







(此文章是记录本人对知识理解的随手笔记,内容不肯定百分百正确,如有错误望指出并谅解)
本文章主要讲如何利用lxml库和requests库写python爬虫代码
1、先看一遍代码(记得看注释)
#导入需要的库
import requests
from lxml import etree
#设置需要访问的URL地址
url='https://blog.csdn.net/m0_51756263/article/details/125700087'
#设置头部中的键值对
headers={
#一般网站的服务器会通过查询User-Agent这个键值对来识别是不是爬虫,所以我们可以更改User-Agent这个键值对的值来仿造是真人在浏览网站,我在代码中用的值是windows服务器下chrome的值
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763'
}
#对网站发送get请求
spider_requests=requests.get(url=url,headers=headers)
#用spider_requests.text获取字符串格式的网页,用etree.HTML()可以将字符串格式的网页转换成_Element对象
html= etree.HTML(spider_requests.text)
#根据xpath语法取出所要查询的值
string_xpath='''//div/h1[@class='title-article']/text()'''
response=html.xpath(string_xpath)
#打印返回值
print(response)在下图中我会讲解怎么拿取自己现在所用的浏览器的User-Agent的值,因为不同操作系统中的不同浏览器中的不同版本的User-Agent值不一样,比如mac下的火狐浏览器的和mac下的ie浏览器和windows下的狐火浏览器的User-Agent值不一样
User-Agent的值可以通过浏览器的F12键调出开发者工具来查看,如下图所示,点击网络,然后ctrl+R刷新一下网页,然后把滚动条拉到最上面,找到一个类型为document,大小为几十KB的文件,单击一下这个文件就会出现如下下图的页面。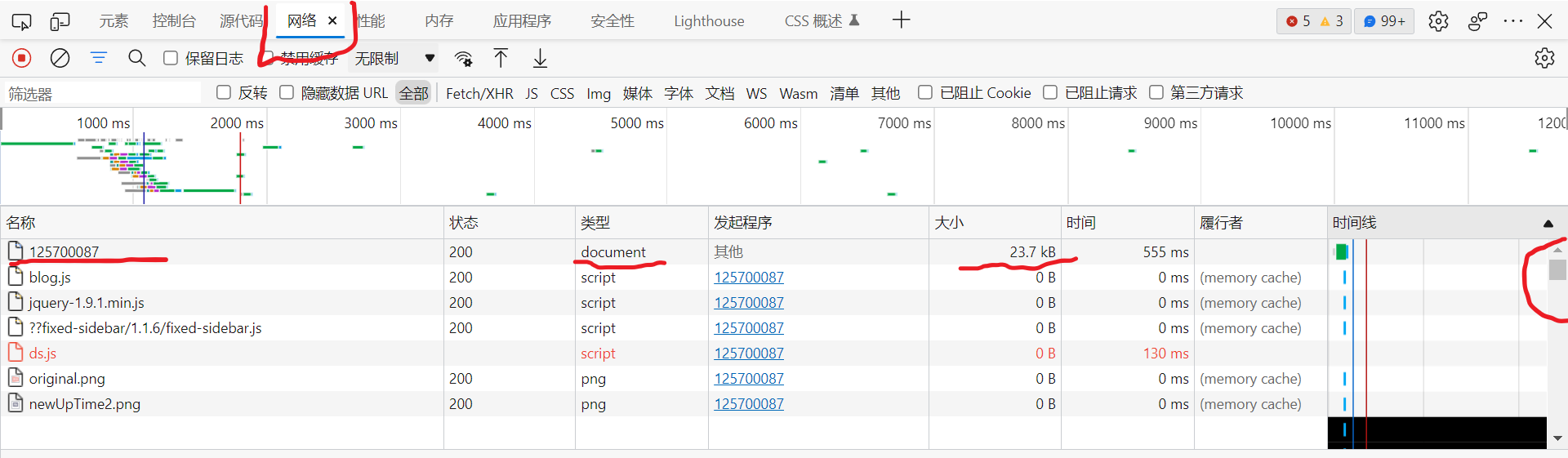
然后在标头中找到User-Agent键值对,通过User-Agent后面的值可以看到我所用的操作系统为windows,用的浏览器为Chorme浏览器,浏览器的版本号为103.0.1264.49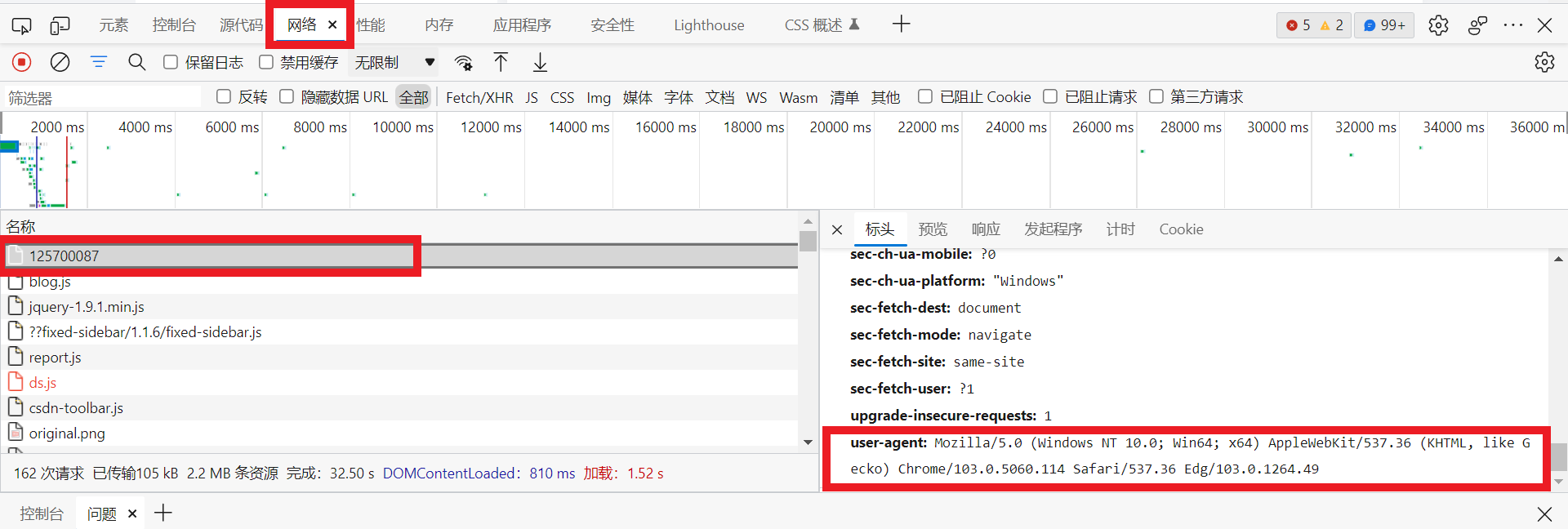
如下图我们可以更改string_xpath的值来更改xpath语法来得到我们想在网页中获取的文本
如下图,我们想获取图中的一段文字“sql注入中的union联合查询,union select 1,2,3”
则将string_xpath的值改为 //div/h1[@class='title-article']/text()
意思是查询所有div元素下有h1元素的,且h1元素中有class属性,且class属性的值为 title-article ,然后获取文本,下图可以看到运行完python程序后获取到的结果















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









