






# 实现目标【删除列表中的列表里第一个元素重复的元素列表,只留第1个】
完整代码附在后面
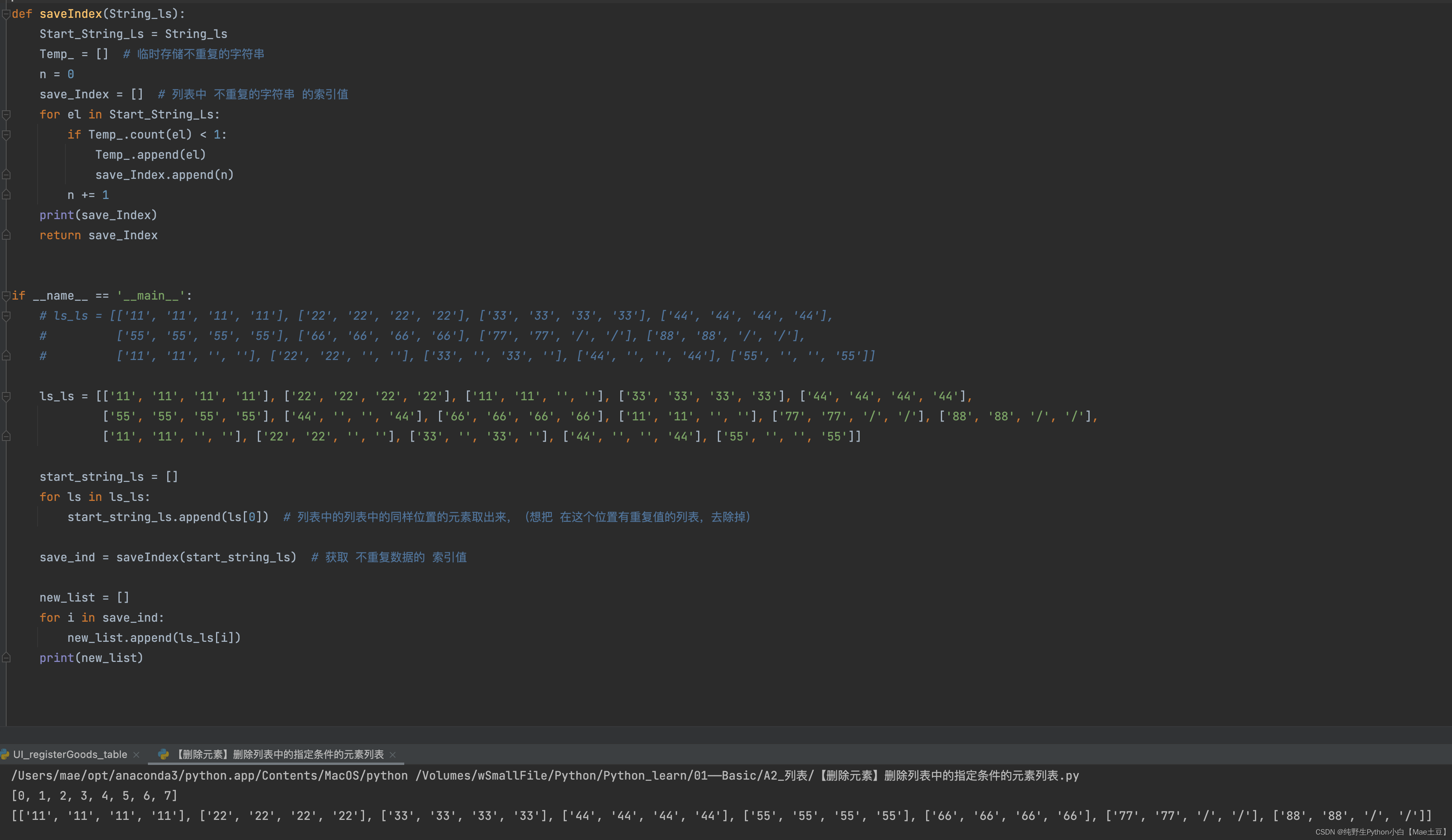
# 实现目标【删除列表中的列表里第一个元素重复的元素列表,只留第1个】
def saveIndex(String_ls):
Start_String_Ls = String_ls
Temp_ = [] # 临时存储不重复的字符串,(判断重复值时需要)
n = 0
save_Index = [] # 列表中 不重复的字符串 的索引值
for el in Start_String_Ls:
if Temp_.count(el) < 1:
Temp_.append(el)
save_Index.append(n)
n += 1
print(save_Index)
return save_Index
if __name__ == '__main__':
ls_ls = [['11', '11', '11', '11'], ['22', '22', '22', '22'], ['11', '11', '', ''], ['33', '33', '33', '33'], ['44', '44', '44', '44'],
['55', '55', '55', '55'], ['44', '', '', '44'], ['66', '66', '66', '66'], ['11', '11', '', ''], ['77', '77', '/', '/'], ['88', '88', '/', '/'],
['11', '11', '', ''], ['22', '22', '', ''], ['33', '', '33', ''], ['44', '', '', '44'], ['55', '', '', '55']]
start_string_ls = []
for ls in ls_ls:
start_string_ls.append(ls[0]) # 列表中的列表中的同样位置的元素取出来,(想把 在这个位置有重复值的列表,去除掉)
save_ind = saveIndex(start_string_ls) # 获取 不重复数据的 索引值
new_list = []
for i in save_ind:
new_list.append(ls_ls[i])
print(new_list)
返回结果
[0, 1, 2, 3, 4, 5, 6, 7]
[['11', '11', '11', '11'], ['22', '22', '22', '22'], ['33', '33', '33', '33'], ['44', '44', '44', '44'], ['55', '55', '55', '55'], ['66', '66', '66', '66'], ['77', '77', '/', '/'], ['88', '88', '/', '/']]















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









