







前言

上一篇文章说到,这将是博主更新的最后一篇关于C语言知识点的博客,也确实,因为这篇文章是讲解的 c的预处理,也是c语言最后的一部分知识了,还是老话,博主的所有文章几乎篇幅都比较长,大家可以根据目录进行选择性观看,同时,博主还是有些小心思,帮自己以前的文章点点浏览量,哈哈哈,放上以前的文章链接.
| c语言操作符 | 基础指针 | 一篇面试题的经历 |
|---|---|---|
| 数据存储原理 | 基础结构体 | 指针进阶 |
| 数组与指针关系 | 指针与数组经典题 | 字符串与内存函数 |
| 自定义类型,结构体进阶 | 动态内存详解 | ^ 异或运算技巧 |
| & 与运算技巧 | c的小细节 | 详细文件相关操作 |
目录
1 程序的翻译环境与执行环境
程序编写完毕,我们就需要让它运行起来,看是否正确执行了我们所需要的目的.但是我们是否想过,这段程序在能够正确运行之前,经历了什么呢? 这就是我们今天要讲的主角 程序环境,程序的环境分为两个大部分:一个是 翻译环境,另一个是 执行环境.而我们所需要着重讲解的就是
翻译环境.
比如在ANSIC(标准C)中就写到,任何C的实现,都存在两个不同的环境.分别是:
翻译环境,在这个环境中源代码被替换转换为可执行的机器指令执行环境,用于实际执行代码.
那么,在这说了这么多,啥是翻译环境与执行环境呢? 博主将会以图的方式进行讲解,但是在放图之前,博主先介绍一个小概念:
- 源文件,即后缀为
.c文件 - 可执行文件(二进制文件),即后缀为
.exe文件 - 目标文件,即后缀为
.obj文件
上图:
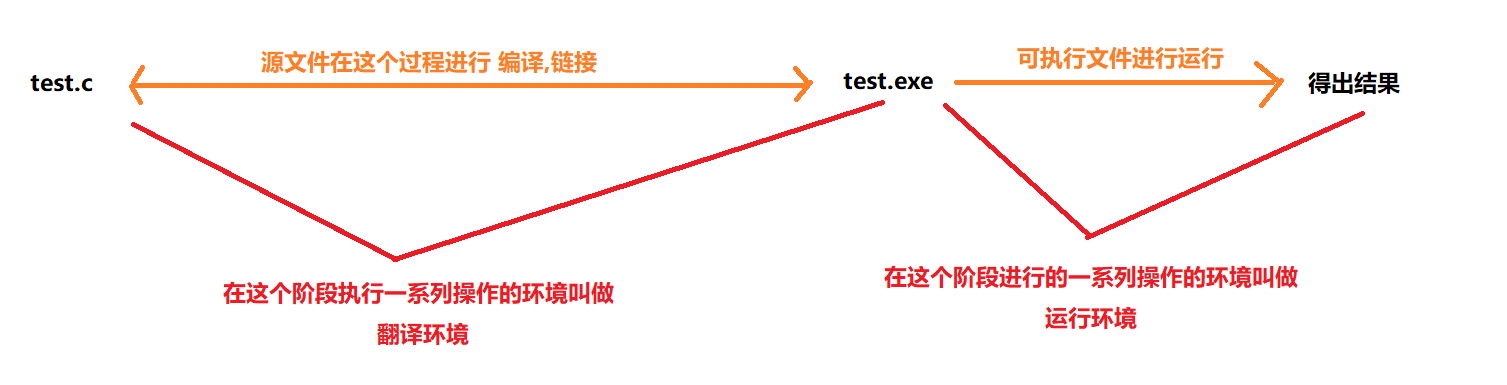
而如图所示,所标注的也正是像ANSIC解释那样.
2.翻译环境的编译与链接
编译阶段的过程是把一个源文件通过编译器的操作后变成目标文件(windos系统下后缀为.obj)
链接阶段的过程就是把编译阶段生成的目标文件与链接库链接起来形成可执行文件.
过程如下:

而什么是链接库? 其实它是一个二进制文件,在这个文件里面他包含了各种源程序可能用到的 函数或类等.

上图为例,LIBC.LIB就是一个链接库,他里面包含了 函数fread,还可能包含其他函数
3.翻译环境中的编译阶段
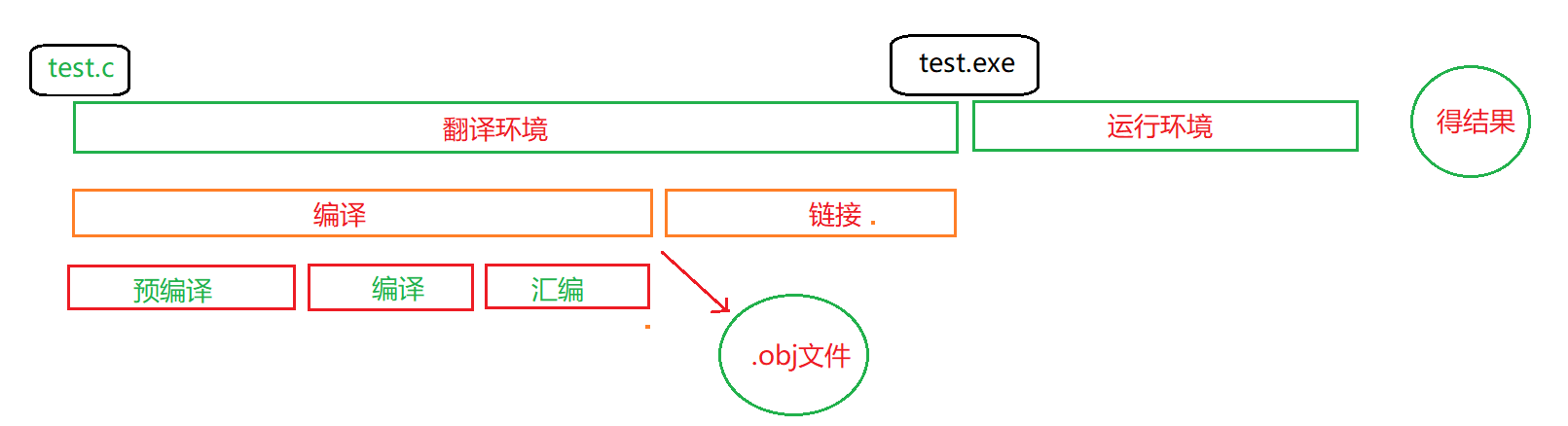
翻译环境总共分为两个大的部分 编译 与 链接,前面已经讲过,但是编译阶段才是我们的讲解重点.
因为在 编译阶段 它会完成很多事情.
而编译阶段我们要讲解的就是 预编译,编译,汇编
3.1预编译
在预编译阶段,程序在做什么呢?------------------嗯,不知道.
但是我们可以尝试下让一个源文件进行预编译,看看有啥变化,就知道预编译阶段在干什么了.
这里有一个test.c文件,内容如下:
#include <stdio.h>
int val = 2021;
int add(int x,int y)
{
return x+y;
}
int main()
{
int a = 10,b = 20;
int ret = add(a,b);
printf("%d",ret);
return 0;
}
现在让test.c进行预编译,怎么预编译?我们借助Linux的命令 gcc test.c -E > test.i
编译结果如下:

我们发现,当我们打开test.i(预编译后产生的文件),内容发生变化的只有 头文件变成了一大堆我们不认识的东西,但是经过查询,我们会发现,横线以上的所有东西都头文件 <stdio.h>的内容.
也就是说,在预编译阶段,会完成头文件的包含
如果我们给 test.c中增加宏呢?
#include <stdio.h>
#define M 1000
#define MAX(x,y) ((x)>(y)?(x):(y))
int val = 2021;
int add(int x,int y)
{
return x+y;
}
int main()
{
int num = M;
int m = MAX(100,200);
int a = 10,b = 20;
int ret = add(a,b);
printf("%d",ret);
return 0;
}
我们再次预编译试试.结果如下:

我们发现,预编译把 #define定义的符号和宏进了替换
如果我们给test.c中增加注释呢?? 执行同样操作,我们会发现注释消失了(不再演示)
总结:所以说预编译阶段,程序做的事情就是文本操作
- 头文件的包含
- #define定义的符号与宏替换
- 删除注释
3.2编译
经过了预编译,我们知道它做了3件文本操作事情.那么在编译阶段呢?会发生什么事情呢?
同理,我们继续借助Linux的命令,让预编译的test.i文件进行编译,命令为 gcc test.i -S
然后就会产生一个后缀为.s的文件,打开其内容如下:

发现,他把预编译后的.i文件变成了**汇编文件.**所以编译就是在干把c程序变成汇编语言的事情
其中,进行汇编过程中便有下面几个专业术语:
- 语法分析 (认识选择结构,循环等)
- 词法分析(认识关键字等等)
- 语义分析(读懂代码要做什么)
- 符号汇总(这个与下面的汇编阶段一起讲解)
3.3汇编
汇编阶段在干嘛呢?同理,我们再借助Linux的命令查看下(gcc test.s -c),把编译阶段产生的.s文件进行汇编.
我们会发现汇编生成了一个.o文件,文件内容为
可以发现,此过程要做的事情就是把编译阶段产生的文件变成二进制指令(机器指令).即变成可执行文件.
而这个过程中发生了一个叫做 生成符号表 的操作.
现在,是不是有人开始疑惑了? 汇编阶段的 生成符号表 和编译阶段的 符号汇总 有关系吗? 答案是有的.
先看符号表,什么是符号表呢?在说这个前,我们先解释下test.o的组成.
.o文件被称作目标文件,他是由固定的格式组成的,怎么组成的?由各种elf格式的段组,如图
那么这些elf文件是什么呢? 我们借助readelf 进行查看.
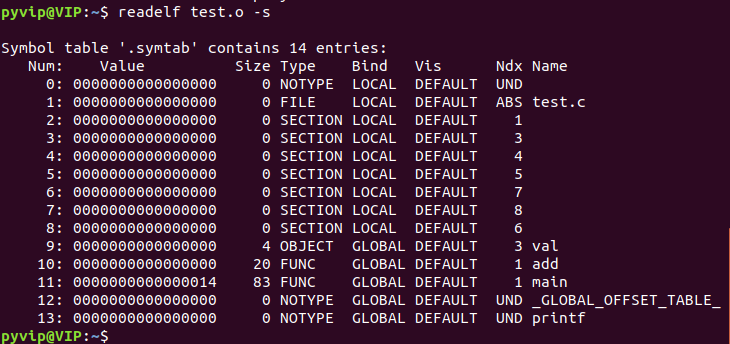
与源文件test.c进行对比

我们发现,他把全局的符号(全局变量,函数)形成了一张表.这就是符号表.
那什么是符号汇总呢???上面已经讲解过,在翻译环境中是多个源文件分别进行编译然后生成目标文件,同理,假设在同一个项目下
我们有一个add.c文件,还有一个test.c文件,内容分别如下:

那么这两个文件在编译阶段最终都会形成符号表,是什么符号呢?全局符号
所以,这两个文件在形成符号表之前,会先收集各自的全局符号放在各自的.s文件中,如下:

这就是符号汇总.
即在编译阶段 符号汇总,在汇编阶段把汇总的符号形成 符号表.
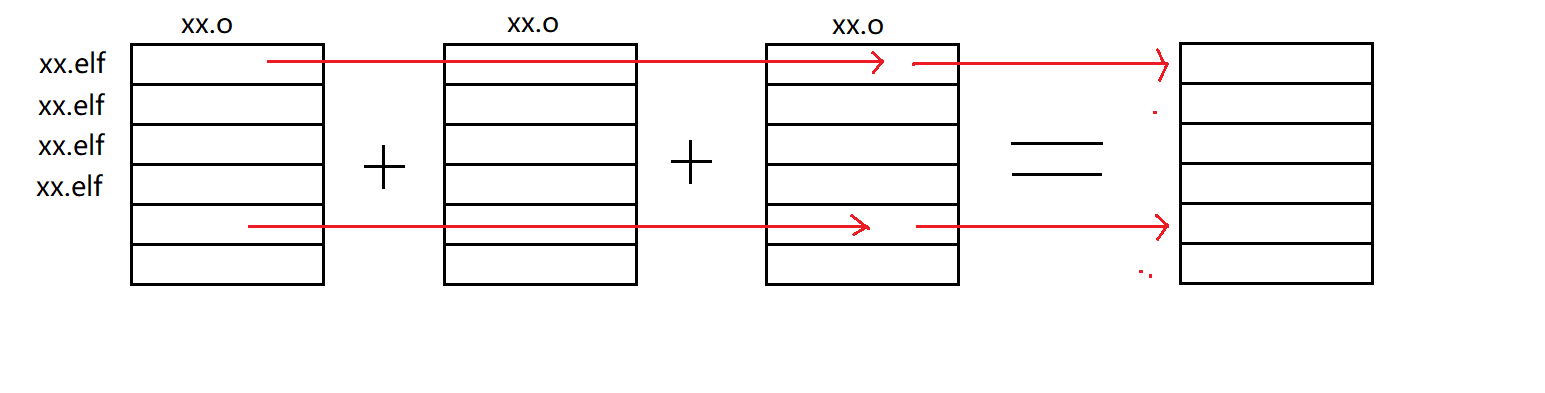
4.链接
链接阶段在干什么事情呢?主要有两件.
- 合并段表.
- 符号表的合并与重定位.
4.1合并段表
上面讲到,汇编阶段产生的.o文件由段表组成.
也就说,多个.o文件都有相同的段表区域,只是各个段表的内容不同.
而链接就是在干把多个相同区域的段表合并的事情,如图:
4.2符号表的合并与重定位
符号表之前讲过,每个文件都会生成符号表.
而链接阶段还会干的事情就是把所有符号表合并在一起,即聚集在一起.,称为符号表的合并.
但是就按照之前讲的那个add.c和test.c为例,我们可以清楚的发现两个文件的符号表是有重合的,那合并时候
的时候是舍弃那个add符号,保留哪个add符号呢?因为每个符号表中的符号还包含了地址,值等多个信息.
正确答案是 保存具有实际意义和真实地址的符号.
比如add.c和test.c都有符号add,但是前者才有效,因为后者的add最终还是用的前者的add函数.
而后面的合并相同符号的过程叫重定位.
经历上面两种操作以后,就会形成最终的.exe文件.















 967
967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











