







背景:因生产环境一台物理机损坏,需要停机修复,张三直接驱逐了这个节点上的所有pod(风险操作),其中有一个有状态的应用zk,驱逐完后做了停机操作,后面业务反馈生产环境zk链接超时,才发现zk集群直接挂了,麻木,接着就是来自于领导的灵魂拷问,三节点zk为什么挂了一个集群就用不了,确实也疑惑,明明还有两个Running的pod,这多副本冗余了个寂寞。
一、问题描述
三副本zk集群,当挂了一个pod,还有两个pod是Running的,集群就开始出现异常,业务客户端连接超时
二、排查原因
1、查看zk集群每个节点状态,发现有一个follower节点本来就异常,通过zkServer.sh status 查看状态和zkCli.sh 连接报错:Closing socket connection and attempting reconnect
bash-4.4# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Error contacting service. It is probably not running.
bash-4.4# bin/zkCli.sh
2024-04-01 06:31:04,078 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1032] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
JLine support is enabled
2024-04-01 06:31:04,176 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@876] - Socket connection established to localhost/127.0.0.1:2181, initiating session
2024-04-01 06:31:04,181 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1158] - Unable to read additional data from server sessionid 0x0, likely server has closed socket, closing socket connection and attempting reconnect
[zk: localhost:2181(CONNECTING) 0] 2024-04-01 06:31:06,059 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1032] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2024-04-01 06:31:06,060 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@876] - Socket connection established to localhost/127.0.0.1:2181, initiating session
2024-04-01 06:31:06,061 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1158] - Unable to read additional data from server sessionid 0x0, likely server has closed socket, closing socket connection and attempting reconnect这个可以得出一个节点,说明原本三个副本的zk集群中,本来有一个follower节点就是有问题的,导致leader节点再宕机之后,只有一个节点可用,导致的客户端连接超时报错,但是问题来了,pod都是Running的为什么有一个节点会连接不上呢,只能够根据这个报错去查看原因了
2、根据zk的报错信息去排查原因
在网上查阅了很多资料,发现每个的报错都差不多,但是导致这个报错的原因都是各种各样,有因为防火墙的,有因为节点数不是奇数的,或者zkclient命令没有指定server的、最大连接数超过60的(这还真接近60了,但是应该不是这个原因导致),但是这次遇到的这个情形不太相符,每种问题的报错表现都是:closing socket connection and attempting reconnect,真的服气。
3、查看myid以及zoo.cfg配置文件(重大发现)
观察zk的配置文件以及myid文件发现一个问题,两个follower节点的myid文件与zoo.cfg中配置的server.x不匹配,之前看了很多次,一直没有注意到这个问题,因为这个在pod运行时就是注入进去了的,并且sts的配置中是正常的,但是在pod容器内不正常,myid为2的节点对应的server.x为server.3,这会导致zk集群节点直接的通信异常
相关文档:ZooKeeper: Because Coordinating Distributed Systems is a Zoo
4、手动搭建一套新的zk集群测试,复现报错
正常情况下的配置文件的状态,myid与server.x一一对应
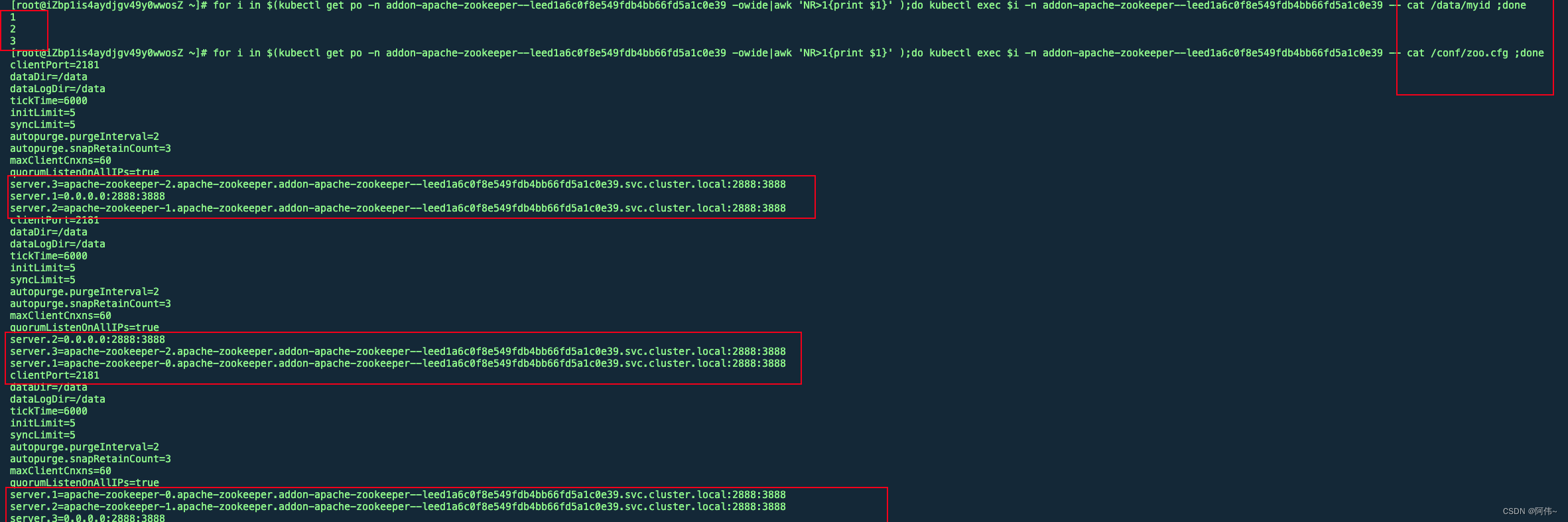
手动干预下myid
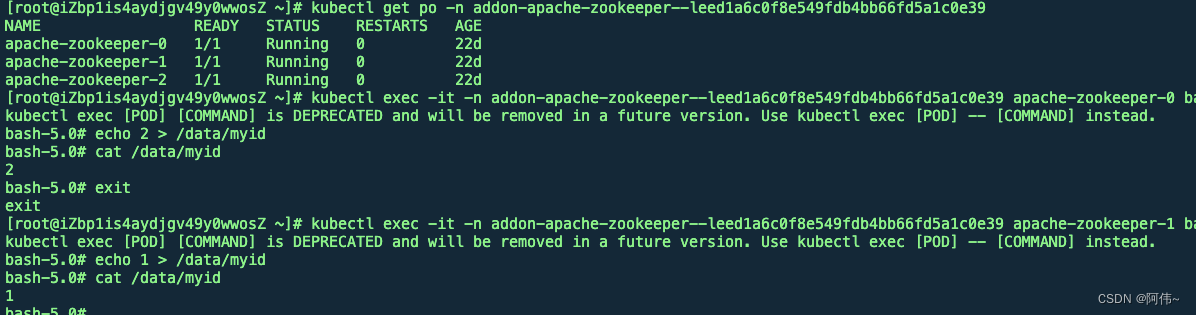
重启两个follower节点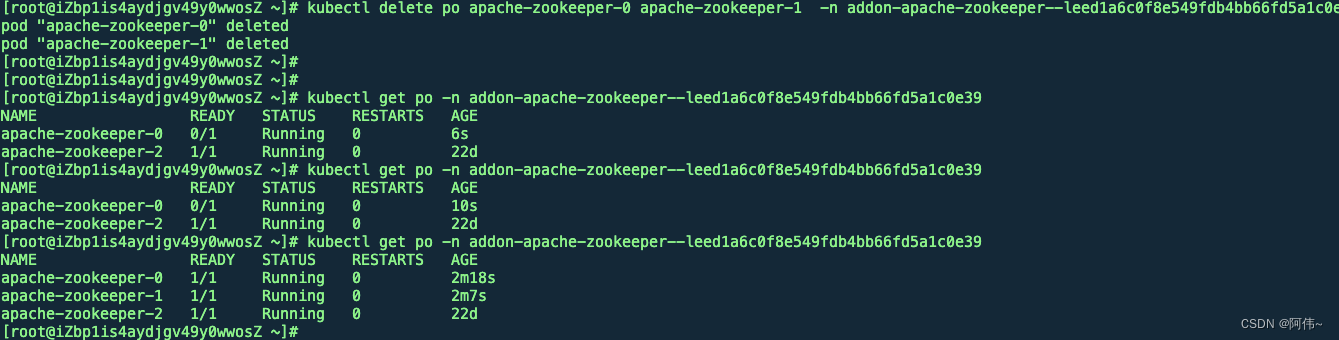
查看状态,确实有一个节点直接进入异常的状态
如下图所示,1和2两个节点的myid与server.x配置相反
猜测一波,就是这个原因导致的zk一个follower节点异常的,在生产环境提一个变更的窗口期验证修复一下这个问题。
三、最终结论
结论:确实是由于节点myid配置与zoo.cfg 中的server.x中的x没有一一对应导致的集群最后启动的那个zk节点始终处于异常
造成原因:怀疑是有人手动更改了这个zk集群的myid配置(实在想不到别的原因了),这个集群已经运行好几年了,也没法溯源了
反馈出来的问题:分布式服务实际可用性的这个监控缺失,大部分情况我们的主动监控只会监控pod的运行状态是不是Running,以及服务可不可用,但是这次遇到的问题,pod都是Running的,zk服务也能够正常使用(但是其实只有两个节点能够使用了),要是再挂一个节点,服务直接挂了,降低了服务的容错能力。
措施:优化监控告警















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









