







数据库增删改查
每个继承自models.Model 的模型类,都会有一个objects对象被同样继承下来
这个对象叫管理器对象数据库的增删改查可以通过模型的管理器实现

创建一条数据
DjangoORM使用-种直观的方式把数据库表中的数据表示成Python对象
创建数据中每一条记录就是创建一个数据对象
创建数据方法1
MyModel.object.create(属性1=值1,属性2=值2)
- 成功:返回创建好的实体对象
- 失败:抛出异常
创建数据方法2
创建 MyModel 实例对象,并调用save()进行保存
类似于类属性赋值的操作
obj = MyModel(属性1=值1,属性2=值2)
obj.属性 = 值
obj.save()
只有当调用最后的 obj.save() 的时候,我们的数据才会真正的插入
Django Shell
-
在Django提供了一个交互式的操作项目叫Django Shell它能够在交互模式用项目工程的代码执行相应的操作
-
利用Django Shell可以代替编写view的代码来进行直接操作
-
注意:项目代码发生变化时,重新进入Django shell
-
启动方式:
python manage.py shell
from bookstore.models import Book
# 方法一创建
b1 = Book.objects.create(书名="Python",出版社="清华大学出版社",价格=20,零售价=25)
# 方法二创建
b2 = Book(书名="Django",出版社="人民大学出版社",价格=80,零售价=56.6)
b2.save()
# 方法二创建
bizmin = Users()
bizmin.name = request.POST['name']
bizmin.age = request.POST['age']
bizmin.phone = request.POST['phone']
bizmin.save()
数据库查询
all()方法
MyModel.objects.all()- 使用这个数据可以用来查询 MyModel 中的所有数据,等同于
SELECT * FROM table - 返回值:
- QuerySet容器对象,内部存放MyModel 实例
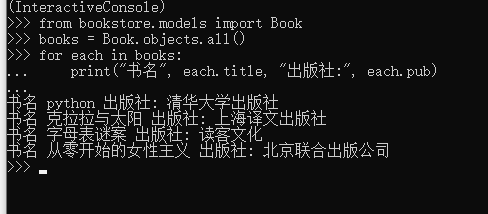
from bookstore.models import Book
books = Book.objects.all()
for each in books:
print("书名", each.title, "出版社:", each.pub)
模型中定义打印方法__str__
我们每一次这样都需要使用 for 循环来显示我们的内容,这个时候我们可以前往我们的模型层里面,给里面添加一个__str__方法
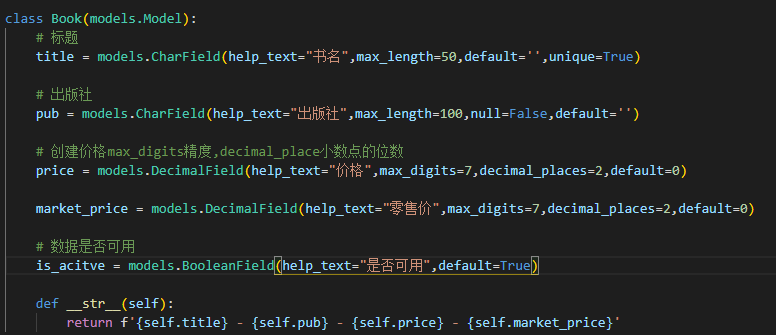
class Book(models.Model):
# 标题
title = models.CharField(help_text="书名",max_length=50,default='',unique=True)
# 出版社
pub = models.CharField(help_text="出版社",max_length=100,null=False,default='')
# 创建价格max_digits精度,decimal_place小数点的位数
price = models.DecimalField(help_text="价格",max_digits=7,decimal_places=2,default=0)
market_price = models.DecimalField(help_text="零售价",max_digits=7,decimal_places=2,default=0)
def __str__(self):
return f"{title} - {pub} - {price} - {market_price}"

我们没有修改数据库数据,只是修改了 Python 内的方法,不需要使用 makegrations 和migrate
values()方法
MyModel.objects.values(‘列1’, ‘列2’)- 作用:查询部分列的数据然后返回
- 等同于 sql 中的
SELECT row1,row2 from table
- 等同于 sql 中的
- 返回值
- QuerySet ,返回的是一个QuerySet,但是内部存的是字典,每一个字典代表着一个数据,格式为:
{‘row1’: ‘value1’, ‘row2’: ‘value2’}
- QuerySet ,返回的是一个QuerySet,但是内部存的是字典,每一个字典代表着一个数据,格式为:

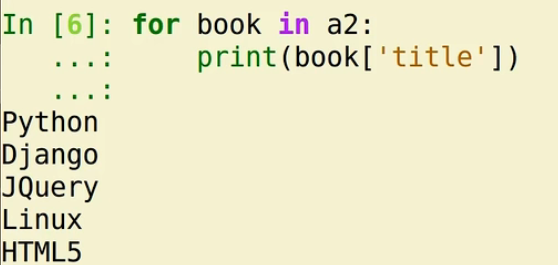
因为这个时候我们里面是字典了,所以我们取值的时候也要使用字典的方式来取值
for each in book:
print(each['title'])
values_list() 方法
-
MyModel.objects.values_list(‘列1’, ‘列2’) -
values_list 与 values 的区别在于 values_list 返回的是一个元组,我们最后输出元素的时候就不能使用字典的方式来取值,而是应该使用索引的方式来进行取值

order_by() 方法
- 用法
MyModel.objects.order_by(‘列1’, ‘-列2’) - 与
all()方法一致,但是它会用SQL语句的ORDER BY子句对查询结果
进行根据某个字段选择性的进行排序 - 说明
- 默认是按照升序排序,降序排序则需要在列前增加
-表示
- 默认是按照升序排序,降序排序则需要在列前增加


方法的融合
我们可以把这些方法合起来使用
- 搜索我们列名字叫 title 的元素, 然后将他们按照 价格 的降序进行排列
Book.objects.values("title").order_by("-price")

显性查看 django 调用的 sql 语句
query方法
a = Book.objects.values("title").order_by("-price")
print(a.query)

练习 查看所有书籍
- 编写
all_book.html模板文件
<table class="tb1" border="1">
<tr>
<th>id</th>
<th>title</th>
<th>pub</th>
<th>price</th>
<th>market_price</th>
<th>op</th>
</tr>
{% for eachrow in data %}
<tr>
{% for eachvalue in eachrow.values %}
<td>{{eachvalue}}</td>
{% endfor %}
<td>
<a href="#">更新</a>
<a href="#">删除</a>
</td>
</tr>
{% endfor %}
</table>
我们使用模板层来让他实时更新
- 编写我们的 views.py 内的视图函数
from django.shortcuts import render
from .models import Book
def all_books(request):
# 从数据库读取数据
data = Book.objects.values().order_by('price')
dataLength = len(data)
return render(request, 'bookstore/all_book.html',locals())
- 配置主路由和子路由
# 主路由 urls.py 文件内
from django.urls import path, include
from . import views
urlpatterns = [
path('bookstore/',include('bookstore.urls'))
]
# 子路由 urls.py 文件内
from django.urls import path, re_path
from . import views
urlpatterns = [
path('all_book',views.all_books)
]
- 打开页面查看成果
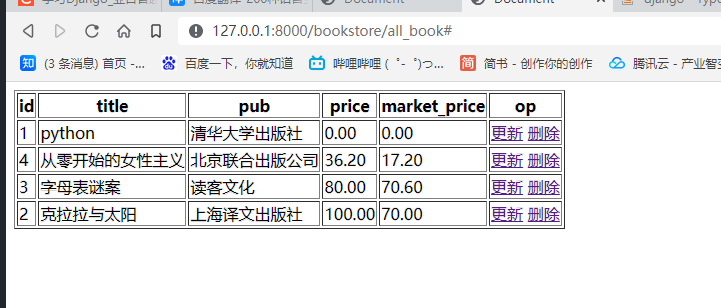
可喜可贺!现在视图MTV已经完全打通,django取得阶段性胜利
数据过滤
filter() 返回过滤后的值
- filter(条件)
- 语法
- MyModel.objects.filter(属性1=值1,属性2=值2)
- 作用
- 返回包含此条件的全部数据集
- 返回值
- QuerySet容器对象,内部存放 MyModel 实例
例子
#查询书中出版社为"清华大学出版社"的图书 from bookstore.models import Book books = Book.objects.filter(pub="清华大学出版社") for book in books: print("书名:" , book. title) #查询Author实 体中name为王老师并且age是28岁的 authors=Author.objects.filter(name='王老师' ,age=28)
exclude() 返回不包含条件的值
- exclude(条件)
- 语法
- MyModel.objects.exclude(属性1=值1,属性2=值2)
- 作用
- 返回不包含此条件的全部数据集
- 示例:查询清华大学出版社,定价等于50以外的全部图书
books = models.Book.objects.exclude(pub="清华大学出版社" , price=50)
for book in books :
print(book)
get() 获取符合条件的单条数据
- 语法
MyModel.objects.get(条件) - 作用
- 返回满足条件的唯一一条数据,该方法只能返回一条数据
- 查询结果多余一条数据则抛出
Model.MultipleObjectsReturned异常 - 如果没有数据则抛出
Model.DoesNotExist异常
查询谓词
我们的 django 没有办法直接书写类似 id>5这样的条件,但是我们可以使用查询谓词来达到同样的效果
- 定义
- 做更灵活的条件查询时需要使用查询谓词
- 说明
- 每一个查询谓词是一个独立的查询功能
exact 等值匹配
Author.objects.filter(id__exact=1)
# 等同于 SELECT * from author where id =1
这里我们 __exact前面的id,表示我们想要查询的属性,后面是我们的值
我们的 exact 主要用来查询 null 值
contains 包含指定值
Author.objects.filter(name__contains="w")
# 等同于 SELECT * FROM author WHERE name like '%w'
更多的查询谓词
| 查询谓词 | 说明 |
|---|---|
__startswith | 查询以 XXX 开始 |
__endswith | 查询以 XXX 结束 |
__gt | 大于指定值( > \gt >) |
__gte | 大于等于( ≥ \geq ≥) |
__lt | 小于( < \lt < ) |
__lte | 小于等于( ≤ \leq ≤) |
__in | 查询数据是否在指定范围内 |
__range | 查询数据是否在指定的区间范围内 |
Author.objects.filter(country_in=['中国','日本','韩国'])
#等同于select * from author where country in ('中国','日本','韩国')
# 查询年龄在指定区间的所有作者
Author.objects.filter(age__range=(35,50))
# 等同于 SELECT * FROM author WHERE age BETWEEN 35 and 50;
更新数据
更新单个数据 get()
- 查
- 通过
get()得到需要修改的实体对象
- 通过
- 改
- 通过
对象.属性的方法修改数据
- 通过
- 保存
- 通过
对象.save()保存数据
- 通过
from bookstore.models import Book
# 获取一条数据,id得是为1
a = Book.objects.get(id=1)
# 修改这个数据的价格
a.price = 50
# 保存数据
a.save()
- 没有更新之前的数据
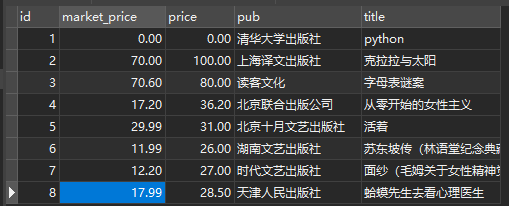
- 更新之后的数据
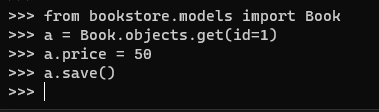
可以看到我们的 price 变成了 50
批量更新数据 update()
-
使用方法
update(属性 = 值)来对选中的值进行批量更改
-
例子1 将 id 大于 3 的所有图书价格定义为 100 元
# 将 id 大于 3 的所有图书价格定义为 100 元
from bookstore.models import Book
# 选中所有大于3的数据
books = Book.objects.filter(id__gt=3)
# 批量进行更新
books.update(price = 100)
- 例子2 把所有的图书零售价都设置为 80
# 把所有的图书零售价都设置为 80
from bookstore.models import Book
# 选中所有大于3的数据
books = Book.objects.all()
# 进行批量修改
books.update(market_price = 80)
练习 完善之前制作的图书管理
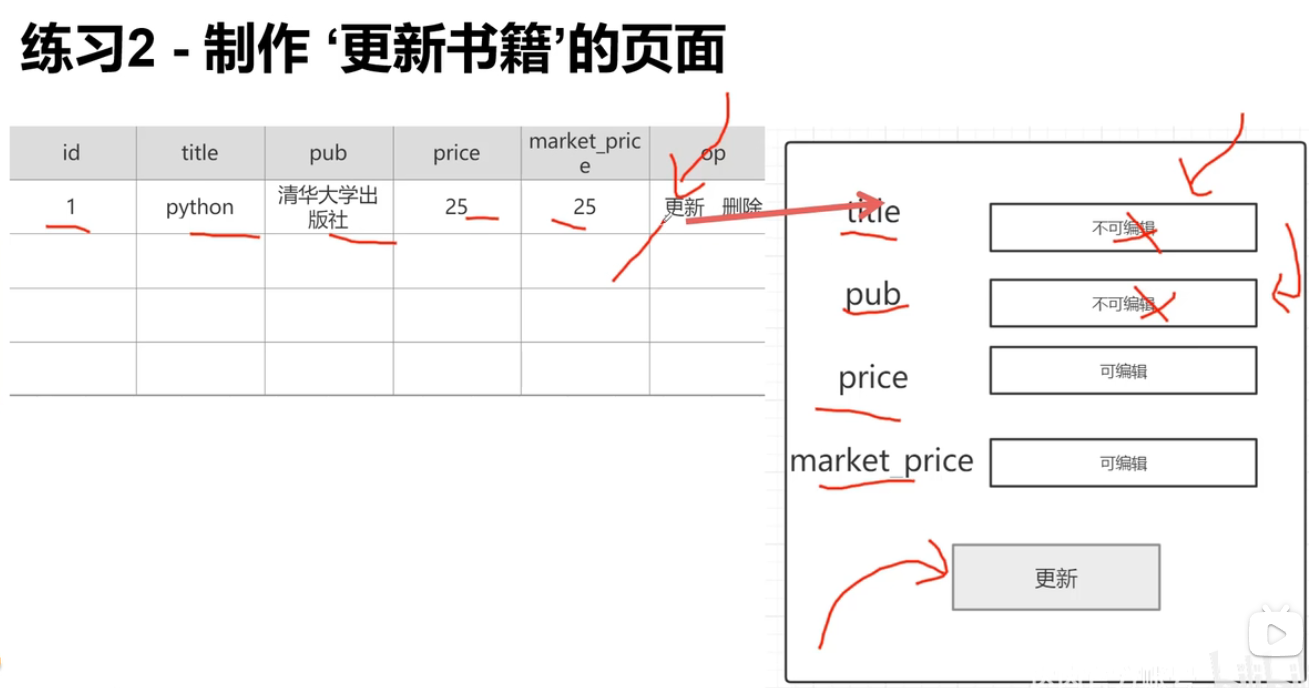
- 制作页面为
all_book.html页面的更新链接添加真正的逻辑
<table class="tb1" border="1">
<tr>
<th>id</th>
<th>title</th>
<th>pub</th>
<th>price</th>
<th>market_price</th>
<th>op</th>
</tr>
{% for eachrow in data %}
<tr>
{% for eachvalue in eachrow.values %}
<td>{{eachvalue}}</td>
{% endfor %}
<td>
<a href={% url "update_book" eachrow.id %}>更新</a>
<a href="#">删除</a>
</td>
</tr>
{% endfor %}
</table>
- 前往视图设置函数
# views.py 文件内
from django.http import HttpResponse, HttpResponseRedirect
from django.shortcuts import render
from .models import Book
def update_book(request,id):
try:
book = Book.objects.get(id=id)
except:
print("未找到相关图书")
return HttpResponse("未找到相关图书")
if request.method == 'GET':
return render(request, 'bookstore/update_book.html',locals())
if request.method == 'POST':
# 读取
#title = request.POST.get('title','ERROR')
#pub = request.POST.get('pub','ERROR')
price = request.POST.get('price','ERROR')
market_price = request.POST.get('market_price','ERROR')
# 修改
#book.title = title
#book.pub = pub
book.price = price
book.market_price = market_price
# 保存
book.save()
return HttpResponseRedirect('/bookstore/all_book')
- 设置路由,顺便添加反向解析
# 子路由 urls.py 文件内
from django.urls import path, re_path
from . import views
# 添加反向代理 name
urlpatterns = [
path('all_book',views.all_books,name='all_book'),
path('update_book/<int:id>',views.update_book,name='update_book'),
]
- 制作被更新后的操作界面
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div {
text-align: center;
margin-top: 270px;
margin-left: 20%;
font-size: 24px;
background-color: #bfa;
float: left;
width: 50%;
}
</style>
</head>
<body>
<div>
<form method="post" action='{% url "update_book" book.id %}'>
<p>
title = <input type="text" name="title" value="{{book.title}}" disabled="disabled">
</p>
<p>
pub = <input type="text" name="pub" value="{{book.pub}}" disabled="disabled">
</p>
<p>
price = <input type="text" name="price" value="{{book.price}}">
</p>
<p>
market price = <input type="text" name="market_price" value="{{book.market_price}}">
</p>
<input type="submit" name="提交">
</form>
<a href={% url 'all_book' %}>
<button>返回图书列表</button>
</a>
</div>
</body>
</html>
- 查看页面端效果
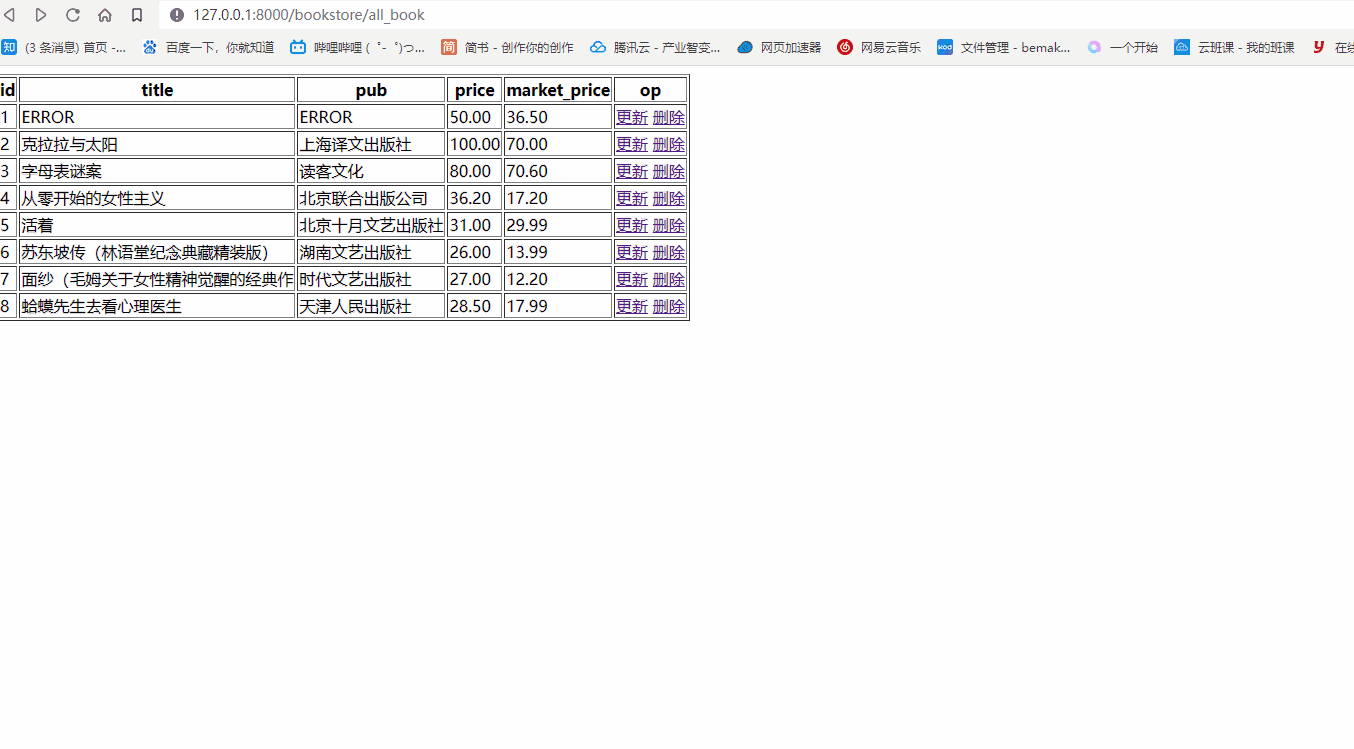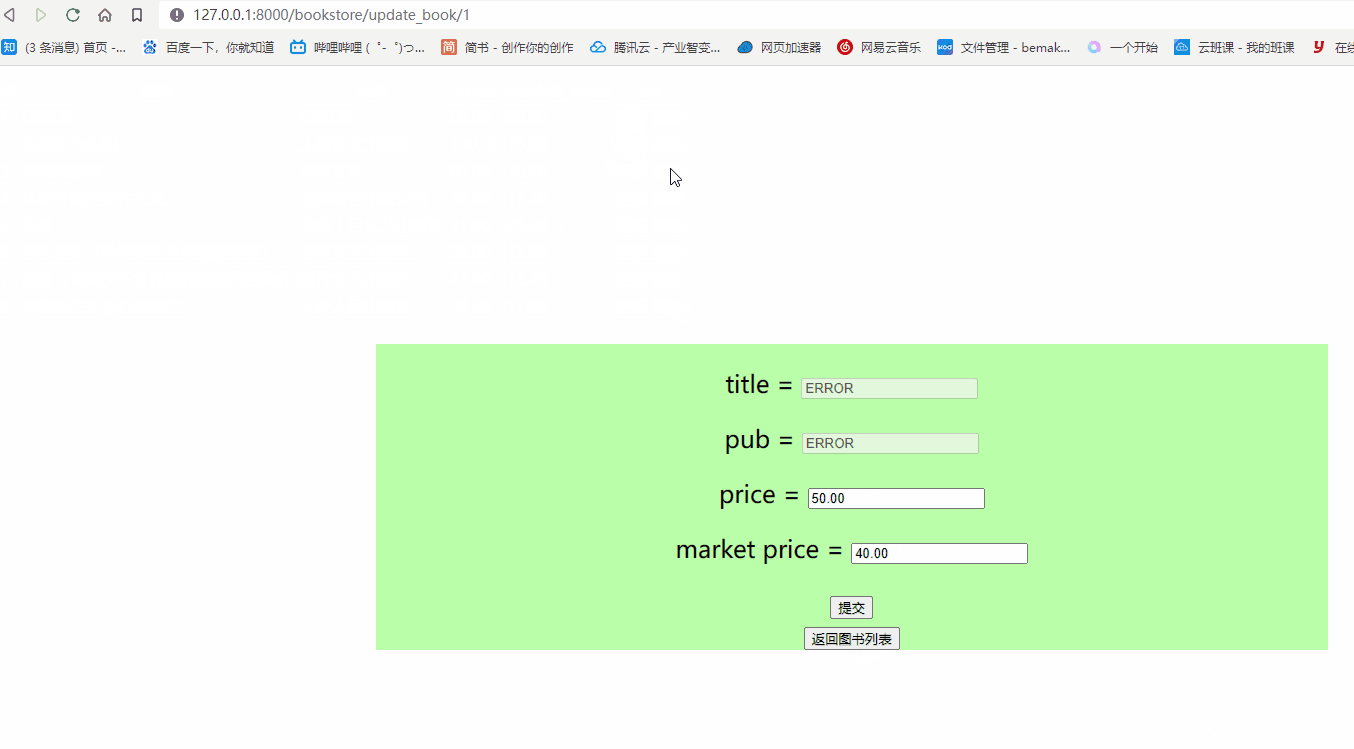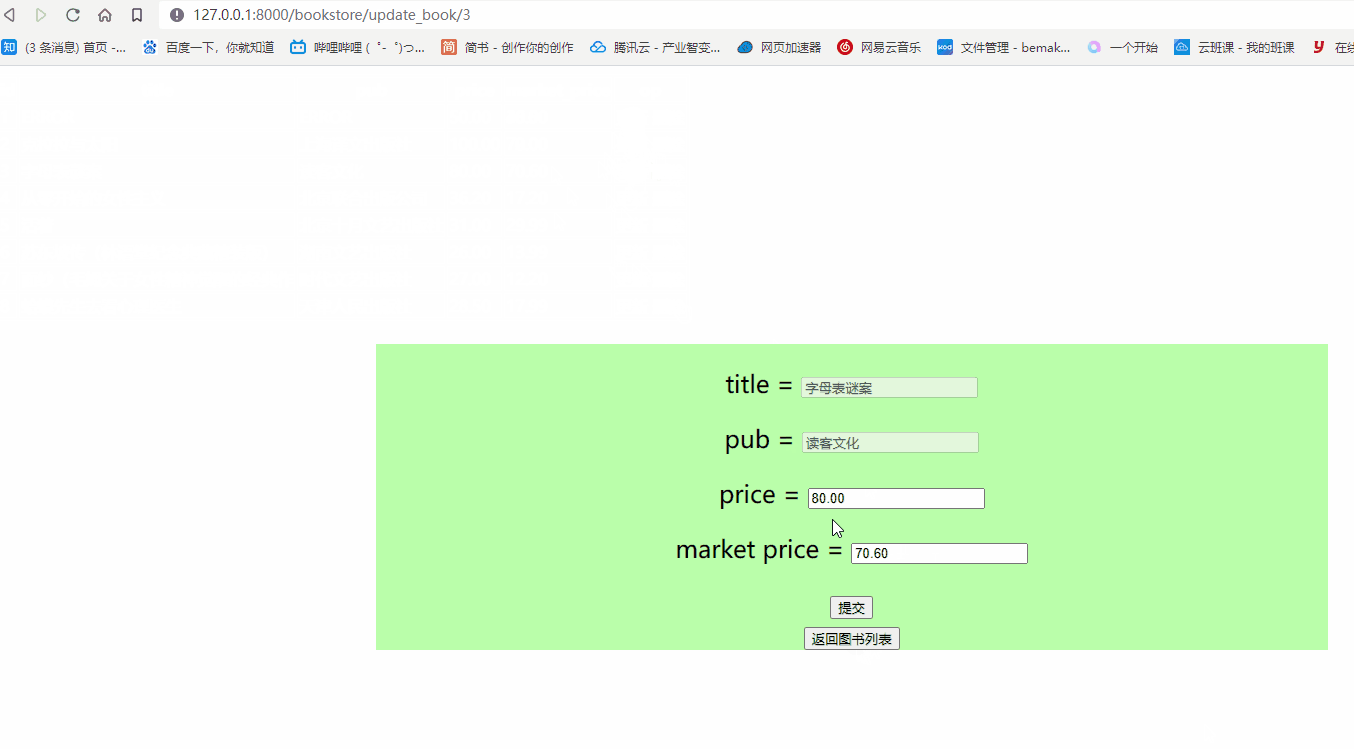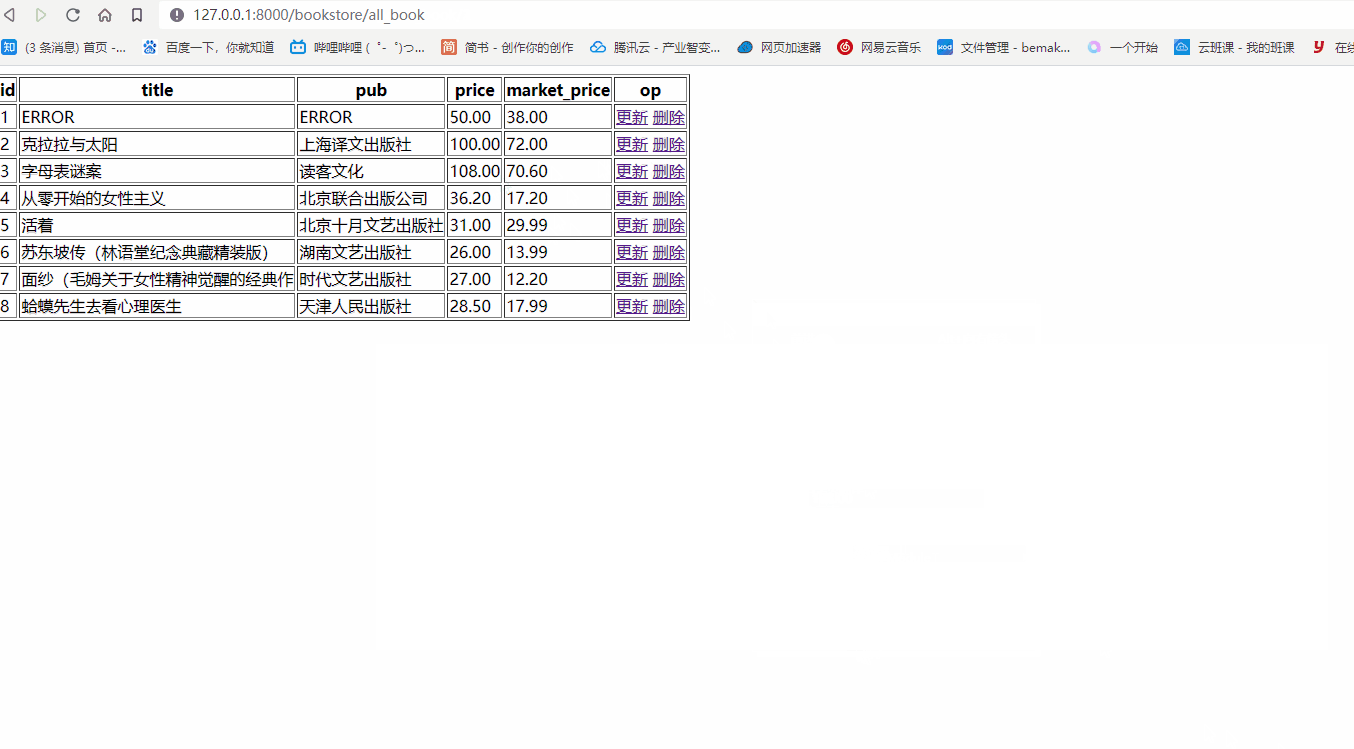
数据删除
单个数据删除
-
查找查询结果对应的一个数据对象
-
调用这个数据对象的
delete()方法实现删除
try:
# 因为 get 可能会报错,所以我们需要加上 get
auth = Author.objects.get(id=1)
auth.delete()
except:
print("删除失败")
批量删除多个数据
-
查询结果满足条件的全部 QuerySet 查询集合对象
-
调用查询集合对象的
delete()方法实现删除
# 删除全部作者中,年龄大于65的
auths = Author.objects.filter(age__gt=65)
# 删除
auths.delete()
伪删除
- 互联网时代数据是很贵的,我们不希望直接把数据删掉
- 通常不会轻易在业务里把数据真正删掉,取而代之的是做伪删除即在表中添加一个布尔型字段(
is_active),默认是True; - 执行删除时,将欲删除数据的
is_active字段置为False. - 注意:用伪删除时,确保显示数据的地方,均加了
is_active=True的过滤查询
练习 给我们的页面添加删除

-
给我们的数据库添加新的字段 is_active 来判断数据是否有效
- 前往 models.py 文件中修改模型
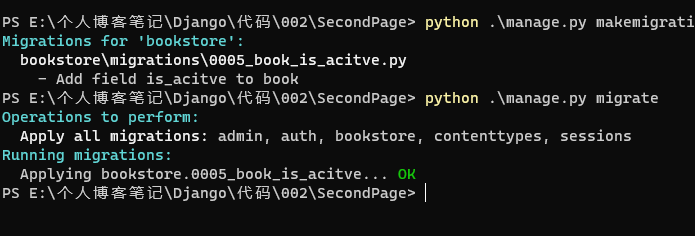
- 前往终端输入数据库迁移命令
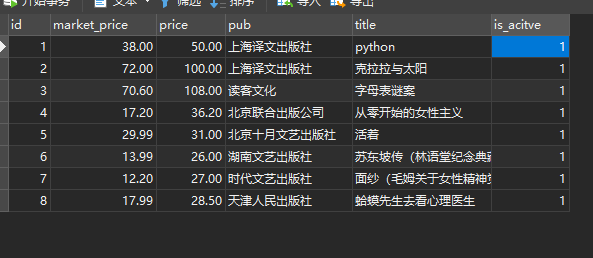
- 前往数据库查看是否修改成功
- 前往 models.py 文件中修改模型
-
添加一个新的视图来给我们的按钮添加逻辑
- 修改我们显示数据的视图(之前写的)
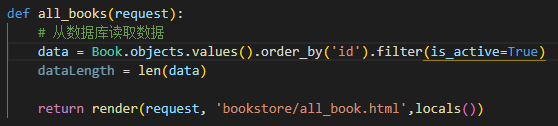
- 在函数的搜索条件修改一下,在最后加上一个过滤器
- 修改我们显示数据的视图(之前写的)
-
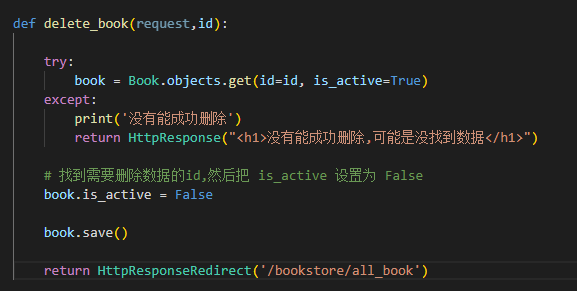
增加一个新的删除视图
-
给我们新加上一个路由地址
-
# 子路由的 ulrs.py 文件内 from django.urls import path, re_path from . import views urlpatterns = [ path('all_book',views.all_books,name='all_book'), path('update_book/<int:id>',views.update_book,name='update_book'), path('delete_book/<int:id>',views.delete_book,name='delete_book'), ]
-
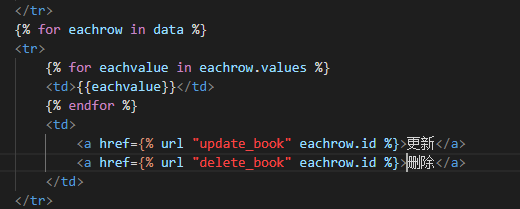
-
修改我们的
all_book.html文件内的代码 -
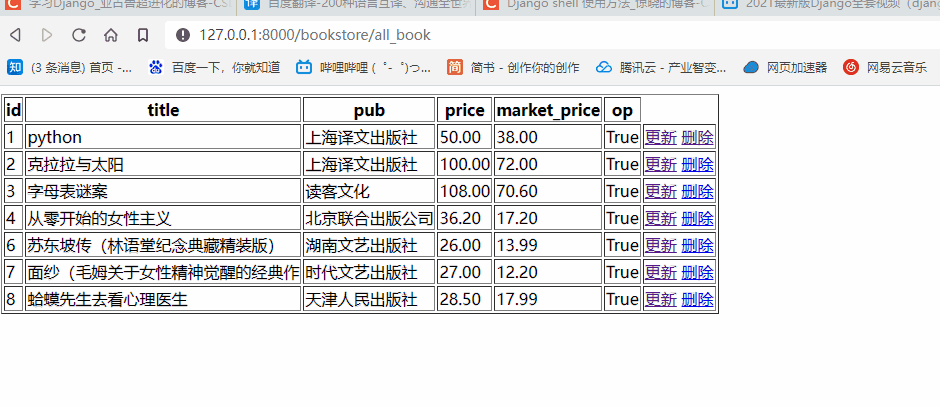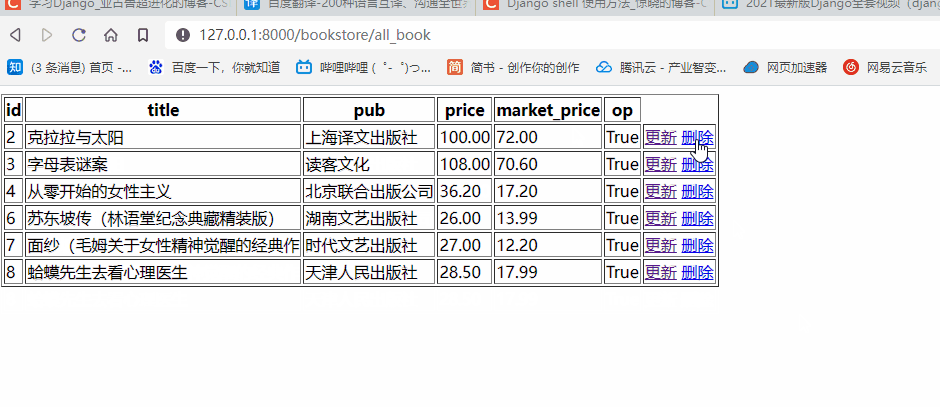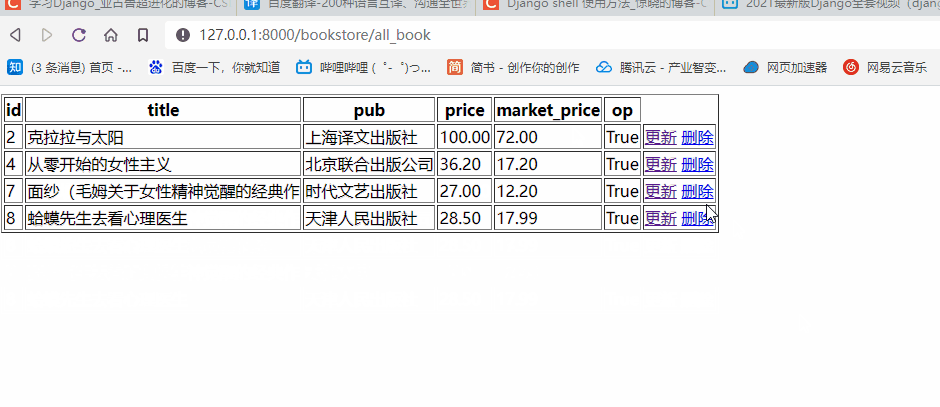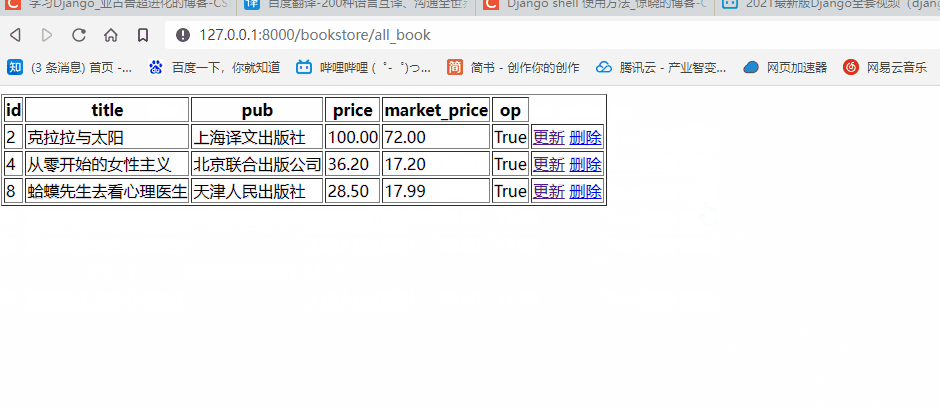
前往查看我们的网页是否能够正常实现功能
F 对象和Q 对象
F 对象
-
使用前需要先引入
from django.db.models import F -
一个F对象代表数据库中某条记录的字段的信息
-
作用
- 通常是对数据库中的字段值在不获取的情况下进行操作
- 一般用于类属性(字段)之间的比较
-
语法
-
from django.db.models import F # 使用 F("列名")
-

使用 F
# 对于我们数据库中 market_price 中的所有的值 + 10 Book.objects.all().update(market_price=F("market_price") + 10)我们调用 F 其实只是输入了一条 sql 语句
UPDATE bookstore_book SET market_price = bookstore_book.market_price + 10;这样我们大量的操作就会留存到 sql 中来操作,我们便可以节约大量的时间
如果不使用 F
books = Book.objects.all() for book in books: book.market_price=book.marget_price + 10 book.save()这个操作实际上有多少条数据我们就需要去数据库访问多少次,大量的时间都浪费在了我们 django 和 sql 通讯的
例子2 对数据库中两个字段的值进行比较,列出哪些书的零售价高于定价
from django.db.models import F from bookstroe.models import Book books = Book.objects.filter(market_price__gt=F("price")) for book in books: print(book.title, "定价:",book.price, "现价:", book.market_price)
Q对象
当在获取查询结果集使用复杂的逻辑或|、逻辑非等操作时可以借助于Q对象进行操作
-
使用前需要先导入
from django.db.models import Q -
例子
-
如果想要找出定价低于20元 或者清华大学出版社的全部书,可以这样写
-
Book.objects.filter(Q(price__lt=20) | Q(pub="清华大学出版社"))
-
-
我们在条件中还可以实现
and(&),or(|),not(~)操作 -
语法:
-
from django.db.models import Q # 或语句 Q(条件1) | Q(条件2) # And 语句 Q(条件1) & Q(条件2) # 非语句(条件1成立且条件2不成立) Q(条件1) &~ Q(条件2) # 条件1不成立的语句 ~ Q(条件1)
-
聚合查询
聚合查询是指对一个数据表中的一个字段的数据进行部分或全部进行统计查询查bookstore_ book数据表中的全部书的平均价格,查询所有书的总个数等,都要使用聚合查询
聚合查询分为
- 整表聚合
- 分组聚合
整表聚合
不带分组的聚合查询是指将全部数据进行集中统计查询
聚合函数
- 使用前需要先导入
from django.db.models import * - 聚合函数
- Sum, Avg, Count, Max, Min
- 语法
MyModel.objects.aggregate(结果变量名=聚合函数(‘列’))
- 返回结果
- 结果变量名和值组成的字典,格式为
{“结果变量名”:值}
- 结果变量名和值组成的字典,格式为
其中结果变量名就是最终我们输出字典的时候我们的表头,类似 sql 里面的 as 给表头重命名

分表聚合
分组聚合是指通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合
- 语法
QuerySet.annotate(结果变量名=聚合函数(‘列’))
- 返回值
- QuerySet


我们在分组之后因为又是一个 QuerySet 所以我们可以继续使用 filter 来过滤结果
原生数据库操作
-
MyModel.objects.raw()进行原生数据库的操作 -
语法
- MyModel.objects.raw(sql语句)
-
返回值
-
RawQuerySet 集合对象[只指出基础操作,比如循环]
-
books = models.Book.objects.raw('SELECT * from bookstore_book') for book in books: print(book)
-
cursor 游标
完全跨过模型类进行操作数据库
-
导入 cursor 所在的包
from django.db import connection
-
用创建 cursor 类的构造函数创建 cursor 对象, 再使用 cursor 对象,为保证在出现异常的时候能够释放 cursor 资源,我们通常使用 with 语句进行创建操作
-
from django.db import connection with connection.cursor() as cur: cur.execute("执行SQL语句")
-















 2097
2097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









