






记录学习微服务
表单提交DTO 接口返回VO
单体拆成 -> 多的小
文档地址:课程说明 - 飞书云文档 (feishu.cn)
学习内容
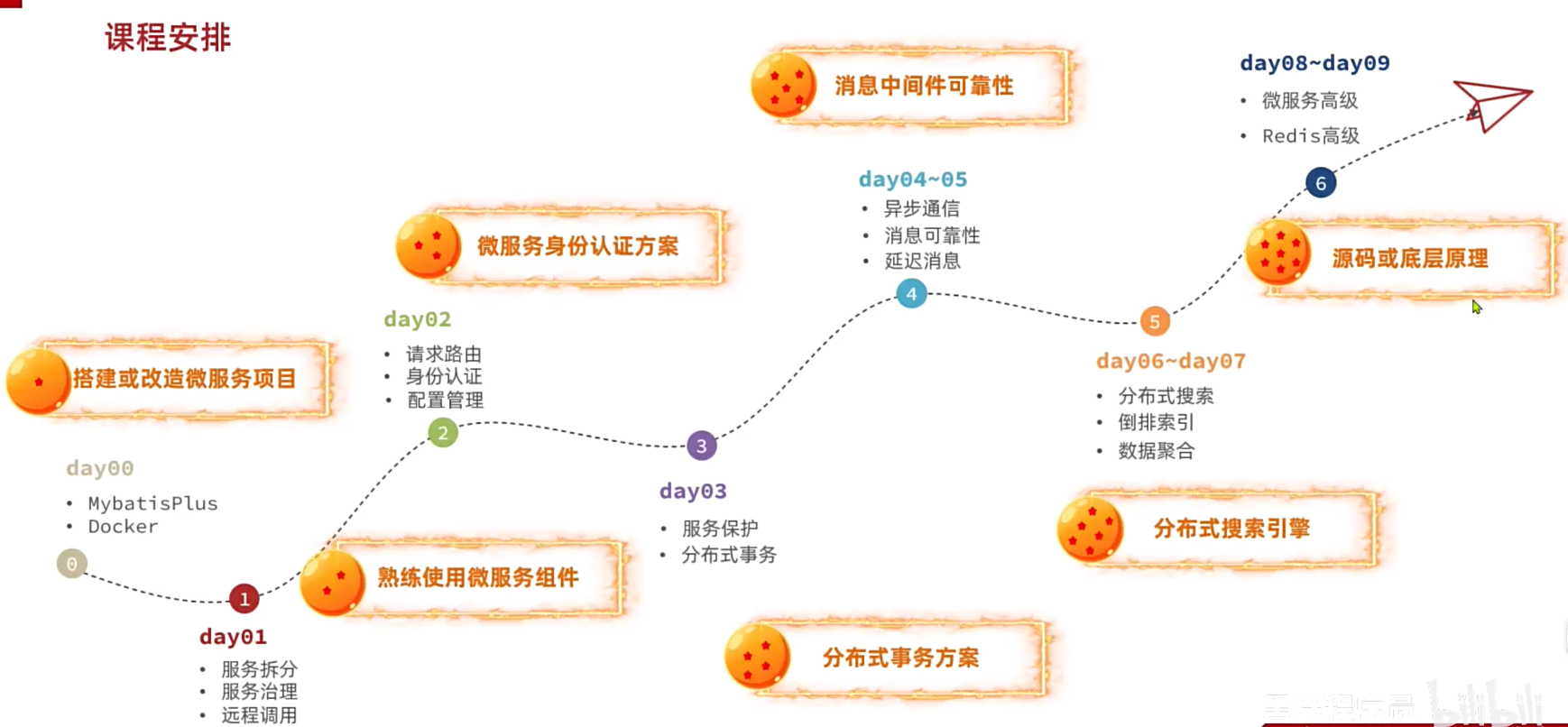
端口
黑马商城:localhost:18080
Nacos:8848
Seata:7099
Sentinel:8090
RabbitMQ:15672
ES:9200
kibana:5601
一.MybatisPlus
无侵入、方便快捷
MybatisPlus的依赖包含Mybatis依赖,所以引入一个就行
快速入门
-
引入MybatisPlus依赖
-
定义Mapper
为了简化单表CRUD,MybatisPlus提供了一个基础的BaseMapper接口,其中已经实现了单表的CRUD(在mapper文件中继承)
常见注解
@TableName:标识实体类对应的表
@TableId:标识实体类中的主键字段
@TableField:标识实体类中的普通字段信息
核心功能
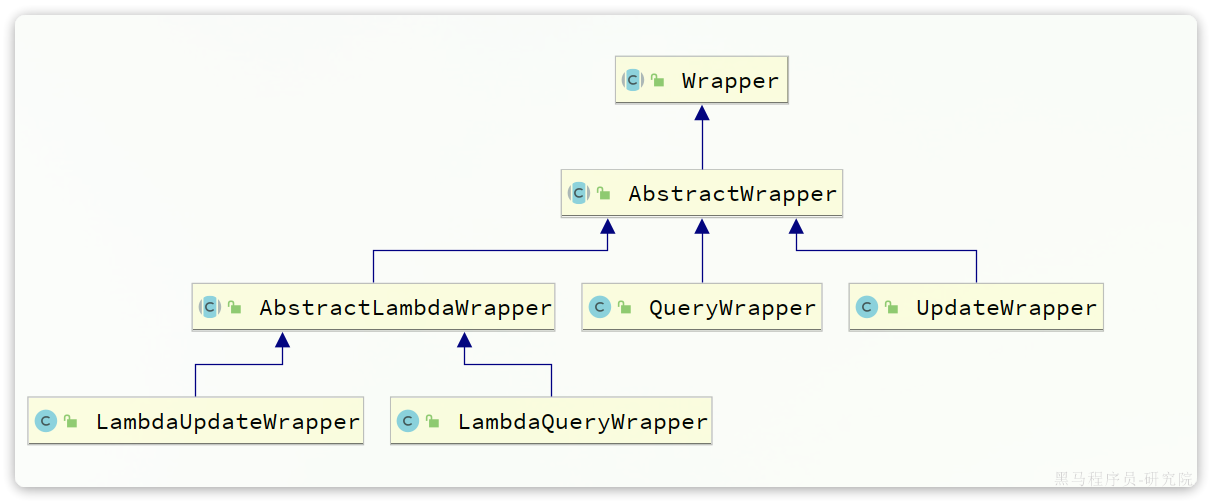
条件构造器
1.QueryWrapper
userMapper.update(user, wrapper);
第一个参数是对象,第二个是规则
2.UpdateWrapper
3.LambdaQuaryWrapper
比较灵活,不会写死
条件构造器的用法:
•QueryWrapper和LambdaQueryWrapper通常用来构建select、delete、update的where条件部分
•UpdateWrapper和LambdaUpdateWrapper通常只有在set语句比较特殊才使用
•尽量使用LambdaQueryWrapper和LambdaUpdateWrapper,避免硬编码
自定义SQL
目的:在业务层写sql语句不符合企业规范,sql语句最好维持在持久层
利用MyBatisPlus的Wrapper来构建复杂的Where条件,然后自己定义SQL语句中剩下的部分。
Service接口
MP不仅提供了BaseMapper,还提供了通用的Service接口IService
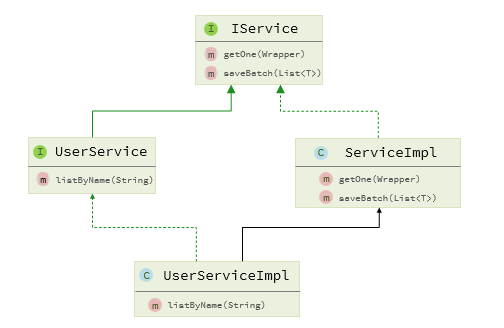
IService中还提供了Lambda功能来简化我们的复杂查询及更新功能
lambdaQuery()
lambdaUpdate()
扩展功能
代码生成
基础的Mapper、Service、PO代码相对固定,重复编写也比较麻烦->使用 MyBatisPlus
Db:MybatisPlus提供一个静态工具类,可以帮助实现CRUD
逻辑删除:在实体类中添加 deleted字段
插件功能
分页功能:PaginationInnerInterceptor
二.Docker
安装docker
黑马的安装会有问题,找别的博主的安装
常见命令
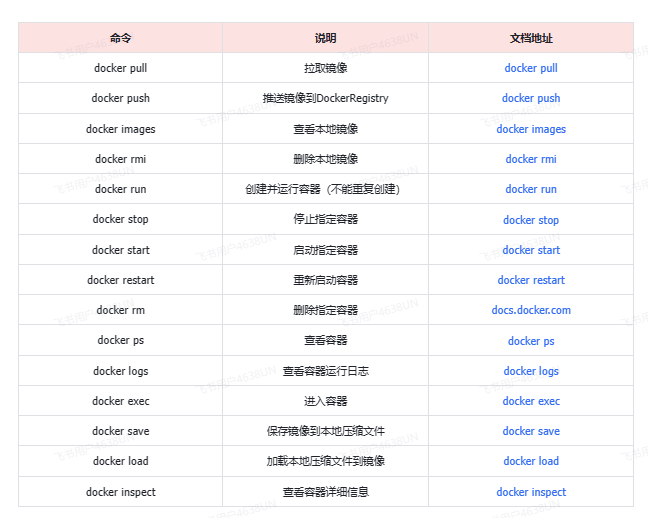
加载镜像tar包:docker load -i yolov5-v6.2.tar
镜像:基础环境、依赖、应用本身、运行配置等文件的集合体

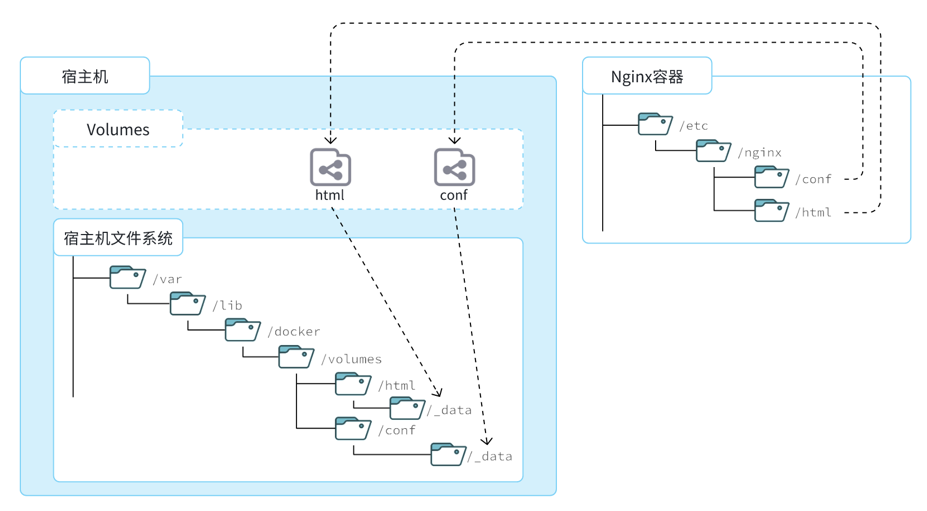
数据卷
数据卷(volume)是一个虚拟目录,是容器内目录与宿主机目录之间映射的桥梁。
作用:实现挂载 将容器与宿主机联系起来
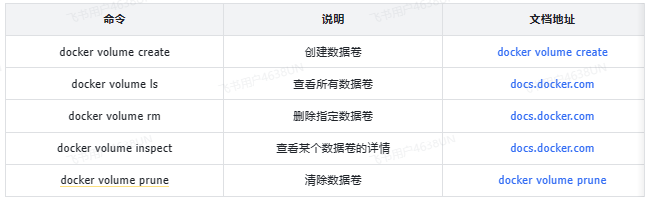
相关命令
Dockerfile:记录镜像结构的文件
DockerCompose:帮助我们实现多个相互关联的Docker容器的快速部署
镜像是一个只读模版,容器是由镜像实例化而来
三.微服务01
什么是微服务:就是将单体架构中的功能模块从单体应用中拆分出来,独立部署为多个服务。
SpringCloud:是一套微服务框架(微服务组件的集合)
RPC:远程调用(跨服务)
Jemeter:模拟用户请求的软件
远程调用:不同的微服务之间进行查询
注册中心三部分:注册中心 服务提供者 服务调用者

Nacos:是一种注册中心的框架,其他的注册中心框架:Eureka
由于远程调用的代码过于复杂,所以引入OpenFeign
避免重复编码的方法就是抽取
四.微服务02
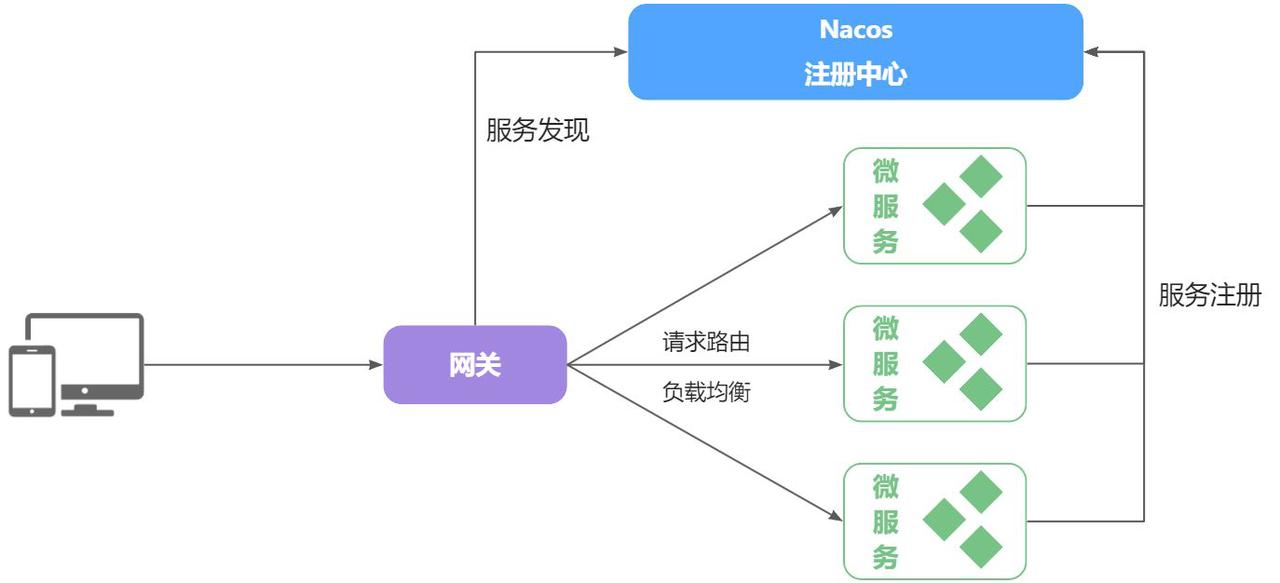
网关路由
黑马商城被拆分为5个微服务:
用户服务 商品服务 购物车服务 交易服务 支付服务
网关作用:对数据经行路由和转发 对数据的安全进行校验
SpringCloudGateway:SpringCloud中实现网关的方式
网关路由示意图:
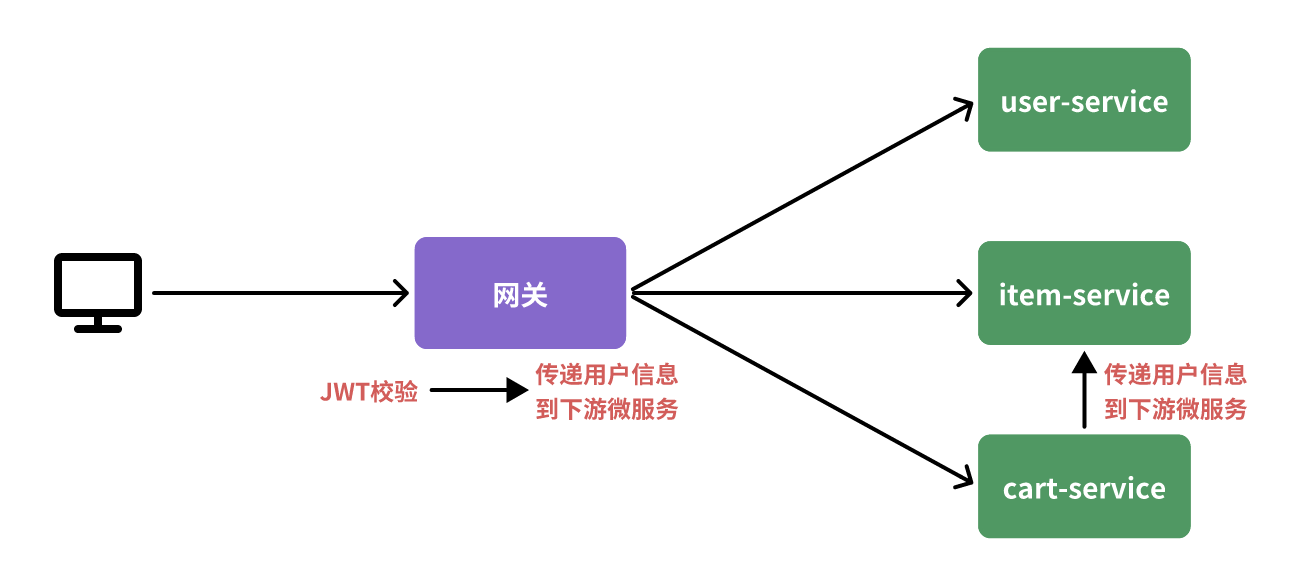
网关登录校验
网关登录校验示意图:
Netty:是一个基于NIO(非阻塞I/O)的开源网络框架 作用:简化网络编程
网关过滤器链:使用GlobalFilter 全局过滤器链 比较简单
微服务如何获取用户信息?
微服务从请求头中获取登录用户的信息,利用SpringMVC的拦截器来实现用户信息获取,并存入ThreadLocal,方便下游服务使用。
配置管理
配置共享
Nacos不仅仅具备注册中心的功能,还有配置管理的功能(抽取重复的配置)
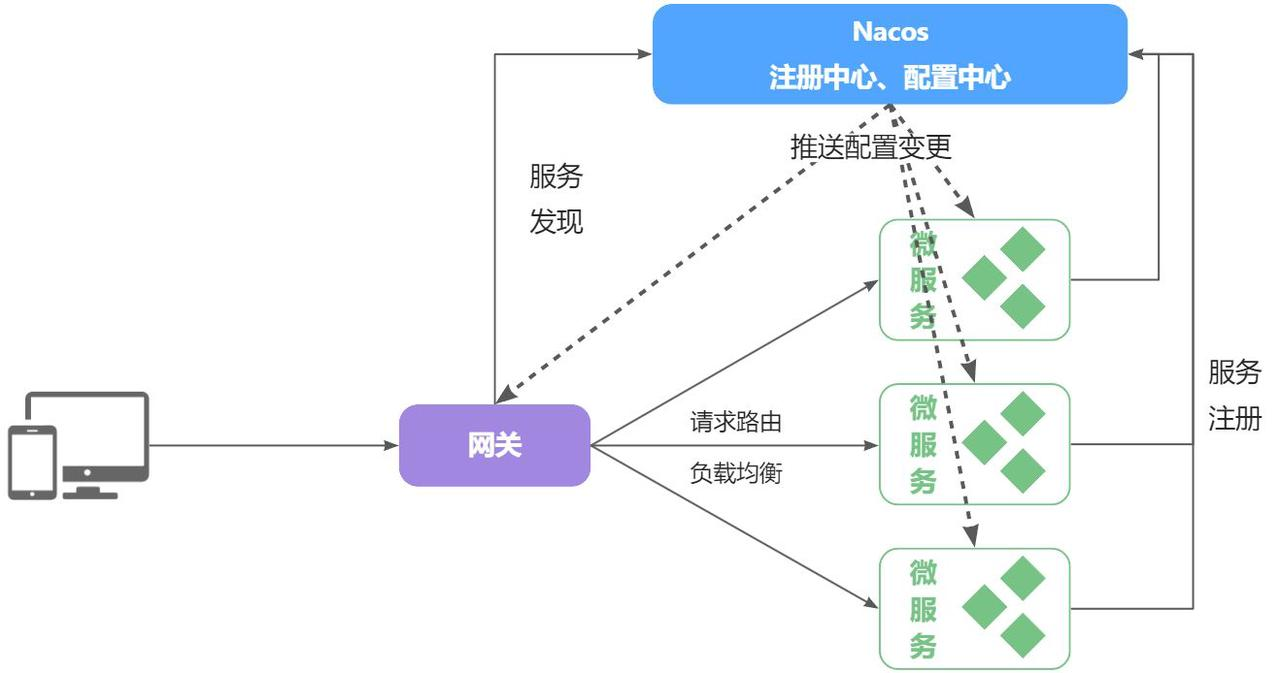
配置热更新
动态路由
步骤
-
创建ConfigService,目的是连接到Nacos
-
添加配置监听器,编写配置变更的通知处理逻辑
Json比较好读取
五.服务保护和分布式事务
服务保护
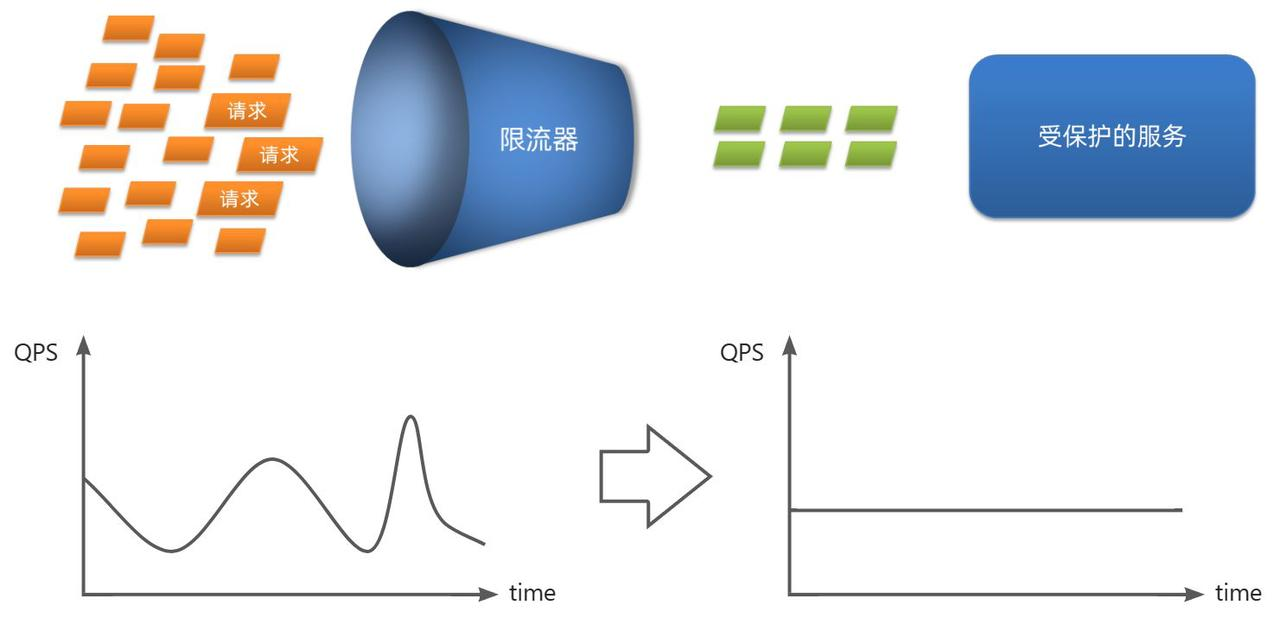
雪崩问题(级联失败问题):一个微服务出现故障,导致整个集群故障。
保护的三种方案:
1.请求限流
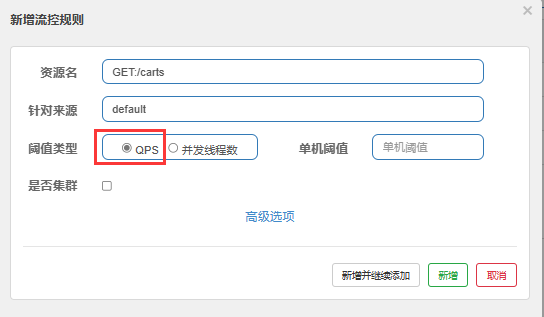
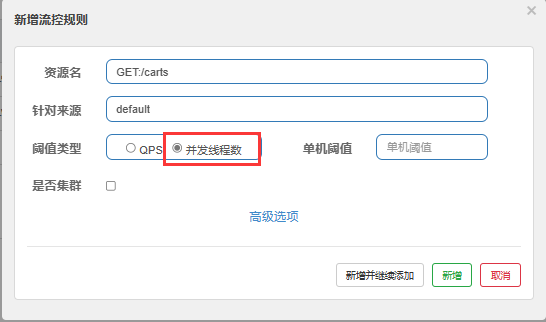
2.线程隔离
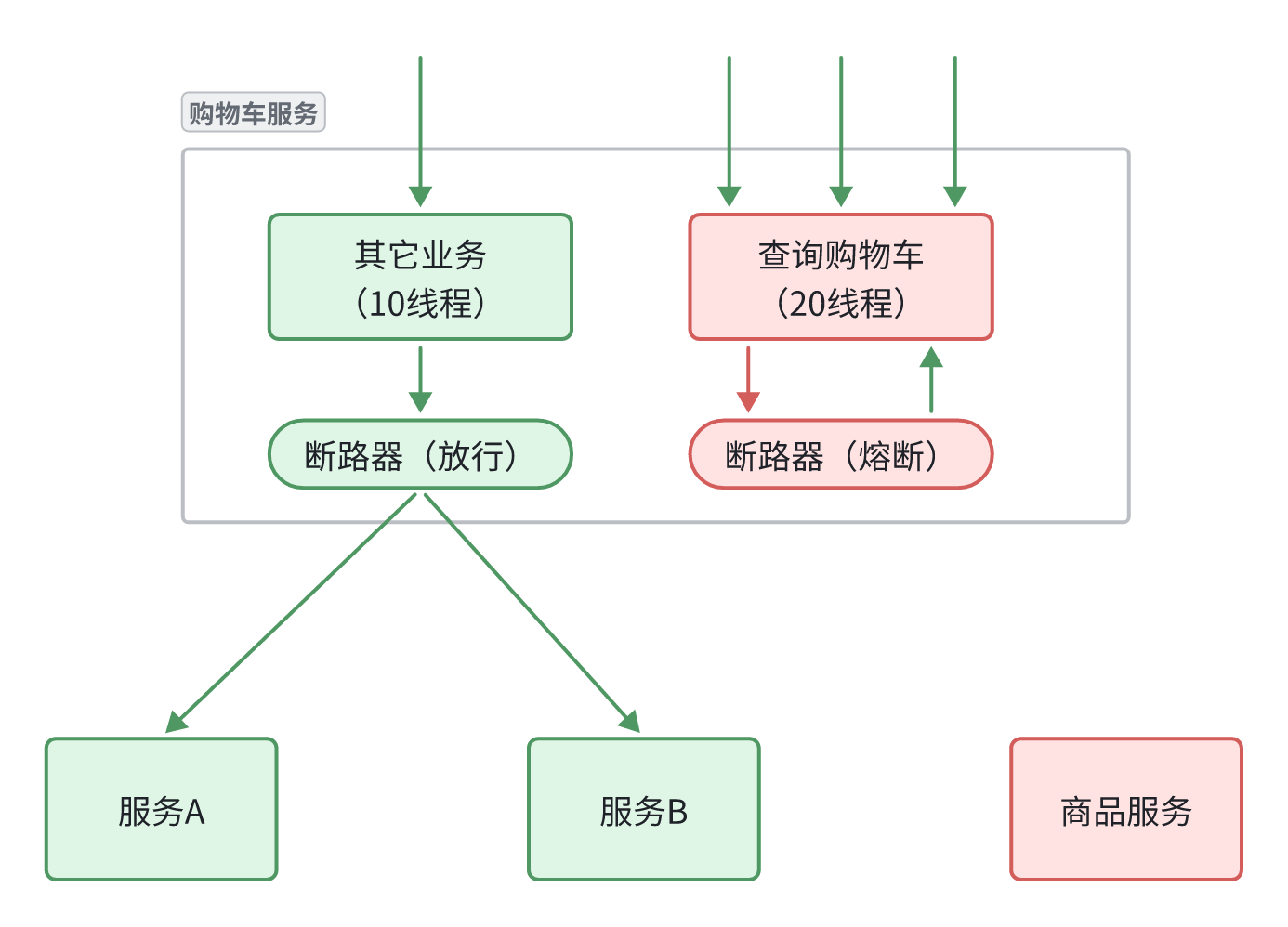
3.服务熔断
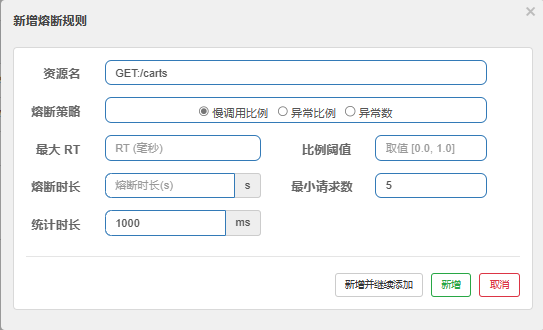
Sentinel:实现微服务保护的一款框架 阿里巴巴开源
启动命令
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jarJemeter:模拟用户发送HTTP请求的工具
编写降级逻辑(不直接报错,给用户更好的体验):使用FallbackFactory
熔断器结构
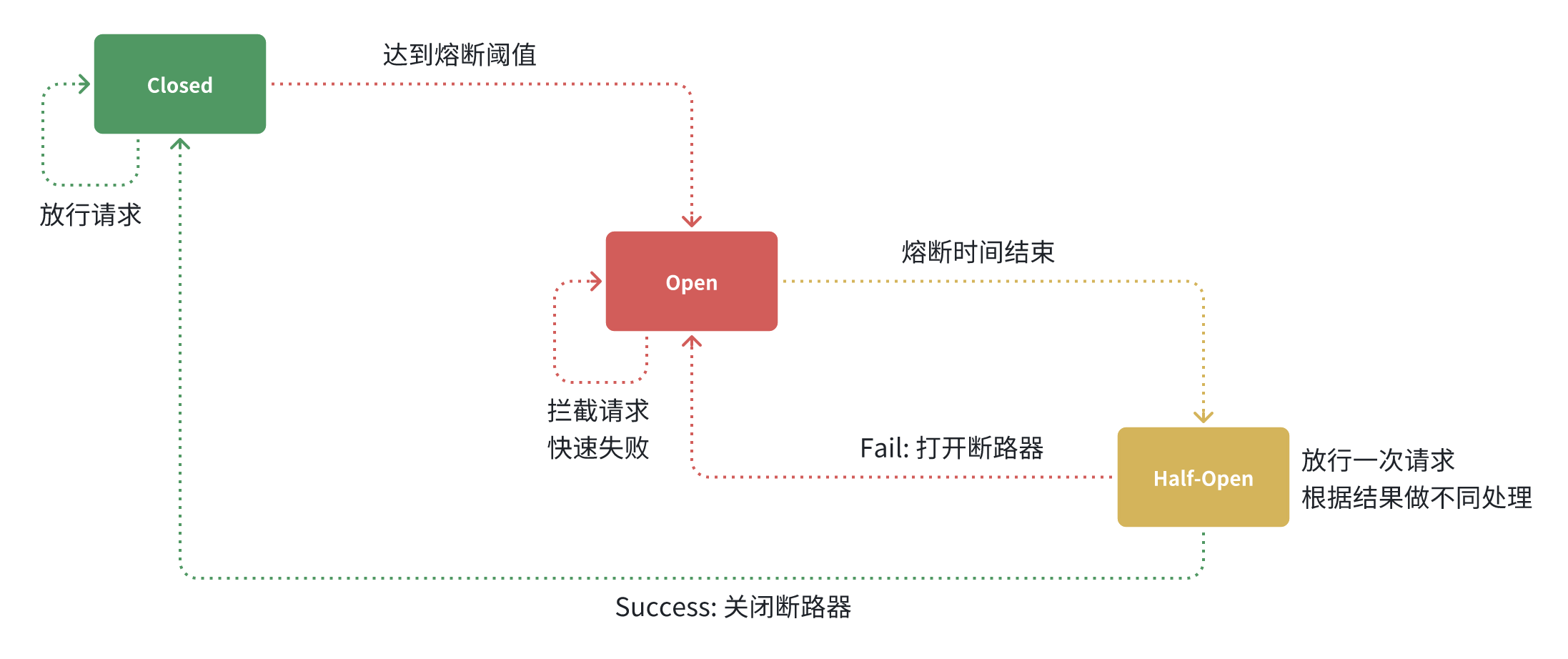
分布式事务
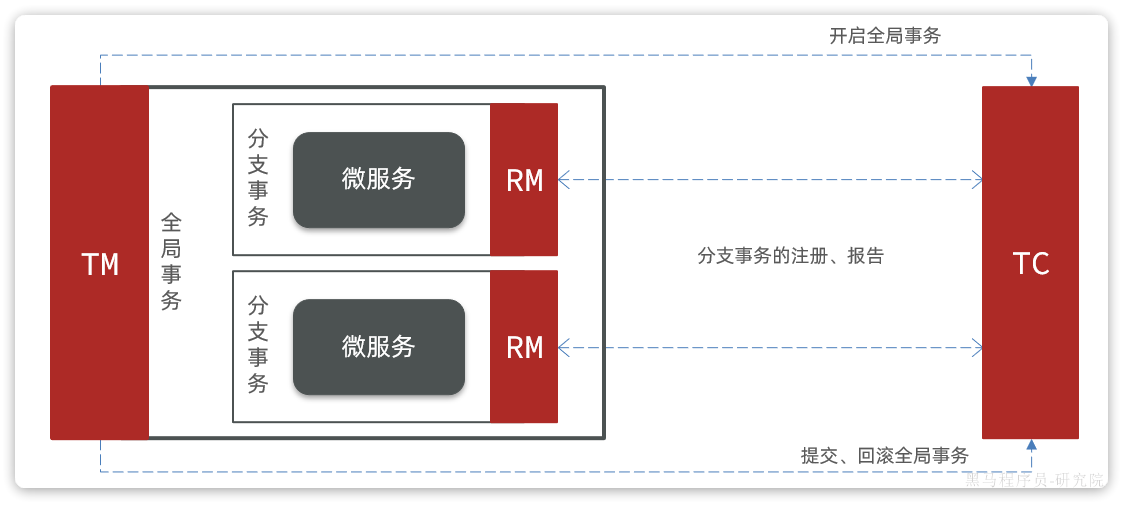
Seata:解决分布式事务的框架 阿里巴巴
Seata工作架构(三个重要角色):
TC:事务协调者
TM:事务管理者 告诉TC代码从哪里开始哪里结束
RM:资源管理器
undo_log:数据快照(备份用的)
Seata支持两种常见的分布式事务解决方案:
XA AT(90%最常用)
XA
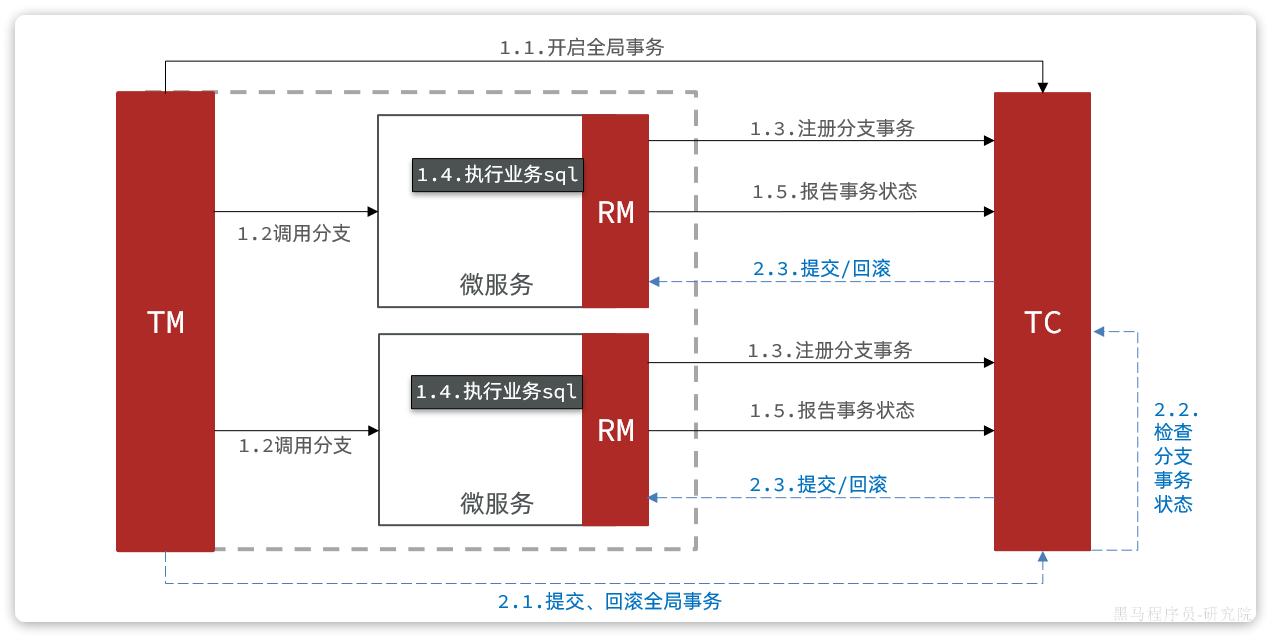
RM一阶段的工作:
-
注册分支事务到
TC -
执行分支业务sql但不提交
-
报告执行状态到
TC
TC二阶段的工作:
-
TC检测各分支事务执行状态-
如果都成功,通知所有RM提交事务
-
如果有失败,通知所有RM回滚事务
-
RM二阶段的工作:
-
接收
TC指令,提交或回滚事务
AT
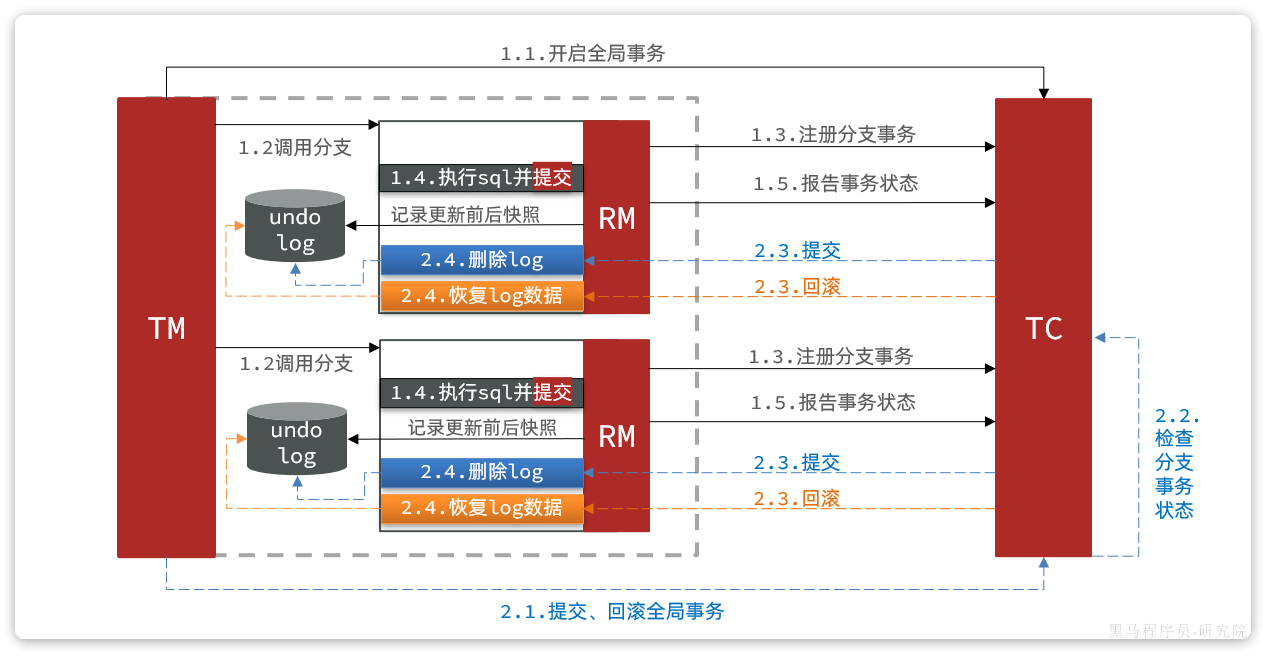
阶段一RM的工作:
-
注册分支事务
-
记录undo-log(数据快照)
-
执行业务sql并提交
-
报告事务状态
阶段二提交时RM的工作:
-
删除undo-log即可
阶段二回滚时RM的工作:
-
根据undo-log恢复数据到更新前
XA与AT的区别:
-
XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。 -
XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。 -
XA模式强一致;AT模式最终一致
六.MQ基础
认识MQ
同步调用:以前的调用都是用的OpenFeign
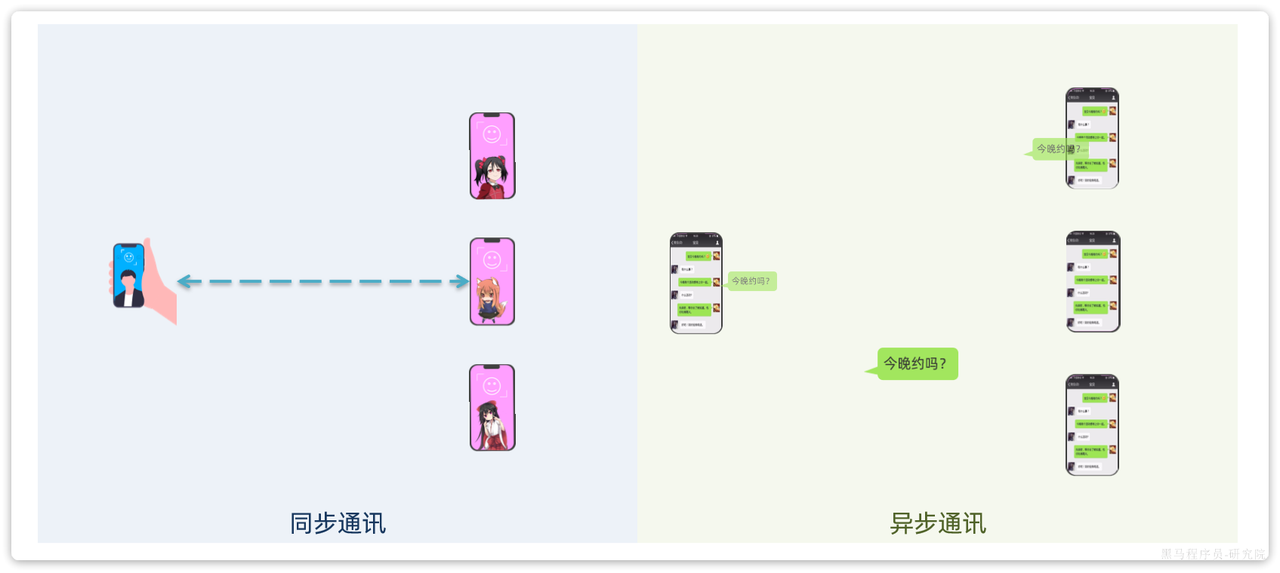
同步调用缺点:拓展性差 性能下降 级联失败(雪崩)
消息代理:Broker
异步调用:MQ 外卖员-外卖柜-你
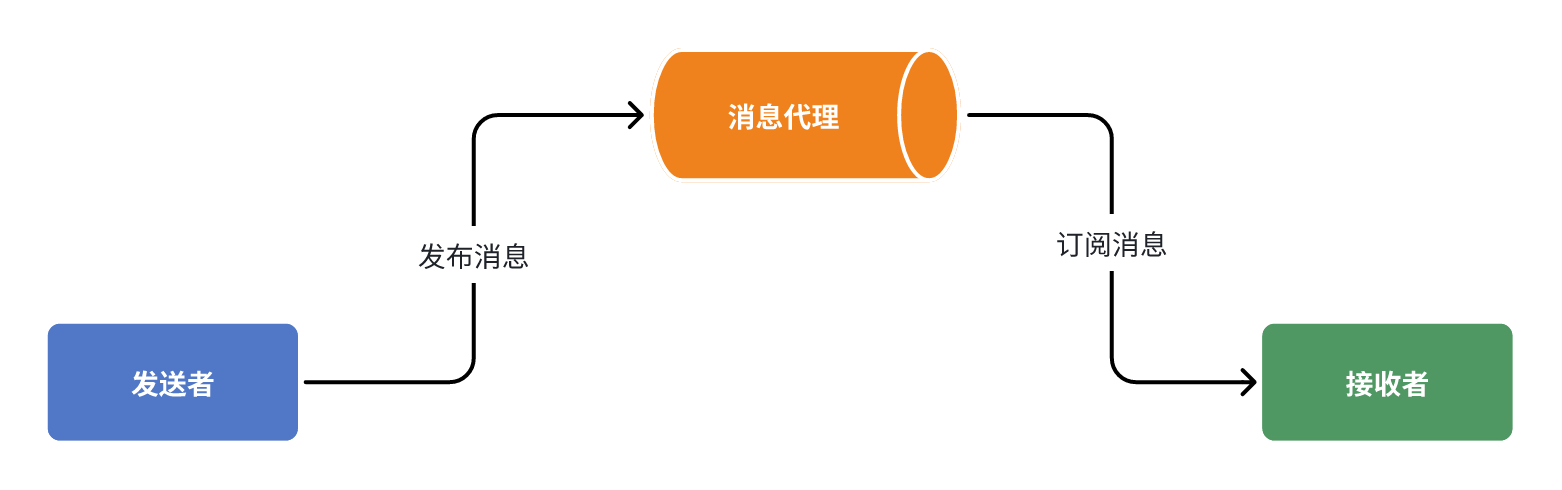
异步代理优势:
低耦合 性能好 拓展强 隔离高
几种MQ的对比:
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
国内使用最多的是RabbitMQ
RabbitMQ
RabbitMQ对用的架构图:

-
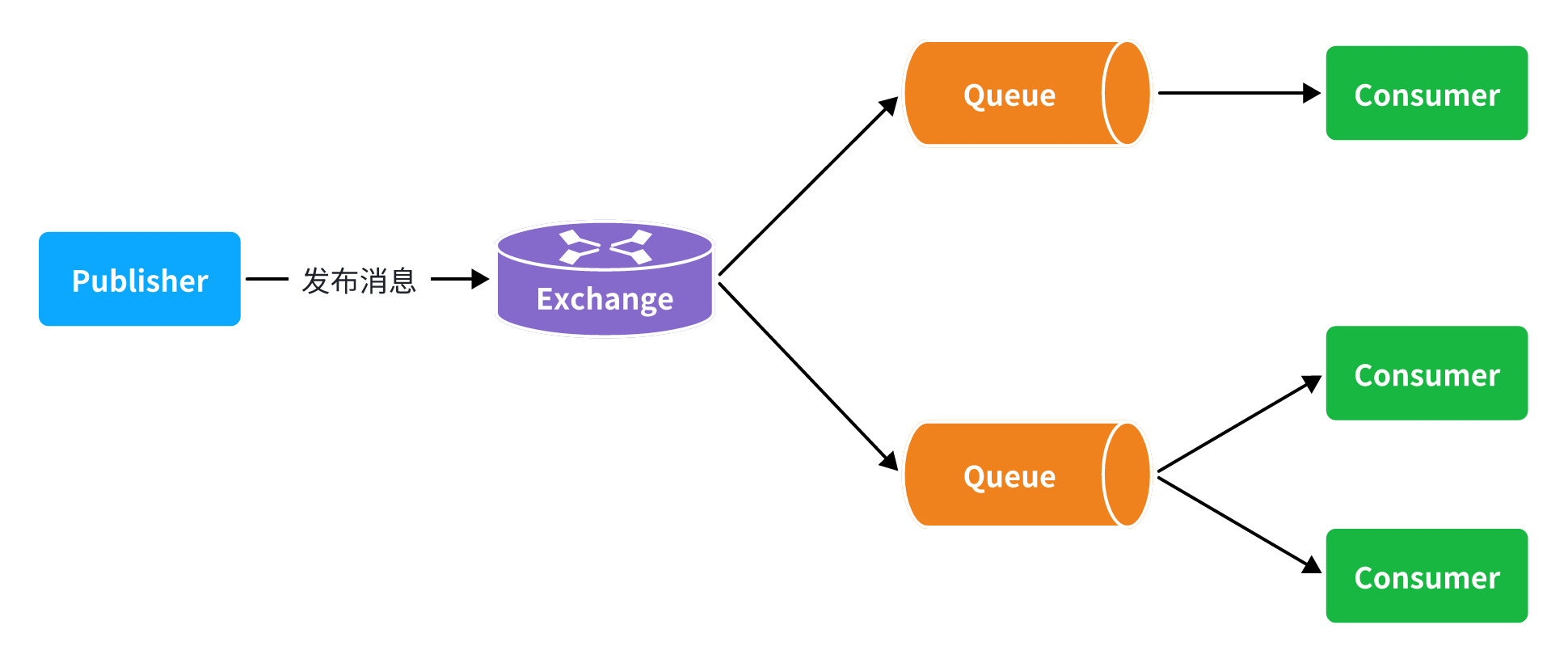
exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。 -
virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
对于小型企业来说,出于成本考虑,只会搭建一套MQ集群
SpringAMQP
以前新增交换机和队列都是在RabbitMQ里面,AMQP是基于编程的方式来创建的。
SpringAMQP提供了三个功能:
-
自动声明队列、交换机及其绑定关系
-
基于注解的监听器模式,异步接收消息
-
封装了RabbitTemplate工具,用于发送消息
WorkQueues模型
让多个消费者绑定到一个队列,共同消费队列中的消息。
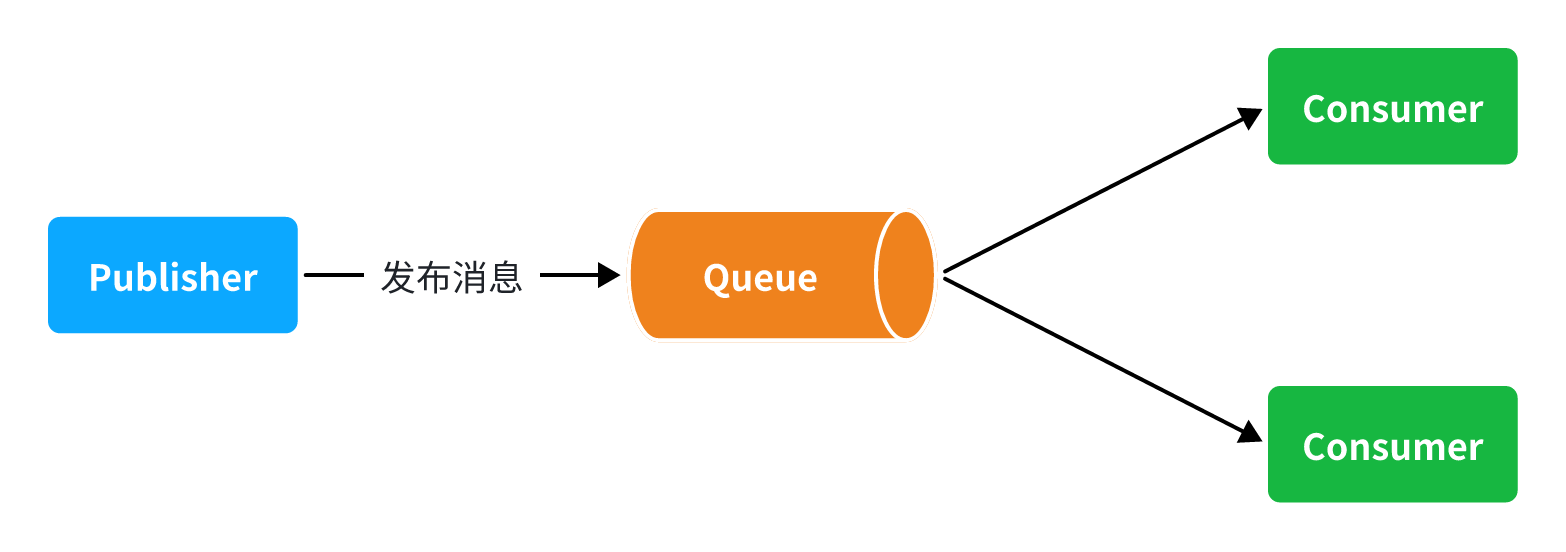
缺点:消息是平均分配给每个消费者,并没有考虑到消费者的处理能力
设置能者多劳
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息交换机只负责转发消息,不具备存储消息的能力
交换机的类型
Fanout:广播
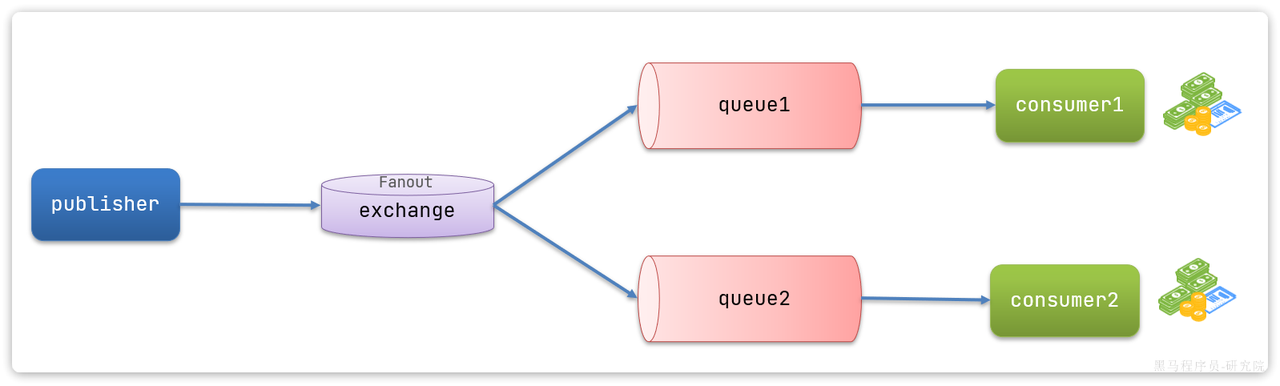
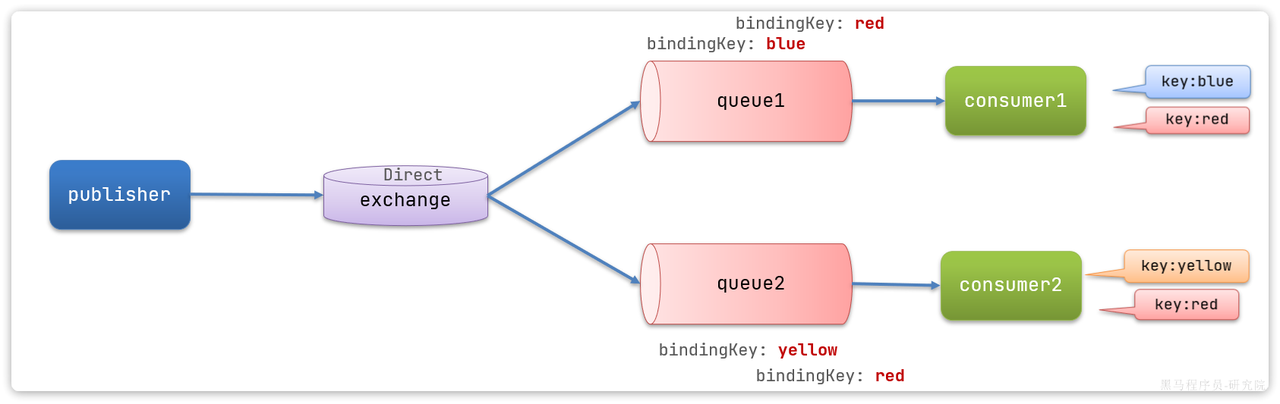
Direct:基于Key,发送给订阅了消息的队列
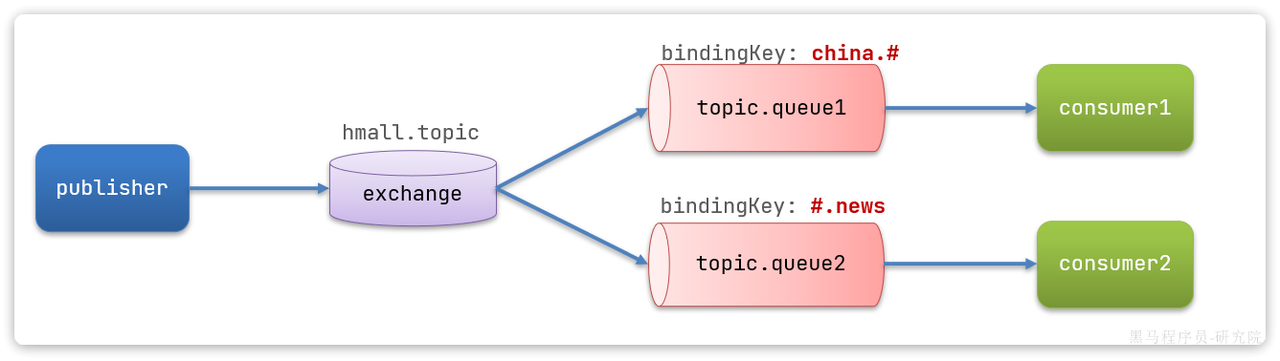
Topic:也是基于Key,只不过Key可以使用通配符
声明队列和交换机:
Exchange Queue Binding
以上方法比较复杂,采用注解的方式来声明
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "hmall.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue1(String msg){
System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】");
}消息转换器:jackson2JsonMessageConverter
七.MQ高级
确保消息真的成功发出去,在三个环节进行验证
避免数据不一致
发送者的可靠性
不建议开启:比较耗性能
生产者重试机制
生产者确认机制
MQ的可靠性
数据持久化(Durable):
交换机持久化
队列持久化
消息持久化
LazyQueue惰性队列:
-
接收到消息后直接存入磁盘而非内存(避免PagrOut消耗时间)
-
消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载)
-
支持数百万条的消息存储
消费者的可靠性
消费者的确认机制
三种回执:
-
ack:成功处理消息,RabbitMQ从队列中删除该消息
-
nack:消息处理失败,RabbitMQ需要再次投递消息
-
reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
幂等性:执行一次和执行多次,效果是一样的(例如:绝对值符号)
两种方案:
-
唯一消息ID
-
业务状态判断(更推荐)
兜底方案:让交易服务自己主动去查询支付状态,这样即便支付服务的MQ通知失败,我们依然能通过主动查询来保证订单状态的一致。

延迟消息
用插件DelayExchange实现
声明延迟交换机:delayed = "true"
不建议设置延迟时间过长的延迟消息:会带来较大的CPU开销
八.Elasticsearch
认识Elasticsearch
完整的技术栈包括:
-
Elasticsearch:用于数据存储、计算和搜索
-
Logstash/Beats:用于数据收集
-
Kibana:用于数据可视化
整套技术栈被称为ELK,经常用来做日志收集、系统监控和状态分析等等:

ELK作用:日志收集、系统监控、状态分析
kibana:可视化展示ES
倒排索引
MySQL:正向索引 正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
Elasticsearch:反向索引 解决根据部分词条模糊匹配的问题
重要概念

倒排索引,无论是词条、还是文档id都建立了索引,速度非常快,无需全表扫描
各自的优点:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
企业中往往是两者结合使用:
-
对安全性要求较高的写操作,使用mysql实现
-
对查询性能要求较高的搜索需求,使用elasticsearch实现

IK分词器
可以把新出现的词语放在拓展词典中
索引库操作
PUT GET DELETE
索引库一旦创建就无法修改mapping,但是可以新增
文档操作
修改文档:
-
全量修改:直接覆盖原来的文档 PUT /{索引库名}/_doc/文档id
-
局部修改:修改文档中的部分字段 POST /{索引库名}/_update/文档id
批处理:POST _bulk
RestClient操作文档
新增文档:index(批量新增)
查询文档:get
删除文档:delete
修改文档:update
九.Elasticsearch02
DSL查询
叶子查询
全文检索查询(分词):match mutil_match
精确查询(不分词):ids term range
默认查询页数只有10条
复合查询
bool查询:
-
must:必须匹配每个子查询,类似“与”
-
should:选择性匹配子查询,类似“或”
-
must_not:必须不匹配,不参与算分,类似“非”
-
filter:必须匹配,不参与算分
出于性能考虑,与搜索关键字无关的查询尽量采用must_not或filter逻辑运算,避免参与相关性算分。
排序:search after
一般我们采取普通分页
高亮标签:<em> 由服务端提供
RestClient查询
关键API
request.source():包含query、sort、from、size、highlight

QueryBuilders:叶子查询、复合查询

数据聚合
常见的三类聚合:桶(Bucket)、度量(Metric)、管道(pipeline)
参加聚合的字段必须是:keyword、日期、数值、布尔类型 (要是不能分词的字段)
聚合三要素:名称、类型、字段
十.Redis面试篇
Redis主从
为什么要用主从:单点的redis并发有限

主从同步原理
全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave

同一个集群中的replid是一样的
如果master的offset超出了slave的offset那就无法做增量同步了,只能做全量同步
Redis哨兵
保障集群的高可用性,监控集群状态、

哨兵作用:
集群监控
故障恢复:一个master坏了,哨兵制定一个slave当master
状态通知:告知天下
状态监控:主观下线、客观下线

选master规则:
选断开时间短的
选优先级高的(数值越小越高)
选offset大的(数据相差小)
判断节点的id(id越小优先级越高)
分片集群
有多个redis集群组成

redis采用的是散列插槽(hash slot)的方式实现数据分片
Redis数据结构
常见物种数据结构:String Hash List Set SortedSet
不管是任何一种数据类型,最终都会封装为RedisObject格式:

ZSET的编码方式有:SkipList
SkipList(跳表):首先他是有顺序的链表,节点包含多个指针,每个指针的跨度不一样
SortedSet内存图
typedef struct zset {
dict *dict; // dict,底层就是HashTable
zskiplist *zsl; // 跳表
} zset;
内存回收
当内存达到上线,无法再存更多的数据,就会进行回收
1.内存过期策略(处理过期Key)
如何删除过期的key
- 惰性删除
每次访问key时判断当前key有没有设置过期时间,如果过期了就删除
- 周期删除
通过一个定时任务,周期行的抽样部分过期的key,然后删除
执行周期有两种:
SLOW模式
FAST模式
2.内存淘特策略
LRU:最近最久未使用
LFU:最少频率使用(官方推荐使用)
缓存问题
缓存数据的一致性
目前企业用的最多的缓存模型是:Cache Aside
-
查询时:命中则直接返回,未命中则查询数据库并写入缓存
-
更新时:更新数据库并删除缓存,查询时自然会更新缓存
先更新数据库,再删除缓存(前者速度慢,先删除缓存的话会造成数据不一致)
缓存穿透
访问一个数据缓存中不存在,数据库中也不存在

解决办法:
缓存空值:实现简单,但消耗内存
布隆过滤器:用于检索一个元素是否在一个集合中,可能会误判


缓存雪崩
定义:同一时间段内,有大量请求到达数据库,带来巨大压力

解决方法:给缓存key设置不同的TTL redis集群
缓存击穿(热点key问题)
一个热点的key突然失效,导致无数的请求在一瞬间给数据库带来巨大的压力
解决方案:互斥锁 逻辑过期
十一.微服务面试篇
分布式事务
定义:不在单体项目下,跨服务的
解决办法:Seata的AT模式
CAP定理:
-
Consistency(一致性)
-
Availability(可用性)
-
Partition tolerance (分区容错性)
注册中心
Eureka:是Netflix(网飞)公司开源的一个服务注册中心组件
Nacos
综上,Eureka和Nacos的共同点有:
-
都支持服务注册发现功能
-
都有基于心跳的健康监测功能
-
都支持集群,集群间数据同步默认是AP模式,即最全高可用性
Eureka和Nacos的区别有:
-
Eureka的心跳是30秒一次,Nacos则是5秒一次
-
Eureka如果90秒未收到心跳,则认为服务疑似故障,可能被剔除。Nacos中则是15秒超时,30秒剔除。
-
Eureka每隔60秒执行一次服务检测和清理任务;Nacos是每隔5秒执行一次。
-
Eureka只能等微服务自己每隔30秒更新一次服务列表;Nacos即有定时更新,也有在服务变更时的广播推送
-
Eureka仅有注册中心功能,而Nacos同时支持注册中心、配置管理
远程调用
微服务之间的调用都是用OpenFeign完成的
Ribbon:一个实现负载均衡的组件(已弃用)
现在已经弃用了,改用Spring Cloud LoadBalancer
服务保护
限流方法:滑动窗口计数法 令牌桶算法 漏桶算法
Hystix和Sentinel都支持线程隔离
线程隔离有两种方法:
线程池隔离(会创建线程池,额外开销,性能一般,隔离性强)
信号量隔离(性能较好,隔离性一般)
而Hystix两种都支持,默认是基于线程池隔离
Sentinel的线程隔离是基于信号量隔离实现的
sentinel中采用的计数器算法就是滑动窗口计数算法。
Sentinel中的热点参数限流正是基于令牌桶算法实现的
sentinel中的限流中的排队等待功能正是基于漏桶算法实现的。
令牌桶算法:有令牌的请求才能处理

漏桶算法:和令牌桶相似 但是在设计上更适合应对并发波动较大的场景
简单来说就是请求到达后不是直接处理,而是先放入一个队列。而后以固定的速率从队列中取出并处理请求。
优势:流量整理

Sentinel限流与Gateway限流的差别
















 2777
2777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









