






项目中遇到的小bug:竟然会因为一个小冒号导致前端编译时间翻倍
同 一 项目、dev分支
d e v分支 a服务器上前端代码的编译时间从33秒突然变为一分钟9秒(此处提交的代码 < e l -f o r m -i t e m l a b e l="IP地址:"重点在这个中文冒号上, )下图为jenkins打包时间:

同一项目 同一时间下release分支
r e l e a s e分支 b 服务器上前端代码的编译时间为36秒(此分支提交的代码 < e l -f o r m-i t e m l a b e l="I P地址:" 【重点在这个英文冒号上】 )下图为j e n k i n s打包时间:
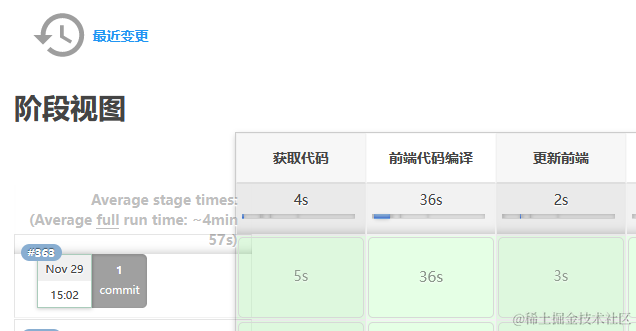
感觉这个有蹊跷,所有我把dev分支上改回去验证一下
dev a服务器上
下面是我更改了中文冒号后的前端代码的编译时间又从一分钟18秒变为了39秒 ,下图为jenkins打包时间:
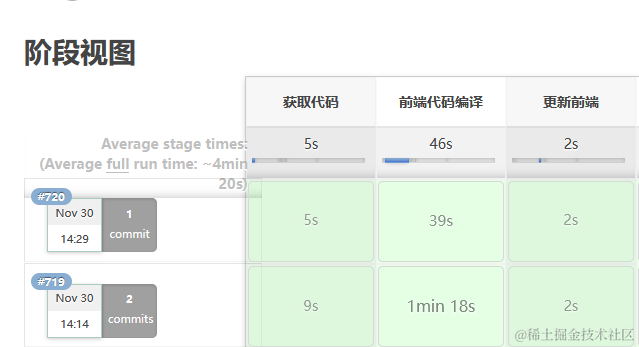
总结一下:
v s C o d e在中英文混输时会报一个黄色提示:

T h e c h a r a c t e r U + f f 1 a ":" c o u l d b e c o n f u s e d w i t h t h e A S C I I c h a r a c t e r U + 0 0 3 a ":", w h i c h i s m o r e c o m m o n i n s o u r c e c o d e. 翻译:字符U+f f1 a ":"可能与A S C I I字符U+003a ":"混淆,后者在源代码中更常见。
好吧,我就是shui一篇文章哈哈哈哈哈哈
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









