






目录
一、雪花算法生成规则
1.1、图解生成规则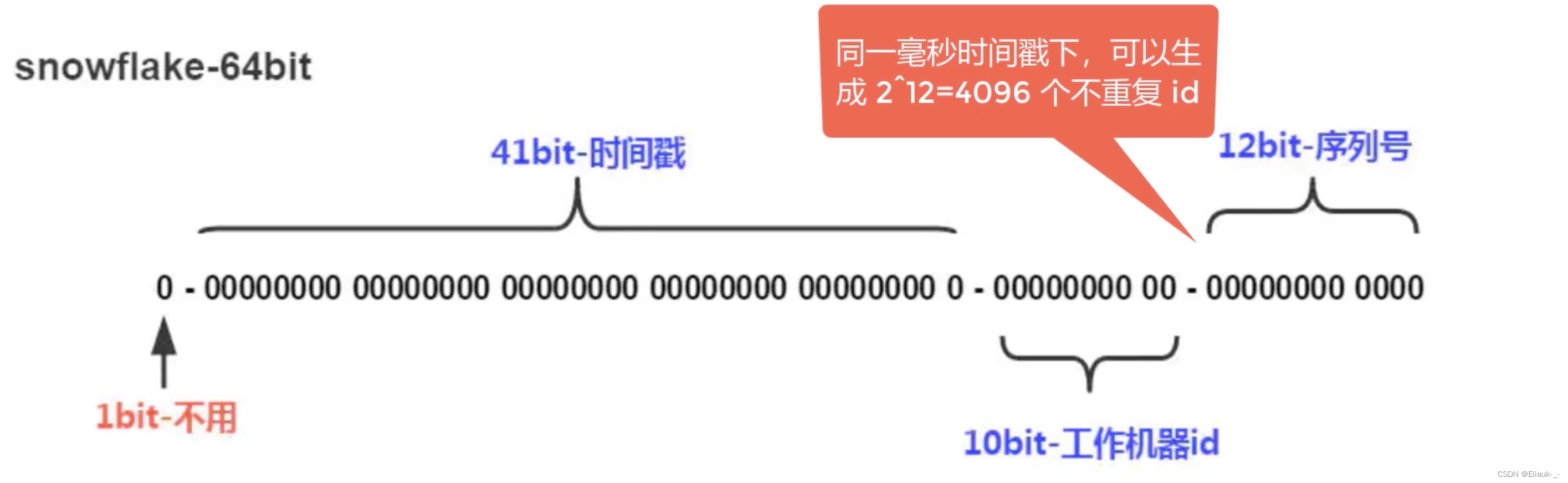
- 最高1位固定值0,因为生成的 id 是正整数,如果是1就是负数了。
- 接下来41位存储毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用69年。
- 再接下10位存储机器码,包括5位 datacenterId 和5位 workerId,最多可以部署2^10=1024台机器。
- 最后12位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成2^12=4096个不重复 id。
1.2、文字解释生成规则
(41bit-时间戳)+(10bit-工作机器id)+(12bit-序列号(统一毫秒时间错下,递增到做大值(最大值4096),自增到最大值后会阻塞到下一毫秒))最后转化成long类型。
二、使用hutool工具类生成雪花算法
//雪花算法生成流水号(参数一:数据中心Id,参数二:机器Id)
IdUtil.getSnowflake(1,1).nextId()三、雪花算法问题
3.1、数据中心,机器ID怎么设置
方案一:利用redis自增序列。
方案二:利用数据库,为每台机器分配workId,报错ip和workId的关系。
3.2、时钟回拨
举例:机器时间是3点,北京时间是2点,此时需要把机器时间调成2点,那么2点~3点的ID会重新生成一遍。
解决方案:修改机器时间后暂停机器服务,等到三点开启。
四、雪花算法优缺点和注意事项
4.1、雪花算法优点
- 高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
- 基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
- 不依赖第三方库或者中间件。
- 算法简单,在内存中进行,效率高。
4.2、雪花算法缺点
- 依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
4.3、注意事项
- 雪花算法每一部分占用的比特位数量并不是固定死的。例如你的业务可能达不到69年之久,那么可用减少时间戳占用的位数,雪花算法服务需要部署的节点超过1024台,那么可将减少的位数补充给机器码用。
- 雪花算法中41位比特位不是直接用来存储当前服务器毫秒时间戳的,而是需要当前服务器时间戳减去某一个初始时间戳值,一般可以使用服务上线时间作为初始时间戳值。
- 对于机器码,可根据自身情况做调整,例如机房号,服务器号,业务号,机器 IP 等都是可使用的。对于部署的不同雪花算法服务中,最后计算出来的机器码能区分开来即可。
















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









