







头歌上的关卡
详细的学习很建议看头歌上的讲解,挺清晰
就是一些命令
mysql -h127.0.0.1 -uroot -p123123; #连接数据库
#在本实验中,需要指定127.0.0.1作为服务器的ip地址;123123为密码,与-p间不要有空格
连接数据库,创建数据库,指定数据库(use)
创建表(create table)只是创建歌表头(表的结构,没一行行的数据)
主外码约束,check约束(限定取值范围)、default(初始默认值)、NOT NULL不许为空值,unique(唯一性如“院名不能重名”)。
alter修改表头的那些东西、约束👆等
创建表及表的主码约束
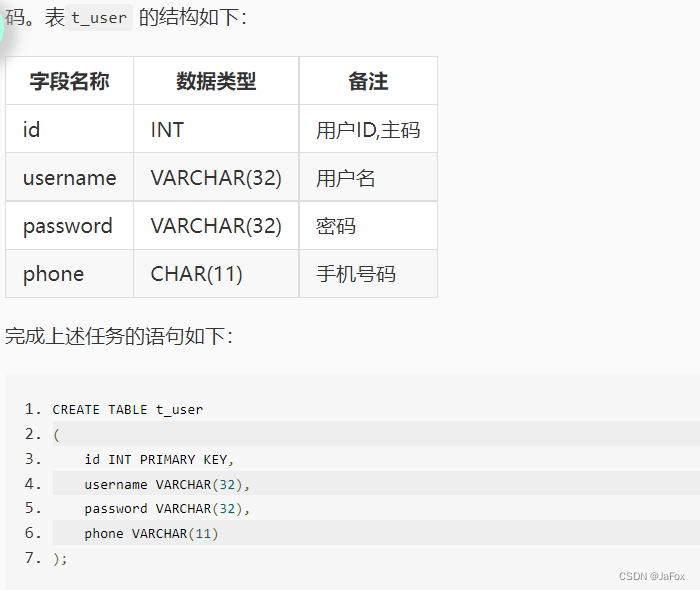
这段语句之前:创建数据库,并use TestDb。(TestDb为创建的数据库的名字)
- 表约束

在语法描述中,方括号里的内容为可选项,可以有,也可以没有;用“|”隔开的内容为多选一,“a|b”表示要么a,要么b。

创建外键约束
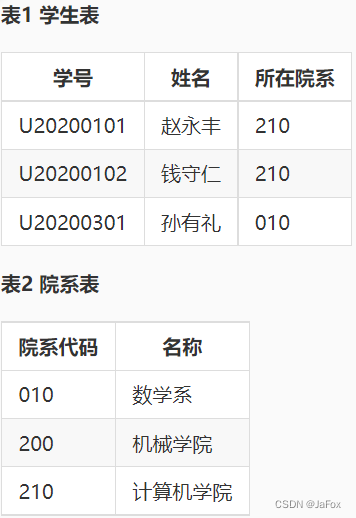
上表中:学生表”和“院系表”中,“学生表”中的字段“所在院系”与“院系表”中的“院系代码”具有对应关系,其中“院系代码”是“院系表”的主码,“学生表”中的“所在院系”为外码。–>可以粗浅地理解为:更精炼短小的表的主码不称为外码,外码是那些发散出去的表的。
创建外码的语句为:
CONSTRAINT 给个外码名字 指定外码是哪个属性 指向哪个表中的哪个主码
CREATE TABLE 院系表
(
院系代码 char(3) PRIMARY KEY,
名称 VARCHAR(22)
);
CREATE TABLE 学生表
(
学号 char(9) PRIMARY KEY,
姓名 VARCHAR(22),
所在院系 char(3),
CONSTRAINT FK_student_dept FOREIGN KEY(所在院系) REFERENCES 院系表(院系代码)
);
创建check约束

也可以有如CHECK(price>0)的部分。
创建default、not null、auto_increment约束
create table 'order'(
orderNo int auto_increment primary key, #自动编号约束
name varchar(32) NOT NULL, #不允许为空值
sex char(2) default '男性', #初始值默认值,即便多个汉字也用单引号
orderDate date default (curdate()),
);
注意:
- AUTO_INCREMENT约束仅用于整数列;
- DEFAULT约束指定默认值为表达式时,表达式要写在一对括弧里;
- 这里,curdate()是MySQL的系统函数,其功能是取当前日期;
- 语句中,表名称order前后的单引号是必须的,因为order是MySQL的关键字,当表名或列名与关键字冲突时,名称前后必须加单引号。
UNIQUE约束
create table department(
dno char(10) primary key,
dname varchar(32) NOT NULL UNIQUE #这的unique具体的意思是不允许两个院系重名
);
注意:
- NOT NULL只能作列约束,且不用命名。
- 本例中的UNIQUE约束还可以用表约束来实现。
- UNIQUE约束作列约束时不能自主命名,作表约束时可以自主命名。
修改表(alter)
alter table 表名 rename [TO|AS] 新表名; #修改表名
alter table orderDetail drop orderDate;
alter table orderDetail add unitPrice numeric(10,2); #删除和增加字段
#更详细的增删看头歌(有特殊情况的处理)
alter table addressBook modify QQ char(12); #将QQ的类型改为char(12)
alter table addressBook rename column weixin to wechat; #把列名weixin改为wechat
添加、删除与修改约束
#(1) 为表Staff添加主码
alter table Staff add PRIMARY KEY(staffNo);
#组合属性则用(列1,列2)
#(2) Dept.mgrStaffNo是外码,对应的主码是Staff.staffNo,请添加这个外码,名字为FK_Dept_mgrStaffNo:
alter table Dept add constraint FK_Dept_mgrStaffNo foreign key(mgrStaffNo) references Staff(StaffNo);
#(3) Staff.dept是外码,对应的主码是Dept.deptNo. 请添加这个外码,名字为FK_Staff_dept:
alter table Staff add constraint FK_Staff_dept foreign key(dept) references Dept(deptNo);
#(4) 为表Staff添加check约束,规则为:gender的值只能为F或M;约束名为CK_Staff_gender:
alter table Staff add constraint CK_Staff_gender check(gender in ('F','M'));
#也可以用check(gender='F'or gender='M')
#(5) 为表Dept添加unique约束:deptName不允许重复。约束名为UN_Dept_deptName:
alter table Dept add constraint UN_Dept_deptName unique(deptName);
暂
- 值只能为……:check( in ( , ))
- where (列) in (select子句)
对行进行挑选,针对的是某个列。select子句中select后面借的列名和where后面的一样。[在另一个表中找到定语条件]
- where in、where < any/all (select子句)、where exists/not exists (select子句)-->看select子句非不非空(select *就行)。
-
后面几关都要用到的表:
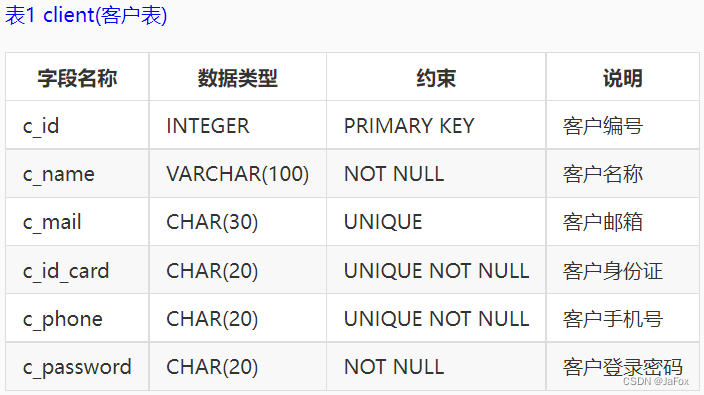
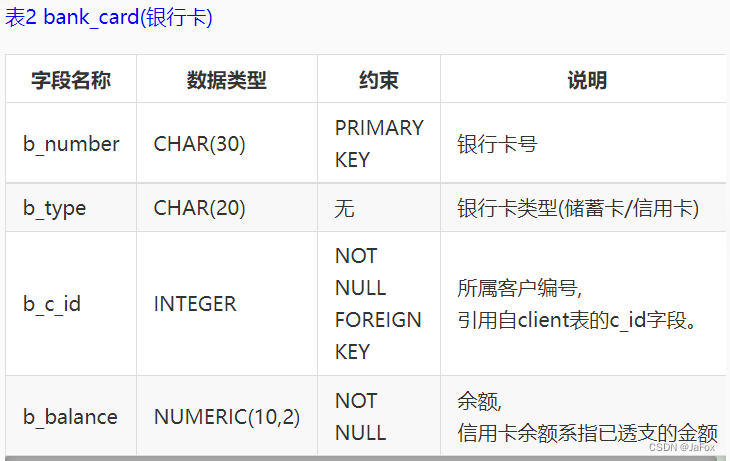
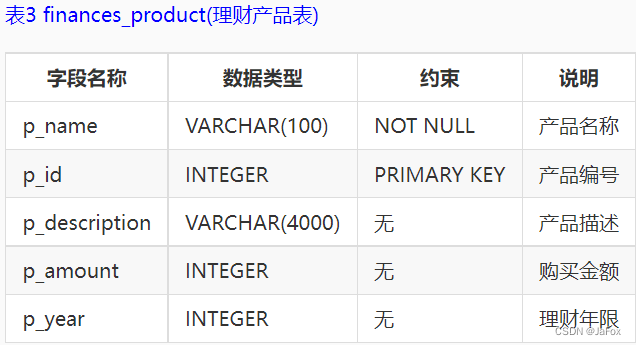
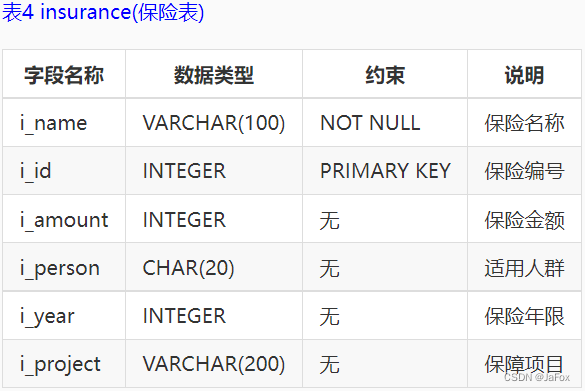
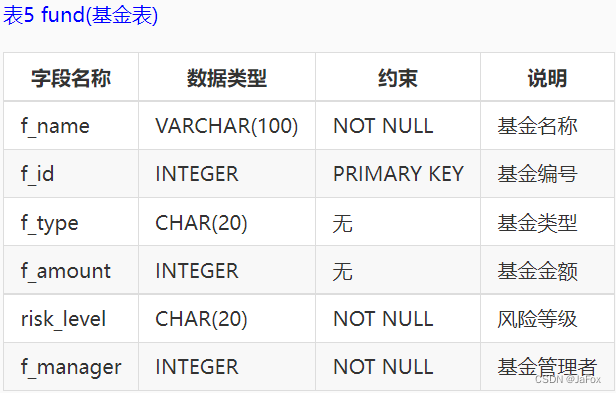
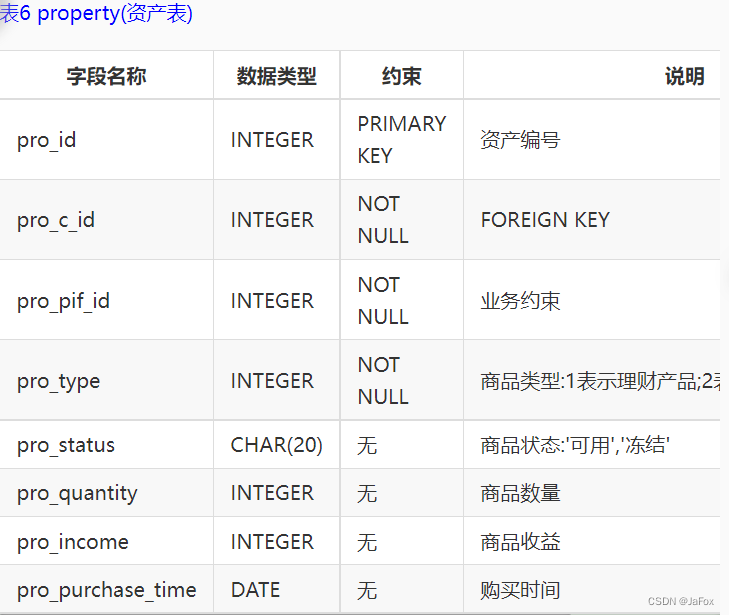
补充:2表示保险;3表示基金
查询(select)
查询某个信息为null的
#查询客户表(client)中邮箱信息为null的客户的编号、名称、身份证号、手机号
select c_id,c_name,c_id_card,c_phone from client where c_mail is null;
跨表查询的
#查询既买了保险又买了基金的客户的名称、邮箱和电话。结果依c_id排序
select c_name,c_mail,c_phone from client where exists
(select * from property where pro_c_id=c_id and pro_type=2) and exists
(select * from property where pro_c_id=c_id and pro_type=3)
order by c_id;
2."where 属性 in 下一张表"方式来跨表
要注意where in间的属性用哪个,关注主码
#查询购买了货币型(f_type='货币型')基金的用户的名称、电话号、邮箱。
select c_name,c_phone,c_mail
from client
where c_id in(
select pro_c_id
from property
where pro_type=3 and pro_pif_id in(
select f_id
from fund
where f_type='货币型'
)
)
order by c_id;
查询结果按两种不同的顺序显示
#查询理财产品中每份金额在30000~50000之间的理财产品的编号,每份金额,理财年限,并按照金额升序排序,金额相同的按照理财年限降序排序。
select p_id,p_amount,p_year from finances_product
where p_amount>=30000 and p_amount<=50000
order by p_amount,p_year desc;
求众数
#查询资产表中所有资产记录里商品收益的众数和它出现的次数
select pro_income,count(pro_income) as presence#查询结果展示处的两列名字为pro_income,count(pro_income),故需要as取个别名(不要别名的话,统计结果是正确的
from property
group by pro_income
having count(*) >= all(select count(*) from property group by pro_income)#这行可以看称固定句式
- count(name)生成了一个新的字段,as给新生成的count字段命名,group by表示分别计数。SQL中group by语法只有与count语法联合使用时才有意义,一般联合聚合函数使用。
- IN:在范围内的值,只要有就true;
ALL:与子查询返回的所有值比较为true,则返回true;
ANY:与子查询返回的任何值比较为true,只有有一个成立,则返回true;
查“持两张及以上 信用卡 的用户的…”、属性组
#查询持有两张(含)以上信用卡的用户的名称、身份证号、手机号。
select c_name,c_id_card,c_phone
from client
where (c_id,"信用卡") in (
select b_c_id,b_type
from bank_card
group by b_c_id,b_type#还不是很理解这个group by的作用
having count(*) > 1
);
-- where 和 having不能一起用
having、group by详解:
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。HAVING 子句可以让我们筛选分组后的各组数据。
小例1:
GROUP BY region
先以region把返回记录分成多个组,这就是GROUP BY的字面含义。分完组后,然后用聚合函数对每组中的不同字段(一或多条记录)作运算。
小例2:
------
select phone from aa group by phone having count(*) > 1
以phone分组,分组后 每组里面phone出现次数 大于1 的 phone 会显示出来。
phone
1
1
2
3
3
4
则
结果为
1
3
---------------
没有分组的情况下having和Where 类似。
有分组的时候 Where对分组前内容过滤,having是分组后的内容进行筛选。
having 里面可以写聚合函数
前几名、inner join
查询当前总的可用资产收益(被冻结的资产除外)前三名的客户的名称、身份证号及其总收益,按收益降序输出,总收益命名为total_income。不考虑并列排名情形。
-- 方式一 inner join
select c_name,c_id_card,sum(pro_income) as total_income
from client
inner join property
on pro_c_id=c_id and pro_status="可用"
group by c_id
order by total_income desc
limit 3;
-- 方式二 很一般的方式
select c_name,
c_id_card,
sum(pro_income) as total_income
from client,property
where pro_c_id = c_id and pro_status = "可用"
group by c_id-- WK
order by total_income desc
limit 3;
👆where放在group by 之前,having放在group by 之后。
第N高问题
-- 14) 查询每份保险金额第4高保险产品的编号和保险金额。
-- 在数字序列8000,8000,7000,7000,6000中,
-- 两个8000均为第1高,两个7000均为第2高,6000为第3高。
-- 请用一条SQL语句实现该查询:
SELECT i_id, i_amount
FROM insurance
WHERE i_amount = (
SELECT DISTINCT i_amount #去重
FROM insurance
ORDER BY i_amount DESC
LIMIT 3, 1
);
👆针对哪个属性的定语,就where 这个属性 in/=/like/··· 子句等
补充limit:
limit N : 返回 N 条记录;
limit N,M : 从第 N 条记录开始, 返回 M 条记录,相当于 limit M offset N(返回的不含第N条)
(offset M : 跳过 M 条记录, 默认 M=0, 单独使用似乎不起作用)
rank() over()/dense_rank() over
👆分别实现两种排序:
- 同数同名次,总排名不连续。例如300、200、200、150、150、100的排名结果为1, 2, 2, 4, 4, 6;
- 同数同名次,总排名连续。例如300、200、200、150、150、100的排名结果为1, 2, 2, 3, 3, 4。
(都是值同排名同)
-- 15) 查询资产表中客户编号,客户基金投资总收益,基金投资总收益的排名(从高到低排名)。
-- 总收益相同时名次亦相同(即并列名次)。总收益命名为total_revenue, 名次命名为rank。
-- (1) 基金总收益排名(名次不连续)
select pro_c_id,
sum(pro_income) as total_revenue,-- 。。别漏逗号
rank() over(order by sum(pro_income) desc) as "rank"
from property
where pro_type = 3
group by pro_c_id
order by total_revenue desc, pro_c_id;
-- order by 最好把主码写上,可以作为第二选择
-- (2) 基金总收益排名(名次连续)
select pro_c_id,
sum(pro_income) as total_revenue,
dense_rank() over(order by sum(pro_income) desc) as "rank"
from property
where pro_type = 3
group by pro_c_id
order by total_revenue desc, pro_c_id;
补充:(1) distinct只能在select中使用;(2) rank() over子句中的排序不可以用自己取的别名
至少有一张
查询至少有一张信用卡余额超过5000元的客户编号,以及该客户持有的信用卡总余额,总余额命名为credit_card_amount。
select b_c_id,
sum(b_balance) as credit_card_amount
from bank_card
where b_type = "信用卡"
group by b_c_id
having max(b_balance) >= 5000-- 至少有一张,即max
order by b_c_id;
-- The SQL standard requires that HAVING must reference only columns in the GROUP BY clause or columns used in aggregate functions.【和mysql不同】
至少有,即having max >
其他
#order by
#查询办理了储蓄卡的客户名称、手机号、银行卡号。 查询结果结果依客户编号排序。
select c_name,c_phone,b_number
from client,bank_card
where b_type='储蓄卡' and b_c_id=c_id
order by c_id;
#like、not exists;select套select
#查询身份证隶属武汉市没有买过任何理财产品的客户的名称、电话号、邮箱。
select c_name,c_phone,c_mail
from client
where c_id_card like '4201%' and not exists(#没有买过理财产品==>产品表中的产品所对应的客户号
select pro_type
from property
where pro_type='1' and pro_c_id=c_id
)
order by c_id;#根据测试集结果,需要
#不查找理财产品表,因为此表中没有客户id这个属性,代码就联系不起来
group by补充
说的多怕你混,你就记住当SELECT 后 既有 表结构本身的字段,又有需要使用聚合函数(COUNT(),SUM(),MAX(),MIN(),AVG()等)的字段,就要用到group by分组,查询的限定条件里有需要用聚合函数计算的字段时也需要用分组,比如:
select avg(grade) from cs
查询选课表(cs)中学生的总成绩(grade);这里就不用分组;
又如:
select sno,sum(grade) from cs group by sno
查询选课表里每个学生的总成绩,这里就要用分组,分组的依照字段必须是select 后没有被计算过的原始字段;
以上是分组用法。
本来我也弄不清,书上说的太模糊,后来自己代码写多了就懂了。
分组的概念:就是让经过计算的查询结果根据某一个或者多个字段分成一组一组(一行一行)的排列显示。
另外顺便介绍下,WHERE和HAVING的区别,WHERE作用于全表,而HAVING只作用于分组的组内。
– 18) 查询至少有一张信用卡余额超过5000元的客户编号,以及该客户持有的信用卡总余额,总余额命名为credit_card_amount。
– 请用一条SQL语句实现该查询:
SELECT b_c_id, SUM(b_balance) as credit_card_amount
FROM bank_card
WHERE b_type = "信用卡"
GROUP BY b_c_id #给having做铺垫
HAVING MAX(b_balance) >= 5000
ORDER BY b_c_id;
– 11) 给出黄姓用户的编号、名称、办理的银行卡的数量(没有办卡的卡数量计为0),持卡数量命名为number_of_cards,
– 按办理银行卡数量降序输出,持卡数量相同的,依客户编号排序。
– 请用一条SQL语句实现该查询:
select c_id,c_name,count(b_c_id) as number_of_cards
from client
left join bank_card
on c_id=b_c_id
where c_name like "黄%"
group by c_id
order by number_of_cards desc, c_id;
>==👆11)好像只能用join【码住,回去再研究一下】==
>
### ==得再去练的关卡==
- SELECT部分_第12关:客户理财、保险与基金投资总额。(挺复杂)
- ……_第13关,也是
- 第15关:基金收益两种方式排名
- 第15关:基金收益两种方式排名
- 第16关:持有完全相同基金组合的客户
- 第17关:购买基金的高峰期
- 第19关:以日历表格式显示每日基金购买总金额
网课
目前这里只记sql部分,即CH3,跳着看(已写了实验,PPT也挺拉
①语法头歌即可②用法,难理解的顺的还是网课会方便
数据查询(重点)

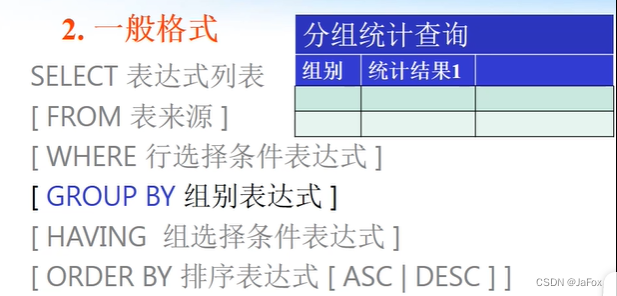
select决定 要查询的结果列表。
where指定 查询条件(满足条件的行)
group by凡组别表达式结果相同的行被看作一组,每组在查询结果中只占一行(如:按系别分组,统计的是每个系别的人数;按课程分组,统计的是每门课程的人数;按学号分组,统计每位同学的各科平均成绩;按课号分组,统计每门课程的最好成绩最坏成绩)
having 用于分组统计后组筛选条件
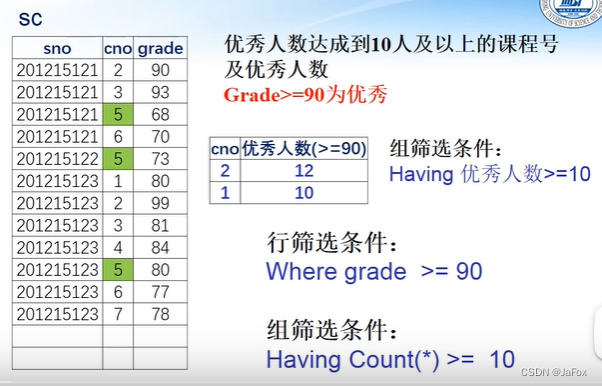
where和having的区别:
这里,where只有满足grade>90的行才会被统计计数。
order by中:asc为升序(是默认值),desc为降序。
*号表示全部的列。

学号的前四位是年级。
↑本例给出了三种重命名方法。

思考==>一定只有两行,男和女


有的学生要补考的课程可能不止一门,所以要消重。

👆注意IN
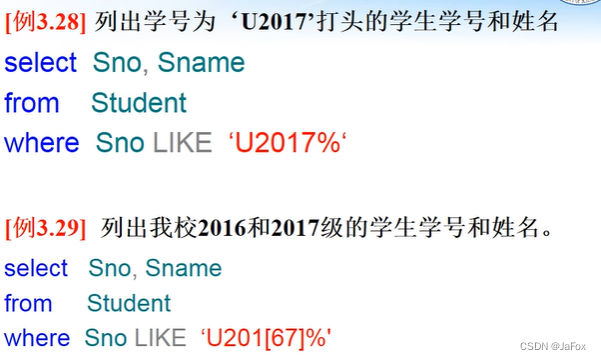
第二个,方括号表示一个集合,集合里面的任何一个元素都可以。


表示反斜杠后面的……(两个百分号就是百分号)。

NULL只能用is
聚集函数

👆函数统计 行、列的情况
–>可以认为count(*)就是统计 行的数量。
一列
(表中的一行称为元组)

统计行数就可以了。

病句:

统计函数和任何属性并列,都表示它是一个带有group by的分组查询语句。
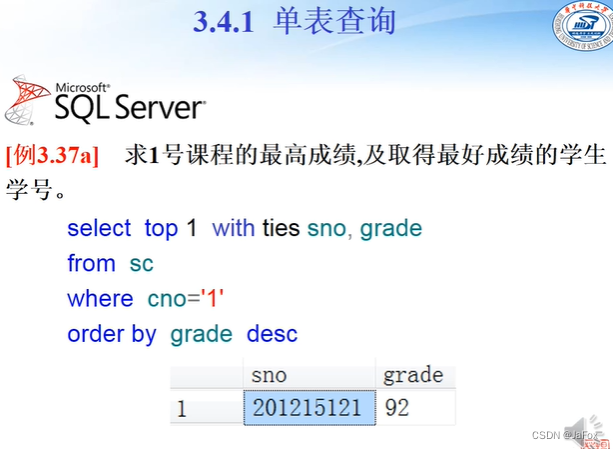
这样即知道最好成绩,又知道是哪位同学的。
top 1 要和 order by连用。(很好理解,要第一个,肯定是先排好顺序的)
with ties表示有并列的,同时列出。

limit 1限定查询结果为第一行
①定语,一般由where和having完成。②函数一般用在selec部分,如:列出人数、etc

分组统计查询:

👆group by什么,考虑最后表呈现的样子,如右图。

having count > 3一般就用count(*)不用count(列名)了
(👆因为?分组统计后的筛选是组筛选,而组筛选只有一个count())
明显,以学号为组别,进行分组统计(以宾语为group by,定语是筛选条件)。然后再进行==组筛选count()==。
一般会要求显示 统计结果(就是灰色部分)。
指定组别group by ,然后对组筛选having。

👆having中的count()内容和select的count内容对应。



注意👆
一个比较难的:
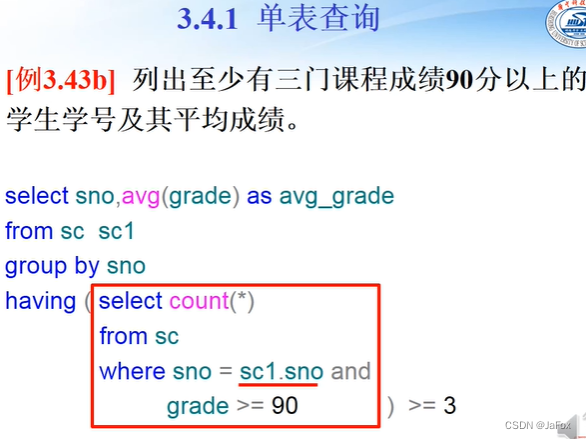
90分不是行选择,否则avg统计的是90分以上的课程的平均成绩。
方案:对每个组别,分别统计成绩在90分以上的门数,这个组别就是这个学号是那个学号的(图中画横线的)。
👆想象成:定语用定语从句来写,且需要连接词即“sno=sc1.sno”,“至少有三个”这样的条件可以在主句中实现。

显然,这是一个,以姓名第一个字为组别的计数统计。

要用到的表
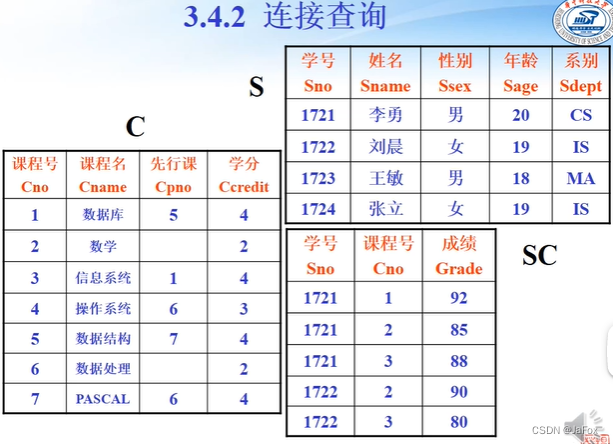

👆链接查询,两个表的列全连接在一起。
注意,student表有5列,sc表有三列,它们的等值连接就有8列。 其中有两个学号列,是一摸一样的,因为这是等值连接。
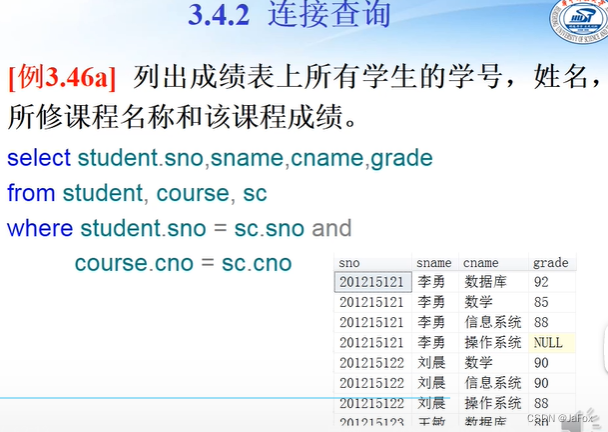
在多个表里查,注意用where=,即连接查询。sno在多个表中有,需要用前缀。

得再看看(内连接的关键词inner可以省略)
可以变成:
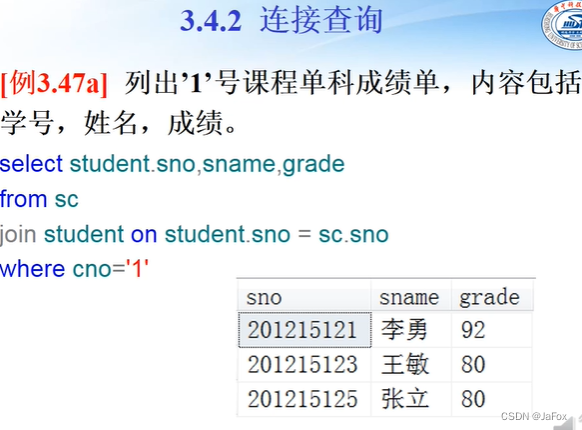
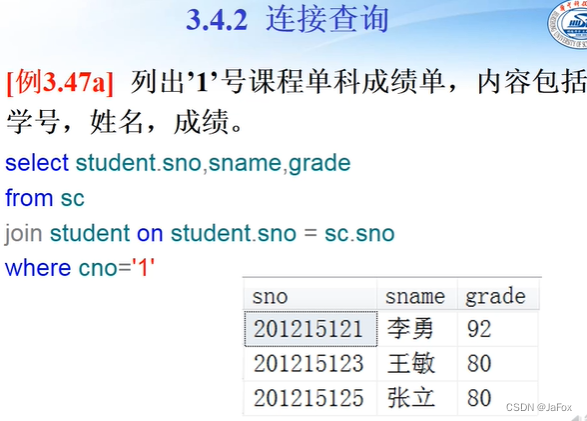
或者不用join语句:
不用join语句的内连接,就from两个表,写连接的桥的时候用前缀就行。
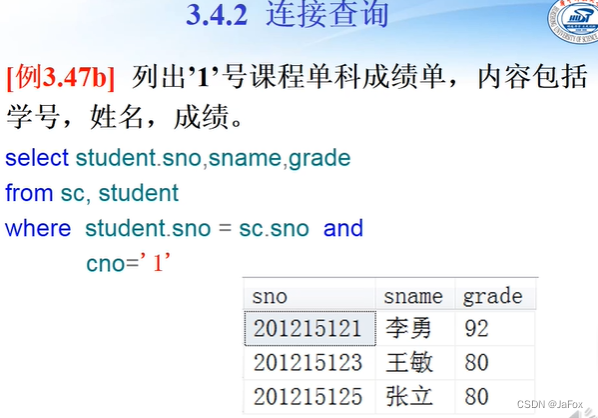
用到两个表的属性(一起在结果中显示出来),就需要用连接,即=或者join(其他的定语条件正常写出来就行)。
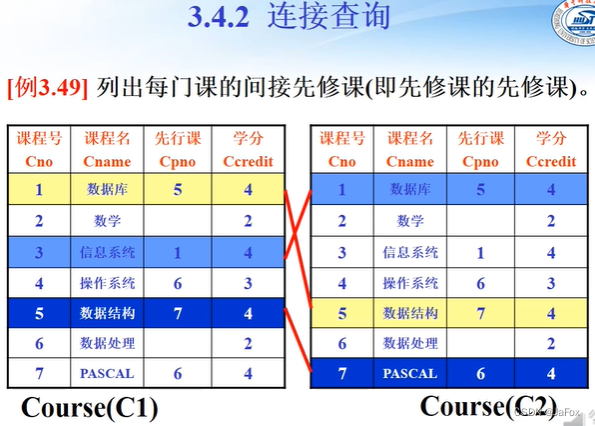
自连接,一个表取两个别名。然后语句为:
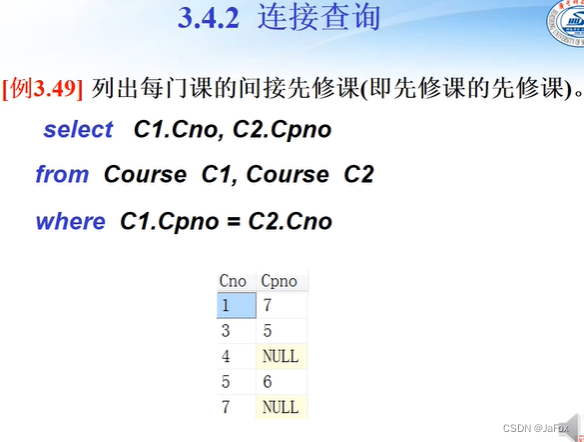
select处就能够用 重新命名的表名了。
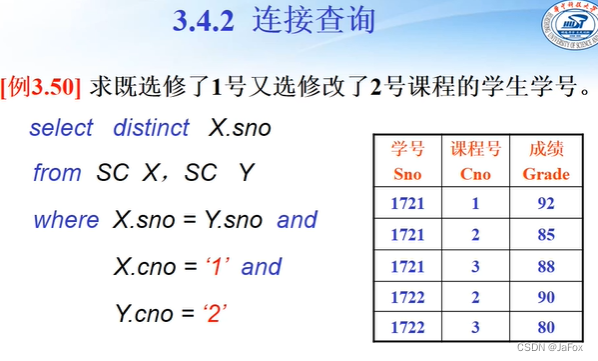
👆“既…又…”用两个表来表达。
外连接(左外右外)

内连接,是两个关系完全匹配上的元组(即没有悬浮元组)才显示在查询结果中。
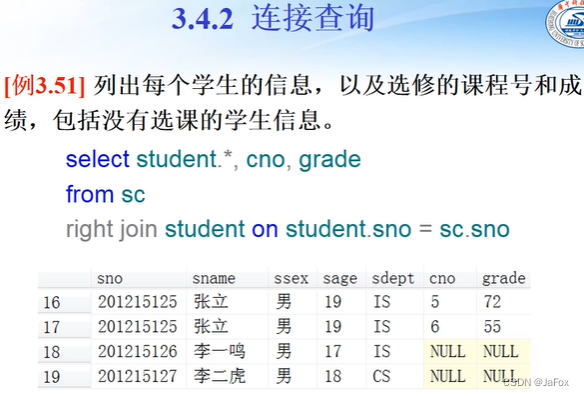
右:因“先出现的为左,后出现的为右。”
↑:先出现的SC表,再join的student表。
👆用join时,在from处不用写第二表的表名。 join…on…的on后面是两个表连接起来的哪个桥(即因为什么连接起来)。
右外,就是要求右边(后出现的)student表的悬浮元组出现在结果中。NULL的人家本来就没有,你student的几个元组缺cno、grade属性,你就是悬浮元组呗。

对上一个例子稍做筛选就可以得到。其中,这里左外是因为先写了student表。
内连接 可以用where子句的条件代替;外连接 不能用where代替。(就是join语句能不能换成where语句的问题)
用join表达连接是个好习惯。
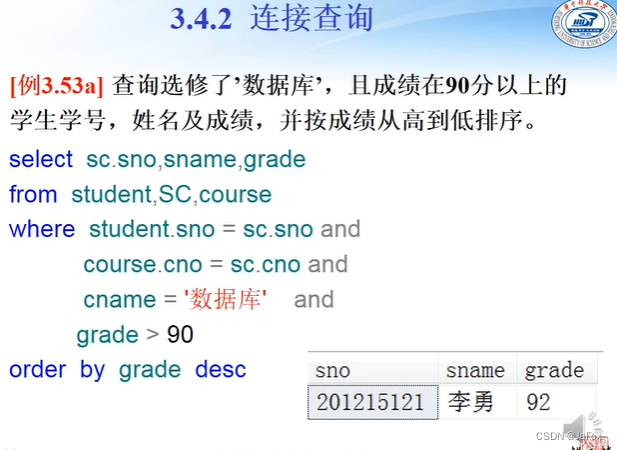
更好的习惯:把行条件 和 表连接条件 分开:
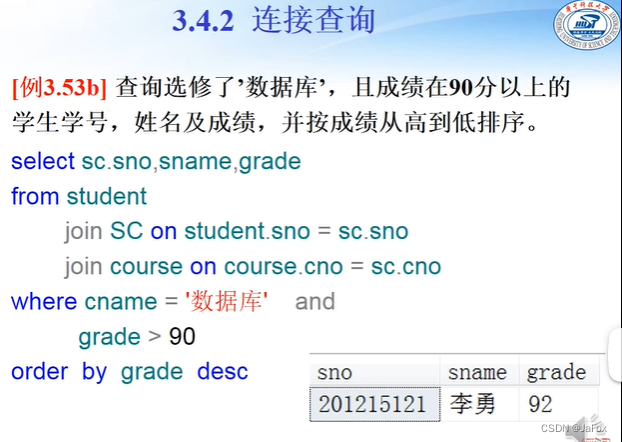
👆难度还好,都是内连接

可知:①至少需要两个表,student和sc。进而需要连接。②是一个以学号,姓名为组别的分组查询,因要统计每组的平均成绩(还要having筛选)。
group by部分:不能只有一列 sno或sname。
语法:group by组别中没有出现的列,不允许出现在查询列表中。(avg是自己建的,并不是原表中的一个列)
嵌套查询:

内层:查名称为数据库的课程号。



用in比=更安全(“唯一”时)。


A:查询列表很明确,来自的表,接下来就可以连接、选择(把这两部分条件写在一起了)。





↑相关子查询。

any,all用得比较少,可以用其他的表达。


两个条件:比计算机的年龄小,这个学生不是计算机的。
注意括号括的位置。

年龄小于 的另一种表达(小于最大):


相较上一个例子,any改all即可。
等价的表达:


例3.56的拓展:

思路:逐行查每个学生,看其在sc表中有没有数据库的课程记录。
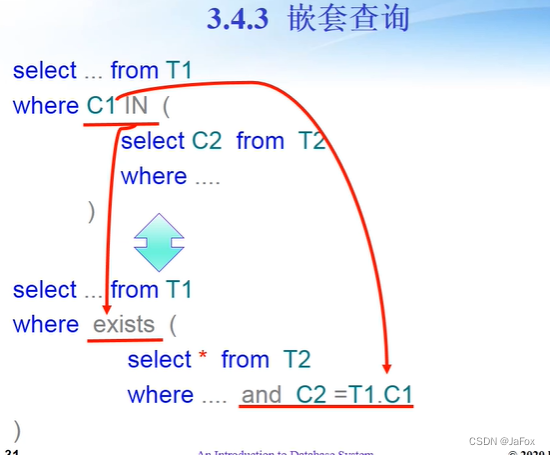




错误的,因:
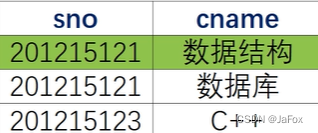
第一行不是数据库,不等于这个学生没选数据库。

exists是逻辑性最强的,但不一定最简单。

任何P=不存在使得P不成立的x。


查student表中的每个学生,满足以下条件的行,在course表中没有这样的课程,在sc表中没有这样的学生关于这门课程的记录。


查每个课程,课程号不在这个学生的选修记录中。

可以↓这么替换,其实没必要,↑更简洁更好理解。

(第一个not exists不能用not in替代)
ch03part3的20:00左右有两个大例子



查询逻辑:排查sc表的每一行,找出符合以下条件的行,15122选修了,而这位同学没有选修的课程为空(?大概这个意思)。
sc表的三次出现分别被命名为X Y Z。
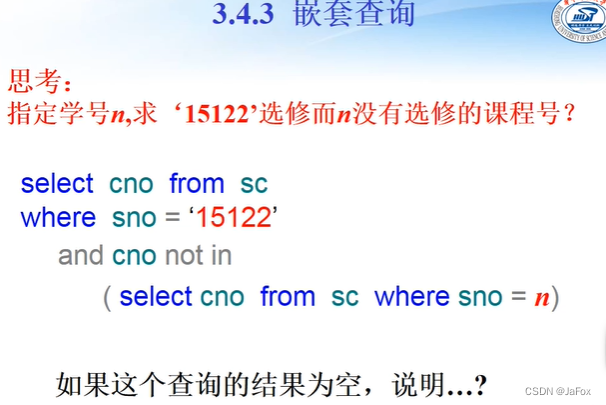
说明:15122选修了的,这位同学都选修了。
扫描学生表,依次把学号代入,凡查询结果不存在的皆为所求。

↑更简洁。
小改:

sc用了两次,把一次命名为Y即可。



查询逻辑:依次查询sc每一行,只要在sc中同一学生的另一门课的选修记录。























 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









