






MySQL学习
一、安装与卸载
指令:
- 查看版本:
mysql --version - 登入:
mysql -uroot -p - 展示数据库:
show databases; - 使用数据库:
use 库名字 - 展示数据表:
show tables; - 用户名:
root密码:020508(若有问题,在要输入password时直接回车跳过输入密码就可以进来,此时在命令提示符界面输入语句修改密码即可:ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '020508';) - 退出登录:
quit或exit
二、初识SQL

1.为什么学习数据库
持久化:将内存中数据存储在关系型数据库中
2.相关概念
数据库(DB):存储数据的文件系统,保存一系列有组织的数据
数据库管理系统(DBMS):操纵和管理数据库的大型软件,例:MySQL,Oracle(关系型数据库管理系统)
结构化查询语言(SQL):用于与数据库通信的语言
3.数据表
关系型数据库典型数据结构就是数据表(E-R模型中三个主要概念是:实体集、属性、联系集)
表与表的关联关系:一对一、一对多、多对多、自我引用
4.SQL分类
SQL在功能上分为3大类:
-
DDL(Data Definition Languages、数据定义语言)
用于创建、删除、修改数据库和数据表的结构
- 主要关键字包括
CREATE、DROP、ALTER
- 主要关键字包括
-
DML(Data Manipulation Language、数据操作语言)
用于添加、删除、更新和查询数据库记录
- 主要关键字包括
INSERT、DELETE、UPDATE、SELECT
- 主要关键字包括
-
DCL(Data Control Language、数据控制语言)
用于定义数据库、表、字段、用户的访问权限
- 主要关键字包括
GRANT(赋予权限)、REVOKE(回收权限)、COMMIT(提交)、ROLLBACK(回滚\撤销)
- 主要关键字包括
三、数据库知识
1.主键和外键
主键(primary key):关系型数据库中的一条记录中有若干个属性,若其中某一个属性组(注意是组)能唯一标识一条记录,该属性组就可以成为一个主键 。
外键(foreign key):如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键作主关键字的表被称为主表,具有此外键的表被称为主表的从表。外键又称作外关键字。
四、SQL语句
1. select语句
1.1常见基础SQL语句
规则:
SQL语句要以分号或\g或\G结尾;字符串、日期、时间类型的变量需要使用’'表示
MySQL在Windows环境下大小写不敏感;在Linux环境下大小写敏感
命名规则:
字符串要用单引号’'引起来
-
创建数据库:
creat database 名字; -
建表前先指定哪个数据库:
use 数据库名字; -
创建数据表:
creat table 名字; -
销毁数据库:
drop database 数据库名字; -
插入数据:
eg:
INSERT INTO users;
VALUE('Aaron',001); -
单行注释:
# 语句;多行注释:/*多行语句*/
1.2 select语句
基础:select 字段 from 表名;
运算式:select salary * 12 "年工资" from 表名
展示所有的列:select * from 表名;
1.2.1 列的别名
select 列名 (as) 别名 from 表名;
例:查询员工最高工资和最低工资的差距(DIFFERENCE):
SELECT MAX(salary) - MIN(salary) "DIFFERENCE"
FROM employess;
1.2.2 去除重复行
select distinct 列名 from 表名;
5.4 空值
空值:null 不等同于0
空值参与运算,无论加减乘除,结果一定是null
1.2.3 过滤数据
(1)
SELECT * FROM 表名 WHERE 条件1 AND 条件2;
eg:select 列名 from 表名 where id in (10,20,30)
注:1. where里不可以用列的别名
2. where必须紧跟着from
(2)
有两个员工表,现在我们要查出同时存在于两个表的员工,则以下用 IN 和 EXISTS 返回的结果是一样,但是用 EXISTS 的 SQL 会更快:
– 慢
SELECT *
FROM Class_A
WHERE id IN (SELECT id
FROM CLASS_B);
– 快
SELECT *
FROM Class_A A
WHERE EXISTS
(SELECT *
FROM Class_B B
WHERE A.id = B.id);
1.2.4 配合运算符使用
select 100 + 50 * 30 from 表名
注:Java里数字+字符使用Java中加号的连接作用,eg:100+‘1’ 结果是1001
SQL中没有这种作用,就表示加法运算,此时会将字符串转为数值(隐式转换),如’1’转换为数值1,不能转换的视为0,如’a’视为数值0;
1.2.5 排序与分页
- 使用order by 关键字对查询到的数据进行排序操作
默认是升序:select 列名,列名 from 表名 order by 列名;
降序:select 列名,列名 from 表名 order by 列名 DESC;
eg:select 列名 from 表名 where 条件 order by 列名;
- 使用limit实现数据的分页
select 列名 from 表名 limit 偏移量,一页展示量;
如:select 列名 from 表名 limit 0,1;表示显示第一个数据
注 :偏移量为0时,表示从0开始显示
sqlyog只显示第一页
想显示第二页,需这样:limit 20,20;
1.3 多表查询
实现方式:(内连接、外连接都能实现)
(1)内连接:主表 JOIN 表1 ON 连接条件1 JOIN 表2 ON 连接条件2
(2)外连接:
左外连接:主表 LEFT JION 表1 ON 连接条件1
WHERE emplyees.department_id = departments.department_id
1.3.1 表间关联
一对多,一对一,多对多
一对多:多的一方要添加外键关联一的一方的主键
多对多:要增加一个关系表来关联它俩
1.3.2 表的别名
注意:如果给表起了别名,在SELECT或WHERE中使用表名的话就必须用别名
SELECT emp.employee_id,emp.department_id
FROM employees emp
WHERE emp.employee_id = emp.department_id
1.3.3 连接方式
笛卡尔积(交叉连接):这在多表查询中是错误的连接方式;
正确的连接方式可分为多种,较为特殊的情况如下:
- 自连接:
例如一张公司成员表中即有老板id又有员工id,同时员工属性中还显示属于哪个老板的情况
#查员工id及其管理者的id
SELECT worker.employee_id,manager.employee_id
FROM employees worker, employees manager #将同一张employees表看作两张表使用:员工表和老板表
WHERE worker.manager_id = manager.employee_id; #俩表间用老板拥有的员工id和员工属于的老板id相等来连接
- 内连接:
合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行 - 外连接:(“所有”)
两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。- 如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
- 如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
1.3.4 七种JOIN
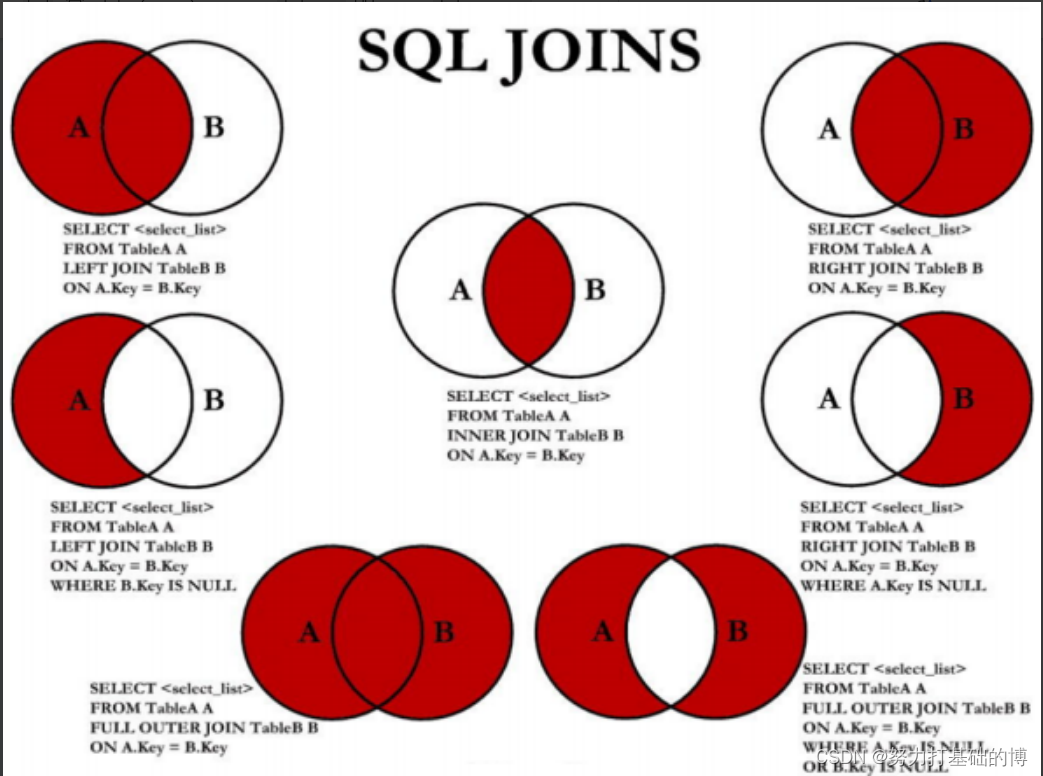
1.4 MySQL内置函数
MySQL从实现功能的角度可以分为数值函数、字符串函数、日期和时间函数、流程控制函数、加密与解密函数等;这里分为单行函数 和 多行函数(聚合函数/分组函数)来学习
1.4.1 单行函数
(输入一行数据,输出一行数据)
基础函数:
ABS(x) :返回x的绝对值 SIGN(X) :返回X的符号。正数返回1,负数返回-1,0返回0
PI() :返回圆周率的值
CEIL(x),CEILING(x) :返回大于或等于某个值的最小整数(天花板函数)
FLOOR(x):返回小于或等于某个值的最大整数(地板函数)
LEAST(e1,e2,e3…) :返回列表中的最小值
GREATEST(e1,e2,e3…):返回列表中的最大值
MOD(x,y) :返回X除以Y后的余数
RAND() :返回0~1的随机值
RAND(x):返回0~1的随机值,其中x的值用作种子值,相同的X值会产生相同的随机数
ROUND(x):返回一个对x的值进行四舍五入后,最接近于X的整数
ROUND(x,y) :返回一个对x的值进行四舍五入后最接近X的值,并保留到小数点后y位
YTRUNCATE(x,y) :返回数字x截断为y位小数的结果
SQRT(x) :返回x的平方根。当X的值为负数时,返回NULL
三角函数:
RADIANS(x):把角度值转化为弧度值
SIN(x) :返回x的正弦值,其中,参数x为弧度值
ASIN(x) :返回x的反正弦值,即获取正弦为x的值。如果x的值不在-1到1之间,则返回NULL
COS(x) :返回x的余弦值,其中,参数x为弧度值
ACOS(x) :返回x的反余弦值,即获取余弦为x的值。如果x的值不在-1到1之间,则返回NULL
TAN(x) :返回x的正切值,其中,参数x为弧度值
ATAN(x) :返回x的反正切值,即返回正切值为x的值
ATAN2(m,n) :返回两个参数的反正切值
COT(x) :返回x的余切值,其中,X为弧度值
进制转换:
BIN(x) :返回x的二进制编码
HEX(x) :返回x的十六进制编码
OCT(x) :返回x的八进制编码
CONV(x,f1,f2) :返回f1进制数变成f2进制数
字符串函数:
ASCII(S) :返回字符串S中的第一个字符的ASCII码值
CHAR_LENGTH(s) :返回字符串s的字符数。作用与CHARACTER_LENGTH(s)相同
LENGTH(s) :返回字符串s的字节数,和字符集有关
CONCAT(s1,s2,…,sn) :连接s1,s2,…,sn为一个字符串
CONCAT_WS(x,s1,s2,…,sn):同CONCAT(s1,s2,…)函数,但是每个字符串之间要加上x
INSERT(str, idx, len,replacestr):将字符串str从第idx位置开始,len个字符长的子串替换为字符串replacestr
REPLACE(str, a, b) :用字符串b替换字符串str中所有出现的字符串a
UPPER(s) 或 UCASE(s) :将字符串s的所有字母转成大写字母
LOWER(s) 或LCASE(s): 将字符串s的所有字母转成小写字母
LEFT(str,n) :返回字符串str最左边的n个字符
RIGHT(str,n) :返回字符串str最右边的n个字符
LPAD(str, len, pad) :用字符串pad对str最左边进行填充,直到str的长度为len个字符
RPAD(str ,len, pad) :用字符串pad对str最右边进行填充,直到str的长度为len个字符
日期时间函数:
CURDATE() ,CURRENT_DATE():返回当前日期,只包含年、月、日
CURTIME() , CURRENT_TIME():返回当前时间,只包含时、分、秒
NOW() / SYSDATE() / CURRENT_TIMESTAMP() / LOCALTIME() /LOCALTIMESTAMP():返回当前系统日期和时间
1.4.2 多行函数(聚合函数、分组函数)
(输入多行数据,输出一行数据)
AVG(列名):求平均值(只针对数值型数据)
SUM():求和(只针对数值型数据)
MAX():(适用于任意数据类型)
MIN():(适用于任意数据类型)
COUNT(*)或者COUNT(1):返回表中记录总数(适用于任意数据类型)
(1) GROUP BY (分组)
表示按什么方式分组
#单列情况:如:查询各个部门平均工资:
SELECT department_id,AVG(salary)
FROM employess
#按部门id分组,也可以按性别分组,由题决定
GROUP BY department_id;
#多列情况:如:查询各个department_id,job_id的最高工资
#注意:select中出现的非主函数字段必须出现在GROUP BY中!!
SELECT department_id,job_id,MAX(salary)
FROM employess
GROUP BY department_id,job_id;
eg:查询平均工资最低的部门信息(从内往外写)
#方式一:
#最外层查询与‘所有部门的平均工资中找到最低的工资’相等的部门分别有哪些
SELECT department_id
FROM employess
GROUP BY department_id
HAVING AVG(salary) = (
#次内层:从所有部门的平均工资中找到最低的工资
SELECT MIN(avg_salary)
FROM(
#最内层:找到所有部门的平均员工工资,并把这些数据组成表
SELECT AVG(salary) avg_salary
FROM employees
GROUP BY department_id
) t_dept_avg_salary #这是表名
)
#方式二:(更简单)
SELECT department_id
FROM employess
GROUP BY department_id
HAVING AVG(salary) >= ALL(
SELECT AVG(salary)
FROM employees
GROUP BY department_id
);
#方式三:(limit)
SELECT department_id
FROM employess
GROUP BY department_id
HAVING AVG(salary) = (
SELECT AVG(salary) avg_salary #找到所有部门的平均员工工资
FROM employees
GROUP BY department_id
ORDER BY avg_salary DESC #把平均工资降序排序
LIMIT 0,1 #只取第一个,即最大值
);
(2)HAVING (过滤)
(也是用来过滤数据的,特殊条件代替where使用)
注:1. 如果过滤条件中使用了聚合函数,则必须使用HAVING来替换where,否则报错
2. HAVING 必须声明在 GROUP BY后面,且必须与GROUP BY一起使用
#要求:查询职工最高工资在10000以上的部门
SELECT department_id,MAX(salary)
FROM employess
GROUP BY department_id
#按原来的学习:在from后用where MAX(salary) > 10000,但有聚合函数不能这样写,应该用HAVING替换
HAVING MAX(salary) > 10000;
#要求:查询id为1的职工最高工资在10000以上的部门
#方式一:
SELECT department_id,MAX(salary)
FROM employess
WHERE department_id = 1
GROUP BY department_id
HAVING MAX(salary) > 10000;
#方式二:
SELECT department_id,MAX(salary)
FROM employess
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id = 1;
据此有了疑问:HAVING功能上能替代WHERE,那还要WHERE干嘛?
答:WHERE效率高很多,且要求开发中必须用方式一,即若非聚合函数必须使用HAVING,其他情况都要用WHERE
(3)CASE WHEN … THEN
场景2:现老师要统计班中,有多少男同学,多少女同学,并统计男同学中有几人及格,女同学中有几人及格。其中SEX字段,0表示男生,1表示女生。
NAME SEX SCORE
小明 0 88
小磊 0 55
小峰 0 45
小红 1 66
晓妮 1 77
小伊 1 99
SELECT
SUM (CASE WHEN STU_SEX = 0 THEN 1 ELSE 0 END) AS MALE_COUNT,
SUM (CASE WHEN STU_SEX = 1 THEN 1 ELSE 0 END) AS FEMALE_COUNT,
SUM (CASE WHEN STU_SCORE >= 60 AND STU_SEX = 0 THEN 1 ELSE 0 END) AS MALE_PASS,
SUM (CASE WHEN STU_SCORE >= 60 AND STU_SEX = 1 THEN 1 ELSE 0 END) AS FEMALE_PASS
FROM
THTF_STUDENTS
1.5.子查询
子查询是指将一个查询语句嵌套在另一个查询语句内部
注:除GROUP BY 和LIMIT外,其他位置都可以写子查询
SELECT department_id , salary
FROM employess
WHERE salary > ALL(
SELECT department_id , salary
FROM employess
WHERE department_id = 1
);
#姓名中含字母u
where last_name like '%u%'
2. 创建、修改和删除数据表
2.1 创建和管理数据库
2.1.1 标识符命名规则
- 必须只能含阿拉伯数字和大小写字母
- 不能含空格
2.1.2 创建语句
方式1:创建数据库
CREATE DATABASE 数据库名;
方式2:创建数据库并指定字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集;
方式3:判断数据库是否已经存在,不存在则创建数据库( 推荐 )
CREATE DATABASE IF NOT EXISTS 数据库名;#如果原数据库已存在,则创建不成功,但不报错
2.1.3 管理数据库
- 展示所有数据库语句:
SHOW DATABASES;
- 查看当前正在使用的数据库:
SELECT DATABASE();
- 查看指定库下所有的表:
SHOW TABLES FROM 数据库名;
- 查看数据库的创建信息:
SHOW CREATE DATABASE 数据库名;
- 使用/切换数据库:
USE 数据库名;
注意:要操作表格和数据之前必须先说明是对哪个数据库进行操作,否则就要对所有对象加上“数据库名.”
- 更改数据库字符集:
ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
- 删除数据库:
DROP DATABASE IF EXISTS 数据库名;
2.2 创建和管理数据表
2.2.1 创建表
-
方式一:(白手起家式)
-
方式二:(基于现有表)
CREATE TABLE 表名
AS
SELECT employee_id, last_name, salary
FROM employees;
2.2.2 查看表
DESC 表名; #查看表结构
SHOW CREATE TABLE 表名; #查看创建表的语句
2.2.3 修改表
2.2.4 重命名表
2.2.5 删除表
2.3 数据处理之增删改
2.3.1 添加数据
- 方式一:逐条添加
INSERT INTO 表名(指明要添加的字段)
VALUES ( ... );
# 不进行赋值时值为null
2.4 约束(constrant)
约束是表级的强制规定,SQL通过规范约束来提高数据完整性(即数据的准确性和可靠性)
2.4.1 分类
- 按约束字段的个数:
单列约束和多列约束 - 按作用范围:
列级约束和表级约束 - 按作用或功能:
非空约束 not null
唯一性约束 unique
主键约束 primary key
外键约束 foreign key
检查约束 check key
默认约束 default
2.4.2 添加和修改约束
- 在建表时添加约束
CREATE TABLES IF NOT EXISTS 表名(
id INT NOT NULL,
name VARCHAR(15) NOT NULL,
salary DOUBLE
);
- 在添加数据时添加约束
INSERT INTO 表名(指明要添加的字段)
VALUES ( ... NOT NULL);
3. 索引(Index)
索引是存储引擎中快速找到数据记录的一种数据结构,可以减少从磁盘I/O的次数,用于加快数据库查询的速度和性能。
索引分单列索引和组合索引:
单列索引:即一个索引只包含单个列,一个表可以有多个单列索引。
组合索引:即一个索引包含多个列。
3.1 创建索引
CREATE INDEX index_name
ON table_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
例如: CREATE INDEX idx_name ON students (name);
ALTER TABLE table_name
ADD INDEX index_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
待继续学
4.SQL语句优化
五、数据库进阶
1.索引
索引是帮助MySQL高效获取数据的数据结构。
索引分类
功能逻辑上分:普通索引、唯一索引、主键索引、全文索引
物理实现上分:聚簇索引和非聚簇索引
创建方式
1.隐式的创建:在声明有主键约束、唯一性约束和外键约束的字段上,会主动的添加相关的索引。
2.显式创建:
- 建新表时:
(1)普通索引
CREATE TABLE table_name{
“表的内容”
INDEX “索引名” “要加索引的列的名字”
};
(2)主键索引
CREATE TABLE table_name{
“要加索引的列的名字” “列的类型” PRIMARY KEY,
“表的内容”
};
主键索引的删除:通过删除主键约束的方式来删除主键索引
ALTER “表名”
DROP PRIMARY KEY;
- 对现成表:
2. redis
六、面试+实战
MySQL事务的四大特性是什么(基础回答)?都是做什么的(入门回答),实现原理是什么?
⑴、数据库事务正确执行的四个基本要素是【ACID】。
⑵、分别作用是:
A:原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
C:一致性(Consistency)
事务前后数据的完整性必须保持一致。
I:隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
D:持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
⑶、ACID的实现原理
A(atomicity):使用undo log日志实现,原子性要么都成功,要么都失败,会记录每一次的操作记录的undo log日志,后面发生异常时在从undo log把事物回滚掉。
C(consistency):一致性是根据原子性+隔离性+持久性组合下完成的。
I(isolation):事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务所干扰,多个并发事务之间要相互隔离。【依赖于锁】。
D(durability):redo log日志实现。
实现原理小节: 事务的原子性是通过undolog来实现的。
事务的持久性性是通过redolog来实现的。
事务的隔离性是通过(读写锁+MVCC)来实现的。
事务的一致性是通过原子性,持久性,隔离性来实现的。
- 合并俩个表
左外连接 left join
- 第二高薪水
order by salary DESC
limit 1,1
- 超过经理的员工的工资
自连接 - 从不订购任何东西的用户
not in















 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









