






机器学习第二天
如果异常值过多,归一化不精确
1.标准化
x
′
=
x
−
m
e
a
n
/
r
x'=x-mean/r
x′=x−mean/r
mean: 平均值
r: 标准差
标准差:离散程度,集中程度
对于标准化来说,少量的异常点,对结果影响不大
from sklearn.preprocessing import StandardScaler
data =pd.read_csv("dataing.txt")
data=data.iloc[:,:3]
print("data:\n",data)
transter=StandarScaler()
data_new=transter.fit_transform(data)
print("data_new:\n",data_new)
2.降维
降维:
维数: 嵌套的层数
0维 标量
1维 向量
2维 矩阵
3维 …
这里的维度是什么呢
这里是指降低特征的个数
:特征特征之间不相关
:相关的可能存在冗余信息
1.特征选择
filter过滤式
1.方差选择法:低方差特征过滤
2.相关系数法:衡量两个特征之间是否具有相关性
embeded 嵌入式
1.决策树
2.正则化
3.深度学习
1.低方差特征过滤
sklearn.feature_selection.VarianceThreshold(threshold=0.0)
# 低方差过滤
# 实例化数据
# 调用fit_transform
data = pd.read_csv()
data.iloc[:,:10]
print("data:\n",data)
transter=VarianceThreshold(threshold=10)
data_new=transter.fit_transform(data)
print("data_new\n",data_new,data_new.shape)
pearsonr(data[""],data[""])
皮尔森相关系数
r
=
n
r=n
r=n
2.
2.主成分分析
将高维数据,变为低位数据,但是在过程中,可能会舍弃原有的数据,创造新的变量,,损失少量信息,降低复杂度.
sklearn.decomposition.PCi(n_compomponents=None)
def Pca_DEMO():
# pca降维
data =[[2,8,4,5],[6,3,0,8],[5,4,9,1]]
transter=PCA(n_components=2)
data_new=transter.fit_transform(data)
print("data_new\n",data_new)
合并表怎么合并
import pandas as pd
tab1=pd.merge(aisles,products,on="aisle_id","aisle_id")
交叉表
table=pd.crosstab(tab3["user_id"],table2["aisle"])
2.sklearn转换器和预估器(estimor)
sklearn转换器和预估器
特征工程
1.实例化一个转换器
2.调用fit_transform。
fit 计算每一列的平均值,标准差
transform 标准化
转换器
1.实例化一个容器
estimator.fit(x_train,y_train)计算
---------调用完毕,模型生成
3.模型评估
1.直接比对真实值和预测值
y_predict=estimator.predict(x_test)
y_test=y_predict
2.计算准确率
estimator.score(x_test,y_test)//真实值,目标值
算法
k.近邻算法(KNN)
随大众,
一个样本离哪个最相似,则属于哪个类别
距离公式------欧氏距离
sklearn.neighbors.KNeighborsClassifier(n_neighbor=5,algorithm="auto")
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
def knn_iris():
iris =load_iris()
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=6)
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(x_train,y_train)
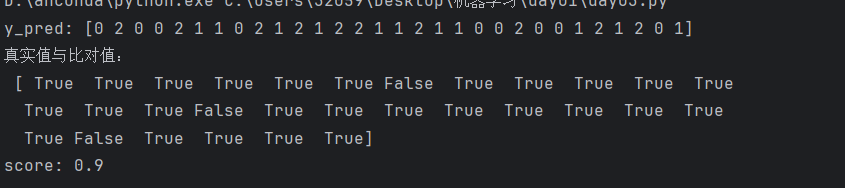
y_pred=clf.predict(x_test)
print("y_pred:",y_pred)
print("真实值与比对值:\n",y_test==y_pred)
score=clf.score(x_test,y_test)
print("score:",score)
if __name__ == '__main__':
knn_iris()
模型选择,与调优
1.交叉验证
将拿到的训练部分,分成四份分为训练集和验证集
分几组叫几折交叉验证

2.超参数-网格搜索

s
in,y_train)
y_pred=clf.predict(x_test)
print(“y_pred:”,y_pred)
print(“真实值与比对值:\n”,y_test==y_pred)
score=clf.score(x_test,y_test)
print(“score:”,score)
if name == ‘main’:
knn_iris()
[外链图片转存中...(img-nk31F1FF-1706575867068)]
###### 模型选择,与调优
1.交叉验证
将拿到的训练部分,分成四份分为训练集和验证集
分几组叫几折交叉验证
[外链图片转存中...(img-dCcGjxEI-1706575867068)]
###### 2.超参数-网格搜索
[外链图片转存中...(img-FHH7P8cl-1706575867068)]
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











