






打包ocr的过程我遇到了很多个问题,整个过程涉及到路径地修改和环境变量等问题。我相信很多人都会遇到与我相同的问题,我把我打包的过程中遇到的各种问题尽量都写下来。希望对大伙有帮助。
起先我的开发环境是这样设置的
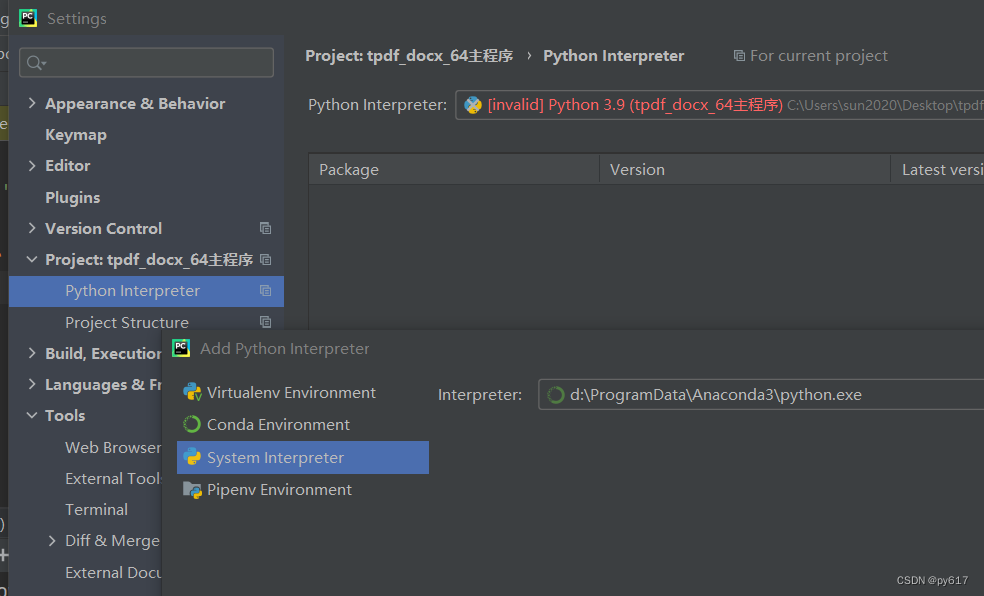
选了第三个 系统环境 ,结果利用 pyinstaller 打包时 ,把系统里的所有库 包括我的py主程序没有使用到的库 全部都给打包进来了,结果自然是文件很大。
为了解决这个问题,我改为选择第一个 Virtualenv Environment ,在主程序的根目录下建立了一个虚拟环境,但是点击确定时,却提示我说:权限被拒绝。
这个问题的本质就是,你当时安装python时,选择了傻瓜式安装,python 安装在你的个人名义下。所以如今使用这个python解释器时,系统认为你是个人名义下的,不是整个电脑的,于是认为没有这个权限,拒绝了。
解决的方法是:建议重新安装python。我下载了![]()
3.9.5版本的,双击安装。
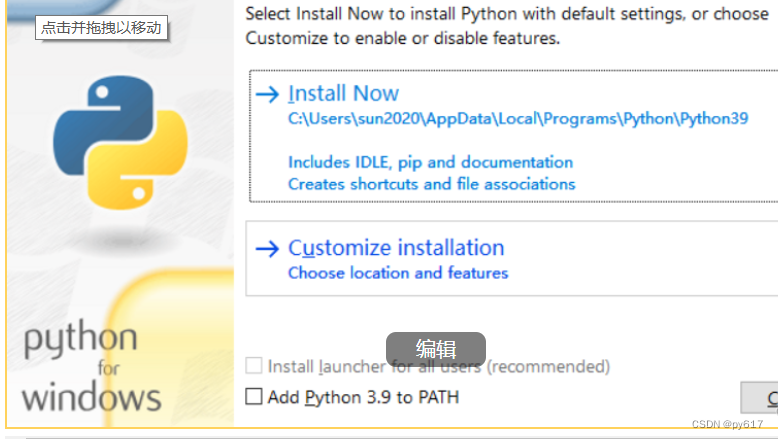
下面的Add python 3.9 to PATH打√,然后点击上面的Customize installation 。然后进入下一个界面,记得对 for all user 打√,接着一步步点下一步安装 直到结束。
这样之后,你的python ,就安装在![]() 这个路径下。并且是权限没有受到限制的。
这个路径下。并且是权限没有受到限制的。
这样你就能顺利设置了虚拟环境了。
扫描类的pdf转word文字时,基本上要用到ocr工具。
要事先安装ocr,傻瓜式安装会安装在C盘。
我的py主程序,用到的模块有:

其中os是python自带的,不需要安装,其他的通过pycharm下面的Terminal安装的:

Terminal,通过pip install xxx安装你需要用到的模块
pip install PIL会出错,要改为pip install image 就可以。
运行时报No module named 'frontend',通过额外安装pip install PyMuPDF解决;
报Error: No module named 'exceptions',通过pip install python-docx解决;
接着又出现下方错误提示,
![]()
这个问题可以通过pip install PyMuPDF==1.19.0解决,这样说明之前PyMuPDF的版本太低,是没有pageCount这个属性的。
((
顺带说一下,运行中提示DeprecationWarning: ANTIALIAS is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.LANCZOS instead.
说ANTIALIAS被弃用了,而我在改变图片像素时,正好就用到了Image.ANTIALIAS,原代码:
![]()
我干脆把上面这句改成了
![]()
结果发现识别出来的出错率还反而更低了。这是一个经验之谈。
))
继续将打包的话题:
py运行时,它是先去找 site-packages\pytesseract\pytesseract.py文件。
这里有两种可能:如果你是设置conda作为解释器而不是建立虚拟环境的,那个系统会去读pytesseract.py文件时,读的是具体位置在D:\ProgramData\Anaconda3\Lib\site-packages\pytesseract\pytesseract.py的这个。
(你打包时系统也会打包走这个py。因此,你的位置指引若需要修改,就改这个py。)
如果你是建立了虚拟环境,venv建立在你的主程序的同个根目录里,那么程序运行或者打包时,系统找的那个文件,就是主程序的根目录下的py文件。具体位置在
(py主程序的根目录)+ \venv\Lib\site-packages\pytesseract\pytesseract.py
然后通过pytesseract.py里的
这段代码,赋值了tesseract的位置,让系统通过你之前设置好的环境变量,找到ocr工具。
如果你没有设置好环境变量,那么就把上面这句话改成

让系统直接去找你安装的工具。
按上面的步骤 ,打包出来的exe ,在你的电脑上是可以运行的,但是去到别人的电脑就无法运行了。因为别人的电脑是没有像你的电脑一样在C盘的特定位置安装有tesseract工具的。
于是,上面的这种网上大多数说到的修改方法,只能在你的电脑上使用,打包exe去到别人的电脑运行就会报错
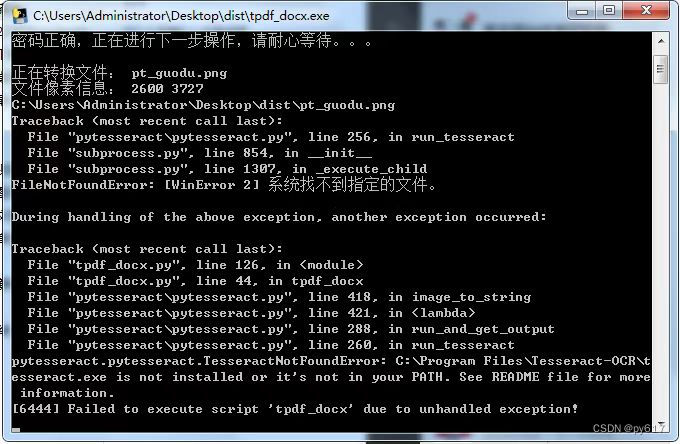
说你没有安装或者安装后没设置虚拟环境。
解决方法,去C盘把ocr工具复制出来, 放到了你的py主程序根目录下。
然后pytesseract.py里,就对应着写,把路径引到根目录下的这个ocr,

这样子,打包好的exe,根目录下放着从C盘复制来的 Tesseract-OCR文件夹,一起发给其他人就可以使用了。
另外还有一点要特别注意的:在 pyinstaller -F XX.py 之前,一定要先 pip install pyinstaller安装pyinstaller。不然虽然也能生成exe,但生成出来的exe文件会大很多倍。
经过这一番折腾,最终我打包出来的文件从之前的347M,缩小到现在66M,缩小了5倍之多。
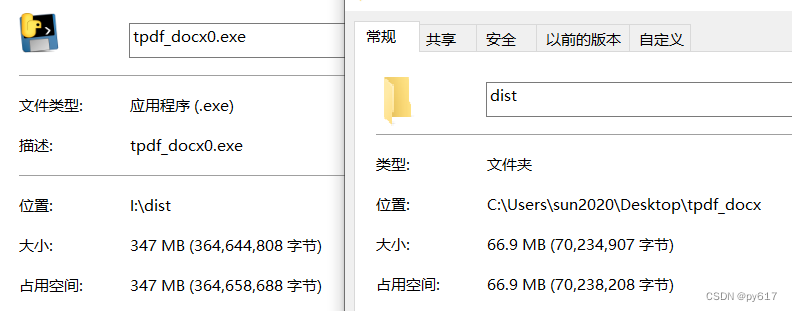
接着我们会想,能不能把这个辅助文件夹 Tesseract-OCR一起打包进去刚刚打包出来的exe呢?
具体请先读一下我之前的这篇文章,其中的原理必须懂, 不然你会看了懵圈。
python如何把程序运行时的需要用到的辅助文件,一起打包进exe里_py617的博客-CSDN博客
接下来我们讲这个问题我的解决方法:
pytesseract.py里进行这样的修改:
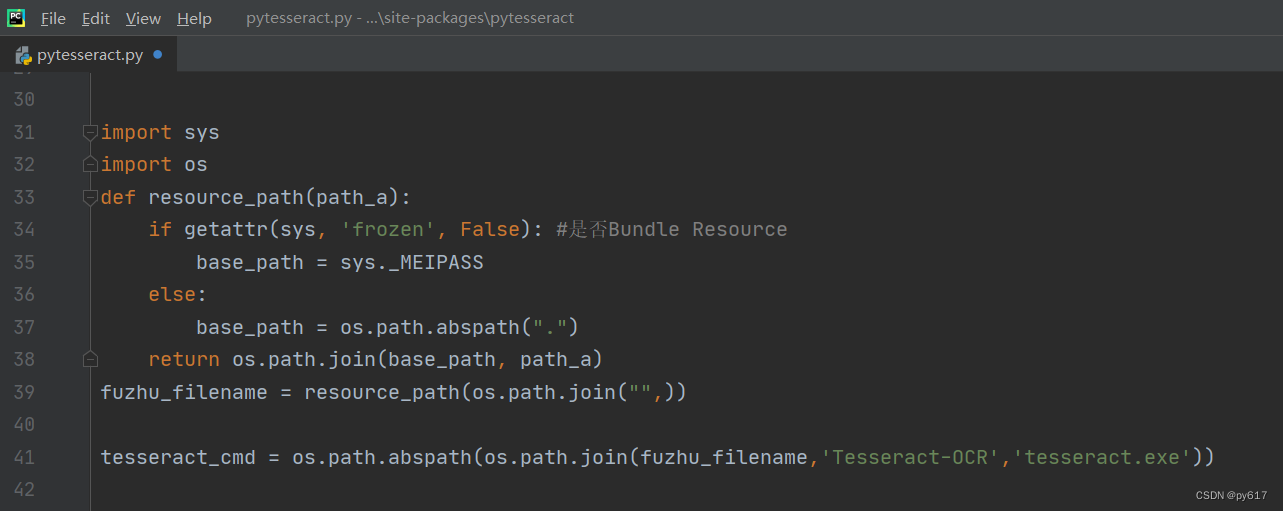
代码如下:
import sys
import os
def resource_path(path_a):
if getattr(sys, 'frozen', False): #是否Bundle Resource
base_path = sys._MEIPASS
else:
base_path = os.path.abspath(".")
return os.path.join(base_path, path_a)
fuzhu_filename = resource_path(os.path.join("",))
tesseract_cmd = os.path.abspath(os.path.join(fuzhu_filename,'Tesseract-OCR','tesseract.exe'))
然后打开第一次打包exe时,同个根目录下生成的spec文件。做出如下修改:
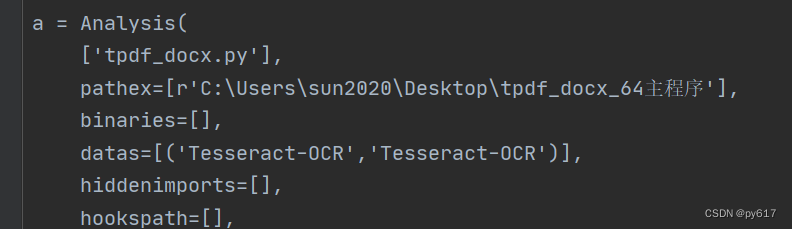
意思是要打包的文件时 tpdf_docx.py ,地址是 xxx,然后打包py文件时,连同Tesseract-OCR要一起打包,打包过去后,名字同样叫Tesseract-OCR。
最后,在pycharm的test.py下面输入pyinstaller tpdf_docx.spec。按Enter键等待,最终的文件生成在dist里。之前第一次生成的exe会被替代掉,你若还要那个第一次生成的exe,就在pyinstaller tpdf_docx.spec之前,先把它复制出来就行了。
这个问题需要不停尝试,中间总会遇到这样那样的问题,但是只要善于琢磨,相信过程是曲折的,前途是光明的。















 2873
2873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









