







前言
上一篇讲完了List,那么这一篇就不得不说说它的好朋友—Set了,Set和List的最大区别就是Set中的元素是不可以重复的,虽然Set 接口并没有对 Collection 接口进行扩充,基本上还是与 Collection 接口保持一致。
此接口没有 List 接口中定义的 get(int index)方法,所以无法使用循环进行输出。所以只能使用toArray()方法或者迭代器进行循环遍历输出。
但是该接口中有着两个集合中不可或缺的子类:HashSet、TreeSet,本文将重点介绍HashSet以及TreeSet
HashSet
HashSet属于散列的存放类集,里面的东内容是无序存放的。通过源码可以发现,Has和Set在构造的时候实际上是创建了一个HashMap,即HashSet的底层数据结构是一个HashMap,如果对HashMap不太理解的朋友,可以看我的这篇博客Java中的Map接口。
老规矩,先看继承树图:
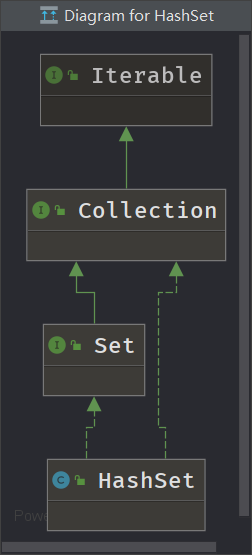
由于HashSet继承了Set,而set在继承Collection接口后并没有怎么进行方法的扩展,所以set的常用方法和Collection接口一样,大家可参考我的这篇博客Java集合之—Collection下面来简单叙述一下HashSet的几个特点:
1、HashSet存储的元素是无序且不可重复
2、可以存储null值
3、是线程不安全的,即如果多个线程同时操作同一个HashSet,那么结果是不可知的
HashSet内部存储机制
HashSet底层使用HashMap来进行存储,当使用HashSet进行存储元素的时候,底层是使用了map类的put方法,实际上就是将要存储的元素存储到了HashMap的key部分,其value部分是使用了一个默认值(new Object() )来存储
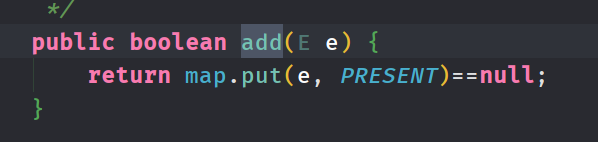
注意,当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode方法来得到该对象的哈希值,然后根据该哈希值决定该对象在HashSet中的存储位置。
但是,如果有两个元素通过equals方法比较返回值为true,可它们的hashCode方法返回的值不相等,HashSet将会把它们存储在不同位置,依然可以添加成功。
即HashSet集合判断两个元素是否相同的标准是两个对象通过equals方法比较相等,且哈希值也相等
所以,在使用HashSet存储自定义类型数据的时候,一定要尽量确保两个对象通过equals方法比较的结果和Hashcode()的方法返回值一致,即equals比较值为true,其哈希值也应该相等,这样可以更好的保证数据的唯一性,下面举个例子来帮助进一步的认知
例子
package com.blog.set;
import java.util.HashSet;
/**
* @Author jinhuan
* @Date 2022/4/15 9:56
* Description:
* 未对Book类重写equals以及hashcode方法,检测hashSet是否可以存重复值
*/
public class Test01 {
public static void main(String[] args) {
//实例化Book对象
Book book01 = new Book(1, "方与圆");
Book book02 = new Book(2, "傲慢与偏见");
Book book03 = new Book(1, "方与圆");
//创建HashSet集合
HashSet<Book> books = new HashSet<>();
//添加元素,注意,book01与book03是同一本书
books.add(book01);
books.add(book02);
books.add(book03);
//遍历该集合
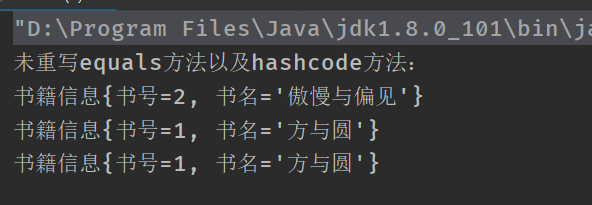
System.out.println("未重写equals方法以及hashcode方法:");
for (Book book : books) {
System.out.println(book);
}
}
}
class Book{
/**
* id
*/
private Integer id;
/**
* name
*/
private String name;
public Book(Integer id, String name) {
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "书籍信息{" +
"书号=" + id +
", 书名='" + name + '\'' +
'}';
}
}
运行截图
package com.blog.set;
import java.util.HashSet;
import java.util.Objects;
/**
* @Author jinhuan
* @Date 2022/4/15 9:56
* Description:
* 未对Book类重写equals以及hashcode方法,检测hashSet是否可以存重复值
*/
public class Test01 {
public static void main(String[] args) {
//实例化Book对象
Book book01 = new Book(1, "方与圆");
Book book02 = new Book(2, "傲慢与偏见");
Book book03 = new Book(1, "方与圆");
//创建HashSet集合
HashSet<Book> books = new HashSet<>();
//添加元素,注意,book01与book03是同一本书
books.add(book01);
books.add(book02);
books.add(book03);
//遍历该集合
System.out.println("已经重写equals方法以及hashcode方法:");
for (Book book : books) {
System.out.println(book);
}
}
}
class Book{
/**
* id
*/
private Integer id;
/**
* name
*/
private String name;
public Book(Integer id, String name) {
this.id = id;
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "书籍信息{" +
"书号=" + id +
", 书名='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o){
return true;
}
if (!(o instanceof Book)) {
return false;
}
Book book = (Book) o;
return Objects.equals(getId(), book.getId()) &&
Objects.equals(getName(), book.getName());
}
@Override
public int hashCode() {
return Objects.hash(getId(), getName());
}
}
运行截图

可以看出,重写了equals方法以及hashcode方法之后,就不会出现Set中存储‘“相同”元素的情况了,但实际上,并不是真正的相同哈,因为hashcode的返回值不同,所以并不是真正意义上的完全相容
众所周知,集合类就是对于数组的一个扩展,是为了解决数组不能解决或者不便解决的问题,关于hashset的存储原理,也就是hashmap的存储原理,还请大家参考我的这篇博客Java集合之—Map,里面对于存储原理做了进步一的讲解叙述,这里只对hash表做简单叙述
hash表
初始化容量:创建hash表时桶的数量;
尺寸:当前hash表中记录的数量;
容量:hash表中桶的数量;
散列因子:负载因子范围0~1,0表示空的hash表,0.5表示半满的hash表,1表示满(几乎不存在)。小对应着查询效率高,存储容量低;大对应着存储容量高,查询效率低。
负载极限:负载极限是一个0~1之间的数值,决定了hash表的最大填满程度。当hash表的负载因子达到指定负载极限时,hash表会自动成倍地增加容量,并将原有的对象重新分配,放入新的桶中。HashSet、HashMap、Hashtable默认的负载极限都是0.75,这个是官方测试后给出的最佳大小。
注意
当向HashSet中添加自定义对象时,必须十分小心!!!
如果修改HashSet集合中的对象,有可能导致该对象与集合中的其他对象相等,此时其哈希值发生变化,从而导致HashSet无法准确访问该对象。更为详细的介绍,还请大家移步上文,查看我的另一篇文章——Map。
TreeSet
说完了HashSet,下面就来谈谈TreeSet,继承树如下:
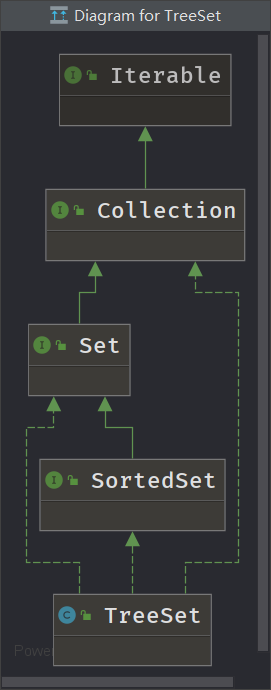
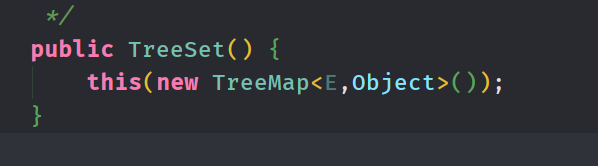
Treeset类实现了SortedSet接口,即TreeSet中的元素是有序的,和HashSet雷同,TreeSet底层是一个TreeMap,其内部实现的是红黑树。也因为其排序的特性,TreeSet有几个额外的方法提供使用,如下:
| 方法: | 简述: |
|---|---|
| Comparator comparator() | 如果TreeSet采用了定制顺序,则该方法返回定制排序所使用的 Comparator,如果TreeSet采用自然排序,则返回null |
| Object first() | 返回集合中的第一个元素 |
| Object last() | 返回集合中的最后一个元素 |
| Object lower(Object e) | 返回指定元素之前的元素 |
| Object higher(Object e) | 返回指定元素之后的元素 |
| SortedSet subSet(Object fromElement,Object toElement) | 返回此Set的子集合,不包含 |
| SortedSet headSet(Object toElement | 返回此Set的子集,由小于toElement的元素组成 |
| SortedSet tailSet(Object fromElement | 返回此Set的子集,由大于fromElement的元素组成 |
到此就不得不说一下TreeSet支持的排序方法:默认排序以及自定义排序
默认排序:
又叫做自然排序,是根据调用集合元素的compare To(Object object)方法来比较该集合中不同元素之间的大小关系,并默认采用升序排列。
关于Compare To(Object object),该方法源于Comarable接口,返回值为整数型,例如:obj1.compareTo(obj2)
如果返回0表示两个对象相等;如果返回正整数则表明obj1大于obj2;如果是负整数则表明obj1小于obj2。
自定义排序:
需要实现定制排序的时候,例如降序排序(TreeSet的自然排序是升序排列),可通过Comparator接口来实现该需求。该接口里包含一个int compare(T o1,T o2)方法,用于比较o1和o2的大小。见实例:
实例
package com.blog.set;
import java.util.Comparator;
import java.util.TreeSet;
/**
* @Author jinhuan
* @Date 2022/4/15 12:46
* Description:
*/
public class TestComparator {
public static void main(String[] args) {
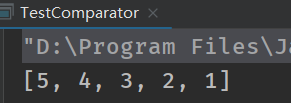
//实现降序输出TreeSet中的元素
TreeSet treeSet = new TreeSet<Integer>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
//修改为逆序
return o2-o1;
}
});
//添加元素
treeSet.add(1);
treeSet.add(2);
treeSet.add(3);
treeSet.add(4);
treeSet.add(5);
//输出
System.out.println(treeSet);
}
}
注意事项:
1、TreeSet是排序类集合,无法正常排序则会出现异常,所以,所有集合中的元素都必须实现compatable接口,注意,自定义类必须实现该接口,否则会出现ClassCastException
2、使用TreeSet建议加上泛型,以保证集合中的元素一致
3、和HashSet一样,已经存入集合的实例变量,不要进行二次修改,这将导致它与其他对象的大小顺序发生改变,但TreeSet集合不会再次调整它们的顺序
4、不可以添加相同对象,自定义类必须重写equals以及hashcode
5、比较是comparable不是equals,所以不能代替equals来判断是否为同一个元素
以上均为本人个人观点,借此分享,希望能和大家一起进步。如有不慎之处,劳请各位批评指正!鄙人将不胜感激并在第一时间进行修改!

















 3651
3651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











