







Paper: Attal B, Huang J B, Richardt C, et al. Hyperreel: High-fidelity 6-dof video with ray-conditioned sampling[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 16610-16620.
Introduction: https://hyperreel.github.io/
Code: https://github.com/facebookresearch/hyperreel
HyperReel 是 CVPR 2023 Highlight,能够使用不同视角下同步的视频训练出高质量、高效内存的场景表示,然后可以在新的视角下合成视频。HyperReel 主要包含一个用于高效渲染的基于射线的样本点预测网络和一个内存紧凑的动态体积表示,这使它兼具高渲染质量、实时和内存紧凑等优越性,性能远超现有的 6-DoF 视频表示方法 1。

目录
一. 预备知识
1. 3-DoF
3 自由度 (3 Degrees of Freedom, 3-DoF) 用于描述物体在三维空间中的平动运动。这 3 个自由度包括:
- 沿着三个平移轴 (X、Y、Z) 的平移运动;
3-DoF 不包括任何旋转自由度,物体无法围绕任何轴进行旋转,因此只能用于描述简单的 3D 运动,如基本的平移和缩放操作。
2. 6-DoF
6 自由度 (6 Degree of Freedom, 6-DoF) 用于描述物体在三维空间中的自由运动。这 6 个自由度包括:
- 沿着三个平移轴 (X、Y、Z) 的平移运动;
- 围绕三个旋转轴 (X、Y、Z) 的旋转运动,即滚转 (Roll)、俯仰 (Pitch)、偏航 (Yaw);
这种 6 个自由度的运动能够充分描述一个物体在 3D 空间中的任意位置和姿态,适用于需要更高水平交互和沉浸感的应用场景。6-DoF 的概念广泛应用于机器人学、航空航天、虚拟现实等领域,用于跟踪和控制物体的位置和方向。比如在 VR/AR 应用中,6-DoF 跟踪能让用户在虚拟环境中自由移动和探索。
二. 研究思路
6-DoF 视频表示方法依赖 NeRF 等体积场景表示方法,但是现有的方法难以兼顾实时性、低内存和高质量。因此,本文提出了 HyperReel,将输入的同步多视角视频流 (synchronized multi-view video streams) 建模为高质量、内存高效的连续三维场景表示,并能够在新的视角下实时呈现。HyperReel 主要包含以下两个部分:
- 基于射线的样本点预测网络 (ray-conditioned sample prediction network):对 NeRF 的 ray-tracing 过程进行优化,既加快了体积渲染的速度,又提高了场景质量。
- 基于关键帧的动态体积表示 (keyframe-based dynamic volume representation):将 TensorRF 扩展到动态场景,充分利用动态场景的时空冗余性来实现高压缩率。
三. 基于射线的样本点预测网络
大多数场景是由实心物体组成的,这些物体的表面位于三维场景体积 (3D scene volume) 内的一个二维流形 (2D manifold) 上。在这种情况下,只有物体表面的样本点会影响每条光线的渲染颜色。为了加快体积渲染速度,只对 w k w_k wk 非零的样本点进行查询颜色和不透明度的操作(其中 w k w_k wk 是每个样本点的颜色对输出的贡献,详见原文第三章开头推理过程)。
HyperReel 一开始采取的做法是使用一个前馈神经网络直接预测样本点的位置:
E
ϕ
:
(
o
,
ω
→
)
→
(
x
1
,
…
,
x
n
)
E_\phi:(\mathbf{o}, \overrightarrow{\boldsymbol{\omega}}) \rightarrow\left(\mathbf{x}_1, \ldots, \mathbf{x}_n\right)
Eϕ:(o,ω)→(x1,…,xn)
并使用二平面(前向场景)或 Plücker 参数化(非前向场景)来表示光线:
r
=
P
l
u
¨
c
k
e
r
(
o
,
ω
→
)
=
(
ω
→
,
ω
→
×
o
)
\mathbf{r}=\operatorname{Plücker}(\mathbf{o}, \overrightarrow{\boldsymbol{\omega}})=(\overrightarrow{\boldsymbol{\omega}}, \overrightarrow{\boldsymbol{\omega}} \times \mathbf{o})
r=Plu¨cker(o,ω)=(ω,ω×o)
Plücker 参数化
在三维空间中,一条直线可以由两点的向量差来唯一确定,也可以通过点和方向向量的组合来表示。然而,这种表示方式在某些几何计算中可能不太方便,Plücker 参数化则提供了一种替代方案。
一条直线 L L L 可以由两个不重合的点 P 1 = ( x 1 , y 1 , z 1 ) P_1 = (x_1, y_1, z_1) P1=(x1,y1,z1) 和 P 2 = ( x 2 , y 2 , z 2 ) P_2 = (x_2, y_2, z_2) P2=(x2,y2,z2) 来定义,也可以使用 Plücker 参数化为六个坐标 ( L 1 , L 2 , L 3 , L 4 , L 5 , L 6 ) (L_1, L_2, L_3, L_4, L_5, L_6) (L1,L2,L3,L4,L5,L6),由两个向量的外积和方向向量的组合给出:
L 1 = y 1 z 2 − z 1 y 2 , L 2 = z 1 x 2 − x 1 z 2 , L 3 = x 1 y 2 − y 1 x 2 L 4 = d x = x 2 − x 1 , L 5 = d y = y 2 − y 1 , L 6 = d z = z 2 − z 1 L_1 = y_1 z_2 - z_1 y_2, \quad L_2 = z_1 x_2 - x_1 z_2, \quad L_3 = x_1 y_2 - y_1 x_2\\ L_4 = d_x = x_2 - x_1, \quad L_5 = d_y = y_2 - y_1, \quad L_6 = d_z = z_2 - z_1 L1=y1z2−z1y2,L2=z1x2−x1z2,L3=x1y2−y1x2L4=dx=x2−x1,L5=dy=y2−y1,L6=dz=z2−z1
与传统的点、向量表示不同,Plücker 坐标能够更有效地处理直线的几何性质,尤其是在相交、共线、平行等几何关系中。
但这样忽略了 ( x 1 , … , x n ) \left(\mathbf{x}_1, \ldots, \mathbf{x}_n\right) (x1,…,xn) 之间的联系,会造成多视角的不一致性。
于是,HyperReel 对
E
ϕ
E_\phi
Eϕ 进行调整:根据输入的射线动态预测一组几何基元 (geometric primitives)
G
1
,
…
,
G
n
G_1, \ldots, G_n
G1,…,Gn,然后将射线与每个基元相交就可以得到样本点:
E
ϕ
(
o
,
ω
→
)
=
(
G
1
,
…
,
G
n
)
(
x
1
,
…
,
x
n
)
=
(
inter
(
G
1
;
o
,
ω
→
)
,
…
,
inter
(
G
n
;
o
,
ω
→
)
)
\begin{aligned} E_{\boldsymbol{\phi}}(\mathbf{o}, \overrightarrow{\boldsymbol{\omega}}) & =\left(G_1, \ldots, G_n\right) \\ \left(\mathbf{x}_1, \ldots, \mathbf{x}_n\right) & =\left(\operatorname{inter}\left(G_1 ; \mathbf{o}, \overrightarrow{\boldsymbol{\omega}}\right), \ldots, \operatorname{inter}\left(G_n ; \mathbf{o}, \overrightarrow{\boldsymbol{\omega}}\right)\right) \end{aligned}
Eϕ(o,ω)(x1,…,xn)=(G1,…,Gn)=(inter(G1;o,ω),…,inter(Gn;o,ω))
几何基元
几何基元 (Geometric Primitives) 是计算机图形学和几何学中的基本形状或图形,用来构建复杂几何对象的基础元素。常见的几何基元包括点、线、平面、三角形、矩形、圆、球体、立方体等。这些基本形状通过组合、变换和操作可以构建更复杂的几何模型。HyperReel 在处理前向场景 (forward-facing scenes) 时使用的是轴对齐的 Z 平面,非前向场景使用的是同心球壳。
轴对齐的Z平面 (Axis-aligned Z-planes) 是平行于 XY 平面且与 Z 轴对齐的平面,通常用于处理前向场景。在这些场景中,平面可以与物体的前向表面对齐,帮助简化场景的表示或加速计算过程。
同心球壳 (Concentric Spherical Shells) 是以原点为中心的球壳,多个球壳可以层层包围。对于非前向场景,这种几何基元可以用来有效地表示三维空间中的对象分布或场景中的距离层次结构。
为了增加灵活性,HyperReel 进一步为每个样本点
x
k
\mathbf{x}_k
xk 预测一个偏移量
e
k
\mathbf{e}_k
ek 和待激活的权重
δ
k
\delta_k
δk。然后将样本点表示为射线与基元相交加上偏移量 (displacement vectors):
(
d
1
,
…
d
n
)
=
(
γ
(
δ
1
)
e
1
,
…
,
γ
(
δ
n
)
e
n
)
(
x
1
,
…
x
n
)
←
(
x
1
+
d
1
,
…
,
x
n
+
d
n
)
\begin{aligned} \left(\mathbf{d}_1, \ldots \mathbf{d}_n\right) & =\left(\gamma\left(\delta_1\right) \mathbf{e}_1, \ldots, \gamma\left(\delta_n\right) \mathbf{e}_n\right) \\ \left(\mathbf{x}_1, \ldots \mathbf{x}_n\right) & \leftarrow\left(\mathbf{x}_1+\mathbf{d}_1, \ldots, \mathbf{x}_n+\mathbf{d}_n\right) \end{aligned}
(d1,…dn)(x1,…xn)=(γ(δ1)e1,…,γ(δn)en)←(x1+d1,…,xn+dn)
有了样本点,就可以使用 NeRF 的体积渲染公式进行渲染。综上所述,HyperReel 的推理流程如下:
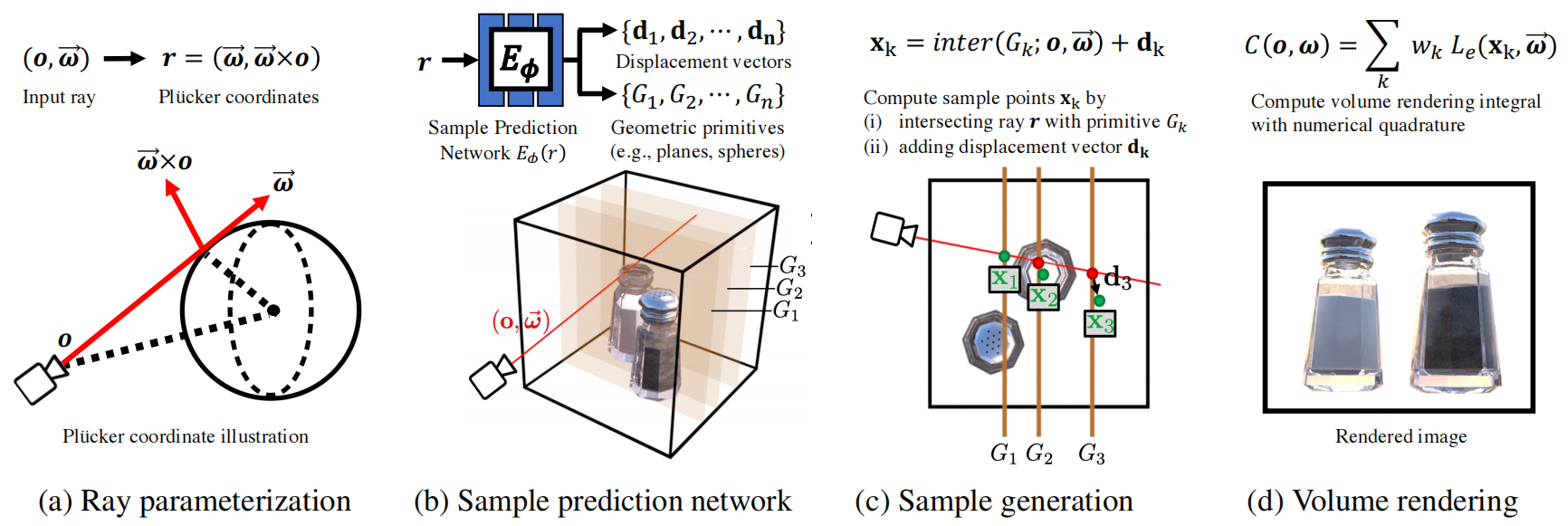
Note:
这一节主要介绍了 HyperReel 的快速渲染方法,能够快速、高质量地合成新视图,原则上来说适配任何三维体积表示方法 2 。下一节将介绍如何表示动态的三维场景。
四. 基于关键帧的动态体积表示
1. 动态体积表示
对于静态三维场景,直接使用 TensoRF:
A
(
x
k
)
=
B
1
(
f
1
(
x
k
,
y
k
)
⊙
g
1
(
z
k
)
)
+
B
2
(
f
2
(
x
k
,
z
k
)
⊙
g
2
(
y
k
)
)
+
B
3
(
f
3
(
y
k
,
z
k
)
⊙
g
3
(
x
k
)
)
σ
(
x
k
)
=
1
⊤
(
h
1
(
x
k
,
y
k
)
⊙
k
1
(
z
k
)
)
+
1
⊤
(
h
2
(
x
k
,
z
k
)
⊙
k
2
(
y
k
)
)
+
1
⊤
(
h
3
(
y
k
,
z
k
)
⊙
k
3
(
x
k
)
)
\begin{aligned} A\left(\mathbf{x}_k\right) & =\mathcal{B}_1\left(\mathbf{f}_1\left(x_k, y_k\right) \odot \mathbf{g}_1\left(z_k\right)\right) \\ & +\mathcal{B}_2\left(\mathbf{f}_2\left(x_k, z_k\right) \odot \mathbf{g}_2\left(y_k\right)\right) \\ & +\mathcal{B}_3\left(\mathbf{f}_3\left(y_k, z_k\right) \odot \mathbf{g}_3\left(x_k\right)\right) \\ \sigma\left(\mathbf{x}_k\right)= & \mathbf{1}^{\top}\left(\mathbf{h}_1\left(x_k, y_k\right) \odot \mathbf{k}_1\left(z_k\right)\right) \\ & + \mathbf{1}^{\top}\left(\mathbf{h}_2\left(x_k, z_k\right) \odot \mathbf{k}_2\left(y_k\right)\right) \\ & + \mathbf{1}^{\top}\left(\mathbf{h}_3\left(y_k, z_k\right) \odot \mathbf{k}_3\left(x_k\right)\right) \\ \end{aligned}
A(xk)σ(xk)==B1(f1(xk,yk)⊙g1(zk))+B2(f2(xk,zk)⊙g2(yk))+B3(f3(yk,zk)⊙g3(xk))1⊤(h1(xk,yk)⊙k1(zk))+1⊤(h2(xk,zk)⊙k2(yk))+1⊤(h3(yk,zk)⊙k3(xk))
其中 B j \mathcal{B}_j Bj 是将 f j \mathbf{f}_j fj 和 g j \mathbf{g}_j gj 的乘积映射到球谐系数的线性变换, A ( x k ) A\left(\mathbf{x}_k\right) A(xk) 表示 x k \mathbf{x}_k xk 的球谐系数; σ ( x k ) \sigma\left(\mathbf{x}_k\right) σ(xk) 表示 x k \mathbf{x}_k xk 的体积密度。
对于动态三维场景,在时间维度上扩展 TensoRF:
A
(
x
k
,
τ
i
)
=
B
1
(
f
1
(
x
k
,
y
k
)
⊙
g
1
(
z
k
,
τ
i
)
)
+
B
2
(
f
2
(
x
k
,
z
k
)
⊙
g
2
(
y
k
,
τ
i
)
)
+
B
3
(
f
3
(
y
k
,
z
k
)
⊙
g
3
(
x
k
,
τ
i
)
)
σ
(
x
k
,
τ
i
)
=
1
⊤
(
h
1
(
x
k
,
y
k
)
⊙
k
1
(
z
k
,
τ
i
)
)
+
1
⊤
(
h
2
(
x
k
,
z
k
)
⊙
k
2
(
y
k
,
τ
i
)
)
+
1
⊤
(
h
3
(
y
k
,
z
k
)
⊙
k
3
(
x
k
,
τ
i
)
)
\begin{aligned} A\left(\mathbf{x}_k, \tau_i\right) & =\mathcal{B}_1\left(\mathbf{f}_1\left(x_k, y_k\right) \odot \mathbf{g}_1\left(z_k, \tau_i\right)\right) \\ & +\mathcal{B}_2\left(\mathbf{f}_2\left(x_k, z_k\right) \odot \mathbf{g}_2\left(y_k, \tau_i\right)\right) \\ & +\mathcal{B}_3\left(\mathbf{f}_3\left(y_k, z_k\right) \odot \mathbf{g}_3\left(x_k, \tau_i\right)\right) \\ \sigma\left(\mathbf{x}_k, \tau_i\right) & =\mathbf{1}^{\top}\left(\mathbf{h}_1\left(x_k, y_k\right) \odot \mathbf{k}_1\left(z_k, \tau_i\right)\right) \\ & +\mathbf{1}^{\top}\left(\mathbf{h}_2\left(x_k, z_k\right) \odot \mathbf{k}_2\left(y_k, \tau_i\right)\right) \\ & + \mathbf{1}^{\top}\left(\mathbf{h}_3\left(y_k, z_k\right) \odot \mathbf{k}_3\left(x_k, \tau_i\right)\right) \end{aligned}
A(xk,τi)σ(xk,τi)=B1(f1(xk,yk)⊙g1(zk,τi))+B2(f2(xk,zk)⊙g2(yk,τi))+B3(f3(yk,zk)⊙g3(xk,τi))=1⊤(h1(xk,yk)⊙k1(zk,τi))+1⊤(h2(xk,zk)⊙k2(yk,τi))+1⊤(h3(yk,zk)⊙k3(xk,τi))
g j \mathbf{g}_j gj 和 k j \mathbf{k}_j kj 增加了时间维度, A ( x k ) A\left(\mathbf{x}_k\right) A(xk) 和 σ ( x k ) \sigma\left(\mathbf{x}_k\right) σ(xk) 分别表示 x k \mathbf{x}_k xk 在时刻 τ i \tau_i τi 的球谐系数和体积密度。
需要注意的是,动态 TensoRF 引入了时间变量,所以样本点预测网络也需要增加时间变量的输入,表示该视角在特定时刻下观察到的像素颜色。
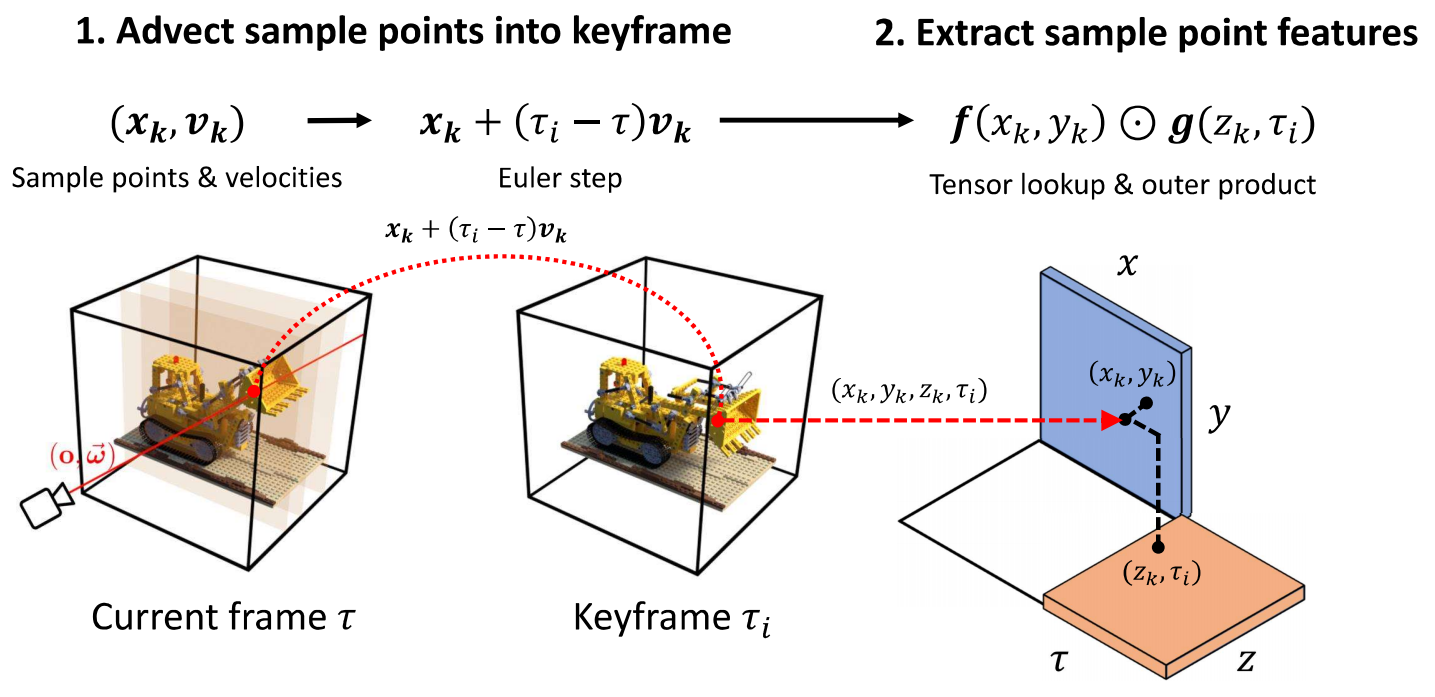
2. 基于关键帧的渲染机制
因为是动态三维场景,所以需要在三维场景中增加时间维度。为了减少所需的存储空间和计算资源,HyperReel 并不是逐帧地训练每一帧整个场景,而是在训练视频中均匀地抽取一些帧作为关键帧 (keyframe),然后在这些关键帧之间插值得到完整的动态场景。
为了表示 任意时刻 的场景,还需要在关键帧之间进行插值,因此增加样本点预测网络的输出,预测样本点在特定时刻相较于最近关键帧的移动速度,因此有:
x
k
←
x
k
+
v
k
(
τ
i
−
τ
)
\mathbf{x}_k \leftarrow \mathbf{x}_k+\mathbf{v}_k\left(\tau_i-\tau\right)
xk←xk+vk(τi−τ)
综上所述,HyperReel 的关键帧插值流程如下:
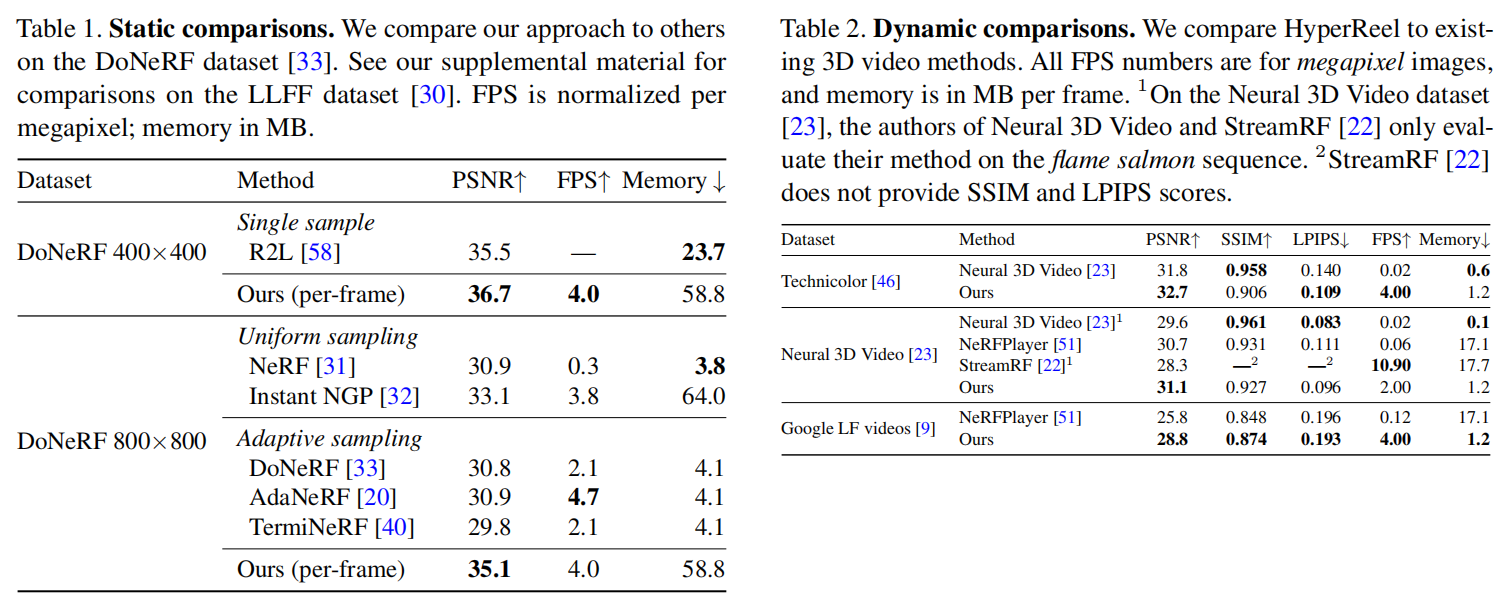
五. 实验

六. 总结
HyperReel 本质上是一种基于 NeRF 的 6-DoF 视频表示方法,不需要任何额外的 CUDA 代码,就可以高质量、低内存地实现动态三维场景的建模。场景训练完成后,可以实时地在任意新视角合成视频。
HyperReel 先在训练视频中均匀地选定一些帧作为关键帧,然后使用任意视频的任意帧对样本预测网络进行训练,使其能够将输入的时间和射线映射到与输入时间最近的关键帧的基元及其偏移量。训练完成后,就可以通过插值在任意时刻任意视角推理出场景。
HyperReel 和 D-NeRF 等 4D NeRF 方法解决的其实是同一个问题:对一段在时间维度上连续的三维场景进行建模。虽然 D-NeRF 数据集 里是不同视角下不同时刻的图像,但这可以看作是每个视角下只有一帧图像的视频,这就和 HyperReel 数据集里不同视角下的视频格式一致了。当然,HyperReel 也可以兼容静态三维场景的重建。
七. 复现
- 平台:AutoDL
- 显卡:RTX 3090 24GB
- 镜像:PyTorch 2.0.0、Python 3.8(ubuntu20.04)、Cuda 11.8
- 源码:https://github.com/facebookresearch/hyperreel
实验过程:
-
克隆仓库后,按照 README 创建虚拟环境
hyperreel并安装依赖。如果 conda 创建环境太慢,可以使用 mamba 代替:conda install mamba -n base -c conda-forge mamba env create -f environment.yml -
下载数据集,本次实验使用的是 Google Immersive 数据集中的 Flames 场景。上传至数据盘的
data/immersive文件夹并解压; -
训练时遇到
undefined symbol: iJIT_NotifyEvent报错: 这是因为 PyTorch 是针对旧版 MKL 分发版构建的,而新版的 MKL 2024.1 将其移除了 3,安装旧版 MKL 即可:
这是因为 PyTorch 是针对旧版 MKL 分发版构建的,而新版的 MKL 2024.1 将其移除了 3,安装旧版 MKL 即可:pip install mkl==2024.0.04; -
又遇到
ImportError: cannot import name '_compare_version' from 'torchmetrics.utilities.imports'报错:
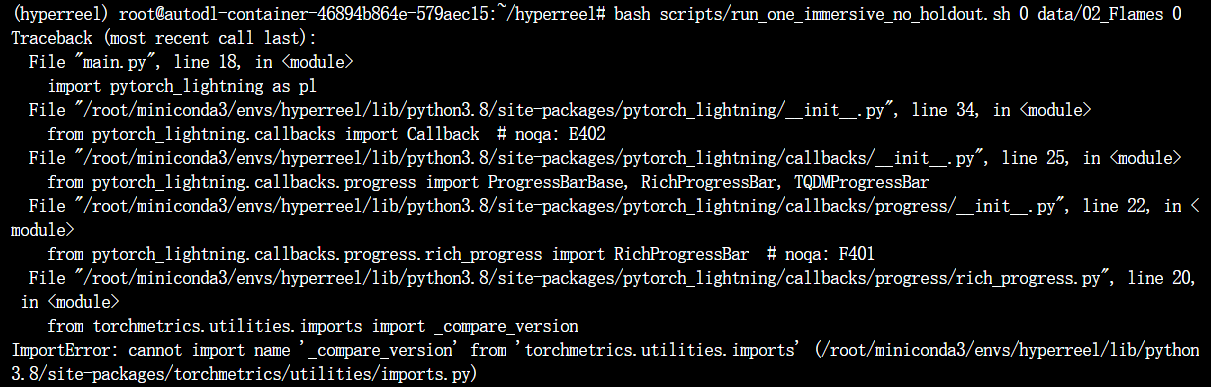
降级 torchmetrics 即可:conda install torchmetrics=0.11.4 -c conda-forge5; -
训练前还需要根据实验环境修改
conf/experiment/params/local.yaml中的配置信息:# ckpt_dir: ~/checkpoints # log_dir: ~/logs # data_dir: ~/data ckpt_dir: ~/autodl-tmp/checkpoints log_dir: ~/autodl-tmp/logs data_dir: ~/autodl-tmp/data -
一开始使用 RTX 4090 显卡遇到
nvrtc: error: invalid value for --gpu-architecture (-arch)报错。应该是GPU、CUDA 和 pytorch 之间不兼容,没想在这里浪费时间,直接换成 RTX 3090 就好了; -
执行训练脚本后,刚加载完数据进程就被 Kill 了:

因为内存超限了,作者使用的 128G RAM 的工作环境,而本次实验只有 45G,将hyperreel/conf/experiment/dataset/immersive.yaml中的 num_frames 由 50 改为 12 6 即可:

-
然后又遇到
ValueError: win_size exceeds image extent.报错:
安装指定版本的 scikit-image 即可:pip install scikit-image==0.19.37; -
到此终于可以开始训练,完整指令:
bash scripts/run_one_immersive_no_holdout.sh 5 02_Flames 0;

-
训练完成后,
checkpoints文件夹下会保存模型权重,logs文件夹下会保存一段测试结果,可以使用下面的脚本将图像合成视频:import cv2 import os def create_video_from_images(image_folder, output_video_path, fps=30): # 获取指定文件夹下的所有图像文件 images = [img for img in os.listdir(image_folder) if img.endswith((".png", ".jpg", ".jpeg"))] # 按图像名顺序排序 images.sort() # 获取第一张图像来确定视频的宽高 first_image_path = os.path.join(image_folder, images[0]) frame = cv2.imread(first_image_path) height, width, layers = frame.shape # 初始化视频写入对象 video = cv2.VideoWriter(output_video_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (width, height)) # 按顺序将每张图像添加到视频中 for image in images: image_path = os.path.join(image_folder, image) frame = cv2.imread(image_path) video.write(frame) # 释放视频写入对象 video.release() if __name__ == "__main__": image_folder = '../autodl-tmp/logs/immersive_02_Flames_start_0/val_videos/30/rgb' output_video_path = 'output_video.mp4' fps = 12 create_video_from_images(image_folder, output_video_path, fps) -
如果不是在远程服务器上运行,还可以启动 scripts 文件夹下的 demo 脚本体验实时交互。
实验结果:
HyperReel复现flames渲染结果
ImportError undefined symbol: iJIT_NotifyEvent encountered when MKL 2024.1 is installed. #123097 ↩︎
ImportError undefined symbol: iJIT_NotifyEvent encountered when MKL 2024.1 is installed. #123097 ↩︎
[Bug]: RuntimeError: cannot import name ‘_compare_version’ from ‘torchmetrics.utilities.imports’ #11648 ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









