






第一章:数据加载
1.1 数据集下载
Titanic - Machine Learning from Disaster | Kaggle
1.2 导入数据使用Numpy或Pandas导入数据。Pandas 的一项重要功能是能够编写和读取 Excel、CSV 和许多其他类型的文件并且能有效地进行处理文件。pandas可以读取的文件格式有很多,包括读取文件csv, excel, txt。
>>> import pandas as pd
>>> import numpy as np
1.3 载入数据
(1) 使用相对路径载入数据
(2) 使用绝对路径载入数据
df = pd.read_csv('train.csv')
df.head()
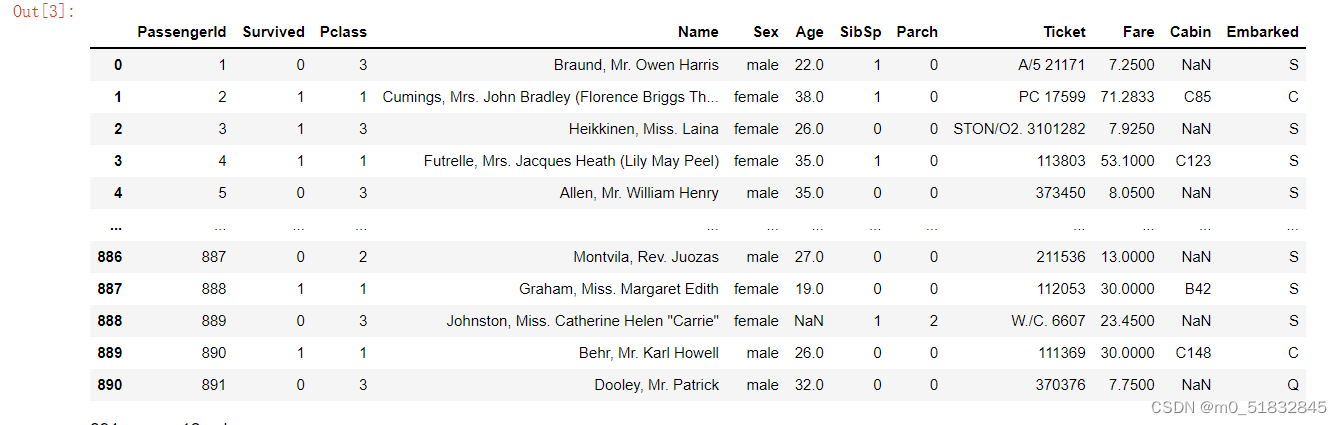
import os
os.path.abspath('train.csv')
储存 path = os.path.abspath('train.csv')
1.4 每1000行为一个数据模块,逐块读取
chunker = pd.read_csv('train.csv', chunksize=1000)
1.5 将表头改成中文,索引改为乘客ID [对于某些英文资料,我们可以通过翻译来更直观的熟悉我们的数据
df.rename(columns={'PassengerId':'乘客ID','Survived':'是否幸存','Pclass':'乘客等级(1/2/3等舱位)','Name':'乘客姓名','Sex':'性别','Age':'年龄','SibSp':'堂兄弟/妹个数','Parch':'父母与小孩个数','Ticket':'船票信息','Fare':'票价','Cabin':'客舱','Embarked':'登船港口'}, inplace = True)
df.head()
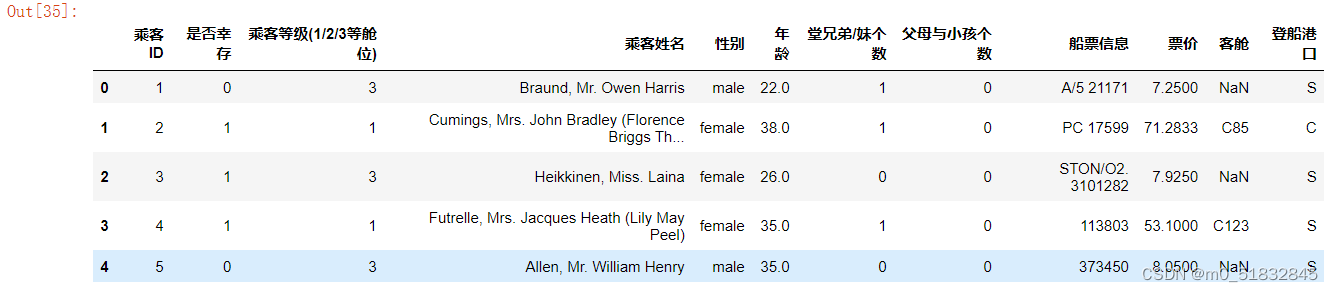
1.6 数据的初步观察
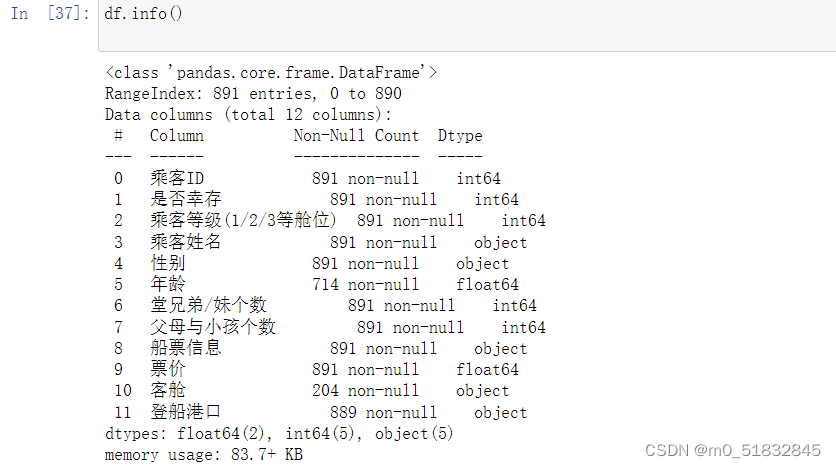
1.6.1 查看数据的基本信息
df.info(): # 打印摘要
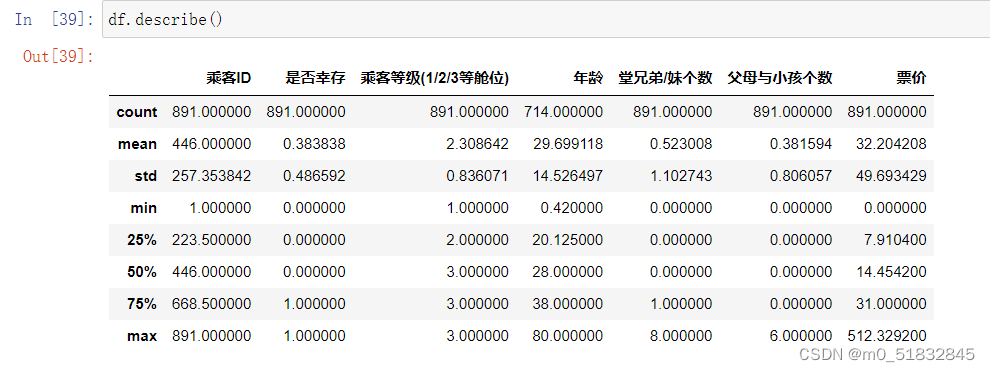
df.describe(): # 描述性统计信息
df.values: # 数据 <ndarray>
df.to_numpy() # 数据 <ndarray> (推荐)
df.shape: # 形状 (行数, 列数)
df.columns: # 列标签 <Index>
df.columns.values: # 列标签 <ndarray>
df.index: # 行标签 <Index>
df.index.values: # 行标签 <ndarray>
df.head(n): # 前n行
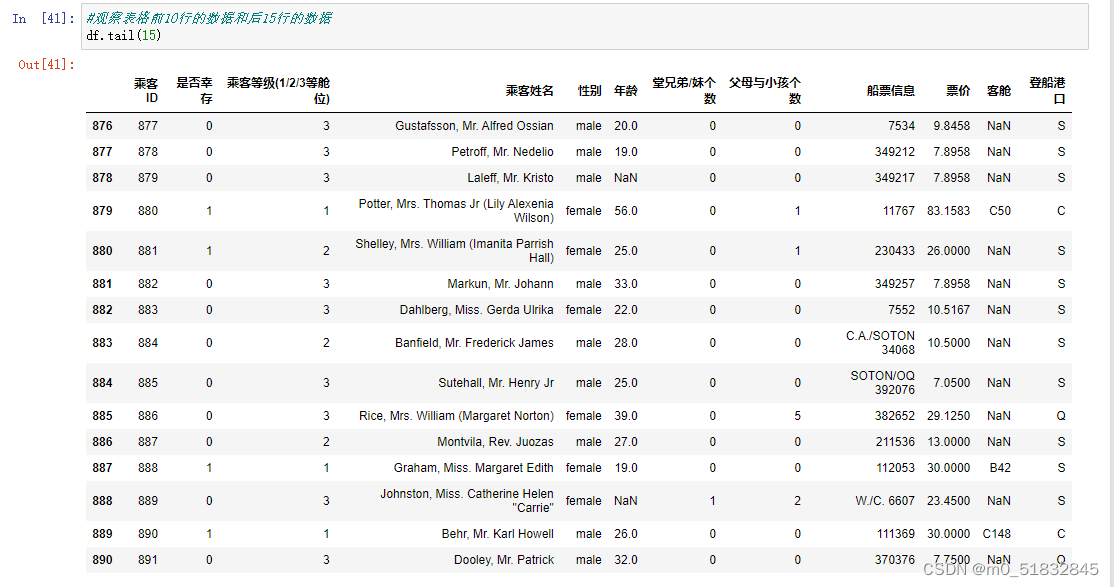
df.tail(n): # 尾n行
pd.options.display.max_columns=n: # 最多显示n列
pd.options.display.max_rows=n: # 最多显示n行
df.memory_usage(): # 占用内存(字节B)
1.6.2 观察表格前10行的数据和后15行的数据















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









