






一、IO读写的基本原理
一个原则:操作系统将内存划分为两部分:一个是内核空间,一个是用户空间。在linux操作系统中,内核模块运行在内核空间,相应的进程处在内核态;用户程序运行在用户态,对应的进程处于用户态。
内核态的进程可以访问内核空间,也可以访问硬件设备(磁盘,网卡等)调用系统的一切资源,用户态的进程(tomcat,redis等等)没有这样的权限,也不能直接调用内核代码定义的函数。并且每个用户态的进程都有一个单独的用户空间,他要想拿到内存或磁盘中的数据,只有将进程切换到内核态然后向内核发出指令,完成调用系统资源之类的操作。
大致过程为下图所示
1.线程或者进程 先从用户态切换到内核态
2.调用操作系统函数(read/write)
并不是执行完第二步 马上就执行第三步 而是说什么时候执行第三步由操作系统决定
3.操作系统将网卡,磁盘,内存里的数据读取到内核缓冲区
4.从内核缓冲区复制到用户缓冲区
5.线程或者进程从内核态再切换到用户态
6.从用户缓冲区读取数据
用户态的进程进行系统调用后,也不是直接就从硬件里把这些数据读出来了。从硬件里读数据是由操作系统来干的。
缓冲区的概念:两个缓冲区,内核缓冲区,应用程序缓冲区。缓冲区的目的就是为了减少硬件之间频繁的物理交换。操作系统会对内核缓冲区进行监控,等待缓冲区达到一定大小后,再进行实际的物理设备的交换(第三步那里 够了一定量才让拿出来 实际的io处理(实际的IO是第三步) )
io操作(我们说的IO是 系统到用户 赋值的过程)其实就是两个缓冲区之间的复制。
二、四种内存模型
1.同步阻塞IO
同步阻塞io:默认情况下,在Java应用程序进程中所有对socket连接进行的IO操作都是同步阻塞IO。
简单的说就是在内核缓冲区获取数据的这个时间,用户态进程得阻塞着,什么也干不了。
在即时通讯项目里,不会采用这种模型,因为一般情况下,是一个socket连接对应一个独立的线程,如果用这种模型,在高并发项目中,需要很多的线程来维护大量的socet连接,内存,线程之间的切换开销会很大,性能很低。
优点:应用程序开发简单,在阻塞等待数据的区间,用户线程挂起,基本不会占用太多的cpu资源。
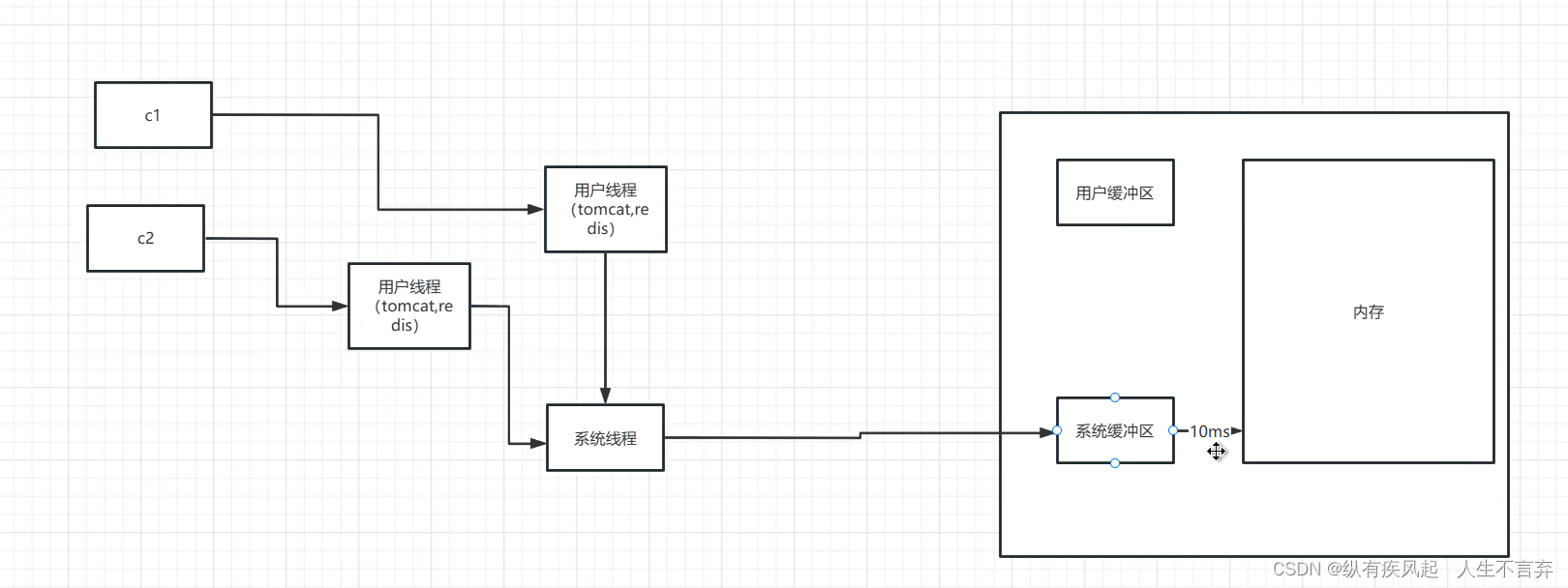
2.同步非阻塞IO(他是由 用户线程发起的轮询 一个线程可以处理多个链接 但是有限制)
(1)在内核数据没有准备好的阶段,用户线程发起IO请求时立即返回。所以,为了读取最终的数据,用户进程(或者线程)需要不断地发起IO系统调用
(2)内核数据到达后,用户进程(或者线程)发起系统调用,用户进程(或者线程)阻塞。内核开始复制数据,它会将数据从内核缓冲区复制到用户缓冲区,然后内核返回结果
(3)用户进程(或者线程)读到数据后,才会解除阻塞状态,重新运行起来。也就是说,用户空间需要经过多次尝试才能保证最终真正读到数据,而后继续执行。
同步非阻塞IO的优点是每次发起的IO系统调用在内核等待数据过程中可以立即返回,用户线程不会阻塞,实时性较好。
同步非阻塞IO的缺点是不断地轮询内核,并且还会不断的进行用户态和系统态之间的切换(这个最占CPU),这将占用大量的CPU时间,效率低下。总体来说,在高并发应用场景中,同步非阻塞IO是性能很低的,也是基本不可用的,一般Web服务器都不使用这种IO模型。在Java的实际开发中,不会涉及这种IO模型,但是此模型还是有价值的,其作用在于其他IO模型中可以使用非阻塞IO模型作为基础,以实现其高性能。
为什么需要不断切换形态 ?
线程没有阻塞 当他想处理c2请求 需要切换到 用户态 然后又需要轮询 就又要切换到系统态
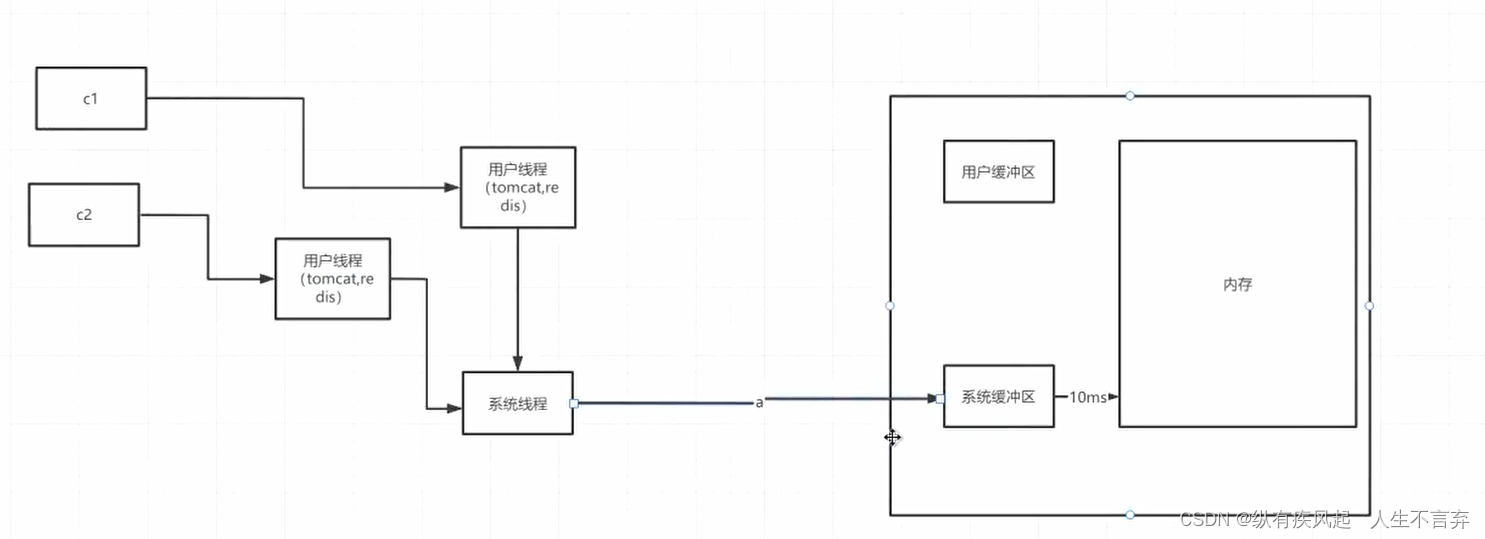
3.IO多路复用(系统线程发起的轮询 轮询时候他不用管 他就不用切换了 回调消息 可能直接回用户线程 也可能取系统线程)
(1)选择器注册。首先,将需要read操作的目标文件描述符(socket连接)提前注册到Linux的select/epoll选择器中,在Java中所对应的选择器类是Selector类。然后,开启整个IO多路复用模型的轮询流程。
(2)就绪状态的轮询。通过选择器的查询方法,查询所有提前注册过的目标文件描述符(socket连接)的IO就绪状态。通过查询的系统调用,内核会返回一个就绪的socket列表。当任何一个注册过的socket中的数据准备好或者就绪了就说明内核缓冲区有数据了,内核将该socket加入就绪的列表中,并且返回就绪事件。
(3)用户线程获得了就绪状态的列表后,根据其中的socket连接发起read系统调用,用户线程阻塞。内核开始复制数据,将数据从内核缓冲区复制到用户缓冲区。
(4)复制完成后,内核返回结果,用户线程才会解除阻塞的状态,用户线程读取到了数据,继续执行。
IO多路复用模型的优点是一个选择器查询线程可以同时处理成千上万的网络连接,所以用户程序不必创建大量的线程,也不必维护这些线程,从而大大减少了系统的开销。与一个线程维护一个连接的阻塞IO模式相比,这一点是IO多路复用模型的最大优势。
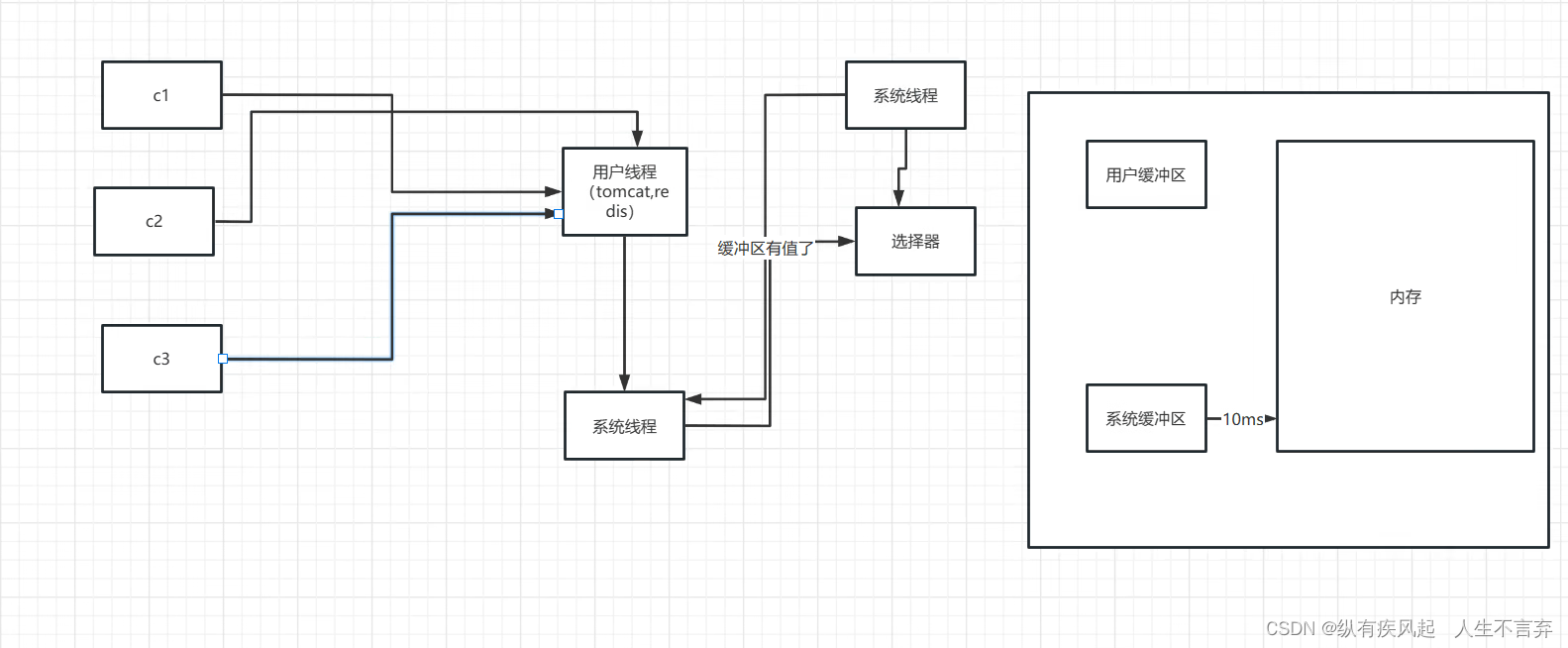
用户线程下面这个系统线程 是用户线程转换的 然后轮询选择器的那个系统线程 是本来就有的
4.异步io
增加了一个回调操作,但是因为出现的晚,jdk对于他的支持并不完善,所以用的不多。
异步io模型是性能最高的一个模型。
目前高并发网络应用程序都是采用的io多路复用。
有数据之后 自己就回调了
















 1159
1159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









