






 本文介绍了SpringBoot中数据访问的自动配置,包括HikariDataSource的使用,JDBC的自动配置,Druid数据源的集成及其监控功能,以及Dubbo和Redis的分布式应用。涵盖了配置、测试和实战案例。
本文介绍了SpringBoot中数据访问的自动配置,包括HikariDataSource的使用,JDBC的自动配置,Druid数据源的集成及其监控功能,以及Dubbo和Redis的分布式应用。涵盖了配置、测试和实战案例。
06、数据访问
1、SQL
1、数据源的自动配置-HikariDataSource
1、导入JDBC场景
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
导入JDBC场景的起动器会帮我们导入了这些组件,比如 数据源HikariDataSource,我们就可以在数据源里获取数据库连接做增删改查的操作。

数据库驱动为什么没有导入?
为什么导入JDBC场景,官方不导入驱动?官方不知道我们接下要操作什么数据库Oracle、Myql。
数据库版本和驱动版本对应
spingboot,Mysql驱动默认版本:<mysql.version>8.0.22</mysql.version>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<!--<version>5.1.49</version>-->
</dependency>
如果Mysql使用的5版本,想要修改版本:两种方式
1、直接依赖引入具体版本(原理:maven的就近依赖原则)
2、重新声明版本(maven的属性的就近优先原则)
<properties>
<java.version>1.8</java.version>
<mysql.version>5.1.49</mysql.version>
</properties>
2、分析自动配置
1、自动配置的类
帮我们配置底层的数据库连接池,及其他组件
DataSourceAutoConfiguration : 数据源的自动配置
修改数据源相关的配置:spring.datasource
数据库连接池的配置,是自己容器中没有DataSource才自动配置的,利用的@ConditionalOnMissBean注解
数据源:底层配置好的连接池是:HikariDataSource
@Configuration(proxyBeanMethods = false)
@Conditional(PooledDataSourceCondition.class)
@ConditionalOnMissingBean({ DataSource.class, XADataSource.class })
@Import({ DataSourceConfiguration.Hikari.class, DataSourceConfiguration.Tomcat.class,
DataSourceConfiguration.Dbcp2.class, DataSourceConfiguration.OracleUcp.class,
DataSourceConfiguration.Generic.class, DataSourceJmxConfiguration.class })
protected static class PooledDataSourceConfiguration
也帮我们配置了事务的,JdbcTemplate
● DataSourceTransactionManagerAutoConfiguration: 事务管理器的自动配置
● JdbcTemplateAutoConfiguration: JdbcTemplate的自动配置,可以来对数据库进行crud(了解)
○ 可以修改这个配置项@ConfigurationProperties(prefix = "spring.jdbc") 来修改JdbcTemplate
○ 程序启动 会通过@Bean@Primary *自动将JdbcTemplate对象放入容器*;容器中有这个组件
● JndiDataSourceAutoConfiguration: jndi的自动配置
● XADataSourceAutoConfiguration: 分布式事务相关的(了解)
3、修改配置项
数据库连接地址
spring:
datasource:
url: jdbc:mysql://localhost:3306/db_account
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
4、测试
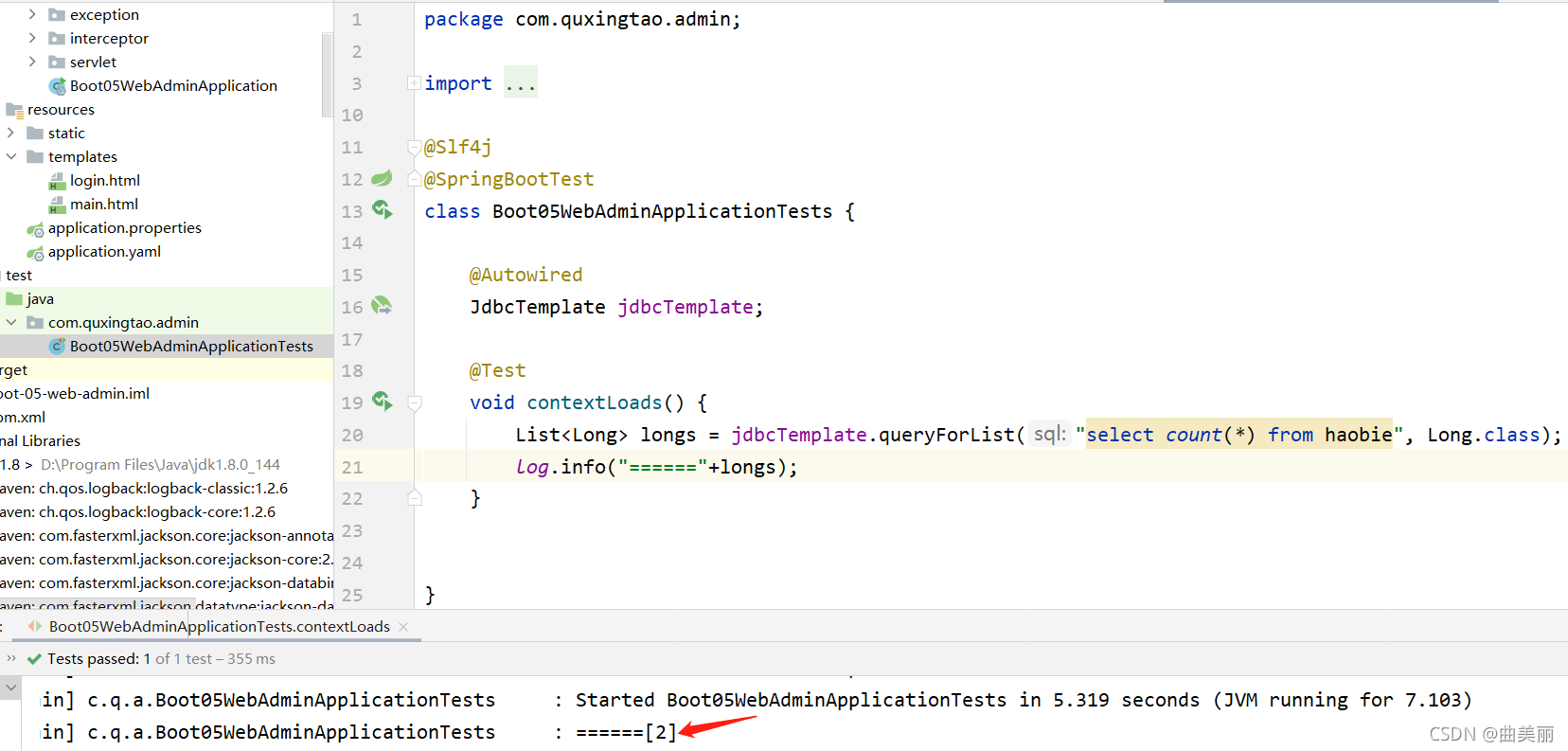
@Slf4j
@SpringBootTest
class Boot05WebAdminApplicationTests {
@Autowired
JdbcTemplate jdbcTemplate;
@Test
void contextLoads() {
// jdbcTemplate.queryForObject("select * from account_tbl")
// jdbcTemplate.queryForList("select * from account_tbl",)
Long aLong = jdbcTemplate.queryForObject("select count(*) from account_tbl", Long.class);
log.info("记录总数:{}",aLong);
}
}
2、使用Druid数据源(阿里,第三方)
1、druid官方github地址
https://github.com/alibaba/druid
整合第三方技术的两种方式
自定义
找starter
2、自定义方式
1、创建数据源
引入数据源
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.17</version>
</dependency>
<!--spring boot之前引入Druid数据源的配置-->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"
destroy-method="close">
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<property name="maxActive" value="20" />
<property name="initialSize" value="1" />
<property name="maxWait" value="60000" />
<property name="minIdle" value="1" />
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<property name="minEvictableIdleTimeMillis" value="300000" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="false" />
<property name="testOnReturn" value="false" />
<property name="poolPreparedStatements" value="true" />
<property name="maxOpenPreparedStatements" value="20" />
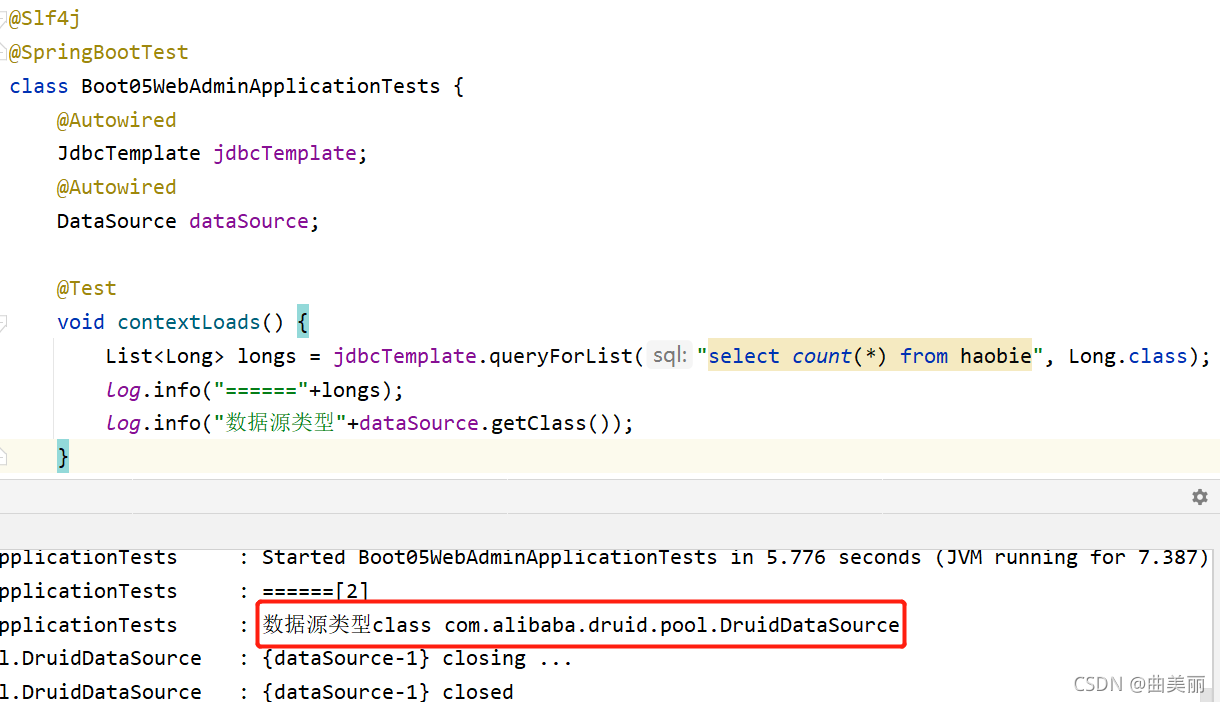
自定义数据源,新建配置类+yaml
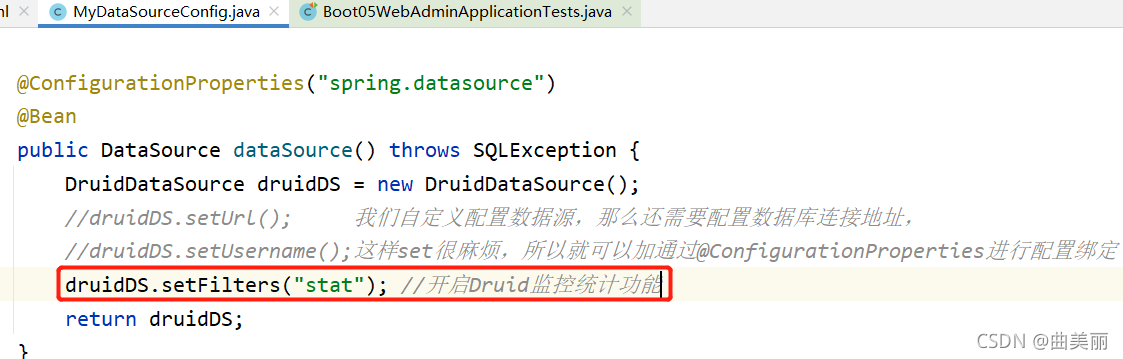
@ConfigurationProperties("spring.datasource") @Bean public DataSource dataSource(){ DruidDataSource druidDS = new DruidDataSource(); //druidDS.setUrl(); 我们自定义配置数据源,那么还需要配置数据库连接地址, //druidDS.setUsername();这样set很麻烦,所以就可以加通过@ConfigurationProperties("spring.datasource")进行配置绑定 return druidDS; } } spring: datasource: url: jdbc:mysql://localhost:3306/his username: root password: 123456 driver-class-name: com.mysql.cj.jdbc.Driver
测试
2、StatViewServlet(Druid的其他功能,开启监控页)
有以下功能:

StatViewServlet的用途包括:
提供监控信息展示的html页面,之前是通过配置StatViewServlet放入容器总 如下xml配置
提供监控信息的JSON API
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
spring boot配置的方式
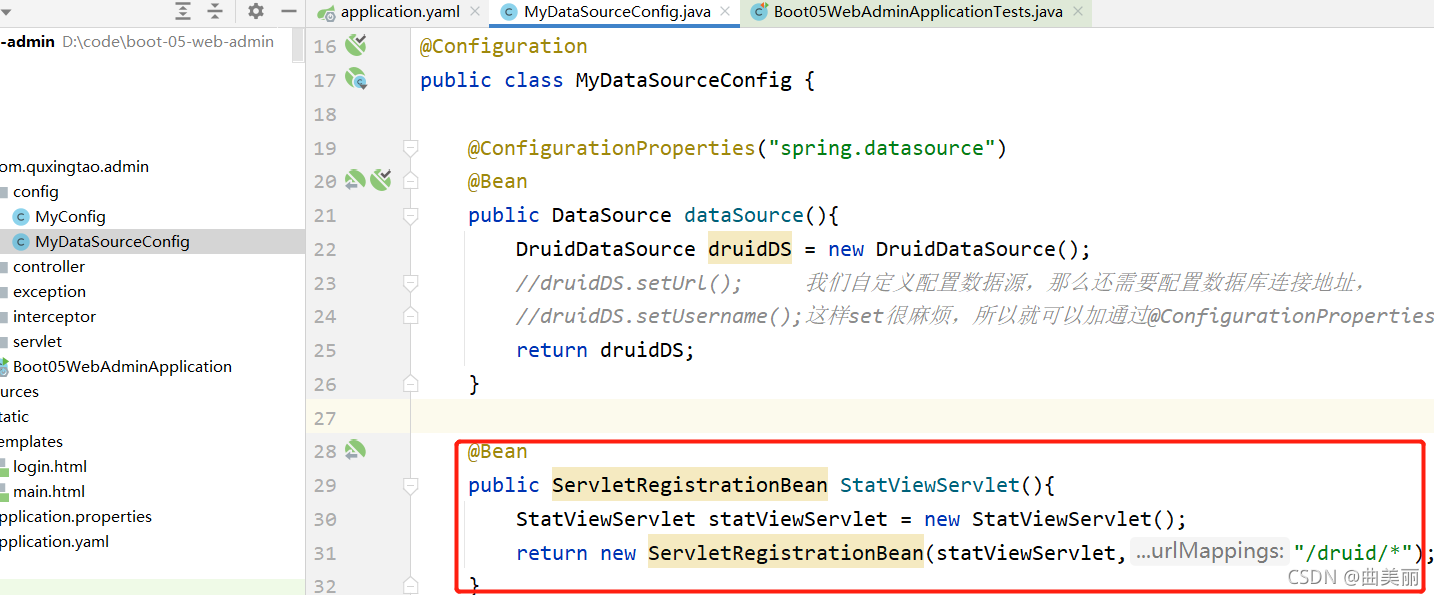
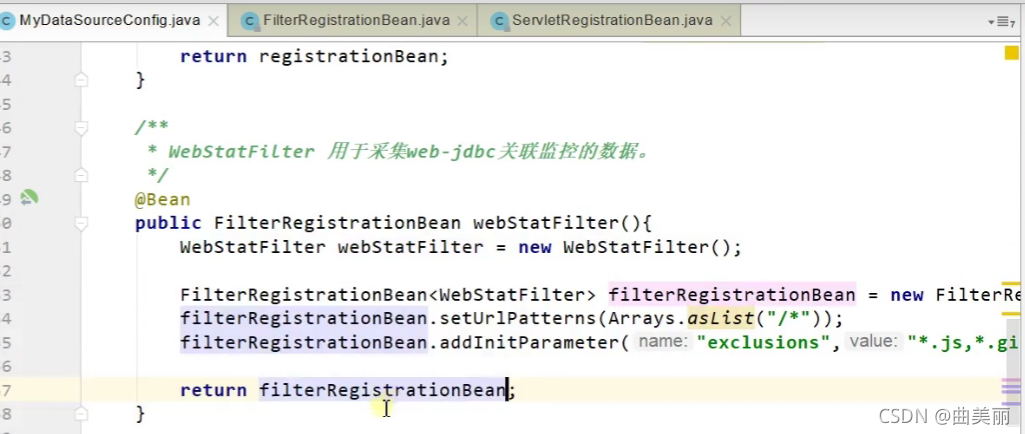
@Bean
public ServletRegistrationBean StatViewServlet(){
StatViewServlet statViewServlet = new StatViewServlet();
return new ServletRegistrationBean(statViewServlet,"/druid/*");
}
启动项目访问
3、StatFilter(监控页中的统计功能)
用于统计监控信息;如SQL监控、URI监控
<!--之前的配置-->
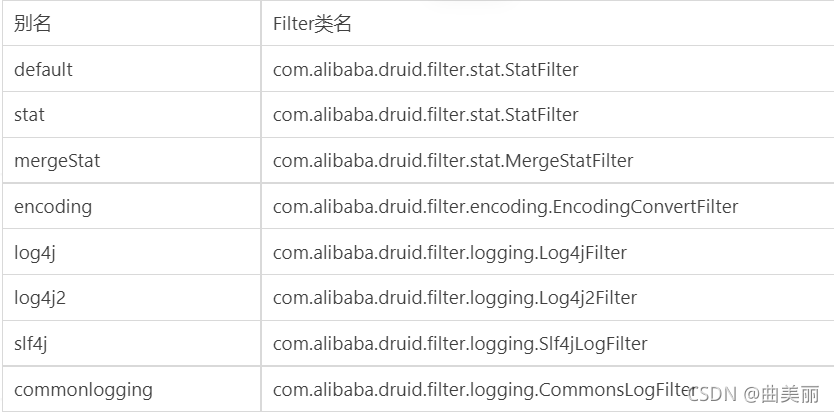
需要给数据源中配置如下属性;可以允许多个filter,多个用,分割;如:
<property name="filters" value="stat,slf4j" />
现在

监控web
系统中所有filter:
慢SQL记录配置
<bean id="stat-filter" class="com.alibaba.druid.filter.stat.StatFilter">
<property name="slowSqlMillis" value="10000" />
<property name="logSlowSql" value="true" />
</bean>
使用 slowSqlMillis 定义慢SQL的时长
3、使用官方starter方式
1、引入druid-starter
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.17</version>
</dependency>
2、分析自动配置
自动配置类DruidDataSourceAutoConfigure
● 配置项 spring.datasource.druid,可以在配置文件中配置
还通过@Import注解导入这几个组件:
● DruidSpringAopConfiguration.class, 监控SpringBean的;配置项:spring.datasource.druid.aop-patterns
● DruidStatViewServletConfiguration.class, 监控页的配置:spring.datasource.druid.stat-view-servlet;默认开启
● DruidWebStatFilterConfiguration.class, web监控配置;spring.datasource.druid.web-stat-filter;默认开启
● DruidFilterConfiguration.class}) 所有Druid自己filter的配置
private static final String FILTER_STAT_PREFIX = "spring.datasource.druid.filter.stat";
private static final String FILTER_CONFIG_PREFIX = "spring.datasource.druid.filter.config";
private static final String FILTER_ENCODING_PREFIX = "spring.datasource.druid.filter.encoding";
private static final String FILTER_SLF4J_PREFIX = "spring.datasource.druid.filter.slf4j";
private static final String FILTER_LOG4J_PREFIX = "spring.datasource.druid.filter.log4j";
private static final String FILTER_LOG4J2_PREFIX = "spring.datasource.druid.filter.log4j2";
private static final String FILTER_COMMONS_LOG_PREFIX = "spring.datasource.druid.filter.commons-log";
private static final String FILTER_WALL_PREFIX = "spring.datasource.druid.filter.wall";
3、配置示例(配置Druid的其他功能)
和"自定义方式"的配置一致,只不过是通过yaml配置文件
spring:
datasource:
url: jdbc:mysql://localhost:3306/db_account
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
druid:
aop-patterns: com.atguigu.admin.* #监控SpringBean
filters: stat,wall # 底层开启功能,stat(sql监控),wall(防火墙)
stat-view-servlet: # 配置监控页功能
enabled: true
login-username: admin
login-password: admin
resetEnable: false
web-stat-filter: # 监控web
enabled: true
urlPattern: /*
exclusions: '*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*'
filter: #filter过滤器中的sql监控配置
stat: # 对上面filters里面的stat的详细配置
slow-sql-millis: 1000 #超过1000毫秒就是慢查询
logSlowSql: true #是否记录慢查询日志
enabled: true
wall: #filter过滤器中的防火墙配置
enabled: true
config:
drop-table-allow: false
SpringBoot配置示例
https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
配置项列表https://github.com/alibaba/druid/wiki/DruidDataSource%E9%85%8D%E7%BD%AE%E5%B1%9E%E6%80%A7%E5%88%97%E8%A1%A8
3、整合MyBatis操作
https://github.com/mybatis
整合MyBatis首先找starter
starter的规则:
SpringBoot官方的Starter:spring-boot-starter-*
第三方的: *-spring-boot-starter
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
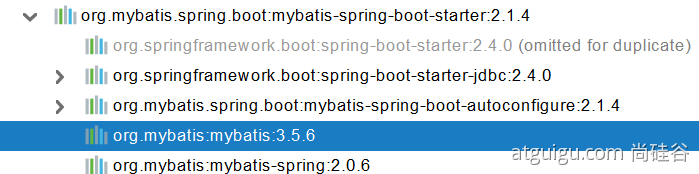
starter引入了以下四个依赖
1、配置模式
分析MybatisAutoConfigurtion的自动配置类
全局配置文件
SqlSessionFactory: 之前需要我们手动建,现在自动配置好了@Bean
SqlSession:自动配置了 SqlSessionTemplate 组合了SqlSession 帮忙我们操作数据库
@Import(AutoConfiguredMapperScannerRegistrar.class);识别Dao层注解,操作持久层
Mapper: 只要我们写的操作MyBatis的接口标准了 @Mapper 就会被自动扫描进来
分析底层源码
@EnableConfigurationProperties(MybatisProperties.class) : MyBatis配置项绑定类。
@AutoConfigureAfter({ DataSourceAutoConfiguration.class, MybatisLanguageDriverAutoConfiguration.class })
public class MybatisAutoConfiguration{}
@ConfigurationProperties(prefix = "mybatis")
public class MybatisProperties
可以修改配置文件中 mybatis 开始的所有;
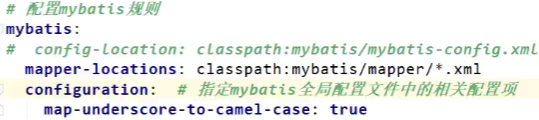
配置mybatis规则
mybatis:
config-location: classpath:mybatis/mybatis-config.xml #全局配置文件位置,可以通过configuration替代配置文件
mapper-locations: classpath:mybatis/mapper/*.xml #sql映射文件位置
dao层接口需要--->绑定Xml:绑定的xml文件中
<mapper namespace="com.quxingtao.admin.mapper.UserInfoMapper">
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.admin.mapper.AccountMapper">
<!-- public Account getAcct(Long id); -->
<select id="getAcct" resultType="com.atguigu.admin.bean.Account">
select * from account_tbl where id=#{id}
</select>
</mapper>
# 配置mybatis规则
mybatis:
# config-location: classpath:mybatis/mybatis-config.xml
mapper-locations: classpath:mybatis/mapper/*.xml
configuration:
map-underscore-to-camel-case: true
可以不写全局;配置文件,所有全局配置文件的配置都放在configuration配置项中即可
导入mybatis官方starter
编写mapper接口。标准@Mapper注解
编写sql映射文件并绑定mapper接口
在application.yaml中指定Mapper配置文件的位置,以及指定全局配置文件的信息 (建议;配置在application.yaml中mybatis.configuration)
流程:mybatis全局配置文件–>实体类–>dao接口–>接口的xml映射文件–>yaml中指定mybatis的配置
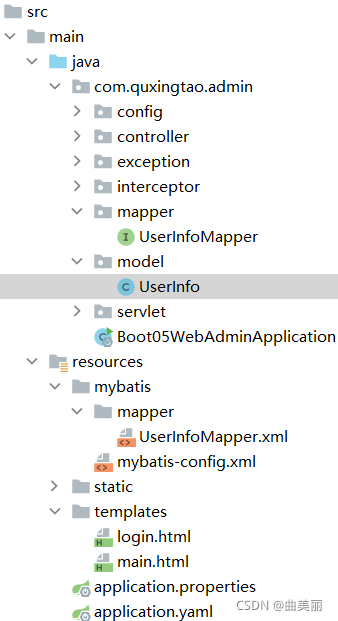
1、演示:
目录结构
<!--Mybatis的全局配置文件-->
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
</configuration>
//实体类
@Data
public class UserInfo {
private Long userId;
private String userName;
private String userPass;
private String role;
}
//dao层接口
@Mapper
public interface UserInfoMapper {
public UserInfo getUserInfo(Long id);
}
//接口的映射文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.admin.mapper.AccountMapper">
<!-- public UserInfo getUserInfo(Long id); -->
<select id="getUserInfo" resultType="com.quxingtao.admin.model.UserInfo">
select * from userinfo where userid=#{id}
</select>
</mapper>
spring:
datasource:
url: jdbc:mysql://localhost:3306/his
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:
mapper-locations: classpath:mybatis/mapper/*.xml
# 以上几步中的mybatis-config.xml全局配置文件可以不使用,所有全局配置文件的配置都放在下面这个configuration配置项中即可
configuration:
map-underscore-to-camel-case: true #开启mybatis的驼峰命名法,表中的user_id映射到实体的userId
//controller页面用于测试
@Controller
public class IndexController {
@Autowired
private IndexService indexService;
/*
* 登录页
* */
@ResponseBody
@GetMapping({"/","/login"})
public UserInfo loginIndex(@RequestParam("id") Long id){
return indexService.getUserInfo(id);
}
}
@Service
public class IndexService {
@Autowired
private UserInfoMapper userInfoMapper;
public UserInfo getUserInfo(Long id){
UserInfo userInfo = userInfoMapper.getUserInfo(id);
return userInfo;
}
}
浏览器返回结果:
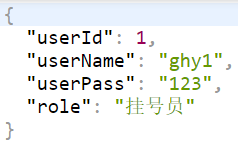
注意:数据的字段如果是user_id 在映射到实体类字段userId会映射不上,因为Mybatis的驼峰命名法默认为false,
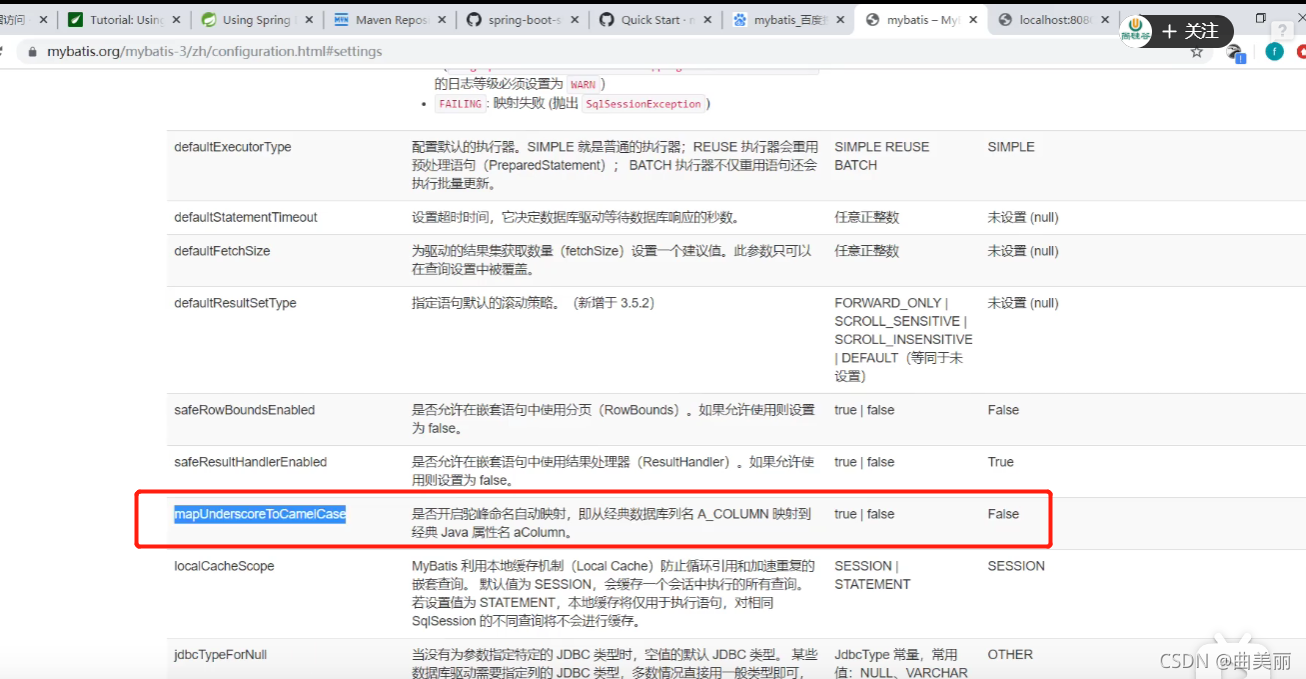
这样配置
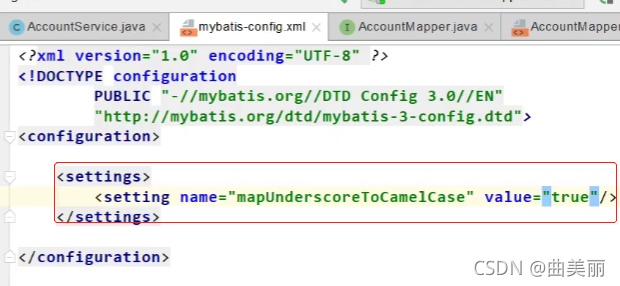
配置 private Configuration configuration; mybatis.configuration下面的所有,就是相当于改mybatis全局配置文件中的值,所以这种方式也是可以的
2、注解模式
在dao层接口通过注解写sql,就不需要为dao绑定xml文件了。
@Mapper
public interface CityMapper {
@Select("select * from city where id=#{id}")
public City getById(Long id);
}
3、混合模式
@Mapper
public interface CityMapper {
@Select("select * from city where id=#{id}")
public City getById(Long id);
public void save(City city);
}
<!--CityMapper.xml文件-->
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.quxingtao.admin.mapper.CityMapper">
<!--public void save(City city);-->
<insert id="save" useGeneratedKeys="true" keyProperty="id">
insert into city(`name`,`state`,`country`) values (#{name},#{state},#{country})
</insert>
</mapper>
现在对象拿到数据库自增的id,也可以使用纯注解方式,和上面xml一样
@Mapper
public interface CityMapper {
@Select("select * from city where id=#{id}")
public City findById(Long id);
@Insert("insert into city(`name`,`state`,`country`) values (#{name},#{state},#{country})")
@Options(useGeneratedKeys = true, keyProperty = "id")
public void save(City city);
}
最佳实战:
引入mybatis-starter
配置application.yaml中,通过mapper-location指定dao层的绑定xml位置即可
编写Mapper接口并标注@Mapper注解
简单方法直接注解方式
复杂方法编写mapper.xml进行绑定映射
@MapperScan("com.atguigu.admin.mapper") 简化,其他的接口就可以不用标注@Mapper注解
4、整合 MyBatis-Plus 完成CRUD
1、什么是MyBatis-Plus
MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
mybatis plus 官网
建议安装 MybatisX 插件
2、整合MyBatis-Plus
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
自动配置
MybatisPlusAutoConfiguration 配置类,MybatisPlusProperties 配置项绑定。mybatis-plus:xxx 就是对mybatis-plus的定制
SqlSessionFactory 自动配置好。底层是容器中默认的数据源
mapperLocations 自动配置好的。有默认值。classpath*:/mapper/**/*.xml;任意包的类路径下的所有mapper文件夹下任意路径下的所有xml都是sql映射文件。 建议以后sql映射文件,放在 mapper下
容器中也自动配置好了 SqlSessionTemplate
dao层接口的@Mapper也可以不写;建议直接 在启动类上加@MapperScan("com.atguigu.admin.mapper") 批量扫描就行
优点:
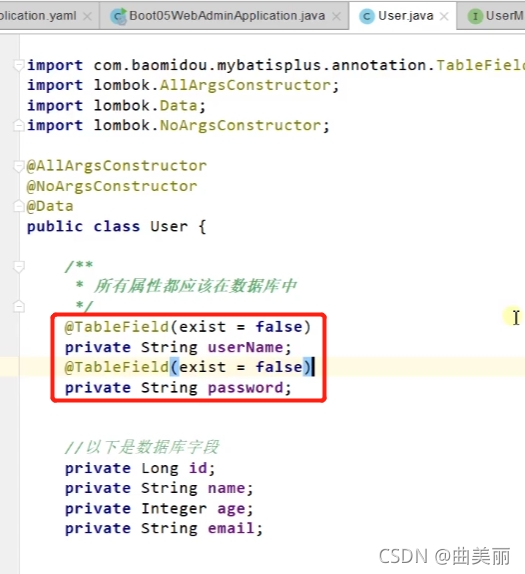
只需要我们的Mapper继承 BaseMapper 就可以拥有crud能力
在使用父类base的selectById时,映射的实体类有不是表中的属性时会报错,可以把实体类的字段加一个注解
使用mybatis-plus时,如果实体类的类名和表名不对应时可以使用mybatis-plus的注解@TableName("")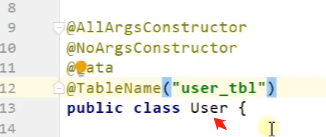
3、CRUD功能
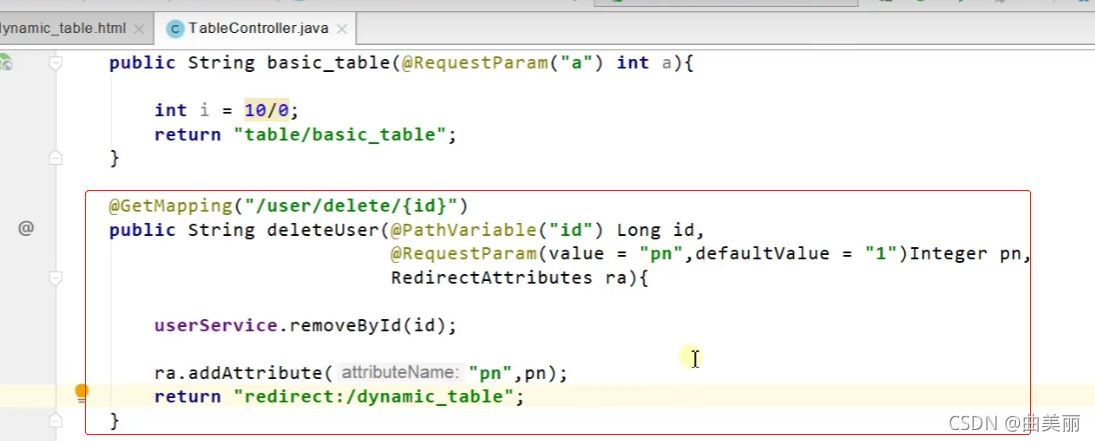
@GetMapping("/user/delete/{id}")
public String deleteUser(@PathVariable("id") Long id,
@RequestParam(value = "pn",defaultValue = "1")Integer pn,
RedirectAttributes ra){
userService.removeById(id);
ra.addAttribute("pn",pn);
return "redirect:/dynamic_table";
}
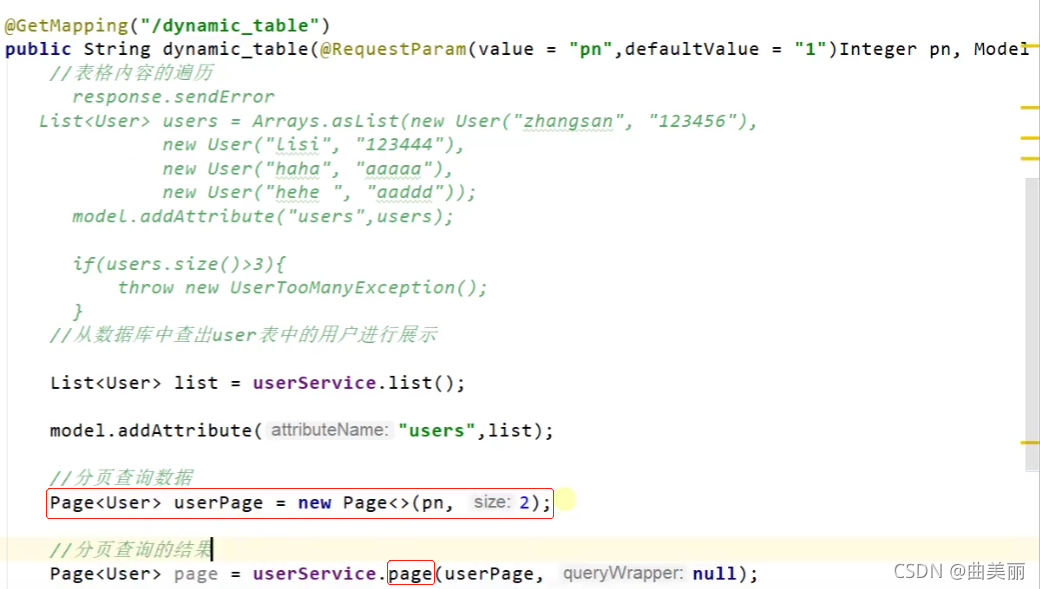
@GetMapping("/dynamic_table")
public String dynamic_table(@RequestParam(value="pn",defaultValue = "1") Integer pn,Model model){
//表格内容的遍历
// response.sendError
// List<User> users = Arrays.asList(new User("zhangsan", "123456"),
// new User("lisi", "123444"),
// new User("haha", "aaaaa"),
// new User("hehe ", "aaddd"));
// model.addAttribute("users",users);
//
// if(users.size()>3){
// throw new UserTooManyException();
// }
//从数据库中查出user表中的用户进行展示
//构造分页参数
Page<User> page = new Page<>(pn, 2);
//调用page进行分页
Page<User> userPage = userService.page(page, null);
// userPage.getRecords()
// userPage.getCurrent()
// userPage.getPages()
model.addAttribute("users",userPage);
return "table/dynamic_table";
}
按照规范service层我们应该写一个接口,然后实现类去实现接口中的方法,但是总是这么做太麻烦,所以mybatis-plus给我们提供了一个service接口的总接口类,并为总接口提供了总实现类。
//dao层接口。实现dao层总接口,BaseMapper 需指明类型
@Mapper
public interface CityMapper extends BaseMapper<City> {
}
//service实现类,实现本身的service接口,并为service总接口继承总实现类ServiceImpl,需要两个类型
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper,User> implements UserService {
}
//service接口 实现mybatis-plus的总接口 需要指明处理的类型
public interface UserService extends IService<User> {
}
//controller层拿到service接口直接调取方法即可
@RestController
public class CityController {
@Autowired
private CityService cityService;
}
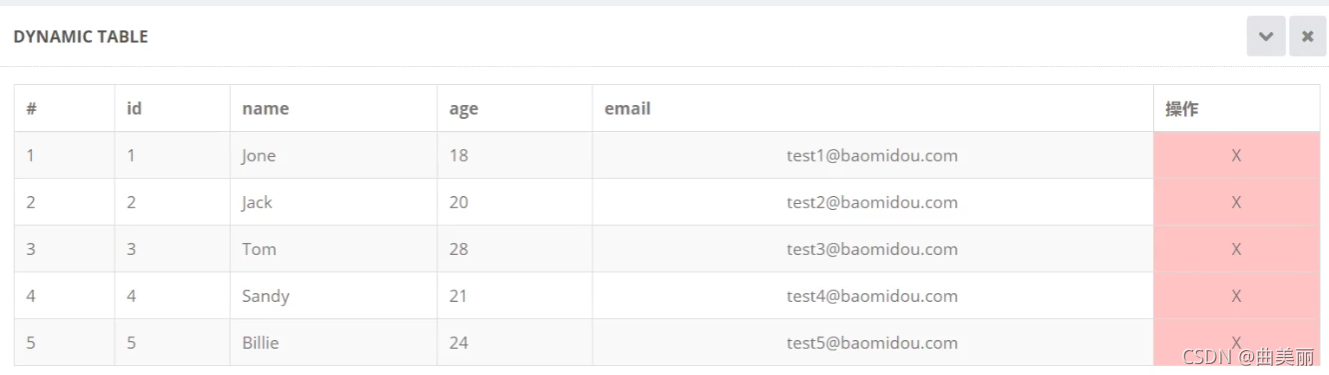
演示: 拿到user表中的信息,展示到页面

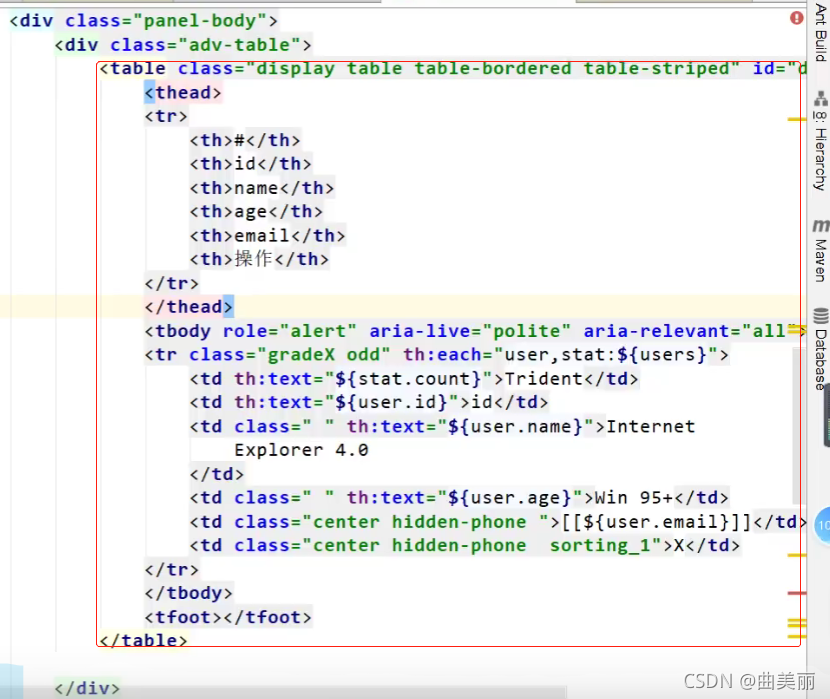
分页可以使用总接口提供的page方法,为这个方法提供一个分页对象,里面是页数和每页大小,返回只一个分页对象,最后放到modle中,页面就可以用了

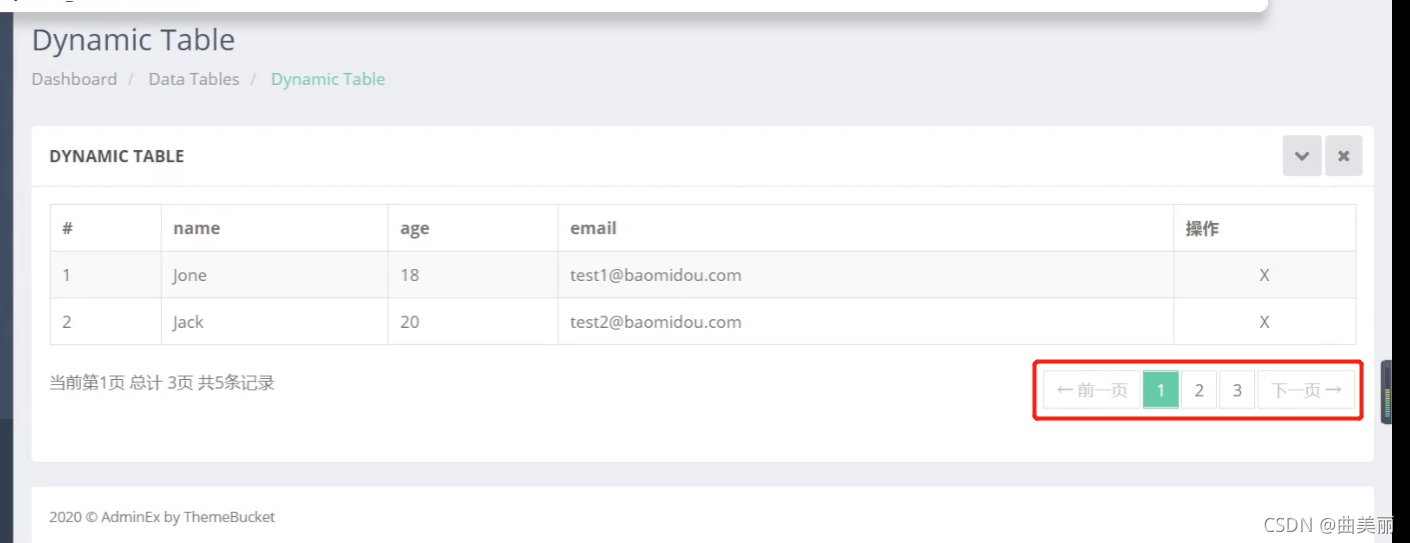
页面
想要使用分页中的总页数和总记录数等还需要分页插件
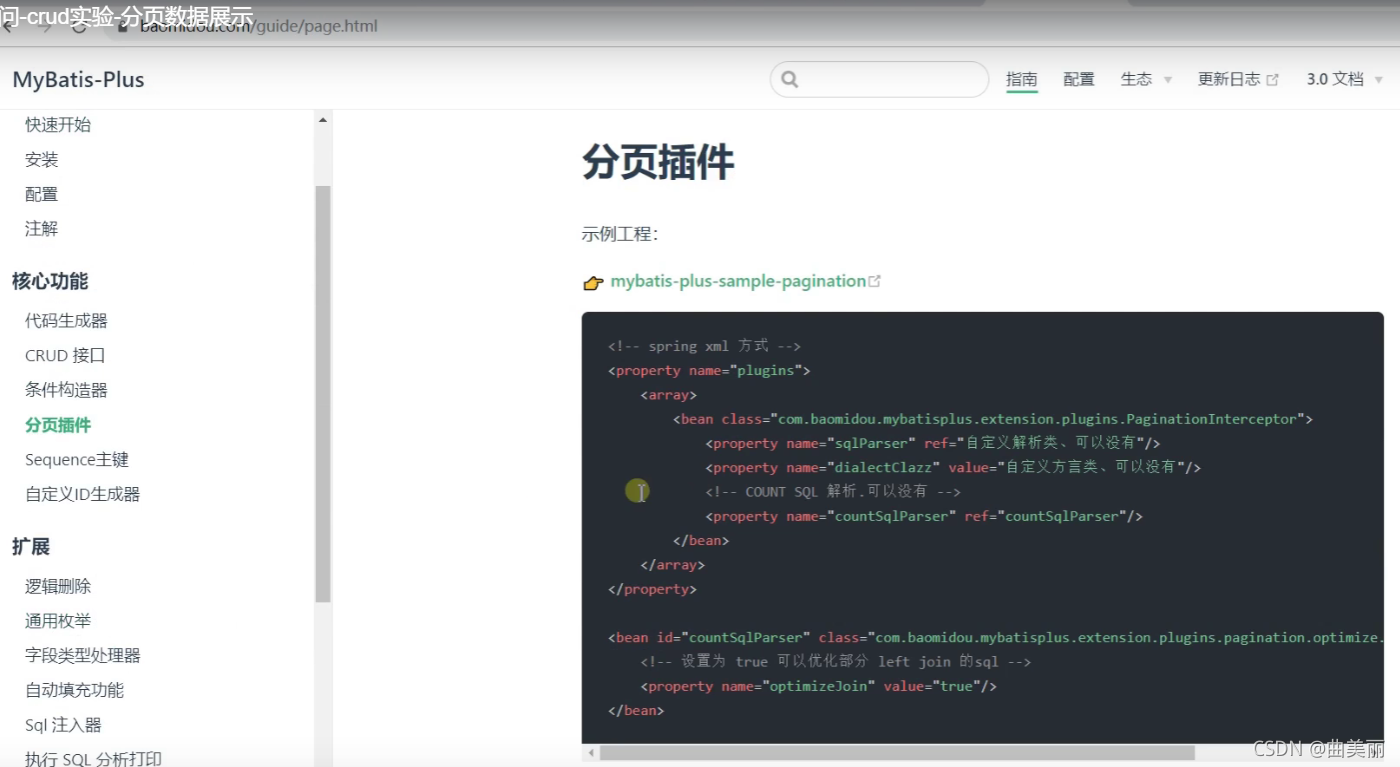
使用插件中的分页拦截器
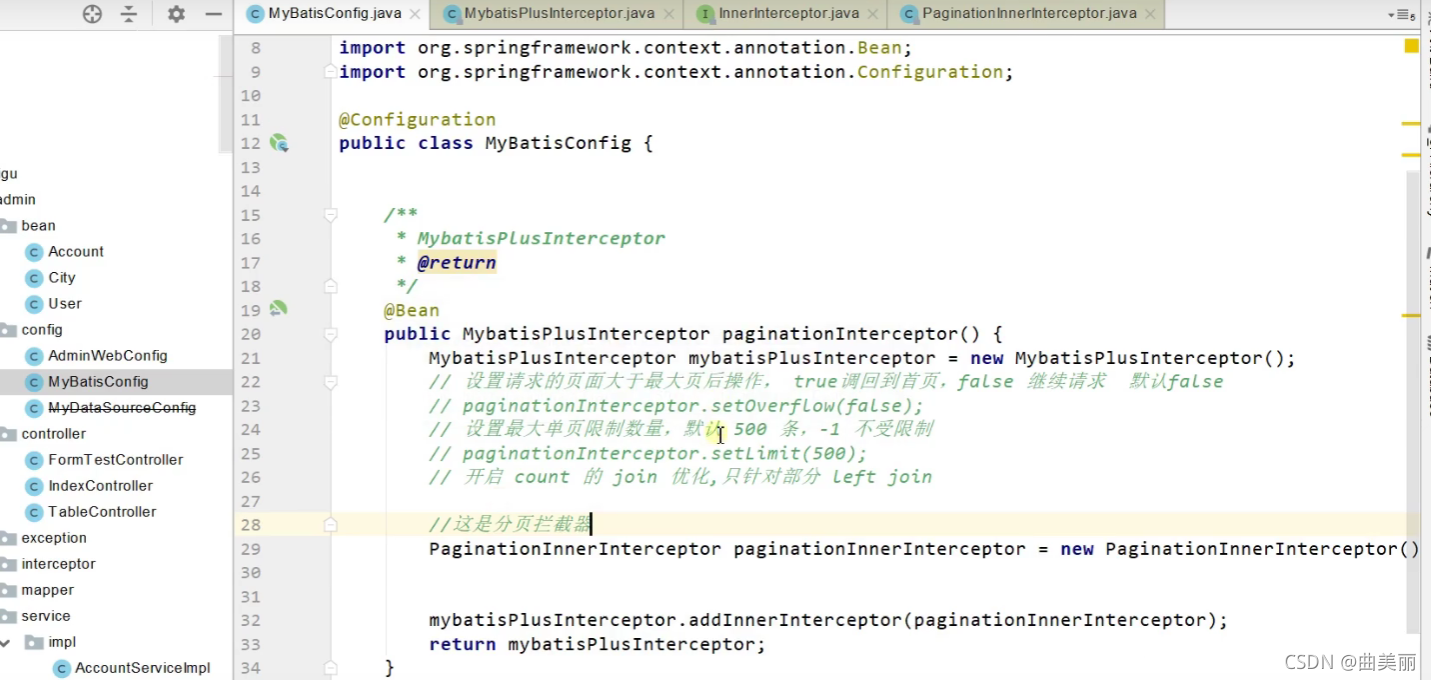
还可以通过numbers.sequence(1,users.pages)这个方法,指明开头和结束参数,就可以生成一个序列
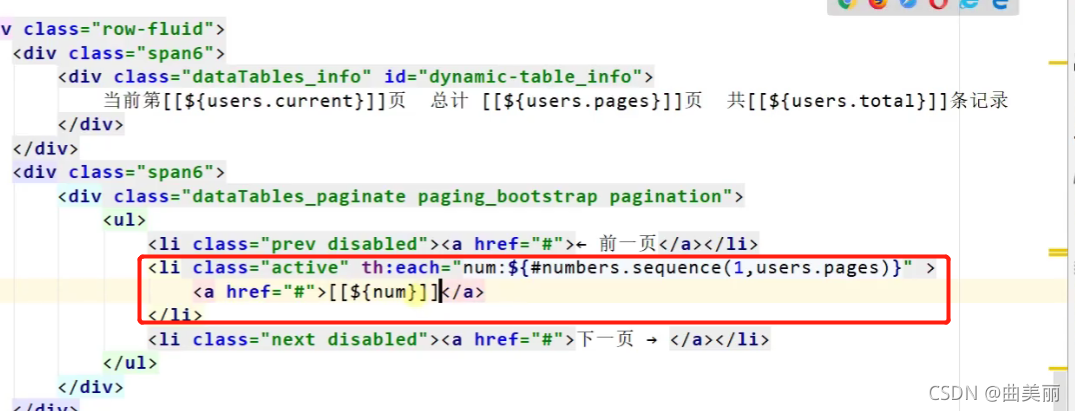
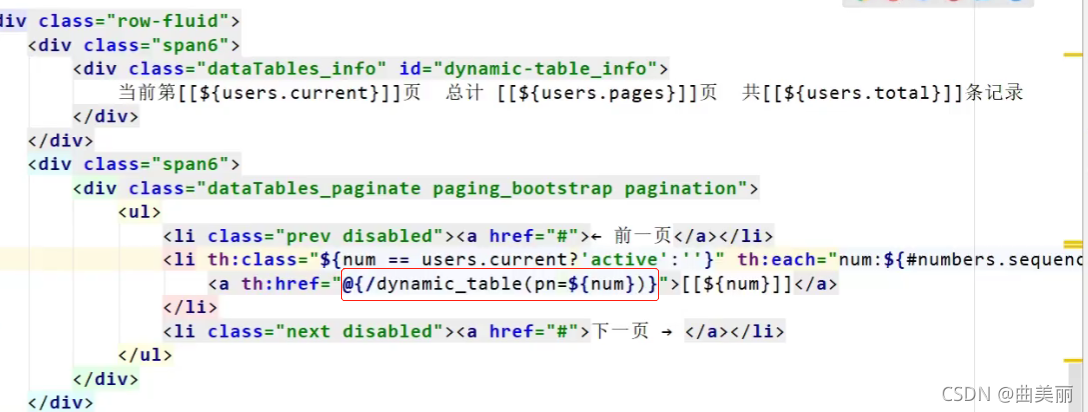
使用超链接传参,场景是在点击第一页的时候需要发送超链接再次访问分页controller,并且传参是1。返回的信息再次渲染页面。
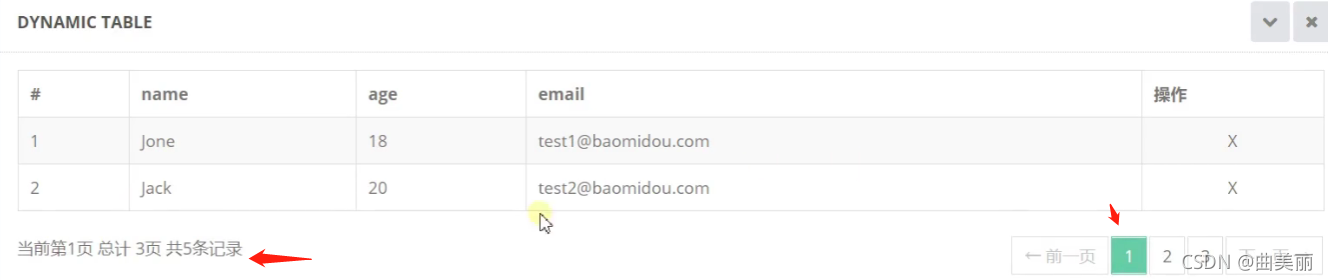
做删除功能,点击删除按钮
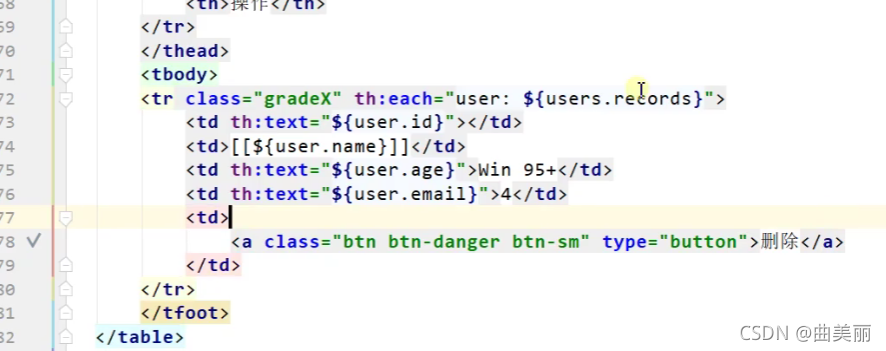
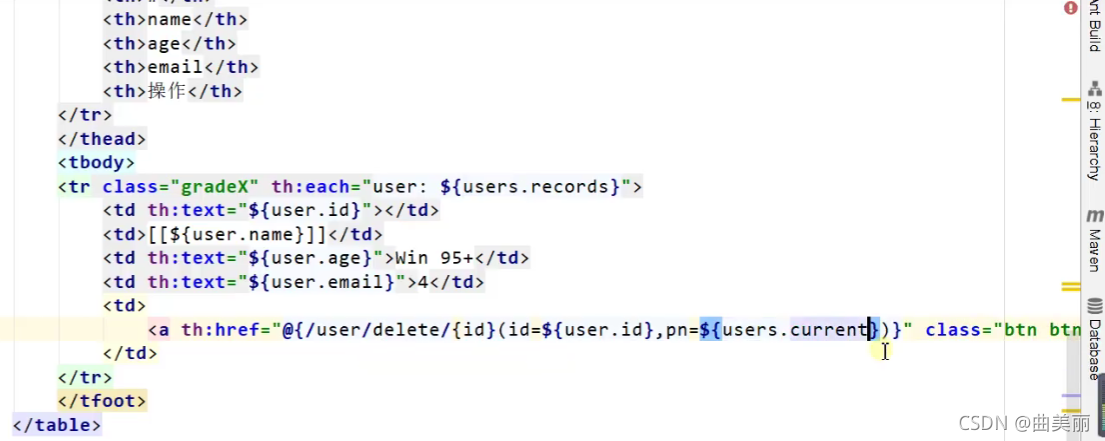
删除需要这条记录的id,删除后还应该会到删除的那页,所以超链接传参用到{id}(id=${user.id}),小括号:指明id是在哪拿的
2、NoSQL
- NoSQL使用Redis作为代表,Redis主要做缓存,通过spring boot整合Redis
Redis 是一个开源(BSD许可)的,内存中的数据结构存储(k,v)系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
1、Redis自动配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
引入Redis的场景
lettuce是操作Redis的客户端

自动配置:
通过看坐标依赖<artifactId>spring-boot-starter-data-redis</artifactId>就能看出是spring boot官方整合的场景,那么就在AutoConfiguration这个包中自动配置了

RedisAutoConfiguration 自动配置类。RedisProperties 属性类 -->
spring.redis.xxx是对redis的配置
连接工厂是准备好的。导入LettuceConnectionConfiguration负责连接、也支持JedisConnectionConfiguration
自动注入了RedisTemplate<Object, Object> : xxxTemplate去操作Redis;
这个场景比较多,所以也自动注入了StringRedisTemplate;也就是k:v都是String key:value 底层只要我们使用
使用这两个模板StringRedisTemplate、RedisTemplate就可以完全操作redis
redis环境搭建了解
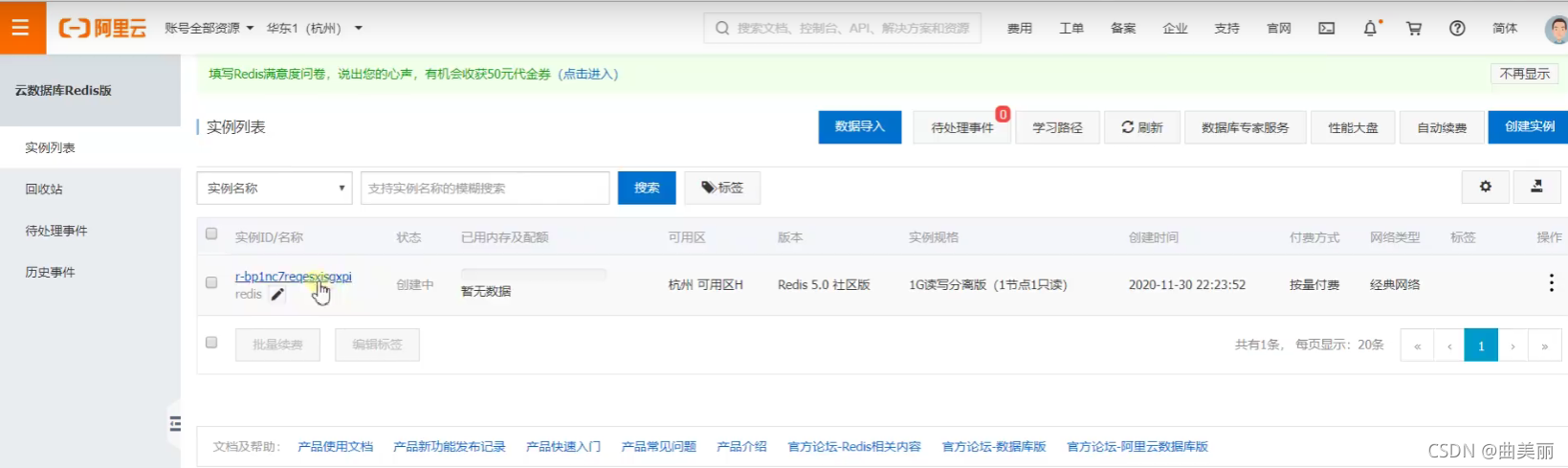
1、购买阿里云按量付费redis。选的版本经典网络
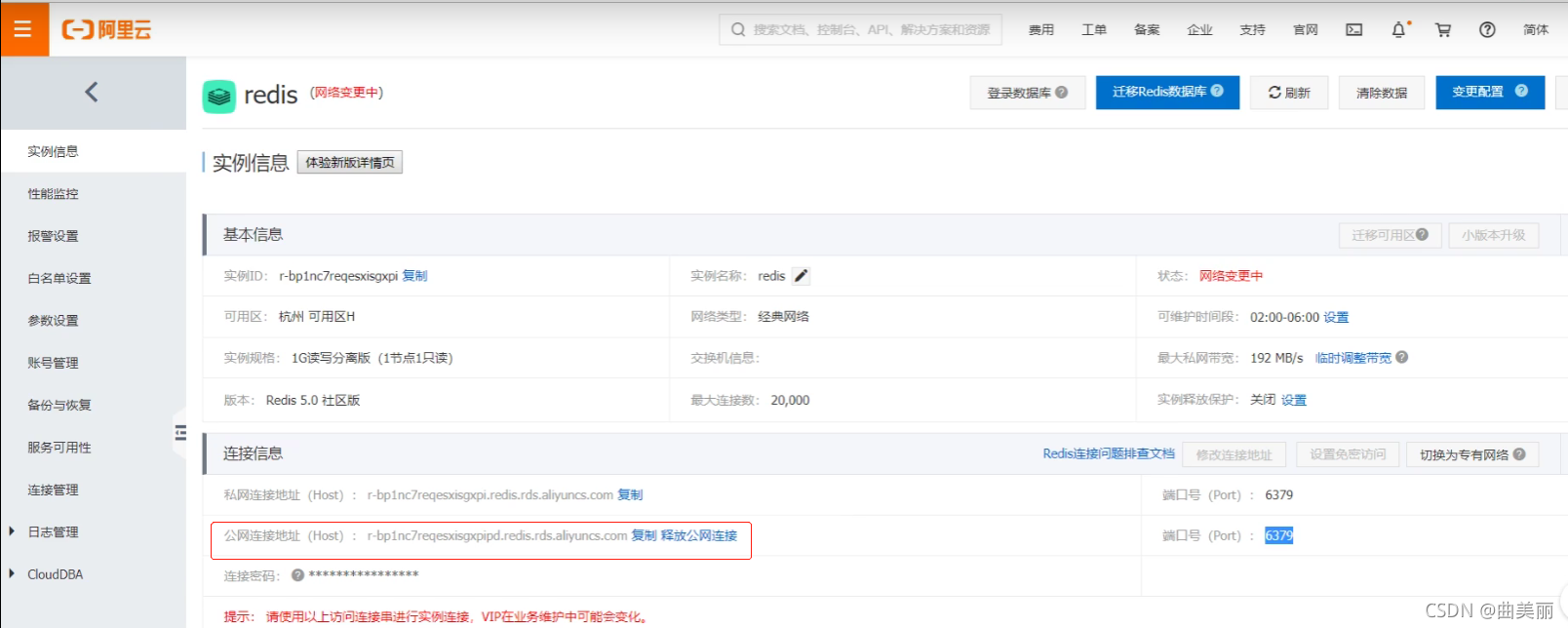
2、申请redis的公网连接地址
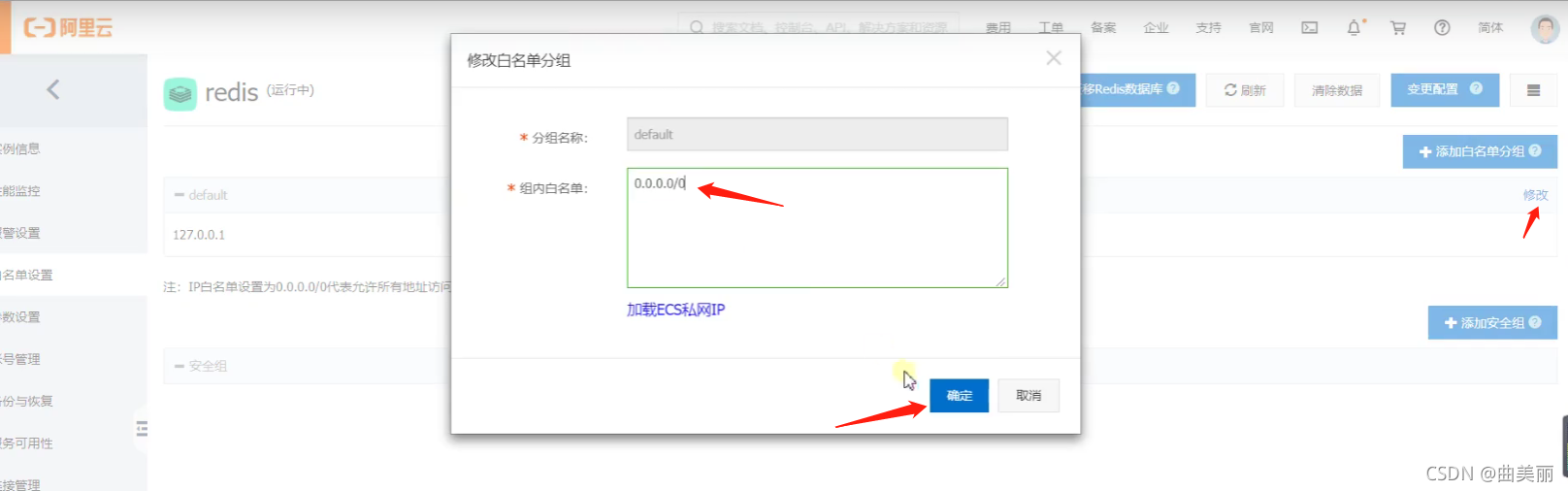
3、修改白名单 允许0.0.0.0/0 访问
通过这个可视化软件连接Redis服务器
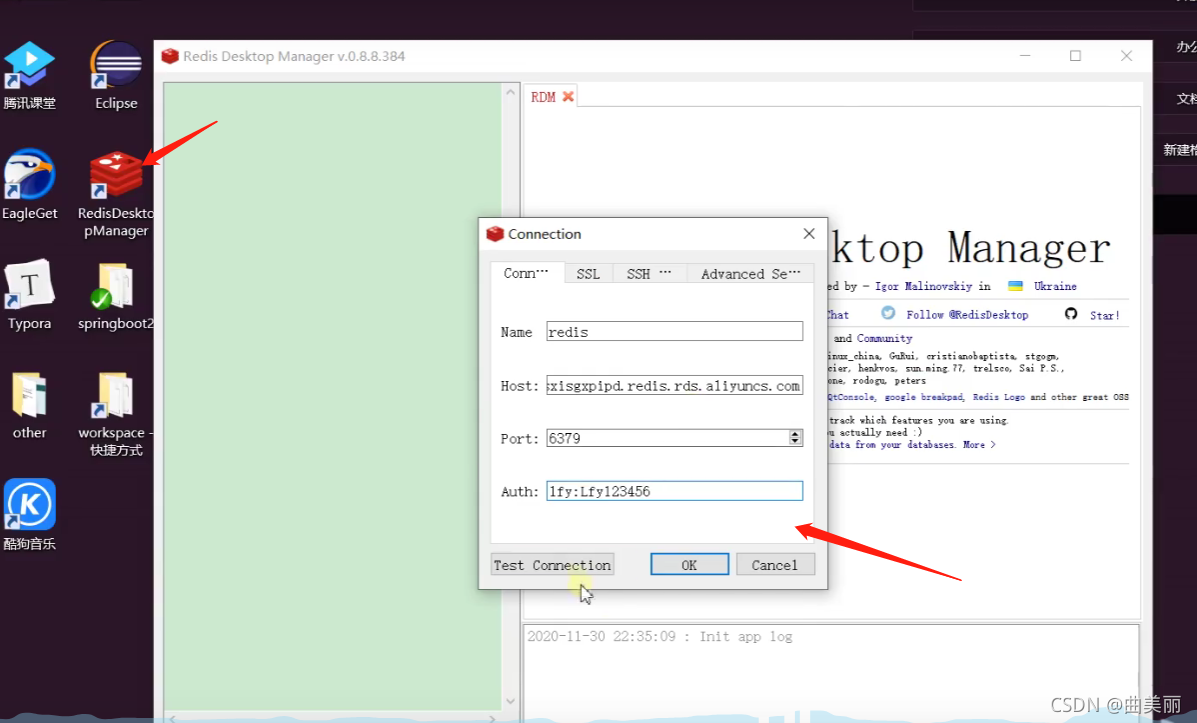
spring boot整合redis
Springboot操作数据:spring-data jpa jdbc mongodb redis
在SpringBoot2.x之后,原来使用的客户端jedis被替换为lettuce
jedis:底层采用直连,多线程操作不安全,如果想要避免不安全,使用jedis pool连接池 更像Bio模式
lettuce:底层采用netty,实例可以在多个线程中共享,不存在线程不安全的情况,可以减少线程数量,更像Nio模式
源码分析
@Bean
@ConditionalOnMissingBean(
name = {"redisTemplate"}//我们可以自己定义一个RedisTamplate来替换这个默认的
)
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
//默认的RedisTemplate没有过多的设置,redis对象都是需要序列化的!
//两个泛型都是<Object,Object>的类型,我们使用需要强制转换成<String,Object>
RedisTemplate<Object, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
//由于String类型时redis中最长使用的类型,所以单独提取出来一个bean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
导入依赖
<!-- 操作redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置连接
#配置redis
spring.redis.host=127.0.0.1
spring.redis.port=6379
测试
@Autowired
private RedisTemplate<Object, Object> redisTemplate;
@Test
void contextLoads() {
//操作不同数据类型
//opsForValue 操作字符串 类似String
//opsForList 操作List 类似List
//opsForSet
//opsForHash
//opsForZSet
//opsForGeo
//opsForHyperLogLog
//除了基本的操作,我们常用的方法都可以直接通过redisTemplate.操作,比如事务和基本的CRUD
//如获取数据库连接(了解) RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
// connection.flushDb();
// connection.flushAll();
redisTemplate.opsForValue().set("mykey","李明");//使用
System.out.println((String)redisTemplate.opsForValue().get("mykey"));
}
以上API了解,真实开发中Redis的运用
需要序列化实体类(implements Serializable)否则将一个对象存入Redis库时,会传输异常。如果不序列化就只能装成json存到库里。

以上spring boot整合redis(kuang),下面是雷神
yaml文件中:
redis:

通过自动注入的RedisTemplate客户端去操作redis
@Slf4j
@SpringBootTest
class Boot05WebAdminApplicationTests {
@Autowired
RedisTemplate redisTemplate;
@Test
void testRedis(){
ValueOperations<String,String> valueOperations = redisTemplate.opsForValue();
valueOperations.set("hello","world");
String hello = valueOperations.get("hello");
log.info(hello);
}
}
2、StringRedisTemplate与Lettuce
@Test
void testRedis(){
ValueOperations<String, String> operations = redisTemplate.opsForValue();
operations.set("hello","world");
String hello = operations.get("hello");
System.out.println(hello);
}
3、切换至jedis
如果底层想使用jedis客户端操作Redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--导入jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
配置,指明操作的客户端是jedis
spring:
redis:
host: r-bp1nc7reqesxisgxpipd.redis.rds.aliyuncs.com
port: 6379
password: lfy:Lfy123456
client-type: jedis # 指明操作的客户端
jedis:
pool:
max-active: 10
实战:
现在有一个需求:访问controller的路径时记录次数。
思路: 需要通过拦截器,请求到拦截器后,操作Redis进行统计,然后返回true放行
新建拦截器类
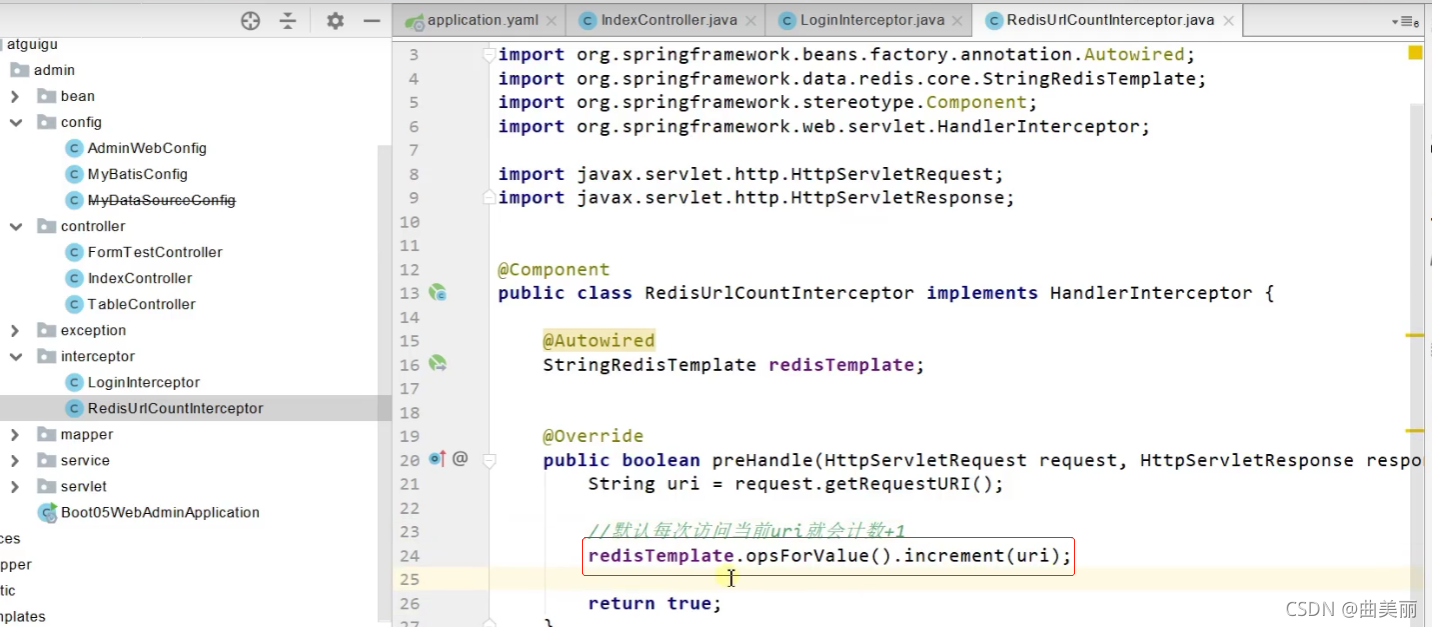
小知识点:拦截器和过滤器的区别?

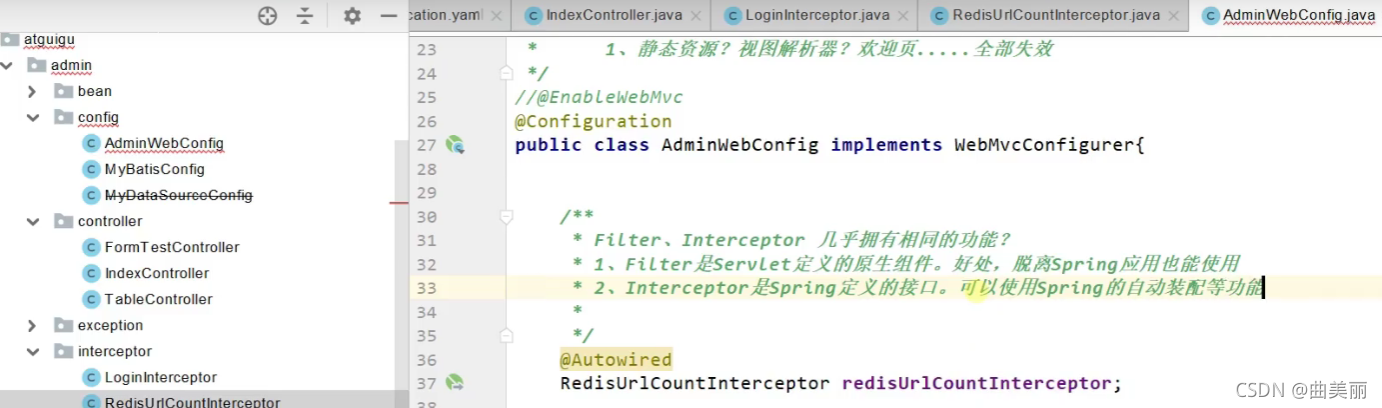
配置拦截器
在一个类中
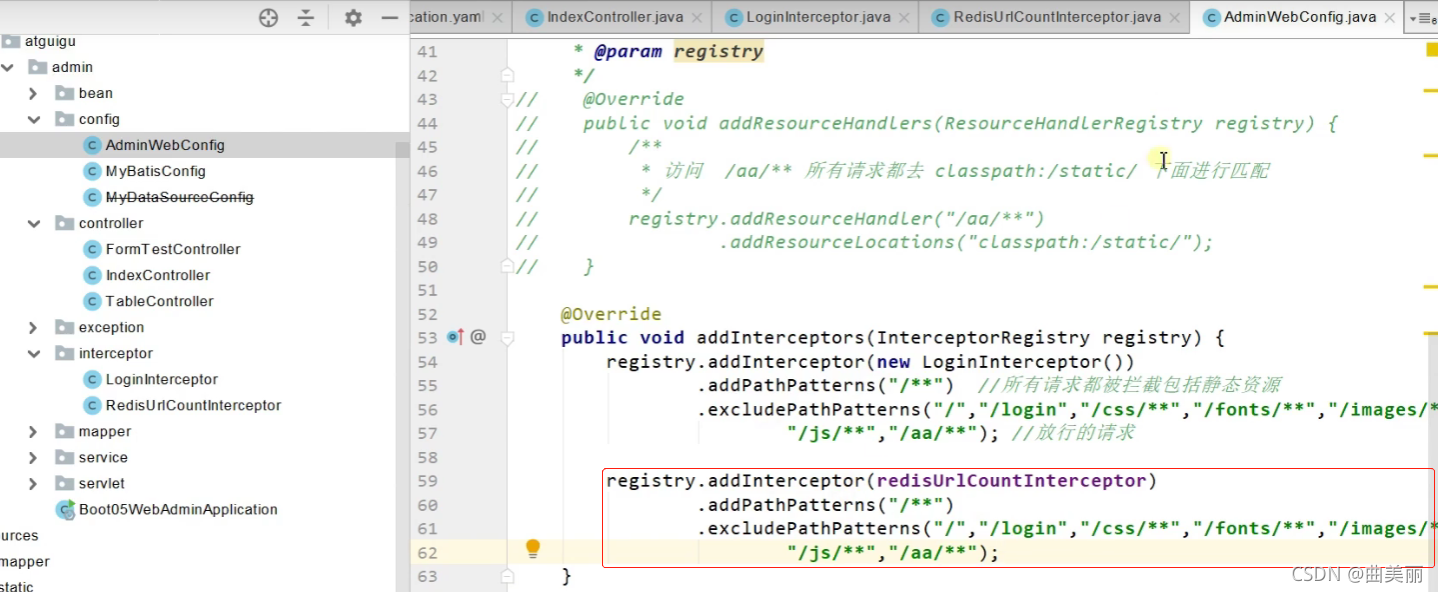
记录数8次

拿到Redis记录的次数,返回给页面
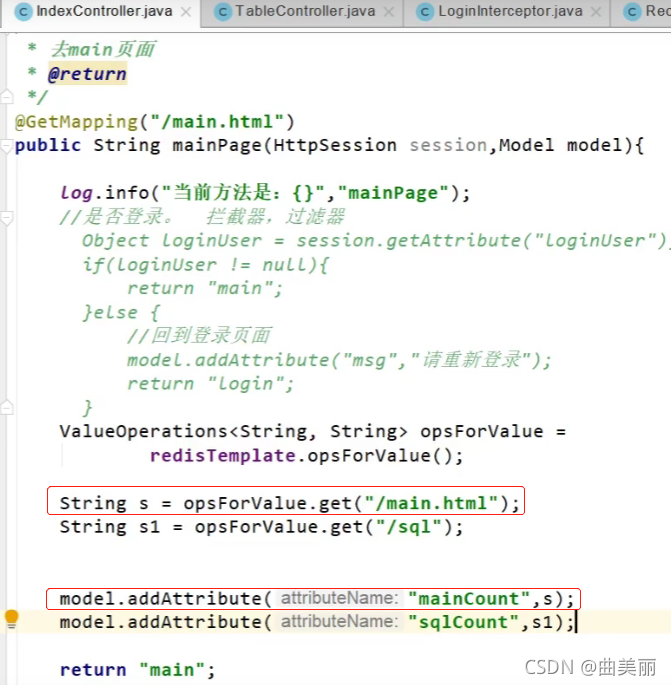
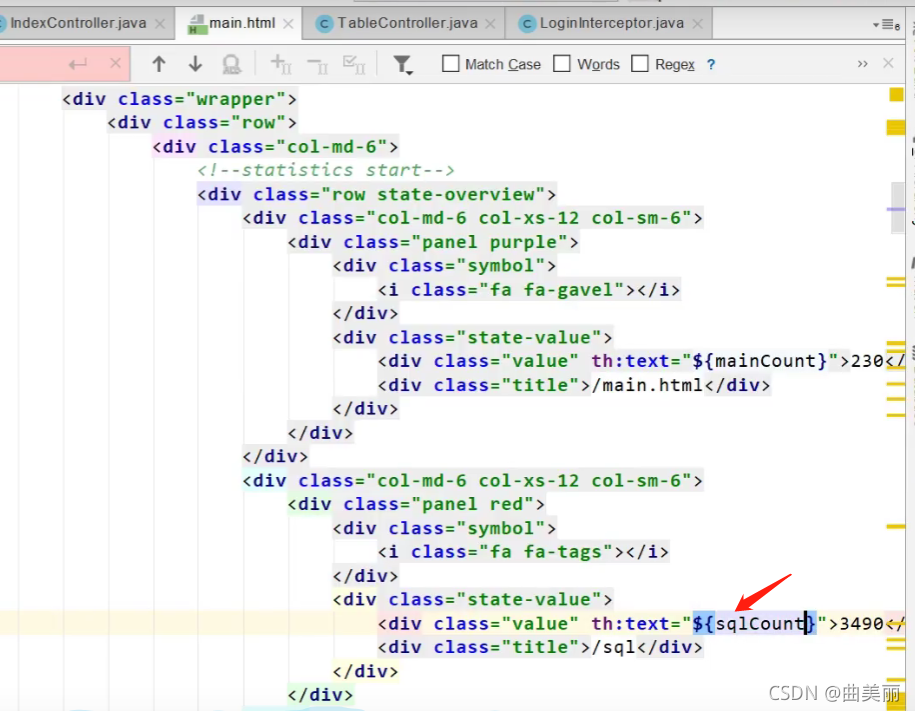
结果就是我们刷新页面就能看到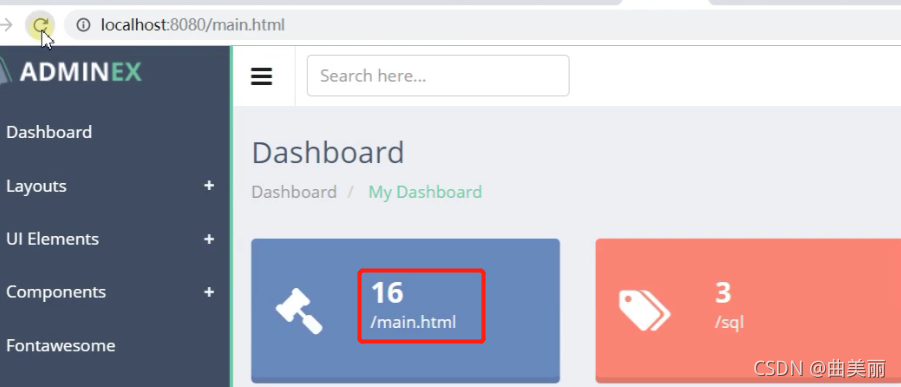
3、分布式Dubbo+Zokeeper+SpringBoot
以下是kuang讲解的
什么是分布式系统?
在《分布式系统原理与范型》一书中有如下定义:“分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统”;
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
分布式系统(distributed system)是建立在网络之上的软件系统。
首先需要明确的是,只有当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,我们才需要考虑分布式系统。因为,分布式系统要解决的问题本身就是和单机系统一样的,而由于分布式系统多节点、通过网络通信的拓扑结构,会引入很多单机系统没有的问题,为了解决这些问题又会引入更多的机制、协议,带来更多的问题。。。
下面的问题就是解决这些问题
什么是RPC
RPC【Remote Procedure Call】是指远程过程调用,是一种进程间通信方式,他是一种技术的思想,而不是规范。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同。
也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。为什么要用RPC呢?就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如不同的系统间的通讯,甚至不同的组织间的通讯,由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用。RPC就是要像调用本地的函数一样去调远程函数;
Dubbo基本概念
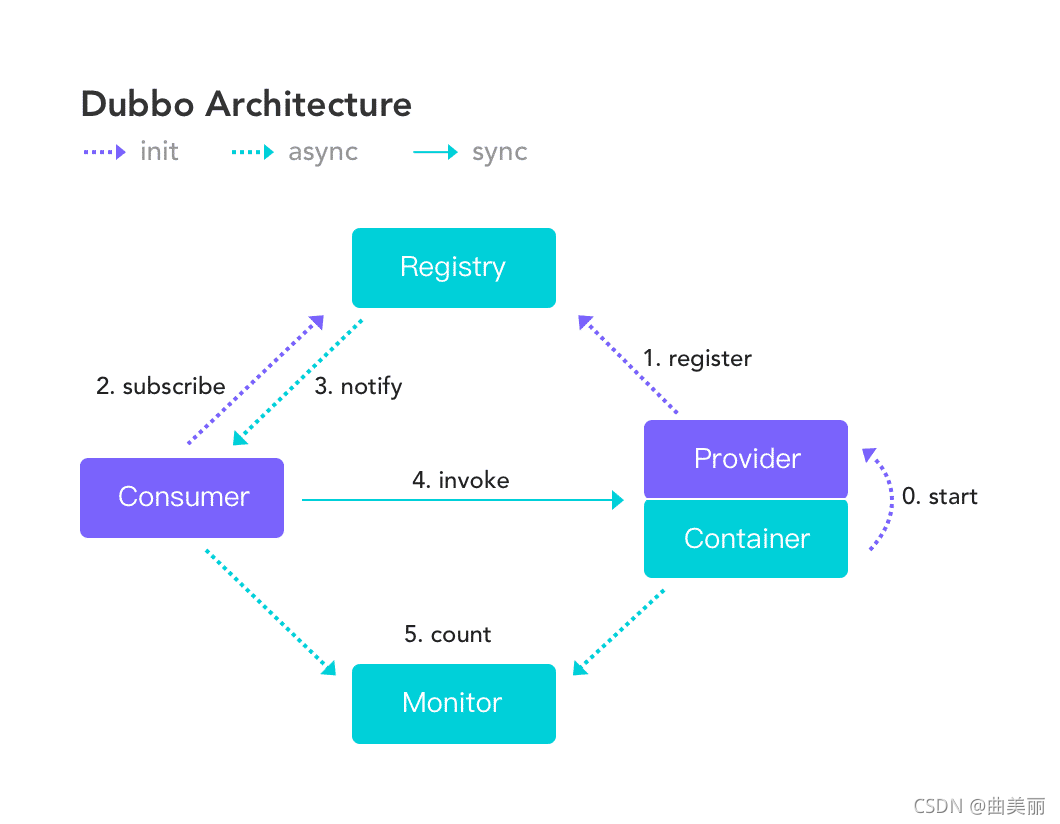
服务提供者(Provider):暴露服务的服务提供方,服务提供者在启动时,向注册中心注册自己提供的服务。
服务消费者(Consumer):调用远程服务的服务消费方,服务消费者在启动时,向注册中心订阅自己所需的服务,服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
注册中心(Registry):注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者
监控中心(Monitor):服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心
调用关系说明
l 服务容器负责启动,加载,运行服务提供者。
l 服务提供者在启动时,向注册中心注册自己提供的服务。
l 服务消费者在启动时,向注册中心订阅自己所需的服务。
l 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
l 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
l 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
安装Dubbo-admin
下载dubbo-admin
地址 :https://github.com/apache/dubbo-admin/tree/master
进行打包(可以是Idea打包,也可以是命令行打包)
使用命令java -jar dubbo-admin-0.0.1-SNAPSHOT.jar
【注意:zookeeper的服务一定要打开!】
访问localhost:7001即可访问Dubbo-admin页面
实现跨项目访问类
1、提供者配置文件
#服务应用名字
dubbo.application.name=provider-server
#注册中心地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
#哪些服务要被注册(扫描包)
dubbo.scan.base-packages=com.servic
2、编写提供者的接口和实现类
3、消费者配置文件
#消费者去哪里拿服务需要暴露自己的名字
dubbo.application.name=customer-server
#注册中心的地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
4、在消费者和提供者相同的包下建立提供者的接口
5、消费者服务类
@Service //注入到容器中
public class UserService {
@Reference //远程引用指定的服务,他会按照全类名进行匹配,看谁给注册中心注册了这个全类名
TicketService ticketService;
public void bugTicket(){
String ticket = ticketService.getTicket();
System.out.println("在注册中心买到"+ticket);
}
6、编写测试类
@Autowired
UserService userService;
@Test
public void contextLoads() {
userService.bugTicket();
}
启动测试
-
开启zookeeper
-
打开dubbo-admin实现监控【可以不用做】
-
开启服务者
-
消费者消费测试
回顾,架构!
架构: 目的–>解耦
开发框架
Spring
IOC AOP
IOC : 控制反转
泡温泉,泡茶泡友
附近的人,打招呼。加微信,聊天,天天聊>约泡
浴场(容器):温泉,茶庄泡友
直接进温泉,就有人和你一起了!
原来我们都是自己一步步操作,现在交给容器了!我们需要什么就去拿就可以了
AOP:切面(本质,动态代理)
为了解什么?不影响业本来的情况下,实现动态增加功能,大量应用在日志,事务等等
Spring是一个轻量级的Java开源框架,容器
目的:解决企业开发的复杂性问题
Spring是春天,但配置文件繁琐
SpringBoot
SpringBoot ,新代javaEE的开发标准,开箱即用!>拿过来就可以用,它自
动帮我们配置了非常多的东西,我们拿来即用,特性:约定大于配置!
随着公司体系越来越大,用户越来越多
微服务架构—>新架构
模块化,功能化!
用户,支付,签到,娱乐…;
人多余多一台服务器解决不了就再增加一台服务器! --横向扩展
假设A服务器占用98%资源B服务器只占用了10%.–负载均衡;
将原来的整体项,分成模块化,用户就是一个单独的项目,签到也是一个单独的项目,项目和项目之前需要通信,如何通信
用户非常多而到十分少给用户多一点服务器,给签到少一点服务器
微服务架构问题?
分布式架构会遇到的四个核心题?
这么多服务,客户端该如何去访?
这么多服务,服务之间如何进行通信?
这么多服务,如何治理呢?
这么多服务,宕机怎么处理?
解决方案:SpringCloud
Springcloud是一套生态,就是来解决以上分布式架构的4个问题,目前有以下三套方案
想使用Spring Clould ,必须要掌握 springBoot , 因为Springcloud是基于springBoot ;
spring Cloud NetFlix ,出来了一套解决方案!一站式解决方案。可以直接使用
Api网关 , zuul组件
Feign --> Httpclient —> http通信方式,同步并阻塞
服务注册与发现 , Eureka
熔断机制 , Hystrix
2018年年底,NetFlix 宣布无限期停止维护。生态不再维护,就会脱节。
Apache Dubbo zookeeper ,
API:没有!要么找第三方组件,要么自己实现
Dubbo 是一个高性能的基于ava实现的RPC通信框架!2.6.x
服务注册与发现 , zookeeper :动物管理者 ( Hadoop , Hive )
没有:借助了Hystrix
不完善,Dubbo
SpringCloud Alibaba 一站式解决方案
目前又提出了新的思路
服务网格:也许是下一代维服务标准,Service mesh
代表解决方案:istio(未来可能需要掌握)
总而言之,要解决的问题就是4个
API网关 , 服务路由
HTTP,RPC框架,异步调用
服务注册与发现,高可用
熔断机制,服务降级
为什么要解决这个问题?因为网络是不可靠的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









