







目录
vid2vid
Paper: Wang T C, Liu M Y, Zhu J Y, et al. Video-to-video synthesis[J]. arXiv preprint arXiv:1808.06601, 2018.
Introduction: https://tcwang0509.github.io/vid2vid/
Code: https://github.com/NVIDIA/vid2vid
Video-to-video 是 Nvidia 提出的一种视频到视频的生成模型,通过生成对抗网络架构,学习源视频到输出视频的映射。具体来说,对生成器应用马尔科夫假设,并在判别器引入时间连续性判别,从而保证输出视频的时间连续性和高质量。
Video-to-video 需要大量的输入 - 输出视频对进行训练,输入可以是分割 mask、草图和姿势。
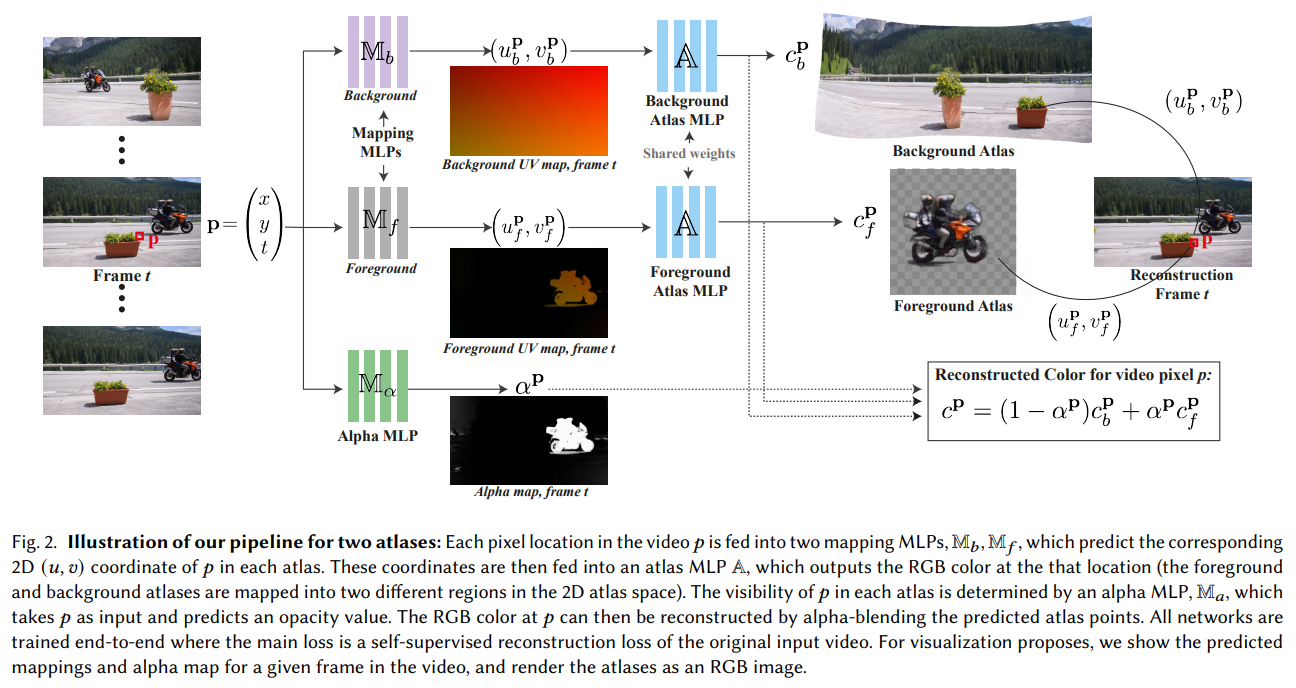
Layered Neural Atlases
Paper: Kasten Y, Ofri D, Wang O, et al. Layered neural atlases for consistent video editing[J]. ACM Transactions on Graphics (TOG), 2021, 40(6): 1-12.
Introduction: https://layered-neural-atlases.github.io/
Code: https://github.com/ykasten/layered-neural-atlases

NLA 通过分层神经图谱 (Layered Neural Atlases) 实现视频编辑的一致性,尤其是在处理复杂场景或具有遮挡的动态视频时。LNA 的核心思想是通过将视频中的对象或场景分解成不同的层,并为每一层生成一个神经图谱存储该层的外观和几何信息,以实现视频中对象或背景的独立编辑。
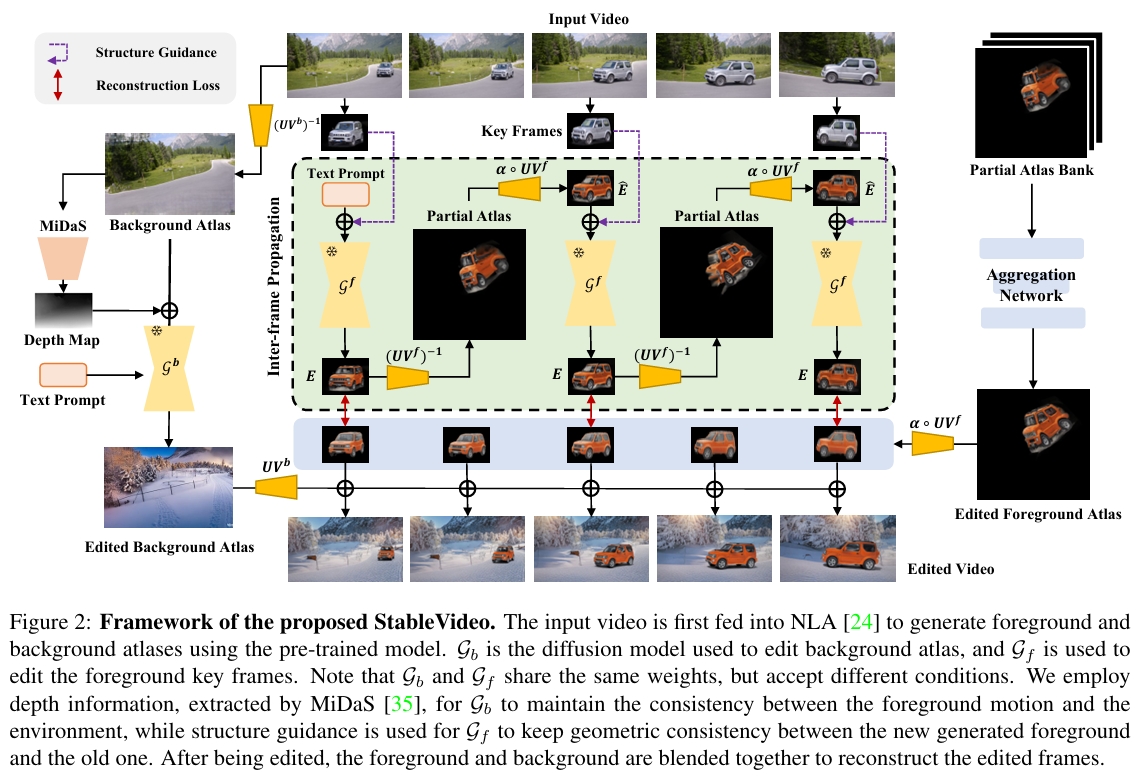
StableVideo
Paper: Chai W, Guo X, Wang G, et al. Stablevideo: Text-driven consistency-aware diffusion video editing[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 23040-23050.
Introduction: https://rese1f.github.io/StableVideo/
Code: https://github.com/rese1f/StableVideo

Stablevideo 在 text-driven diffusion 中引入时间依赖性来解决编辑任务中的帧间不连续性。具体来说,Stablevideo 先使用 NLA 将视频的前景和背景分离,然后对前景和背景分别应用 text-driven diffusion 进行编辑。为了保证帧间连续性,在前景编辑中还引入了帧间传播机制 (inter-frame propagation mechanism),将当前帧的物体外观信息传播到下一帧:
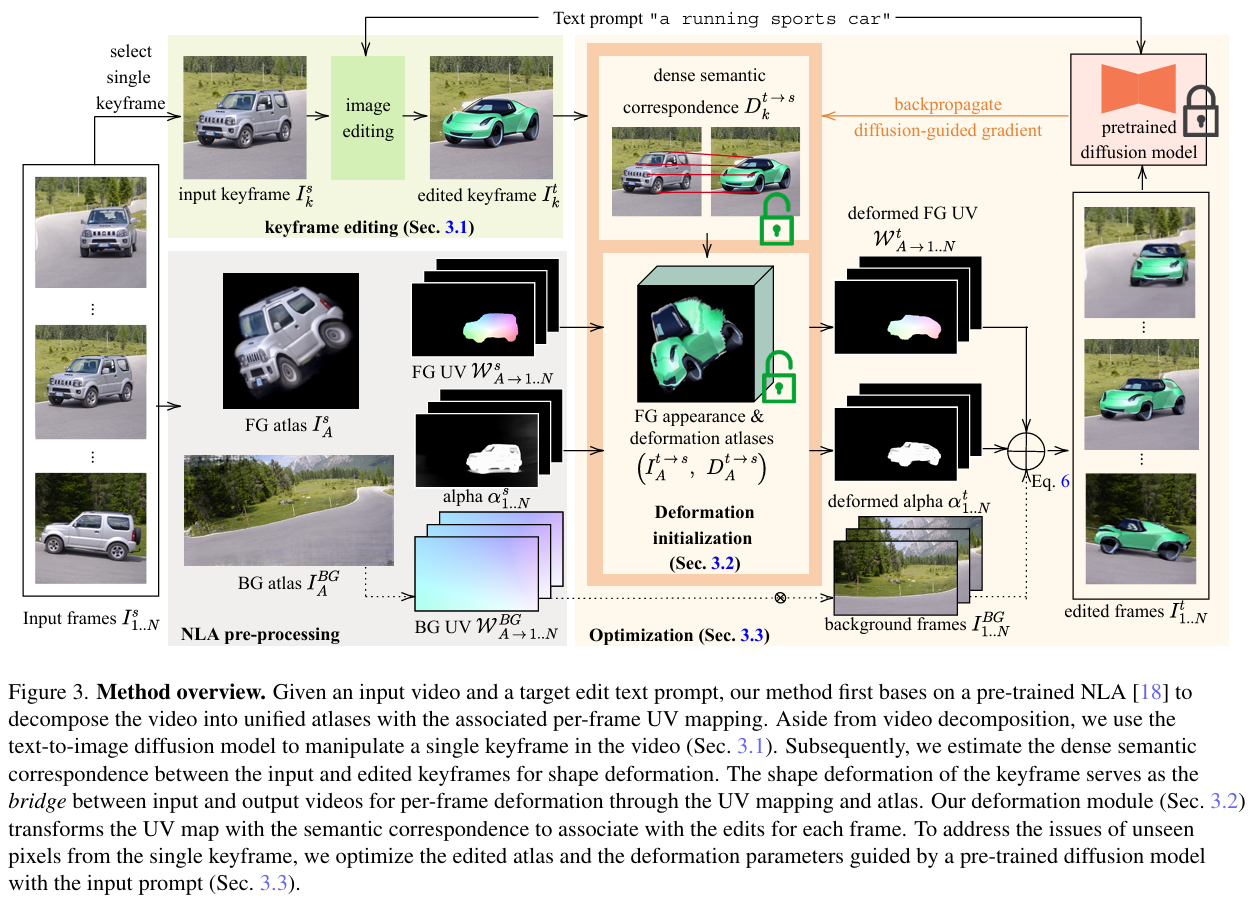
Text video edit
Paper: Lee Y C, Jang J Z G, Chen Y T, et al. Shape-aware text-driven layered video editing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 14317-14326.
Introduction: https://text-video-edit.github.io/
Code: https://github.com/text-video-edit/shape-aware-text-driven-layered-video-editing-release

现有的视频编辑方法依赖 UV 映射场修复纹理以完成物体外观的编辑,但在形状编辑任务上难以实现,Text video edit 提出了一种形状感知、基于文本的视频编辑方法来解决这一难题。具体来说,Text video edit 先使用 NLA 将视频的前景和背景分离;在编辑前景时,训练一个关键帧与编辑后关键帧之间的变形场,实现对整个视频的形状和外观一致的编辑;最后借助预训练的 text-driven diffusion,进一步优化形状失真并补全未见区域。
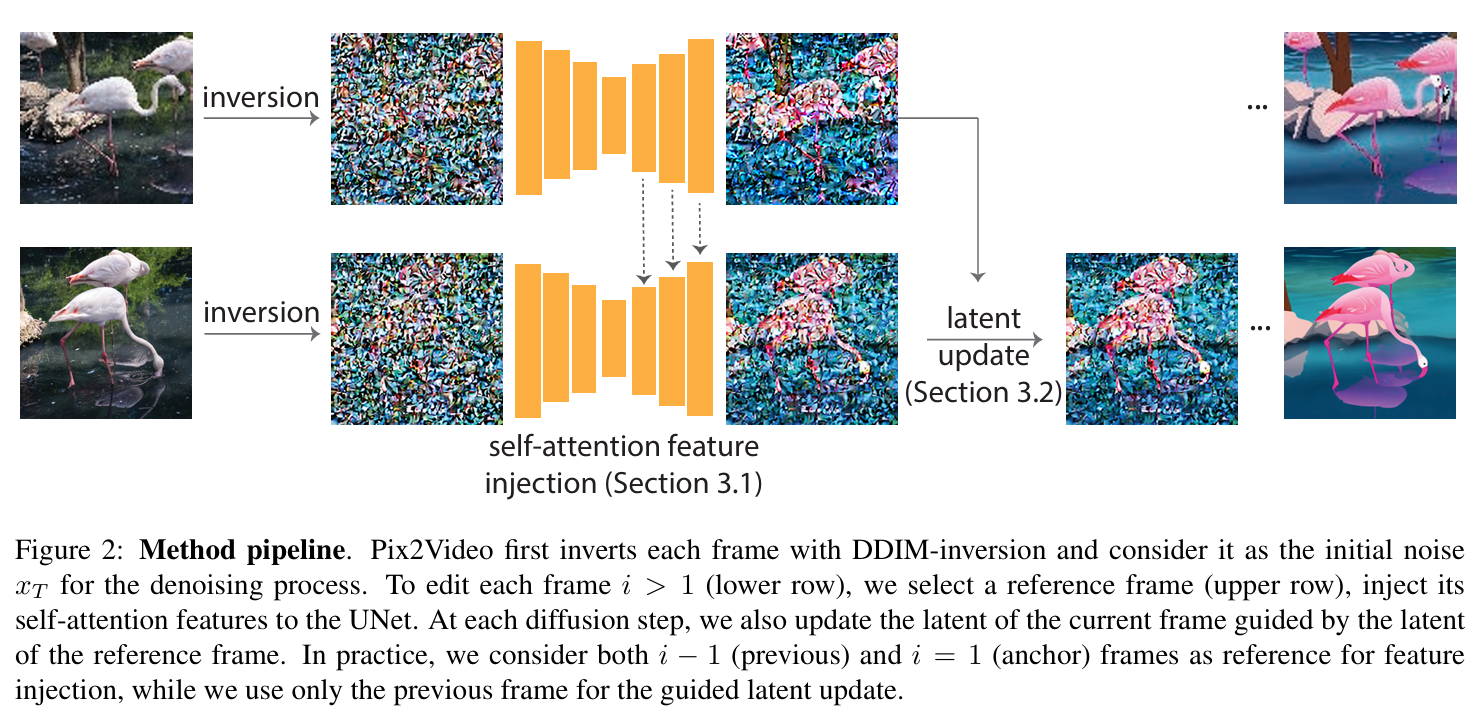
pix2video
Paper: Ceylan D, Huang C H P, Mitra N J. Pix2video: Video editing using image diffusion[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 23206-23217.
Introduction: Unreleased
Code: https://github.com/duyguceylan/pix2video

pix2video 将文本引导的视频编辑任务 (text-guided video editing) 分为两个步骤:
- 在锚点帧上使用预训练的结构引导(如深度)模型进行编辑;
- 在关键步骤,通过自注意力特征注入逐步将更改传播到其他帧。
Dreamix
Paper: Molad E, Horwitz E, Valevski D, et al. Dreamix: Video diffusion models are general video editors[J]. arXiv preprint arXiv:2302.01329, 2023.
Introduction: https://dreamix-video-editing.github.io/
Code: Unreleased
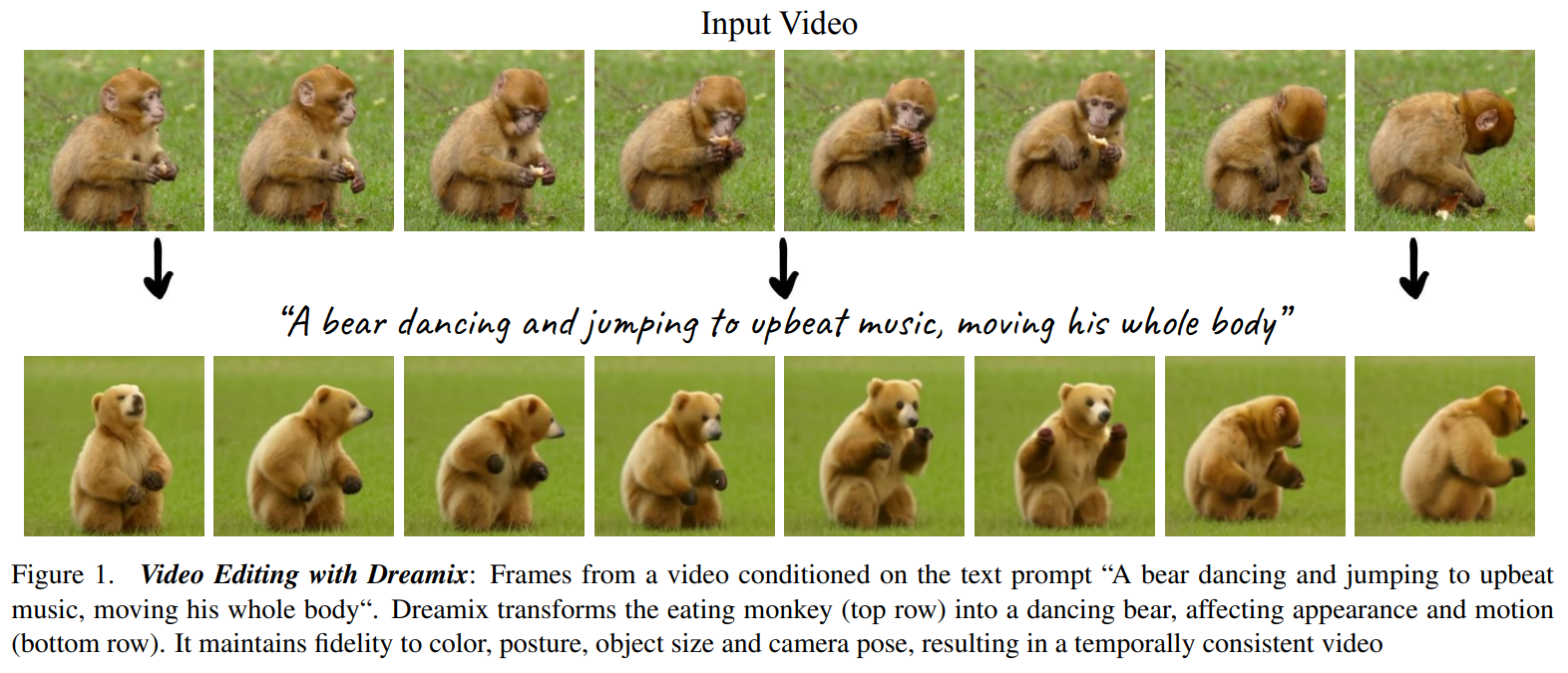
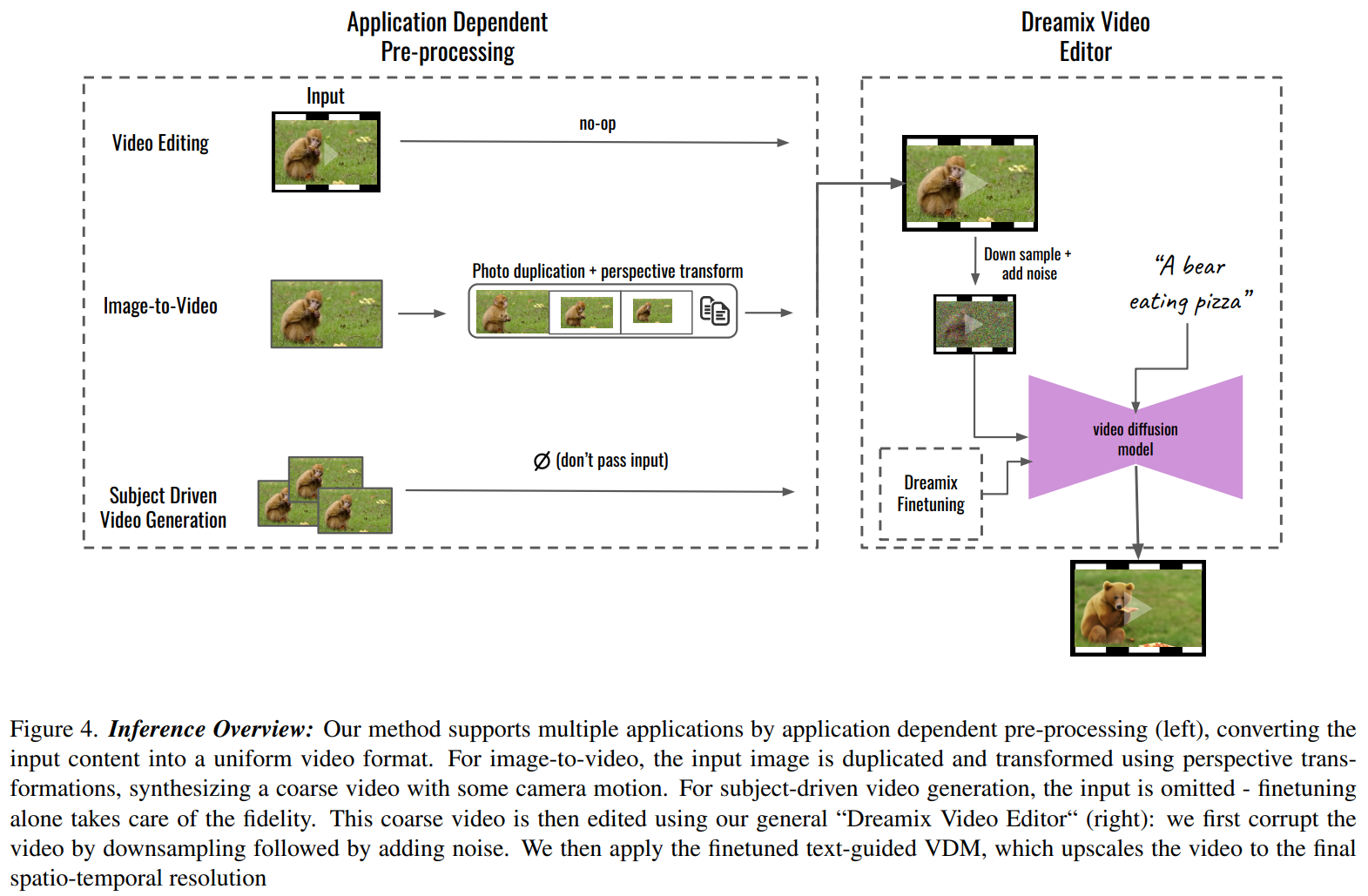
Dreamix 是一种基于 diffusion 的通用视频编辑框架,允许用户通过文本、图像等条件输入,对视频进行广泛的修改和控制。具体来说,Dreamix 基于 diffusion 框架,在编辑过程中结合低分辨率时空信息与高分辨率生成信息,并使用时空注意力机制以保持帧间的时间和空间一致性。
vid2vid-zero
Paper: Wang W, Jiang Y, Xie K, et al. Zero-shot video editing using off-the-shelf image diffusion models[J]. arXiv preprint arXiv:2303.17599, 2023.
Introduction: Unreleased
Code: https://github.com/baaivision/vid2vid-zero
Edit a video
Paper: Shin C, Kim H, Lee C H, et al. Edit-a-video: Single video editing with object-aware consistency[C]//Asian Conference on Machine Learning. PMLR, 2024: 1215-1230.
Introduction: https://editavideo.github.io/
Code: Unreleased
Tokenflow
Paper: Geyer M, Bar-Tal O, Bagon S, et al. Tokenflow: Consistent diffusion features for consistent video editing[J]. arXiv preprint arXiv:2307.10373, 2023.
Introduction: https://diffusion-tokenflow.github.io/
Code: https://github.com/omerbt/TokenFlow
NVEdit
Paper: Yang S, Mou C, Yu J, et al. Neural video fields editing[J]. arXiv preprint arXiv:2312.08882, 2023.
Introduction: https://nvedit.github.io/
Code: Unreleased
Flatten
Paper: Cong Y, Xu M, Simon C, et al. Flatten: optical flow-guided attention for consistent text-to-video editing[J]. arXiv preprint arXiv:2310.05922, 2023.
Introduction: https://flatten-video-editing.github.io/
Code: https://github.com/yrcong/flatten

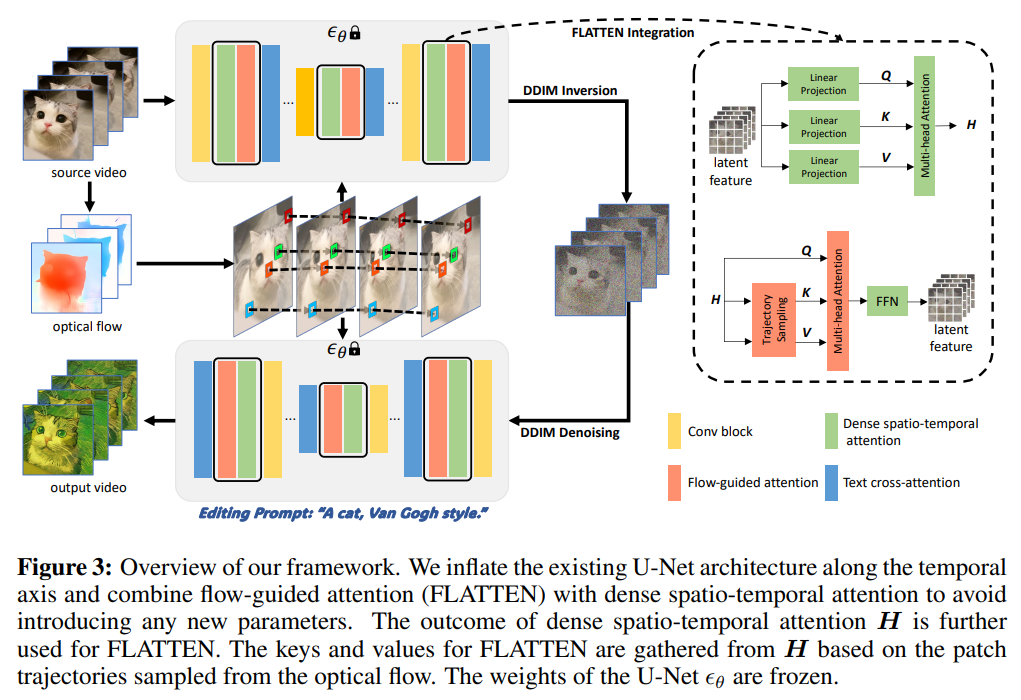
FLATTEN 是一种文本驱动的视频编辑方法,通过在扩展的U-Net架构中引入光流来指导注意力机制,用于解决视频编辑中帧间不一致问题。具体实现中,FLATTEN 将光流信息引入 U-Net 扩展的时空注意力模块中,确保同一物体在不同帧中的特征能够相互关联。FLATTEN 使用光流引导注意力机制,而不用增加新的可训练参数,使得该方法能够无缝集成到现有的基于扩散模型的文本生成视频框架中。
CCEdit
Paper: Feng R, Weng W, Wang Y, et al. Ccedit: Creative and controllable video editing via diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 6712-6722.
Introduction: https://ruoyufeng.github.io/CCEdit.github.io/
Code: https://github.com/RuoyuFeng/CCEdit
Video-p2p
Paper: Liu S, Zhang Y, Li W, et al. Video-p2p: Video editing with cross-attention control[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 8599-8608.
Introduction: https://video-p2p.github.io/
Code: https://github.com/ShaoTengLiu/Video-P2P
EVA
Paper: Yang X, Zhu L, Fan H, et al. EVA: Zero-shot Accurate Attributes and Multi-Object Video Editing[J]. arXiv preprint arXiv:2403.16111, 2024.
Introduction: https://knightyxp.github.io/EVA/
Code: Unreleased


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









