







1.图片处理
首先遍历一个本地文件夹中的所有图片,对它们按需进行等比例缩放、可选高斯模糊处理,并以指定质量保存到另一个目录,同时保持原有的子目录结构。参考代码如下:
from PIL import Image, ImageFilter
import os
def process_image(input_path, output_path,
target_size=(512, None), # 目标尺寸(宽, 高)
blur_radius=0, # 高斯模糊半径(0 表示不模糊)
quality=30): # 保存质量(仅对 JPEG 有效)
try:
# 打开图片
with Image.open(input_path) as img:
# 保持宽高比调整尺寸
original_width, original_height = img.size
aspect_ratio = original_width / original_height
new_width, new_height = target_size
if new_width is None and new_height is None:
# 都为 None 时不改变尺寸
new_width, new_height = original_width, original_height
elif new_width is None:
new_width = int(new_height * aspect_ratio)
elif new_height is None:
new_height = int(new_width / aspect_ratio)
img = img.resize((new_width, new_height), Image.LANCZOS)
# 应用高斯模糊
if blur_radius > 0:
img = img.filter(ImageFilter.GaussianBlur(blur_radius))
# 统一转换为 RGB(去除 Alpha 通道或其它模式)
img = img.convert("RGB")
# 确保输出目录存在
output_dir = os.path.dirname(output_path)
os.makedirs(output_dir, exist_ok=True)
# 根据后缀保存
ext = os.path.splitext(output_path)[1].lower()
if ext in ('.jpg', '.jpeg'):
img.save(output_path, quality=quality)
elif ext == '.png':
# PNG 本身支持透明,但此处已经转为 RGB,可去掉 compress_level 调整压缩
img.save(output_path, optimize=True)
else:
# GIF、BMP 等按默认方式保存
img.save(output_path)
except Exception as e:
print(f"处理失败:{input_path} -> {e}")
def traverse_folder(input_dir, output_dir, **kwargs):
"""
递归遍历 input_dir,处理所有常见图片文件,
并按相对路径输出到 output_dir。
"""
for root, _, files in os.walk(input_dir):
for file in files:
if file.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')):
input_path = os.path.join(root, file)
relative_path = os.path.relpath(input_path, input_dir)
output_path = os.path.join(output_dir, relative_path)
process_image(input_path, output_path, **kwargs)
if __name__ == "__main__":
# —— 配置区域 —— #
input_folder = r"D:\study\images"
output_folder = r"D:\study\images_out1"
target_size = (512, None) # 只指定宽度,高度自动计算
blur_radius = 0 # 模糊半径,0 表示不模糊
save_quality = 30 # JPEG 保存质量(1–100)
# 批量处理
traverse_folder(
input_dir=input_folder,
output_dir=output_folder,
target_size=target_size,
blur_radius=blur_radius,
quality=save_quality
)
print("处理完成!")
结果对比: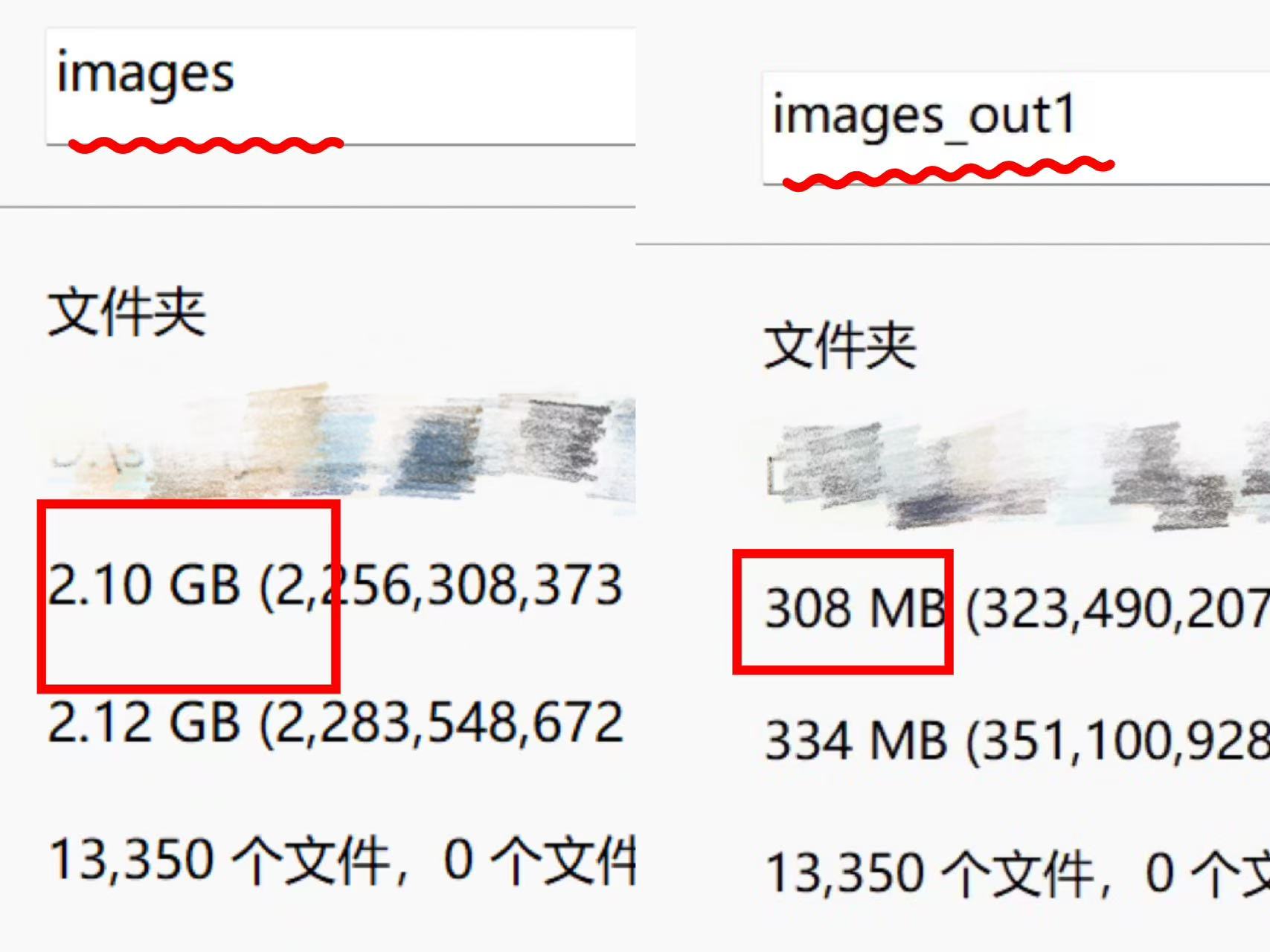
2.tsv文件转变成json文件
将数据集tsv文件转变成gemma3模型所适用的格式,tsv文件包含ID、Title、Content、Image Paths列,其中Image Paths列包含图片的名称,还有一个图片存储的文件夹。代码如下:
import csv
import json
import os
def convert_tsv_to_json(
input_tsv: str,
output_json: str,
base_image_path: str
):
data = []
with open(input_tsv, 'r', encoding='utf-8') as tsvfile:
reader = csv.DictReader(tsvfile, delimiter='\t')
for row in reader:
title = row.get("Title", "").strip()
content = row.get("Content", "").strip()
img_rel = row.get("Image Paths", "").strip()
# 改用正斜杠,避免 JSON 里 \\ 的转义
img_full = os.path.join(base_image_path, img_rel).replace("\\", "/")
data.append({
"messages": [
{
"role": "user",
"content": (
"你是一个图文摘要生成模型。"
"收到用户上传的藏文文章和对应图像后,"
"请为该文章和图像内容生成一段简洁准确的藏文摘要。"
+ "\n"
+ f"<image>{content}"
)
},
{
"role": "assistant",
"content": title
}
],
"images": img_full
})
os.makedirs(os.path.dirname(output_json), exist_ok=True)
with open(output_json, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print(f"转换完成,共生成 {len(data)} 条记录。")
if __name__ == "__main__":
convert_tsv_to_json(
input_tsv=r"D:\study\data.tsv",
output_json=r"D:\study\gemma3_data.json",
base_image_path=r"gemma3_demo_data"
)
json文件截图如下:
3.LLaMA-Factory中data文件夹
将数据集中使用的图片全部存放在gemma3_demo_data。
将自己数据集的json文件添加到data文件夹下,同时在dataset_info.json中添加数据集的信息。相关图片如下:

"gemma3_demo": {
"file_name": "gemma3_data.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
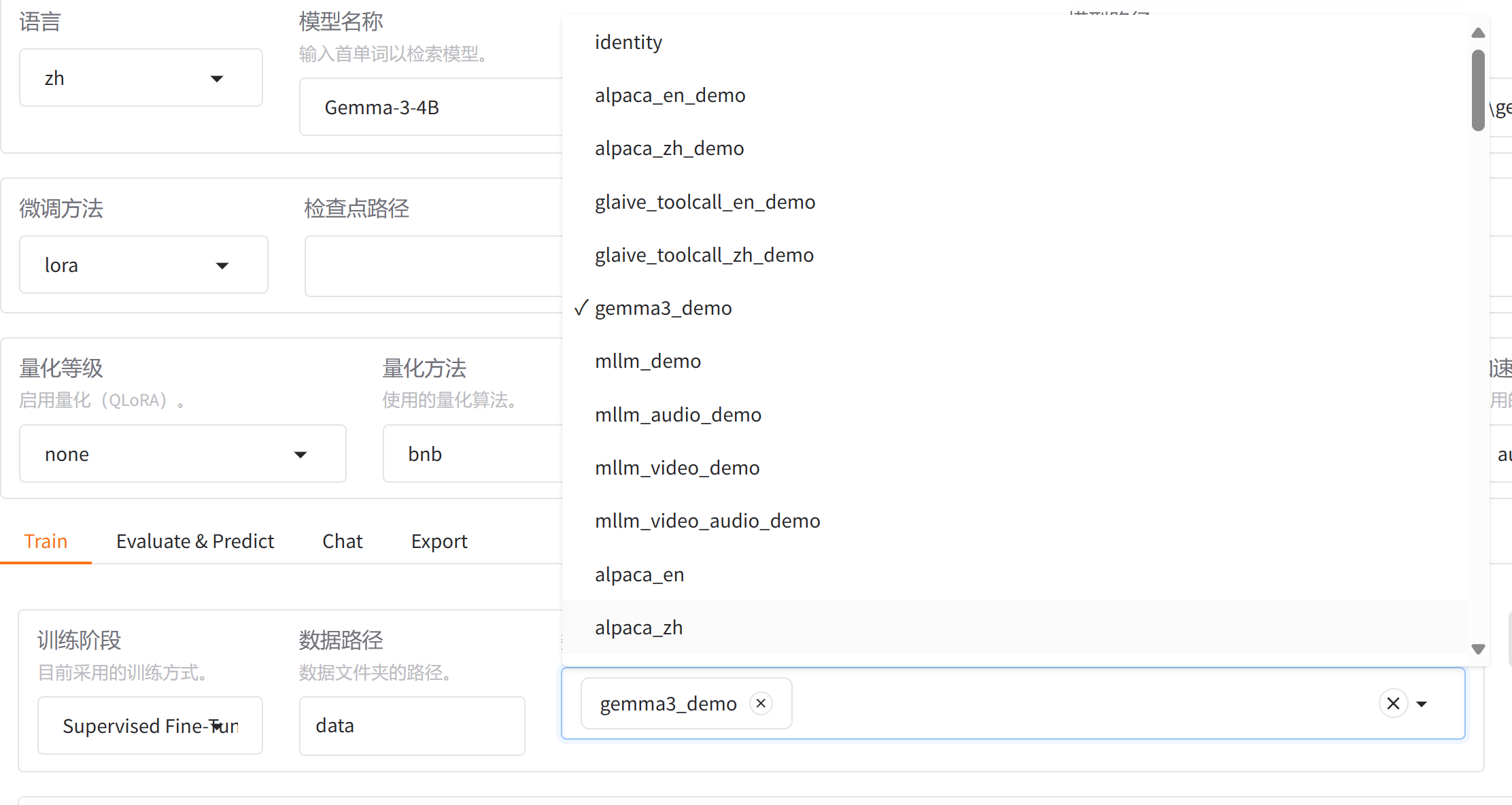
},在可视化界面中就能看到gemma3数据集,以及还可以预览数据集



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









