit; --->提交事务
Query OK, 0 rows affected (0.01 sec)
mysql> select * from dept_bak;
+--------+-------+------+
| DEPTNO | DNAME | LOC |
+--------+-------+------+
| 10 | abc | bj |
| 20 | abc | tj |
| 20 | abc | tj |
| 20 | abc | tj |
+--------+-------+------+
4 rows in set (0.00 sec)
mysql> rollback; --->开启回滚
Query OK, 0 rows affected (0.00 sec)
mysql> select * from dept_bak;
+--------+-------+------+
| DEPTNO | DNAME | LOC |
+--------+-------+------+
| 10 | abc | bj |
| 20 | abc | tj |
| 20 | abc | tj |
| 20 | abc | tj |
+--------+-------+------+
4 rows in set (0.00 sec)
//已将事务提交,只能返回到上一个提交点
//跟游戏中的存档点一样!!!
5.4.4 事务的隔离级别种类
//1、形容
A教室和B教室中间有一道墙,这道墙可以很厚,也可以很薄。这就是事务的隔离级别。这道墙越厚,表示隔离级别就越高。
//2、4个级别
//2-1、读未提交
read uncommitted(最低的隔离级别)《没有提交就读到了》
什么是读未提交?
事务A可以读取到事务B未提交的数据。
这种隔离级别存在的问题就是:
脏读现象!(Dirty Read)
我们称读到了脏数据。
这种隔离级别一般都是理论上的,大多数的数据库隔离级别都是二档起步!
//2-2、读已提交
read committed《提交之后才能读到》
什么是读已提交?
事务A只能读取到事务B提交之后的数据。
这种隔离级别解决了什么问题?
解决了脏读的现象。
这种隔离级别存在什么问题?
不可重复读取数据。
什么是不可重复读取数据呢?
在事务开启之后,第一次读到的数据是3条,当前事务还没有结束,可能第二次再读取的时候,读到的数据是4条,3不等于4,称为不可重复读取。
这种隔离级别是比较真实的数据,每一次读到的数据是绝对的真实。
oracle数据库默认的隔离级别是:read committed
//2-3、可重复读
repeatable read《提交之后也读不到,永远读取的都是刚开启事务时的数据》
什么是可重复读取?
事务A开启之后,不管是多久,每一次在事务A中读取到的数据都是一致的。即使事务B将数据已经修改,并且提交了,事务A读取到的数据还是没有发生改变,这就是可重复读。
可重复读解决了什么问题?
解决了不可重复读取数据。
可重复读存在的问题是什么?
可以会出现幻影读。
每一次读取到的数据都是幻象。不够真实!
早晨9点开始开启了事务,只要事务不结束,到晚上9点,读到的数据还是那样!读到的是假象。不够绝对的真实。
mysql中默认的事务隔离级别就是这个!!!!!!!!!!!
//2-4、序列化/串行化
serializable(最高的隔离级别)
这是最高隔离级别,效率最低。解决了所有的问题。
这种隔离级别表示事务排队,不能并发!
synchronized,线程同步(事务同步)
每一次读取到的数据都是最真实的,并且效率是最低的。
5.4.5 事务隔离级别演示(*)
1、验证各种隔离级别
查看隔离级别:
SELECT @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ | --->可重复读
+-----------------+
mysql默认的隔离级别
2、read uncommited(读未提交)
//验证:read uncommited(读未提交)
被测试的表t_user
mysql> set global transaction isolation level read uncommitted;
事务A 事务B
--------------------------------------
use bjpowernode;
use bjpowernode;
start transaction;
select * from t_user;
start transaction;
insert into t_user values('zhangsan');
select * from t_user;
3、read committed(读已提交)
//验证:read commited(读已提交)
被测试的表t_user
mysql> set global transaction isolation level read committed;
事务A 事务B
--------------------------------------
use bjpowernode;
use bjpowernode;
start transaction;
start transaction;
select * from t_user;
insert into t_user values('zhangsan');
select * from t_user;
commit;
select * from t_user;
4、repeatable read(可重复读)
//验证:read uncommited(读未提交)
被测试的表t_user
mysql> set global transaction isolation level repeatable read;
事务A 事务B
--------------------------------------
use bjpowernode;
use bjpowernode;
start transaction;
start transaction;
select * from t_user;
insert into t_user values('lisi');
insert into t_user values('wangwu');
commit;
select * from t_user;
5、serializable(序列化)
//验证:read uncommited(读未提交)
被测试的表t_user
mysql> set global transaction isolation level serializable;
事务A 事务B
--------------------------------------
use bjpowernode;
use bjpowernode;
start transaction;
start transaction;
select * from t_user;
insert into t_user values('abc');
select * from t_user;
6. DDL(数据定义语句)
6.1 create 创建表
6.1.1 创建表的格式
//1、模板
create table 表名(
字段名1 数据类型,
字段名2 数据类型,
字段名3 数据类型
);
//2、普通创建表 table 的方法
mysql> create table t_student(
-> no int,
-> name varchar(32),
-> sex char(1),
-> age int(3),
-> email varchar(255)
-> );
Query OK, 0 rows affected (0.01 sec)
//3、指定默认值
mysql> create table t_student(
-> no int,
-> name varchar(32),
-> sex char(1) default 'm', ---> 指定默认值
-> age int(3),
-> email varchar(255)
-> );
Query OK, 0 rows affected (0.01 sec)
6.1.2 快速复印表
//复制全表
mysql> create table emp2 as select * from emp;
Query OK, 14 rows affected (0.02 sec)
//复制部分字段
mysql> create table emp3 as select empno,ename from emp where job = 'manager';
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from emp3;
+-------+-------+
| empno | ename |
+-------+-------+
| 7566 | JONES |
| 7698 | BLAKE |
| 7782 | CLARK |
+-------+-------+
3 rows in set (0.00 sec)
6.2 drop 删除表
//模板
mysql> drop table if exists t_student;
Query OK, 0 rows affected (0.01 sec)
6.3 constraint 约束
6.3.1 非空约束:not null
//模板:not null
//列级约束
drop table if exists t_vip;
create table t_vip(
id int,
name varchar(255) not null --->添加约束
);
insert into t_vip(id,name) values(1,'zhangsan');
insert into t_vip(id,name) values(2,'lisi');
mysql> select * from t_vip;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
| 2 | lisi |
+------+----------+
2 rows in set (0.00 sec)
//插入空数据
mysql> insert into t_vip(id) values(1);
ERROR 1364 (HY000): Field 'name' doesn't have a default value
6.3.2 唯一性约束: unique
//模板:unique
//列级约束
mysql> create table t_vip(
-> id int,
-> name varchar(255) unique,
-> email varchar(255)
-> );
Query OK, 0 rows affected (0.03 sec)
mysql> select * from t_vip;
+------+----------+------------------+
| id | name | email |
+------+----------+------------------+
| 1 | zhangsan | zhangsan@123.com |
| 2 | lisi | lisi@123.com |
| 3 | wangwu | wangwu@123.com |
+------+----------+------------------+
3 rows in set (0.00 sec)
//加入相同姓名
mysql> insert into t_vip(id,name,email) values(4,'wangwu','wangwu@sina.com');
ERROR 1062 (23000): Duplicate entry 'wangwu' for key 'name'
6.3.3 not null与unique联合
//案例: name 与 email 字段联合起来具有唯一性
//表级约束
mysql> create table t_vip(
-> id int,
-> name varchar(255),
-> email varchar(255),
-> unique(name,email)
-> );
Query OK, 0 rows affected (0.02 sec)
//插入第一条
mysql> insert into t_vip(id,name,email) values(1,'zhangsan','zhangsan@123.com');
Query OK, 1 row affected (0.01 sec)
//插入第二条
mysql> insert into t_vip(id,name,email) values(2,'zhangsan','zhangsan@sina.com');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_vip;
+------+----------+-------------------+
| id | name | email |
+------+----------+-------------------+
| 1 | zhangsan | zhangsan@123.com |
| 2 | zhangsan | zhangsan@sina.com |
+------+----------+-------------------+
2 rows in set (0.00 sec)
//列级约束
mysql> create table t_vip(
-> id int,
-> name varchar(255) not null unique
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> desc t_vip;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(255) | NO | PRI | NULL | |
+-------+--------------+------+-----+---------+-------+
2 rows in set (0.01 sec)
//在mysql当中,如果一个字段同时被not null和unique约束的话,该字段自动变成主键字段(primary key)
6.3.4 主键约束:primary key
1、主键概述
//1、主键:相当于身份证号
任何一张表都应该有主键,没有主键,表无效!!
//2、主键概述:
主键字段:该字段上添加了主键约束,这样的字段叫做:主键字段
主键值:主键字段中的每一个值都叫做:主键值
//3、主键的特征:
not null + unique(主键值不能是NULL,同时也不能重复!)
2、单一主键
//4-2、单一主键
//列级约束
mysql> create table t_vip(
-> id int primary key, --->添加主键
-> name varchar(255)
-> );
Query OK, 0 rows affected (0.02 sec)
//表级约束
mysql> create table t_vip(
-> id int,
-> name varchar(255),
-> primary key(id) --->添加主键
-> );
Query OK, 0 rows affected (0.01 sec)
3、联合主键
//4-3、联合主键
mysql> create table t_vip(
-> id int,
-> name varchar(255),
-> email varchar(255),
-> primary key(id,name) --->添加主键
-> );
//不建议使用复合主键
4、自然主键与业务主键
//1、概述
自然主键:主键值是一个自然数,和业务没关系。
业务主键:主键值和业务紧密关联,例如拿银行卡账号做主键值。这就是业务主键!
//2、在实际开发中使用业务主键多,还是使用自然主键多一些?
自然主键使用比较多,因为主键只要做到不重复就行,不需要有意义。
业务主键不好,因为主键一旦和业务挂钩,那么当业务发生变动的时候,
可能会影响到主键值,所以业务主键不建议使用。尽量使用自然主键。
//3、 auto_increment的使用
mysql> create table t_vip(
-> id int primary key auto_increment,
【auto_increment表示自增,从1开始,以1递增!】
-> name varchar(255)
-> );
Query OK, 0 rows affected (0.01 sec)
//插入第一条数据
mysql> insert into t_vip(name) values('zhangsan');
Query OK, 1 row affected (0.00 sec)
//插入第二条数据
mysql> insert into t_vip(name) values('zhangsan');
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_vip;
+----+----------+
| id | name |
+----+----------+
| 1 | zhangsan |
| 2 | zhangsan |
+----+----------+
6.3.5 外键约束:foreign key
1、外键描述
//1、外键概述:
外键字段:该字段上添加了外键约束
外键值:外键字段当中的每一个值。
//2、外键的概念:
请设计数据库表,来描述“班级和学生”的信息?
第一种方案:班级和学生存储在一张表中???
t_student
no(pk) name classno classname
---------------------------------------------------------
1 jack 100 1班
2 lucy 100 1班
3 lilei 100 1班
4 hanmeimei 100 1班
5 zhangsan 101 2班
6 lisi 101 2班
7 wangwu 101 2班
8 zhaoliu 101 2班
第二种方案:班级一张表、学生一张表??
t_class 班级表
classno(pk) classname
------------------------------------------------------
100 1班
101 2班
t_student 学生表
no(pk) name cno(FK引用t_class这张表的classno)
--------------------------------------------------------
1 jack 100
2 lucy 100
3 lilei 100
4 hanmeimei 100
5 zhangsan 101
6 lisi 101
7 wangwu 101
8 zhaoliu 101
//第一种方法缺点:
数据冗余,空间浪费!!!!
这个设计是比较失败的!
2、案例
//创建两个表
mysql> create table t_class(
-> classno int primary key,
-> classname varchar(255)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql> create table T_student(
-> no int primary key auto_increment,
-> name varchar(255),
-> cno int,
-> foreign key(cno) references t_class(classno)
-> );
Query OK, 0 rows affected (0.04 sec)
//插入数据
mysql> insert into t_class(classno,classname) values(100,'一班');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_class(classno,classname) values(101,'二班');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_student(name,cno) values('shangsan',100);
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_student(name,cno) values('lisi',101);
Query OK, 1 row affected (0.01 sec)
//查看表
mysql> select * from t_class;
+---------+-----------+
| classno | classname |
+---------+-----------+
| 100 | 一班 |
| 101 | 二班 |
+---------+-----------+
2 rows in set (0.00 sec)
mysql> select * from t_student;
+----+----------+------+
| no | name | cno |
+----+----------+------+
| 1 | shangsan | 100 |
| 2 | lisi | 101 |
+----+----------+------+
2 rows in set (0.00 sec)
//注意:
t_class是父表
t_student是子表
1、删除表的顺序?
先删子,再删父。
2、创建表的顺序?
先创建父,再创建子。
3、删除数据的顺序?
先删子,再删父。
4、插入数据的顺序?
先插入父,再插入子。
//思考:
1、子表中的外键引用的父表中的某个字段,被引用的这个字段必须是主键吗?
不一定是主键,但至少具有unique约束。
2、测试:外键可以为NULL吗?
外键值可以为NULL。
6.4 index 索引
6.4.1 索引的概念
//1、什么是索引?(index)
索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。
一张表的一个字段可以添加一个索引,当然,多个字段联合起来也可以添加索引。(字段中添加)
索引相当于一本书的目录,是为了缩小扫描范围而存在的一种机制。
//2、MySQL在查询方面主要就是两种方式:
第一种方式:全表扫描
第二种方式:根据索引检索。
//3、注意:
在mysql数据库当中索引也是需要排序的,并且这个所以的排序和TreeSet
数据结构相同。TreeSet(TreeMap)底层是一个自平衡的二叉树!mysql
当中索引是一个B-Tree数据结构。
遵循左小右大原则存放。采用中序遍历方式遍历取数据。
//在mysql当中,主键上,以及unique字段上都会自动添加索引的!!!!
6.4.2 索引的实现原理
假设有一张用户表:t_user
id(PK) name 每一行记录在硬盘上都有物理存储编号
--------------------------------------------------
100 zhangsan 0x1111
120 lisi 0x2222
99 wangwu 0x8888
88 zhaoliu 0x9999
101 jack 0x6666
55 lucy 0x5555
130 tom 0x7777
//索引的实现原理就是缩小扫描范围,避免全表扫描(平衡二叉树)
//提醒:在任何数据库当中主键上都会自动添加索引对象,id字段上自动有索引,
因为id是PK。另外在mysql当中,一个字段上如果有unique约束的话,也会自动创建索引对象。
6.4.3 索引的使用情况
//什么条件下,我们会考虑给字段添加索引呢?
条件1:数据量庞大(到底有多么庞大算庞大,这个需要测试,因为每一个硬件环境不同)
条件2:该字段经常出现在where的后面,以条件的形式存在,也就是说这个字段总是被扫描。
条件3:该字段很少的DML(insert delete update)操作。(因为DML之后,索引需要重新排序。)
1、建议不要随意添加索引,因为索引也是需要维护的,太多的话反而会降低系统的性能。
2、建议通过主键查询,建议通过unique约束的字段进行查询,效率是比较高的。
6.4.4 索引的基本操作
//1、创建索引
mysql> create index emp_ename_index on emp(ename);
//2、删除索引
mysql> drop index emp_ename_index on emp;
//3、查看SQL语句是否用了索引来检索
//没使用索引
mysql> explain select * from emp where ename = 'KING';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
//扫描14条记录:说明没有使用索引。type=ALL
//使用了索引
mysql> create index emp_ename_index on emp(ename);
mysql> explain select * from emp where ename = 'KING';
+----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | emp | ref | emp_ename_index | emp_ename_index | 33 | const | 1 | Using index condition |
+----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-----------------------+
1 row in set (0.04 sec)
//扫描1条记录:说明使用了索引。
6.4.5 索引的失效的五种情况
1、失效第1种情况
//模糊查询(%开头)
mysql> explain select * from emp where ename like '%T';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
ename上即使添加了索引,也不会走索引,为什么?
原因是因为模糊匹配当中以“%”开头了!
尽量避免模糊查询的时候以“%”开始。
这是一种优化的手段/策略。
2、失效第2种情况
//or条件语句
mysql> explain select * from emp where ename = 'KING' or job = 'MANAGER';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.04 sec)
//使用or的时候会失效,如果使用or那么要求or两边的条件字段都要有索引,才会走索引,如果其中一边有一个字段没有索引,那么另一个字段上的索引也会实现。所以这就是为什么不建议使用or的原因。
(都要用索引both),可以用union
3、失效第3种情况
//复合索引
//检索左侧
ysql> explain select * from emp where job='manager';
+----+-------------+-------+------+-------------------+-------------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-------------------+-------------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | emp | ref | emp_job_sal_index | emp_job_sal_index | 30 | const | 3 | Using index condition |
+----+-------------+-------+------+-------------------+-------------------+---------+-------+------+-----------------------+
1 row in set (0.00 sec)
--->检索成功!!!
//检索右侧
mysql> explain select * from emp where sal=800;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
--->检索失败
//使用复合索引的时候,没有使用左侧的列查找,索引失效
什么是复合索引?
两个字段,或者更多的字段联合起来添加一个索引,叫做复合索引。
4、失效第4种情况
//在where当中索引进行了运算
mysql> create index emp_sal_index on emp(sal);
//没进行运算
mysql> explain select * from emp where sal=800;
+----+-------------+-------+------+---------------+---------------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------------+---------+-------+------+-------+
| 1 | SIMPLE | emp | ref | emp_sal_index | emp_sal_index | 9 | const | 1 | NULL |
+----+-------------+-------+------+---------------+---------------+---------+-------+------+-------+
1 row in set (0.00 sec)
//进行运算
mysql> explain select * from emp where sal+1=800;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
5、失效第5种情况
//在where当中索引列使用了函数
mysql> explain select * from emp where lower(ename) = 'smith';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 14 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.04 sec)
6.4.6 索引小结
//索引是各种数据库进行优化的重要手段。优化的时候优先考虑的因素就是索引。
索引在数据库当中分了很多类?
单一索引:一个字段上添加索引。
复合索引:两个字段或者更多的字段上添加索引。
主键索引:主键上添加索引。
唯一性索引:具有unique约束的字段上添加索引。
.....
注意:唯一性比较弱的字段上添加索引用处不大。
7. MySQL其他知识
7.1 存储引擎
7.1.1 存储引擎概念
//1、概念
实际上存储引擎是一个表存储/组织数据的方式
不同的存储引擎,表存储数据的方式不同
//2、查询使用的存储引擎
mysql> show create table t_student;
CREATE TABLE `t_student` (
`no` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cno` int(11) DEFAULT NULL,
PRIMARY KEY (`no`),
KEY `cno` (`cno`),
CONSTRAINT `t_student_ibfk_1` FOREIGN KEY (`cno`) REFERENCES `t_class` (`classno`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 |
其中:
ENGINE来指定存储引擎。
CHARSET来指定这张表的字符编码方式。
结论:
mysql默认的存储引擎是:InnoDB
mysql默认的字符编码方式是:utf8
//3、指定存储引擎
create table t_product(
id int primary key,
name varchar(255)
)engine=InnoDB default charset=gbk;
7.1.2 查看mysql支持哪些存储引擎
//mysql版本
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.5.36 |
+-----------+
//命令
mysql> show engines \G
*************************** 1. row ***************************
Engine: FEDERATED
Support: NO
Comment: Federated MySQL storage engine
Transactions: NULL
XA: NULL
Savepoints: NULL
*************************** 2. row ***************************
Engine: MRG_MYISAM
Support: YES
Comment: Collection of identical MyISAM tables
Transactions: NO
XA: NO
Savepoints: NO
...
7.1.3 InnoDB存储引擎
这是mysql默认的存储引擎,同时也是一个重量级的存储引擎。
InnoDB支持事务,支持数据库崩溃后自动恢复机制。
InnoDB存储引擎最主要的特点是:非常安全。
它管理的表具有下列主要特征:
– 每个 InnoDB 表在数据库目录中以.frm 格式文件表示
– InnoDB 表空间 tablespace 被用于存储表的内容(表空间是一个逻辑名称。表空间存储数据+索引。)
– 提供一组用来记录事务性活动的日志文件
– 用 COMMIT(提交)、SAVEPOINT 及ROLLBACK(回滚)支持事务处理
– 提供全 ACID 兼容
– 在 MySQL 服务器崩溃后提供自动恢复
– 多版本(MVCC)和行级锁定
– 支持外键及引用的完整性,包括级联删除和更新
InnoDB最大的特点就是支持事务:
以保证数据的安全。效率不是很高,并且也不能压缩,不能转换为只读,
不能很好的节省存储空间。
7.1.4 MEMORY存储引擎
使用 MEMORY 存储引擎的表,其数据存储在内存中,且行的长度固定,
这两个特点使得 MEMORY 存储引擎非常快。
MEMORY 存储引擎管理的表具有下列特征:
– 在数据库目录内,每个表均以.frm 格式的文件表示。
– 表数据及索引被存储在内存中。(目的就是快,查询快!)
– 表级锁机制。
– 不能包含 TEXT 或 BLOB 字段。
MEMORY 存储引擎以前被称为HEAP 引擎。
MEMORY引擎优点:查询效率是最高的。不需要和硬盘交互。
MEMORY引擎缺点:不安全,关机之后数据消失。因为数据和索引都是在内存当中。
7.2 视图
7.2.1 视图的概念&使用
//1、什么是视图?
view:站在不同的角度去看待同一份数据。
//2、跟复制表table的区别
我们可以面向视图对象进行增删改查,对视图对象的增删改查,会导致原表被操作!(视图的特点:通过对视图的操作,会影响到原表数据。)
表复制:
mysql> create table dept2 as select * from dept;
//3、创建视图对象
mysql> create view dept2_view as select * from dept2;
Query OK, 0 rows affected (0.04 sec)
//4、删除视图对象:
mysql> drop view dept2_view;
Query OK, 0 rows affected (0.00 sec)
//注意:只有DQL语句才能以view的形式创建。
create view view_name as 这里的语句必须是DQL语句;
7.2.2 视图用法
//1、单表视图操作
//面向视图查询
select * from dept2_view;
// 面向视图插入
insert into dept2_view(deptno,dname,loc) values(60,'SALES', 'BEIJING');
// 查询原表数据
mysql> select * from dept2;
// 面向视图删除
mysql> delete from dept2_view;
// 查询原表数据
mysql> select * from dept2;
Empty set (0.00 sec)
//2、多表视图操作
// 创建视图对象
create view
emp_dept_view
as
select
e.ename,e.sal,d.dname
from
emp e
join
dept d
on
e.deptno = d.deptno;
// 查询视图对象
mysql> select * from emp_dept_view;
// 面向视图更新
update emp_dept_view set sal = 1000 where dname = 'ACCOUNTING';
// 原表数据被更新
mysql> select * from emp;
7.2.3 视图作用
//视图对象在实际开发中到底有什么用?
//作用:方便,简化开发,利于维护
create view
emp_dept_view
as
select
e.ename,e.sal,d.dname
from
emp e
join
dept d
on
e.deptno = d.deptno;
假设有一条非常复杂的SQL语句,而这条SQL语句需要在不同的位置上反复使用。每一次使用这个sql语句的时候都需要重新编写,很长,很麻烦,怎么办?可以把这条复杂的SQL语句以视图对象的形式新建。在需要编写这条SQL语句的位置直接使用视图对象,可以大大简化开发。并且利于后期的维护,因为修改的时候也只需要修改一个位置就行,只需要
修改视图对象所映射的SQL语句。
我们以后面向视图开发的时候,使用视图的时候可以像使用table一样。可以对视图进行增删改查等操作。视图不是在内存当中,视图对象也是存储在硬盘上的,不会消失。
再提醒一下:
视图对应的语句只能是DQL语句。
但是视图对象创建完成之后,可以对视图进行增删改查等操作。
小插曲:
增删改查,又叫做:CRUD。
CRUD是在公司中程序员之间沟通的术语。一般我们很少说增删改查。
一般都说CRUD。
C:Create(增)
R:Retrive(查:检索)
U:Update(改)
D:Delete(删)
7.3 DBA命令
7.3.1 数据的备份
//数据的导出和导入
//1、数据的导出
注意:在windows的dos命令窗口中:
mysqldump bjpowernode>D:\bjpowernode.sql -uroot -p123456
导出数据库中指定的表:
mysqldump bjpowernode emp>D:\bjpowernode.sql -uroot -p123456
//2、数据的导入
注意:需要先登录到mysql数据库服务器上。
然后创建数据库:create database bjpowernode;
使用数据库:use bjpowernode
然后初始化数据库:source D:\bjpowernode.sql
7.4 数据库设计三范式
7.4.1 三范式概述
//1、什么是数据库设计范式?
数据库表的设计依据。教你怎么进行数据库表的设计。
//2、数据库设计三范式
第一范式:要求任何一张表必须有主键,每一个字段原子性不可再分。
第二范式:建立在第一范式的基础之上,要求所有非主键字段完全依赖主键,不要产生部分依赖。
第三范式:建立在第二范式的基础之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。
//设计数据库表的时候,按照以上的范式进行,可以避免表中数据的冗余,空间的浪费。
7.4.2 第一范式
最核心,最重要的范式,所有表的设计都需要满足。
必须有主键,并且每一个字段都是原子性不可再分。
//1、不合格表table
学生编号 学生姓名 联系方式
------------------------------------------
1001 张三 zs@gmail.com,1359999999
1002 李四 ls@gmail.com,13699999999
1001 王五 ww@163.net,13488888888
以上是学生表,满足第一范式吗?
不满足,第一:没有主键。第二:联系方式可以分为邮箱地址和电话
//2、合格表table
学生编号(pk) 学生姓名 邮箱地址 联系电话
----------------------------------------------------
1001 张三 zs@gmail.com 1359999999
1002 李四 ls@gmail.com 13699999999
1003 王五 ww@163.net 13488888888
7.4.3 第二范式
建立在第一范式的基础之上,
要求所有非主键字段必须完全依赖主键,不要产生部分依赖。
//1、不合格表table
学生编号 学生姓名 教师编号 教师姓名
-----------------------------------------
1001 张三 001 王老师
1002 李四 002 赵老师
1003 王五 001 王老师
1001 张三 002 赵老师
//这张表描述了学生和老师的关系:
(1个学生可能有多个老师,1个老师有多个学生)
这是非常典型的:多对多关系!
//2、改进表table
学生编号+教师编号(pk) 学生姓名 教师姓名
------------------------------------------
1001 001 张三 王老师
1002 002 李四 赵老师
1003 001 王五 王老师
1001 002 张三 赵老师
//学生编号 教师编号,两个字段联合做主键,复合主键(PK: 学生编号+教师编号)
经过修改之后,以上的表满足了第一范式。但是满足第二范式吗?
不满足,“张三”依赖1001,“王老师”依赖001,显然产生了部分依赖。
产生部分依赖有什么缺点?
数据冗余了。空间浪费了。“张三”重复了,“王老师”重复了。
//3、合格表table
使用三张表来表示多对多的关系!!!!
student table:
学生编号(pk) 学生名字
------------------------------------
1001 张三
1002 李四
1003 王五
teacher table:
教师编号(pk) 教师姓名
--------------------------------------
001 王老师
002 赵老师
学生教师关系表
id(pk) 学生编号(fk) 教师编号(fk)
-------------------------------------------
1 1001 001
2 1002 002
3 1003 001
4 1001 002
背口诀:
多对多怎么设计?
多对多,三张表,关系表两个外键!!!!!!!!!!!!!!!
7.4.4 第三范式
第三范式建立在第二范式的基础之上
要求所有非主键字典必须直接依赖主键,不要产生传递依赖。
学生编号(PK) 学生姓名 班级编号 班级名称
------------------------------------------
1001 张三 01 一年一班
1002 李四 02 一年二班
1003 王五 03 一年三班
1004 赵六 03 一年三班
//问题:
1、以上表的设计是描述:班级和学生的关系。很显然是1对多关系!
一个教室中有多个学生。
2、分析以上表是否满足第一范式?
满足第一范式,有主键。
3、分析以上表是否满足第二范式?
满足第二范式,因为主键不是复合主键,没有产生部分依赖。主键是单一主键。
4、分析以上表是否满足第三范式?
第三范式要求:不要产生传递依赖!
一年一班依赖01,01依赖1001,产生了传递依赖。
不符合第三范式的要求。产生了数据的冗余。
那么应该怎么设计一对多呢?
班级表:一
班级编号(pk) 班级名称
-----------------------------
01 一年一班
02 一年二班
03 一年三班
学生表:多
学生编号(PK) 学生姓名 班级编号(fk)
-------------------------------------------
1001 张三 01
1002 李四 02
1003 王五 03
1004 赵六 03
背口诀:
一对多,两张表,多的表加外键!!!!!!!!!!!!
7.4.5 总结表的设计
1、一对多:
一对多,两张表,多的表加外键!!!!!!!!!!!!
2、多对多:
多对多,三张表,关系表两个键!!!!!!!!!!!!
3、一对一:
口诀:一对一,外键唯一!!!!!!!!!!
一对一放到一张表中不就行了吗?为啥还要拆分表?
在实际的开发中,可能存在一张表字段太多,太庞大。这个时候要拆分表。
思考:一对一怎么设计?
//1、没有拆分表之前:一张表
t_user
id login_name login_pwd real_name email address........
---------------------------------------------------------
1 zhangsan 123 张三 zhangsan@xxx
2 lisi 123 李四 lisi@xxx
...
//2、这种庞大的表建议拆分为两张:
t_login 登录信息表
id(pk) login_name login_pwd
--------------------------------------
1 zhangsan 123
2 lisi 123
t_user 用户详细信息表
id(pk) real_name email address........ login_id(fk+unique)
--------------------------------------------------------
100 张三 zhangsan@xxx
1
200 李四 lisi@xxx
2
//口诀:一对一,外键唯一!!!!!!!!!!
7.4.6 嘱咐
数据库设计三范式是理论上的。
实践和理论有的时候有偏差。
最终的目的都是为了满足客户的需求,有的时候会拿冗余换执行速度。
因为在sql当中,表和表之间连接次数越多,效率越低。(笛卡尔积)
有的时候可能会存在冗余,但是为了减少表的连接次数,这样做也是合理的,并且对于开发人员来说,sql语句的编写难度也会降低。
面试的时候把这句话说上:他就不会认为你是初级程序员了!
8. JDBC
8.1 JDBC基本概念
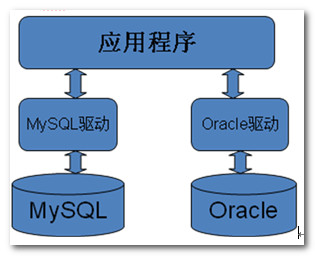
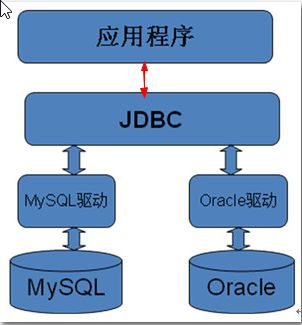
8.1.1 JDBC的本质
【没有JDBC时】
【有JDBC时】
//概念
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。是Java访问数据库的标准规范。
//JDBC需要连接驱动,驱动是两个设备要进行通信,满足一定通信数据格式,数据格式由设备提供商规定,设备提供商为设备提供驱动软件,通过软件可以与该设备进行通信。
我们使用的是mysql的驱动mysql-connector-java-5.1.39-bin.jar
//总结
* JDBC是java提供给开发人员的一套操作数据库的接口
* 数据库驱动就是实现该接口的实现类
8.1.2 导入数据库驱动
【导入mysql-connector-java-5.1.39.bin.jar】
8.2 第一个JDBC程序
//1、加载驱动
作用:告诉Java程序,即将要连接的是哪个品牌的数据库
//2、获取连接
作用:表示JVM的进程和数据库进程之间的通道打开了,这属于进程之间的通信,使用完要关闭
//3、获取数据库操作对象
//4、执行SQL语句(DQL,DML...)
//5、处理查询结果集(第四步为select语句时,才需要)
//6、释放资源
作用:Java和数据库之间数据进程之间的关系,这属于进程之间的通信,使用完要关闭
package OtherStudy;
import java.sql.*;
public class JDBCText01 {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
//1、加载驱动
//DriverManager.registerDriver(new com.mysql.jdbc.Driver());
Class.forName("com.mysql.jdbc.Driver"); //固定写法,加载驱动
//2、获取连接(用户信息和url)
String url="jdbc:mysql://localhost:3306/test?" +
"useUnicode=true&characterEncoding=utf8&useSSL=true";
String username="root";
String password="123456";
//3、获取数据库对象
Connection connection= DriverManager.getConnection(url,username,password);
//4、执行SQl语句
Statement statement = connection.createStatement();
//5、处理查询结果集
String sql="select * from emp";
ResultSet resultSet=statement.executeQuery(sql);
while(resultSet.next()){
System.out.println("ename:"+resultSet.getObject("ename"));
}
//6、释放资源
resultSet.close();
statement.close();
connection.close();
}
}
输出:
ename:SMITH
ename:ALLEN
ename:WARD
ename:JONES
ename:MARTIN
ename:BLAKE
ename:CLARK
ename:SCOTT
ename:KING
ename:TURNER
ename:ADAMS
ename:JAMES
ename:FORD
ename:MILLER
Process finished with exit code 0
8.2.1 Connection类
//DriverManager.registerDriver(new com.mysql.jdbc.Driver());
Class.forName("com.mysql.jdbc.Driver"); //固定写法,加载驱动
//connection 代表数据库
//数据库设置自动提交
//事务提交
//事务回滚
connection.rollback();
connection.commit();
connection.setAutoCommit();
8.2.2 URL连接端口
String url="jdbc:mysql://localhost:3306/test?" + "useUnicode=true&characterEncoding=utf8&useSSL=true";
//mysql —— 3306
//协议://主机地址:端口号/数据库名?参数1&参数2&参数3
8.2.3 Statement类
(PrepareStatement执行SQL对象)
Statement statement = connection.createStatement();
statement.executeQuery(); //返回ResultSet
statement.executeUpdate();
statement.execute();
8.2.4 ResultSet类
resultSet.getObject();
resultSet.getDouble();
resultSet.getInt();
resultSet.next();
resultSet.previous();
resultSet.absolute(row); //移动到指定行
8.3 Statement对象
8.3.1 配置文件和工具类
//配置文件+工具类=>普通实现类
//配置文件db.properties
driver = com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&useSSL=true
username=root
password=123456
//测试类
package OtherStudy;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class JdbcUtils {
private static String driver=null;
private static String url=null;
private static String username=null;
private static String password=null;
static {
try{
InputStream in = JdbcUtils.class.getClassLoader().getResourceAsStream("db.properties");
Properties pr=new Properties();
pr.load(in);
driver=pr.getProperty("driver");
url=pr.getProperty("url");
username=pr.getProperty("username");
password=pr.getProperty("password");
//1、加载驱动
Class.forName(driver);
}catch (Exception e) {
e.printStackTrace();
}
}
//2、获取连接
public static Connection getConnection() throws SQLException {
return DriverManager.getConnection(url, username, password);
}
//6、释放资源
public static void release(Connection conn, Statement st, ResultSet rs){
if(rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(st!=null){
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
8.3.2 增加数据
//实现类
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCText02 {
public static void main(String[] args) {
Connection conn=null;
Statement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
conn=JdbcUtils.getConnection();
//4、获取SQL的执行对象
st = conn.createStatement();
String sql="insert into t_vip(id,name) values(11,'小刚')";
int i=st.executeUpdate(sql);
if(i>0){
System.out.println("增加成功!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(conn,st,rs);
}
}
}
8.3.3 删除数据
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCText02 {
public static void main(String[] args) {
Connection conn=null;
Statement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
conn=JdbcUtils.getConnection();
//4、获取SQL的执行对象
st = conn.createStatement();
String sql="delete from t_vip where id=14";
int i = st.executeUpdate(sql);
if(i>0){
System.out.println("删除成功!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(conn,st,rs);
}
}
}
8.3.4 修改数据
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCText02 {
public static void main(String[] args) {
Connection conn=null;
Statement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
conn=JdbcUtils.getConnection();
//4、获取SQL的执行对象
st = conn.createStatement();
String sql="update t_vip set name='大大' where id=1";
int i = st.executeUpdate(sql);
if(i>0){
System.out.println("修改成功!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(conn,st,rs);
}
}
}
8.3.5 查找数据
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCText02 {
public static void main(String[] args) {
Connection conn=null;
Statement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
conn=JdbcUtils.getConnection();
//4、获取SQL的执行对象
st = conn.createStatement();
String sql="select * from t_vip where id=1";
//5、处理查询结果集
rs=st.executeQuery(sql);
while(rs.next()){ System.out.println(rs.getString("name"));
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(conn,st,rs);
}
}
}
8.4 PreparedStatement对象
//作用:
PerparedStatement对象防止SQL注入。效果更好!更安全!
8.4.1 增加数据
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCText03 {
public static void main(String[] args) {
login(12,"luffy");
}
public static void login(int id,String name){
Connection con=null;
PreparedStatement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
con = JdbcUtils.getConnection();
//区别
//4、执行SQL语句
//使用占位符代替参数
String sql="insert into t_vip(id,name) values(?,?)";
//预编译,先写sql,不执行
st=con.prepareStatement(sql);
st.setInt(1,id);
st.setString(2,name);
//执行
int i = st.executeUpdate();
if(i>0){
System.out.println("增加成功!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(con,st,rs);
}
}
}
8.4.2 删除数据
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCText03 {
public static void main(String[] args) {
login(12);
}
public static void login(int id){
Connection con=null;
PreparedStatement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
con = JdbcUtils.getConnection();
//区别
//4、执行SQL语句
//使用占位符代替参数
String sql="delete from t_vip where id=?";
//预编译,先写sql,不执行
st=con.prepareStatement(sql);
st.setInt(1,id);
//执行
int i = st.executeUpdate();
if(i>0){
System.out.println("删除成功!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(con,st,rs);
}
}
}
8.4.3 修改数据
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCText03 {
public static void main(String[] args) {
login(12,"老王");
}
public static void login(int id,String name){
Connection con=null;
PreparedStatement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
con = JdbcUtils.getConnection();
//区别
//4、执行SQL语句
//使用占位符代替参数
String sql="update t_vip set name=? where id=?";
//预编译,先写sql,不执行
st=con.prepareStatement(sql);
st.setString(1,name);
st.setInt(2,id);
//执行
int i = st.executeUpdate();
if(i>0){
System.out.println("修改成功!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(con,st,rs);
}
}
}
8.4.4 查找数据
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCText03 {
public static void main(String[] args) {
login("小明");
}
public static void login(String name){
Connection con=null;
PreparedStatement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
con = JdbcUtils.getConnection();
//区别
//4、执行SQL语句
//使用占位符代替参数
String sql="select * from t_vip where name=?";
//预编译,先写sql,不执行
st=con.prepareStatement(sql);
st.setString(1,name);
//执行
//5、处理查询结果集
rs = st.executeQuery();
while(rs.next()){
System.out.println(rs.getInt(1));
System.out.println(rs.getString(2));
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(con,st,rs);
}
}
}
8.5 操作事务
package OtherStudy;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Scanner;
public class JDBCText04 {
public static void main(String[] args) {
System.out.println("输入你要增加100月薪的员工:");
Scanner sc=new Scanner(System.in);
String s=sc.nextLine();
login(s);
}
private static void login(String ename) {
Connection con=null;
PreparedStatement st=null;
ResultSet rs=null;
try {
//3、创建数据库对象
con = JdbcUtils.getConnection();
//关闭数据库的自动提交功能,自动开启事务
con.setAutoCommit(false);
//4、执行SQL语句
String sql="update emp2 set sal=sal+100 where ename=?";
st=con.prepareStatement(sql);
st.setString(1,ename);
st.executeUpdate();
//提交事务
con.commit();
System.out.println("修改成功!");
} catch (SQLException e) {
try {
con.rollback();
} catch (SQLException ex) {
ex.printStackTrace();
}
e.printStackTrace();
}finally{
JdbcUtils.release(con,st,rs);
}
}
}
//区别
//4、执行SQL语句
//使用占位符代替参数
String sql="delete from t_vip where id=?";
//预编译,先写sql,不执行
st=con.prepareStatement(sql);
st.setInt(1,id);
//执行
int i = st.executeUpdate();
if(i>0){
System.out.println("删除成功!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(con,st,rs);
}
}
}
#### 8.4.3 修改数据
~~~java
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCText03 {
public static void main(String[] args) {
login(12,"老王");
}
public static void login(int id,String name){
Connection con=null;
PreparedStatement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
con = JdbcUtils.getConnection();
//区别
//4、执行SQL语句
//使用占位符代替参数
String sql="update t_vip set name=? where id=?";
//预编译,先写sql,不执行
st=con.prepareStatement(sql);
st.setString(1,name);
st.setInt(2,id);
//执行
int i = st.executeUpdate();
if(i>0){
System.out.println("修改成功!");
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(con,st,rs);
}
}
}
8.4.4 查找数据
package OtherStudy;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCText03 {
public static void main(String[] args) {
login("小明");
}
public static void login(String name){
Connection con=null;
PreparedStatement st=null;
ResultSet rs=null;
try {
//3、获取数据库对象
con = JdbcUtils.getConnection();
//区别
//4、执行SQL语句
//使用占位符代替参数
String sql="select * from t_vip where name=?";
//预编译,先写sql,不执行
st=con.prepareStatement(sql);
st.setString(1,name);
//执行
//5、处理查询结果集
rs = st.executeQuery();
while(rs.next()){
System.out.println(rs.getInt(1));
System.out.println(rs.getString(2));
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
JdbcUtils.release(con,st,rs);
}
}
}
8.5 操作事务
package OtherStudy;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Scanner;
public class JDBCText04 {
public static void main(String[] args) {
System.out.println("输入你要增加100月薪的员工:");
Scanner sc=new Scanner(System.in);
String s=sc.nextLine();
login(s);
}
private static void login(String ename) {
Connection con=null;
PreparedStatement st=null;
ResultSet rs=null;
try {
//3、创建数据库对象
con = JdbcUtils.getConnection();
//关闭数据库的自动提交功能,自动开启事务
con.setAutoCommit(false);
//4、执行SQL语句
String sql="update emp2 set sal=sal+100 where ename=?";
st=con.prepareStatement(sql);
st.setString(1,ename);
st.executeUpdate();
//提交事务
con.commit();
System.out.println("修改成功!");
} catch (SQLException e) {
try {
con.rollback();
} catch (SQLException ex) {
ex.printStackTrace();
}
e.printStackTrace();
}finally{
JdbcUtils.release(con,st,rs);
}
}
}
















 1502
1502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









