






数仓的整体调度使用的是Azkaban工具来完成的。我们要先理清楚各层之间的流程以及各脚本之间的依赖关系,然后根据这个关系来编写Azkaban的工作流程配置文件。
配置文件包括两个,一个是以.project结尾的文件,这里面放版本号;一个是以.flow结尾的文件,这里面放配置的流程依赖关系。然后将这两个文件放到zip压缩包里,上传到Azkaban的web界面里来执行。
在Azkaban中,我们可以配置执行时间、报警通知等,azkaban会帮我们按指定的需求执行脚本。
数仓各层脚本之间的流程依赖关系图:
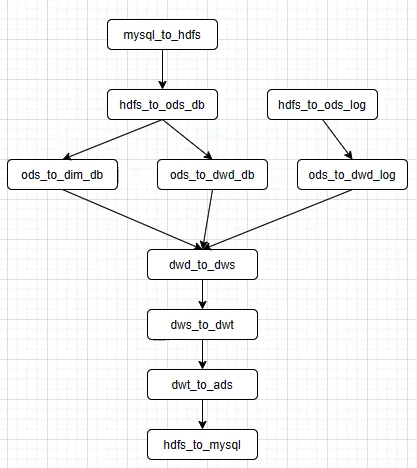
编写Azkaban工作流程配置文件
1)编写 azkaban.project 文件,内容如下
azkaban-flow-version: 2.0
2)编写gmall .flow 文件,内容如下
nodes:
- name: mysql_to_hdfs
type: command
config:
command: /home/atguigu/bin/mysql_to_hdfs.sh all ${dt}
- name: hdfs_to_ods_log
type: command
config:
command: /home/atguigu/bin/hdfs_to_ods_log.sh ${dt}
- name: hdfs_to_ods_db
type: command
dependsOn:
- mysql_to_hdfs
config:
command: /home/atguigu/bin/hdfs_to_ods_db.sh all ${dt}
- name: ods_to_dim_db
type: command
dependsOn:
- hdfs_to_ods_db
config:
command: /home/atguigu/bin/ods_to_dim_db.sh all ${dt}
- name: ods_to_dwd_log
type: command
dependsOn:
- hdfs_to_ods_log
config:
command: /home/atguigu/bin/ods_to_dwd_log.sh all ${dt}
- name: ods_to_dwd_db
type: command
dependsOn:
- hdfs_to_ods_db
config:
command: /home/atguigu/bin/ods_to_dwd_db.sh all ${dt}
- name: dwd_to_dws
type: command
dependsOn:
- ods_to_dim_db
- ods_to_dwd_log
- ods_to_dwd_db
config:
command: /home/atguigu/bin/dwd_to_dws.sh all ${dt}
- name: dws_to_dwt
type: command
dependsOn:
- dwd_to_dws
config:
command: /home/atguigu/bin/dws_to_dwt.sh all ${dt}
- name: dwt_to_ads
type: command
dependsOn:
- dws_to_dwt
config:
command: /home/atguigu/bin/dwt_to_ads.sh all ${dt}
- name: hdfs_to_mysql
type: command
dependsOn:
- dwt_to_ads
config:
command: /home/atguigu/bin/hdfs_to_mysql.sh all
1.1为什么使用全流程调度工具?
1)一个完整的数据分析系统通常都是由大量任务单元组成:
S hell脚本程序, J ava程序, M ap R educe程序、 H ive脚本等
2)各任务单元之间存在时间先后及前后依赖关系,要先执行哪个之后,才能后执行哪个。
3 )所以,为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
使用azkaban全流程调度工具,来对数仓项目的任务进行分别调度。使用这个工具,我们不用估算哪个任务需要多久执行完,再开启另一个任务,而是把依赖关系交给azkaban工具,它会先执行完一个任务,再执行后面的任务。
1 .2 常见工作流调度系统
1)简单的任务调度:直接使用 L inux的 Crontab来定义;(C rontab需要给定每个任务的开始时间,因为数仓中的任务之间存在依赖关系,所以这需要我们估算每个任务需要执行的时间,但事实上这并不可控,所以不用它。)
2 )复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如 O oize、 A zkaban、 Airflow 、 DolphinScheduler 等。
1.3 Azkaban与Oozie对比
总体来说, O oize相比 A zkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。 如果可以不在意某些功能的缺失,轻量级调度器 A zkaban是很不错的候选对象。
步骤:编写两个文件,一个以 .project结尾、一个以.flow结尾,.project文件内容写版本,.flow文件内容写任务与依赖关系,然后将两个文件压缩到zip文件中,上传到azkaban的web界面里运行即可。
.project文件内容如:
azkaban-flow-version: 2.0
.flow文件内容如:
需求: JobA 和Job B 执行完了,才能执行Job C
具体步骤:
1)修改b asic.flow 为如下内容
nodes:
- name: jobC
type: command
# jobC 依赖 JobA和JobB
dependsOn :
- jobA
- jobB
config:
command: echo "I’m JobC"
- name: jobA
type: command
config:
command: echo "I’m JobA"
- name: jobB
type: command
config:
command: echo "I’m JobB"
1.4 Azkaban多Executor模式下注意事项
Azkaban多Executor模式是指,在集群中多个节点部署Executor。在这种模式下, Azkaban web Server会根据策略,选取其中一个Executor去执行任务。
由于我们需要交给Azkaban调度的脚本,以及脚本需要的 Hive , S qoop等应用只在hadoop102部署了,为保证任务顺利执行,我们须在以下两种方案 任选其一,推荐使用方案二。
方案一:指定特定的Executor(hadoop102)去执行任务。
1)在M ySQL 中azkaban数据库executors表中,查询hadoop102上的 E xecutor的id。
mysql> use azkaban;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from executors;
+----+-----------+-------+--------+
| id | host | port | active |
+----+-----------+-------+--------+
| 1 | hadoop103 | 35985 | 1 |
| 2 | hadoop104 | 36363 | 1 |
| 3 | hadoop102 | 12321 | 1 |
+----+-----------+-------+--------+
3 rows in set (0.00 sec)
2)在执行工作流程时加入 useExecutor 属性,如下
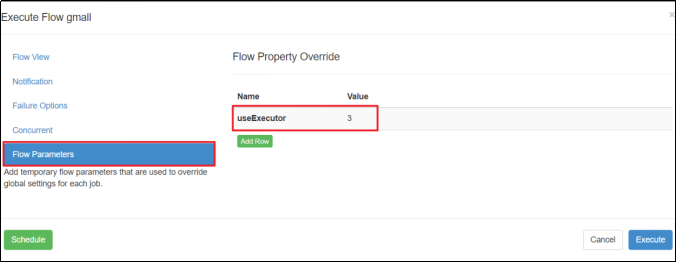
方案二:在Executor所在所有节点部署任务所需脚本和应用。(这样任一一个executor都可以在本地执行)
1)分发脚本、sqoop、spark、my _env.sh
[atguigu@hadoop102 ~]$ xsync /home/atguigu/bin/
[atguigu@hadoop102 ~]$ xsync /opt/module/ hive
[atguigu@hadoop102 ~]$ xsync /opt/module/sqoop
[atguigu@hadoop102 ~]$ xsync /opt/module/spark
[atguigu@hadoop102 ~]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
2)分发之后,在hadoop 103 ,hadoop 104 重新加载环境变量配置文件(source ....),并重启Azkaban
【电商数仓】数仓调度之全流程调度(调度数据准备、Azkaban部署、创建数据库和表、Sqoop导出脚本、编写工作流程配置文件、一些注意事项)















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









