






一、基础
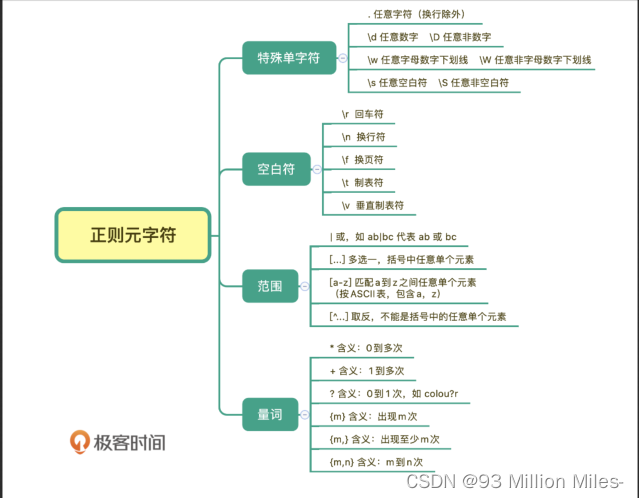
首先贴一个分类记忆正则表达式的图片,自行选择方式记忆。也可以根据下面的符号类型记忆。
1.限定符
a* : a出现0次或多次;ab*c代表a和c之间b可以出现0次也可以出现多次,那么可以匹配到ac、abc、abbbbc,但是匹配不到adc 。
a+ : a出现1次或多次;
a?: a出现0次或1次;字符a可有可无
a{6}:a出现6次;
a{2,6}:a出现2-6次;
a{2,}: a出现2次以上;
2. 或运算符
(a | b):匹配a或b;
(ab | cd):匹配ab或cd;当想匹配a dog或a cat时,可以写成a (cat|dog);括号不可省略,
a dog| cat 匹配到的就是a dog或cat。
3. 字符类
[ abc ]: 匹配a或者b或者c;方括号里的内容代表要求匹配的字符只能取自于它们
[ a-c ]:匹配a或者b或者c;
[ a-fA-F0-9 ]:匹配小写字母+大写英文字符以及数字;
[ ^0-9 ]:匹配非数字字符;^代表脱字符,要求匹配除了尖号后面列出的以外的字符,需要放在[ ]的里面。
4. 元字符
\d:匹配数字字符, 等同于[0-9];那么\d{3}代表匹配三个数字;
如果匹配101-23795的电话号码,那么就可以写成\d{3}-\d{5};
如果想匹配8个数字或者9个数字,\d{8,9}就可以啦;
如果遇到9个数字时只想匹配到第八个数字那么可以写成\d{8,9}?就可以啦。
\D:匹配非数字字符;
\w:匹配单词字符(英文、数字、下划线);
\W:匹配非单词字符;
\s:匹配空白符(包含换行符、tab);用的时候要用\转换;
\S:匹配非空白字符
. : 匹配任意字符(换行符除外),只能出现在[ ]方括号以外;出现在[ ]内就是匹配英文点. 啦;
\bword\b:\b标注字符的边界(全字匹配),这样就可以只匹配到word这个单词;
^ :匹配行首;例如^javascript-123456-javascript只会匹配到开头的单词,后面的不会匹配到;如果是javascript-123456-javascript$匹配到的就是后面的单词,前面的不会匹配到;注意和脱字符区分,脱字符需要写到[ ]里面。
$:匹配行尾;
5. 贪婪/非贪婪(懒惰)模式/独占模式
< + >/< * >:默认贪婪匹配“任意字符”;尽可能进行最长匹配。
< +? >/< *? >: 懒惰匹配“任意字符”;?会将贪婪匹配切换为懒惰匹配;尽可能进行最短匹配。
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
首先,我们看一下在字符串 aaabb 中使用正则 a* 的匹配过程。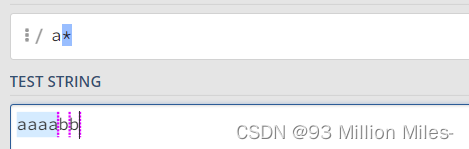
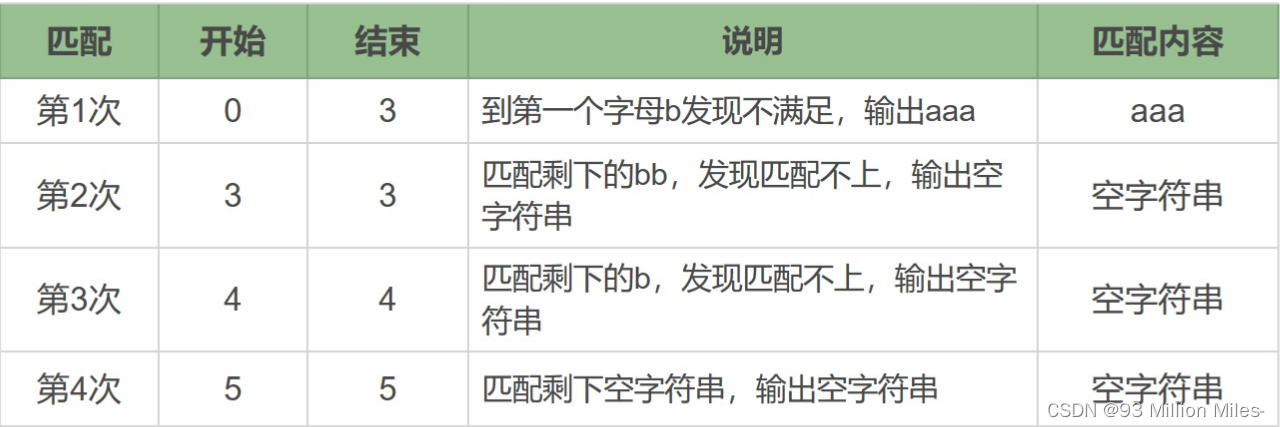
a*在匹配开头的a时,会尝试尽量匹配更多的a,知道第一个字母b不满足要求为止,匹配上三个a在,后面每次匹配时都得到了空字符串。
在量词后面加上? 就可以将贪婪模式变成非贪婪模式。
>>> import re
>>> re.findall(r'a*','aaabb') // 贪婪模式
['aaa','','','']
>>> re.findall(r'a*?','aaabb') // 非贪婪模式
['','a','','a','','a','','','']这次可以看到,匹配到的结果都是单个的a,就连a左边的空字符串也匹配上了。
下面再看一个示例加深一下理解:
匹配到了第一个引号和最后一个引号之间的所有内容:
找到符合结果的非贪婪匹配:
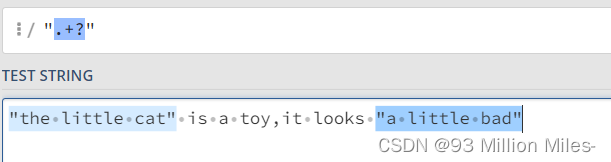
不管是贪婪模式还是非贪婪模式,都需要发生回溯才能完成相应的功能。但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了,因此正则中还有另外一种模式,独占模式,它类似贪婪匹配,但匹配过程不会发生回溯,因此在一些场合下性能会更好。
首先看一下回溯:
贪婪模式下:
>> regex = "xy{1,3}z"
>> text = "xyyz"
在匹配时,y{1,3}会尽可能长地去匹配,当匹配完 xyy 后,由于 y 要尽可能匹配最长,即三个,但字符串中后面是个 z 就会导致匹配不上,这时候正则就会向前回溯,吐出当前字符z,接着用正则中的 z 去匹配。
非贪婪模式下:
>> regex = "xy{1,3}?z"
>> text = "xyyz"
由于 y{1,3}? 代表匹配 1 到 3 个 y,尽可能少地匹配。匹配上一个 y 之后,也就是在匹配上text 中的 xy 后,正则会使用 z 和 text 中的 xy 后面的 y 比较,发现正则 z 和 y 不匹配,这时正则就会向前回溯,重新查看 y 匹配两个的情况,匹配上正则中的 xyy,然后再用 z去匹配 text 中的 z,匹配成功。
6.速写符号
* :等价于{ 0,};
+ :等价于{1,};
7.举例
(1).匹配16进制RGB颜色值 #ffffff #FFFFFF #00hh00
先去匹配前面的#,代表颜色值的字符都是16进制,因此取自于a-f A-F 0-9之间,并且字符需要出现6次,最后在表达式末尾加上\b来代表字符的边界,最终是#[a-fA-F0-9]{6}\b。
(2). 匹配以http开头,以 / 结尾的所有数据
http.*/$
二 . 进阶
8. 分组:
括号()在正则中可以用于分组,被括号括起来的部分“子表达式”会被保存成一个子组。当使用分组时,除了获得整个匹配。还能够在匹配中选择每一个分组。分组有一个非常重要的功能——捕获数据。所以()被称为捕获分组,用来捕获数据,当我们想要从匹配好的数据中提取关键数据的时候可以使用分组。
例如电话号0632-5897444想分别获取前面的区号和后面的电话号时就可以写成:(\d{4})-(\d{7});
想匹配<div>hi</div>并提取hi,就可以写成:<div>(.*?)</div>;
9. 单词边界(Word Boundary):
单词的组成一般可以用元字符\w+来表示,\w包括了大小写字母、下划线和数字(即 [A-Za-z0-9_]。当出现了\w 表示的范围以外的字符,比如引号、空格、标点、换行等这些符号,我们就可以在正则中使用\b 来表示单词的边界。 \b 中的 b 可以理解为是边界(Boundary)这个单词的首字母。具体用法可以看下面的表格:
三. 常用的正则表达式
1. 版本号限制,只允许输入两个小数点和数字,且二者间隔分布:^\d+(\.\d+\.\d+)$;
那如果想输入三个小数点就可以写成^\d+(\.\d+\.\d+\.\d+)$;
那如果想输入更多位的小数点就可以用花括号来限制^\d+(\.\d+){1,3}$;
当然也可以限制前面数字的位数^\d{1,4}(\.\d+){1,2}$,此时限制的只是第一位数字的位数为四位;
2. 只能输入数字和字母:[0-9a-zA-Z]+(不限制位数);[0-9a-zA-Z]{1,}(限制位数);
3. 只输入只能输入数字、字母和符号,也就是限制了汉字的输入:^[^\u4e00-\u9fa5]+$;(至少一位);
另一种写法:^[^\u4E00-\u9FFF]*$;(可以零位);
由此可以看出,这是对汉字的输入进行了取反,如果只想要汉字那就是:^[\u4e00-\u9fa5]+$;
4. 正整数:^[1-9]{1}[0-9]*$;
5. 正负整数:^-?[0-9]{1}[0-9]*$;
6. 数字字母下划线,且不能纯数字:^[A-Za-z0-9_]*[A-Za-z_][A-Za-z0-9_]*$;
7. 限制空格的输入:^[^\\s]*$; \s表示只要出现空白就匹配,\S表示非空白就匹配,所以也可以写成^[\\S]*$;一定要注意,在一些正则验网站上是不需要\来转换的,但是在编码的时候要使用转义符来转换;
一般在进行编码时,例如,字段只允许输入数字字母汉字时,空格会被限制输入;但是当字段没有限制,或只限制了不为空时,空格不会被限制输入,所以要看看需求到底限不限制空格的输入。















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









