






1、CountDownLatch:
如果我们知道了我们的需要执行的任务数,那么我们可以用java并发包下的CountDownLatch,直接上代码:
public class CountDownLaunch {
private static final Executor executor = Executors.newFixedThreadPool(2);
public static void main(String[] args) {
CountDownLaunch.concurrencyTest();
}
/**
* 要求并行执行完thread1、thread2才能执行
* thread3
*/
private static void concurrencyTest() {
// 创建一个count为2的CountDownLatch对象
CountDownLatch countDownLatch = new CountDownLatch(2);
// 并行执行以下2块代码,
executor.execute(()->{
System.out.println("thread1");
// 每次任务执行完count -1
countDownLatch.countDown();
});
executor.execute(()->{
System.out.println("thread2");
// 每次任务执行完count -1
countDownLatch.countDown();
});
try {// 阻塞等待上面任务执行完,也就是count值为0/或线程被中断
countDownLatch.await();
System.out.println("thread3");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}2、CompletableFuture:
语意更加清晰,如 f3 = f1.thenCombine(f2, ()->{}) 能够清晰地表述“任务 3 要等待任务 1 和任务 2 都完成后才能开始,代码演示:
public class CompletableFutureTest {
public static void main(String[] args) {
CompletableFutureTest.testCompletableFuture();
}
private static void testCompletableFuture() {
ThreadPoolExecutor threadPoolExecutor = ThreadPoolTest.getThreadPoolExecutor();
// 从自定义线程池拿去线程异步处理数据
CompletableFuture<String> CompletableFuture1 = CompletableFuture.supplyAsync(()->{
System.out.println("thread1");
return "thread1";
}, threadPoolExecutor);
// 从自定义线程池拿去线程异步处理数据
CompletableFuture<String> CompletableFuture2 = CompletableFuture.supplyAsync(()->{
System.out.println("thread2");
return "thread2";
}, threadPoolExecutor);
System.out.println("thread3");
try {
// 这一步表示要CompletableFuture3的执行依赖于CompletableFuture1/CompletableFuture2执行成功
CompletableFuture<String> CompletableFuture3 = CompletableFuture1.thenCombine(CompletableFuture2, (string1,string2)->{
return string1+string2;
});
// 阻塞等待CompletableFuture3的结果
String join = CompletableFuture3.join();
System.out.println(join);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}创建CompletableFuture的4种方式:
//使用默认线程池
static CompletableFuture<Void>
runAsync(Runnable runnable)
static <U> CompletableFuture<U>
supplyAsync(Supplier<U> supplier)
//可以指定线程池
static CompletableFuture<Void>
runAsync(Runnable runnable, Executor executor)
static <U> CompletableFuture<U>
supplyAsync(Supplier<U> supplier, Executor executor) 默认情况下CompletableFuture使用的是公共的线程池forkJoinPool,那这个线程池默认创建的线程数是cpu的核数,在实际情况下,如果所有 CompletableFuture 共享一个线程池,那么一旦有任务执行一些很慢的 I/O 操作,就会导致线程池中所有线程都阻塞在 I/O 操作上,从而造成线程饥饿,进而影响整个系统的性能。所以,强烈建议你要根据不同的业务类型创建不同的线程池,以避免互相干扰。
创建完 CompletableFuture 对象之后,会自动地异步执行 runnable.run() 方法或者 supplier.get() 方法,对于一个异步操作,你需要关注两个问题:一个是异步操作什么时候结束,另一个是如何获取异步操作的执行结果。因为 CompletableFuture 类实现了 Future 接口,所以这两个问题你都可以通过 Future 接口来解决。
CompletableFuture .get()源码介绍: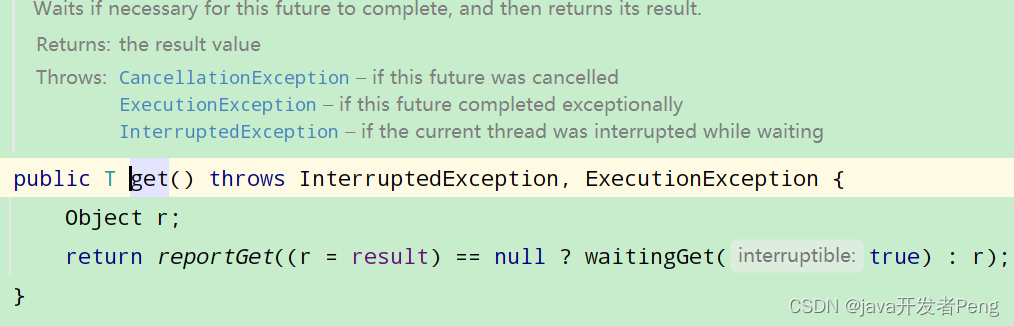
3、并发编程的可见性,有序性问题:
举例:2个线程并发将一个值count加到20000,结果你会发现,加的值小于20000;
指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
指令 2:之后,在寄存器中执行 +1 操作;
指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
所以当其中一个线程进行+1操作后只是刷到了cpu缓存还没有刷到内存中,另一个线程去执行+1操作时是不会取到最新的值,进而导致最后的结果小于20000。
所以根本原因:系统层面->cpu缓存导致了线程的可见性,导致有序性的原因是编译优化
如何解决可见性问题:
那解决可见性、有序性最直接的办法就是禁用缓存和编译优化,但是这样问题虽然解决了,我们程序的性能可就堪忧了。
合理的方案应该是按需禁用缓存以及编译优化->具体来说这些方法包括 volatile、synchronized 和 final 三个关键字。
Happens-Before 规则:
前面一个操作的结果对后续操作是可见的,Happens-Before 约束了编译器的优化行为,虽允许编译器优化,但是要求编译器优化后一定遵守 Happens-Before 规则。
volatile:禁用cpu缓存,确保线程之间共享变量的可见性;
synchronized:在synchronized关键字对共享变量用代码块加锁,由于Happen-before管程锁的规则,可以使得后续的线程可以看到abc的值。


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









