







 本文指导如何为MovieDB数据库创建艺人表'imdbnumber'唯一索引,增加演员出生地信息,并通过update语句添加。后续详细介绍了8个SQL查询,涵盖电影信息、演员年龄、角色关联、洲际统计、人口分析等。
本文指导如何为MovieDB数据库创建艺人表'imdbnumber'唯一索引,增加演员出生地信息,并通过update语句添加。后续详细介绍了8个SQL查询,涵盖电影信息、演员年龄、角色关联、洲际统计、人口分析等。
先贴一下实验要求:
1、准备工作
1.选择实验1创建的数据库MovieDB
2.为艺人表中的'imdbnumber'列创建唯一索引
3.导入country.sql创建country表和数据
4.修改演员表,增加出生地(birthplace),类型与country表的code列一致,并建立外键关联
使用update语句为已有演员添加相应的出生地
2、实现以下查询
1.查询所有电影的电影名、时长与上映日期
2.查询年龄小于40岁的女演员的姓名和年龄
3.查询所有艺人演出的电影ID及角色名
4.查询全世界各洲(Continent)的名称
5.查询南美洲人口数量小于1千万的国家,并按人口由多到少排序
6.查询欧洲国家的数量
7.查询人最多和人最少的国家的人口数量(0除外)
8.查询演员出生地都有哪些(结果不能重复)
首先是准备工作:
1、为艺人表中的'imdbnumber'列创建唯一索引
使用如下语句创建索引:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name[USING index_type] ON tbl_name (index_col_name 次序,...)索引可以建立在表的一列或多列上 ,各列名之间用逗号分隔,最多16列
<次序>为ASC(升)/DESC(降),缺省值为ASC
UNIQUE:此索引每一个值只对应唯一的数据记录
FULLTEXT:全文索引
SPATIAL:控件索引
index_type:BTREE、HASH
本题实例如下:
CREATE UNIQUE INDEX imdb ON Artist(imdbnumber);修改索引使用如下语句:
ALTER TABLE tbl_name RENAME INDEX old_index_name TO new_index_name;删除索引使用如下语句:
DROP INDEX index_name ON tbl_name;2、修改演员表,增加出生地(birthplace),类型与country表的code列一致,并建立外键关联
使用update语句为已有演员添加相应的出生地
修改增加使用如下语句:
ALTER TABLE tbl_name ADD col_name col_type;本题实例如下:
ALTER TABLE Artist ADD birthplace char(3);建立外键关联使用如下语句:
ALTER TABLE <更改的表名> ADD CONSTRAINT 自己取的联系名 FOREIGN KEY(本表列名) REFERENCES 目标表名(目标表列名);本题实例如下:
ALTER TABLE Artist ADD CONSTRAINT birthplace FOREIGN KEY(birthplace) REFERENCES country(CODE);update语句格式为:
UPDATE <表名> SET <列名>=<表达式>[, <列名>=<表达式>]...[WHERE <条件>]本题实例如下:
UPDATE Artist SET birthplace ='CHN' WHERE id=1;准备工作做完了,接下来做查询工作。
查询知识点:
查询使用如下语句:
SELECT [ALL|DISTINCT] <目标列表达式>[,<目标列表达式>]...FROM <表名或视图名>[, <表名或视图名> ] ...[ WHERE <条件表达式> ][ GROUP BY <列名1> [ HAVING <> [ HAVING <条件表达式> ] ][ ORDER BY <列名2> [ ASC|DESC ] ]> [ ASC|DESC ] ]3
其中涉及知识点:
(1)查询公式解读:
选择表中的若干列——SELECT子句
选择表中的若干元组——WHERE子句
对查询结果排序——ORDER BY子句
对查询结果进行统计、计算——使用聚集函数
对查询结果分组统计——GROUP BY子句
(2)查询所有列
如果列的显示顺序与其在基表中的顺序相同,则将<目标列表达式>指定为 * ,否则就一个个输入
(3)起别名AS
如SELECT Sname AS 姓名,也可以省略AS直接把别名写在后面
(4)DISTINCT关键词可过滤重复元组
(5)WHERE语句中可以使用的语句:

(6)NOW( )、YEAR( )、MONTH( )、DAY( )
NOW( )函数返回系统日期时间,YEAR( )函数返回年份,MONTH( )函数返回月份,DAY( )函数返回日,组合一下可以做一些简单运算
(7)通配符
% (百分号) 代表任意长度(长度可以为 0) 的字符串
a%b——表示以a开头,以b结尾的任意长度的字符串。如:acb,addgb,ab 等
_ (下划线) 代表任意单个字符
a_b——表示以a开头,以b结尾的长度为 3的任意字符串。如:acb,afb等
(8)ORDER BY语句用法:
ORDER BY <列名1> [ASC|DESC][, <列名2> [ASC|DESC]...];(9)聚集函数(库函数)
COUNT([DISTINCT|ALL] * )统计元组个数
COUNT([DISTINCT|ALL]<列名>) 统计一列中值的个数
SUM([DISTINCT|ALL] <列名>) 计算——使用聚集函数一数值列值的总和
AVG([DISTINCT|ALL]<列名>) 计算——使用聚集函数一数值列值的平均值
MAX([DISTINCT|ALL]<列名>) 求一列值中的最大值
MIN([DISTINCT|ALL] <列名>) 求一列值中的最小值
(10)GROUP BY语句用法:
GROUP BY <分组列> [, <分组列> ...][HAVING <分组条件>];GROUP BY子句要和聚合函数配合使用才能完成分组查询,在SELECT查询的字段中,如果没有使用聚合函数就必须出现在ORDER BY子句中。
GROUP BY子句分组的列名一般也要存在于SELECT查询中,如SELECT student.Sname,SUM(Ccredit) FROM student,course,sc WHERE student.Sno=sc.Sno AND course.Cno=sc.Cno GROUP BY student.Sno,student.Sname;
(11)Invalid use of group function解决办法
错误写法:
SELECT student.Sname,SUM(Ccredit) FROM student,course,sc WHERE student.Sno=sc.Sno AND course.Cno=sc.Cno AND SUM(Ccredit)<30 GROUP BY student.Sno,student.Sname;正确写法:
SELECT student.Sname,SUM(Ccredit) FROM student,course,sc WHERE student.Sno=sc.Sno AND course.Cno=sc.Cno GROUP BY student.Sno,student.Sname HAVING SUM(Ccredit)<30;WHERE和HAVING的区别在于:
where 子句的作用是对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
现在开始查询:
1.查询所有电影的电影名、时长与上映日期
SELECT name,duration,releasedate FROM movie;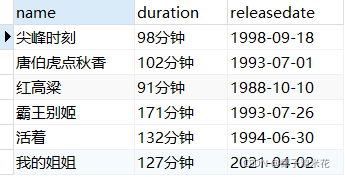
2.查询年龄小于40岁的女演员的姓名和年龄
SELECT name,sex,year(now())-year(birthday) AS age FROM artist WHERE year(now())-year(birthday)<40 AND sex='女';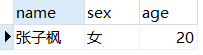
3.查询所有艺人演出的电影ID及角色名
SELECT artist.name,movie.id AS movieid,rolename FROM artist,movie,participation WHERE artist.id=movie.id AND movie.id=participation.id;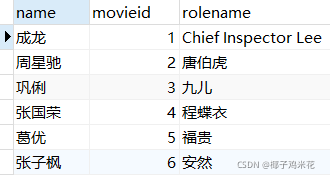
4.查询全世界各洲(Continent)的名称
SELECT DISTINCT Continent FROM country;
5.查询南美洲人口数量小于1千万的国家,并按人口由多到少排序
SELECT `Name` FROM country WHERE Population<10000000 AND Continent='South America' ORDER BY Population DESC;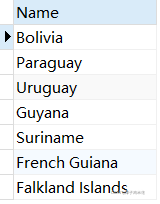
6.查询欧洲国家的数量
SELECT COUNT(*) FROM country WHERE Continent='Europe';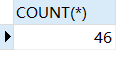
7.查询人最多和人最少的国家的人口数量(0除外)
SELECT MAX(Population) AS maxpopulation, MIN(Population) AS minpopulation FROM country WHERE Population>0;
8.查询演员出生地都有哪些(结果不能重复)
SELECT DISTINCT birthplace FROM artist;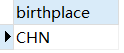
作业完成,下次见!


















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









